







目录
一、常量
常量就是在程序中不可变化的量,常量在定义的时候必须给一个初值。
1.1 宏常量
使用#define 修饰 ,常量名通常大写
#include<stdio.h>
#define MAX 100 //定义常量, 注意没有=号, 没有;号, 需要使用#号+define关键字
int main(){
printf("%d\n",MAX);
return 0;
}
1.2 const常量
常量名和变量名命名方式一样, 一般来说在c语言用宏常量比较多,c++用const常量比较多
#include<stdio.h>
const int a = 100;// 1.可以定义在这里,需要声明常量的类型,这里是int类型, 必须带;号
int main(){
const int b = 200; // 2.也可以定义在方法内
printf("%d\n",a);
printf("%d\n",b);
return 0;
}
1.3 字符串常量
用双引号标识,例如"hello world"
1.4 整数常量
例如int a = 500; // a是变量 ,但是500是整数常量
二、十进制与二进制
一个比特就是1bit, 只能是0或者1
一个BYTE = 8 bit
一个int =4 BYTE = 32bit
2BYTE = WORD(字)
2个WORD = 1DWORD(双字)
1KB = 1024BYTE
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
注意:MB和Mb是不一样的意思,前者是M BYTE ,后者是 M bit, 他们之间相差8倍, 也就是1MB = 8Mbit
2.1 十进制,二进制,八进制,十六进制的关系
| 10进制 | 二进制 | 八进制 | 十六进制 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 10 | 2 | 2 |
| 3 | 11 | 3 | 3 |
| 4 | 100 | 4 | 4 |
| 5 | 101 | 5 | 5 |
| 6 | 110 | 6 | 6 |
| 7 | 111 | 7 | 7 |
| 8 | 1000 | 10 | 8 |
| 9 | 1001 | 11 | 9 |
| 10 | 1010 | 12 | a |
| 11 | 1011 | 13 | b |
| 12 | 1100 | 14 | c |
| 13 | 1101 | 15 | d |
| 14 | 1110 | 16 | e |
| 15 | 1111 | 17 | f |
| 16 | 10000 | 20 | 10 |
2.2 二进制与八进制和16进制的关系
每3位二进制 可以用1位8进制表示 , 每4位二进制可以用1位16进制表示
二进制:1011011011000101011
->八进制:001 011 011 011 000 101 011 每3段2进制来划分, 不够的前面补0
001(1) 011(3) 011(3) 011(3) 000 (0) 101(5) 011(6) = 1333056(八进制)
二进制:1011011011000101011
->十六进制:0101 1011 0110 0010 1011 每4段2进制来划分, 不够的前面补0
0101(5) 1011 (b) 0110 (6) 0010 (2) 1011 (b) = 5b62b(十六进制)
注意:
二进制的表示是以0b或0B(不区分大小写)开头表示的,例如 int a = 0b101; //换算成十进制为 5 = 4+1
八进制的表示是以0开头(注意是数字 0,不是字母 o), 例如 int a = 015; //换算成十进制为 13 = 8+5
十六进制的表示是以0x或0X()不区分大小写)开头表示的, 例如 int a = 0X2A; //换算成十进制为 42 = 16+16+10
2.3 十进制数转换为2进制的技巧
十进制的56转为2进制的技巧?
先把这个数转成8进制, 然后再把8进制直接对应2进制.
方法:用短除法56除以8, 分别取余数和商数,商数为0 的时候把余数倒过来.
图示:
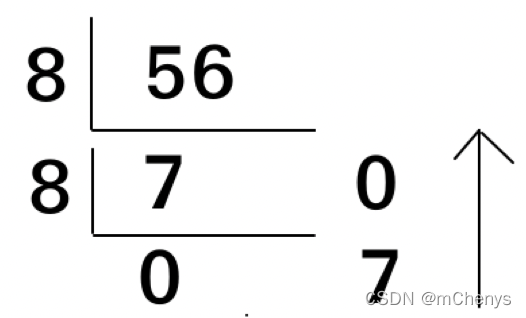
余数倒过来就是70,转换位2进制就是1110
三、原码反码与补码
正数的二进制原码、反码和补码是一样的;负数的反码=原码符号位不变,其他位取反,负数的补码=反码+1
3.1 原码推算补码的方式
7的二进制原码, 反码,补码是一样的
0000 0111 一个BYTE(字节)
0000 0000 0000 0111 一个WORD(字)
0000 0000 0000 0000 0000 0000 0000 0111 一个DWORD(双字)
最高位是符号位,0是整数, 1是负数
-7的二进制原码
1000 0111 一个BYTE(字节)
1000 0000 0000 0111 一个WORD(字)
1000 0000 0000 0000 0000 0000 0000 0111 一个DWORD(双字)
负数的反码 = 符号位不变,其他位取反
1111 1000 一个BYTE(字节)
1111 1111 1111 1000 一个WORD(字)
1111 1111 1111 1111 1111 1111 1111 1000 一个DWORD(双字)
负数的补码 = 反码+1
1111 1001 一个BYTE(字节)
1111 1111 1111 1001 一个WORD(字)
1111 1111 1111 1111 1111 1111 1111 1001 一个DWORD(双字)
在计算机中都是用补码来操作的.
3.2 补码推算原码的方式
(1)正数:保持不变
(2)负数:符号位全程不变, 要先-1变成反码 , 然后再取反变成原码; 或者符号位全程不变, 要先取反后+1
若已知 负数 -8,则其
原码为:1000 1000,(1为符号位,为1代表负数,为0代表正数)
反码为:1111 0111,(符号位保持不变,其他位置按位取反)
补码为:1111 1000,(反码 + 1)
即在计算机中 用 1111 1000表示 -8
若已知补码为 1111 1000,如何求其原码呢?
(1)方法1:先-1后取反(求负数 原码->补码的逆过程),注意:符号位保持不变!
(A)先 - 1,得到 1111 0111
(B)取反(符号位保持不变,其他位置按位取反 ),得到 1000 1000
(2)方法2:先取反后+1,注意:符号位保持不变!
(A)将这个二进制数中(即 1111 1000),除了符号位,其余位置按位取反,得 1000 0111
(B)+ 1,得到 1000 1000
总结:
-1 后,再取反 和 取反后,再+1 的效果是一样的。
这就和 -(3-1) 和 (-3 +1) 是一个道理。
因此,可以直接记住方法2即可,因为原码->补码也是先取反后+1,刚好反过来也是一样,便于记忆。
四、sizeof关键字的使用
关键字不是函数,不需要引入头文件,可以直接使用, 作用是求一个数在内存中占用的大小,单位是字节.
注意:C语言是不规定数据类型的大小的,具体是根据系统来决定的,不同的系统可能的长度不一样.
chenys@chenys-pc:~/桌面/c$ cat c.c
#include<stdio.h>
int main(){
int a; //整形
long b; //长整形
short c; //短整型
_Bool d;
short int e;
long long f; //在32系统下是4个字节, 在64位的linux系统是8个字节,64位的windows系统是4个字节
double g;
printf("int=%ld\n",sizeof(a));
printf("long=%ld\n",sizeof(b));
printf("short=%ld\n",sizeof(c));
printf("_Bool=%ld\n",sizeof(d));
printf("short int=%ld\n",sizeof(e));
printf("long long=%ld\n",sizeof(f));
printf("double=%ld\n",sizeof(g));
return 0;
}
chenys@chenys-pc:~/桌面/c$ ./c
int=4
long=8
short=2
_Bool=1
short int=2
long long=8
double=8
chenys@chenys-pc:~/桌面/c$
4.1 有符号和无符号的区别
有符号:最高位表示符号位,0是正数,1是负数
无符号:最高位是数的一部分,都是正数,最小是0.
int a ;//定义了一个有符号的int
unsigned int b ;// 定义了一个无符号的int, 占用的字节大小和int一样,这是取值范围不一样
4.2 整数的溢出
当超过一个整数能够存放的最大范围是,整数会溢出, 有符号的溢出会导致符号位溢出, 有可能会造成数据的正负值发生改变.
如果是无符号的溢出, 会造成高位丢失, 例如:
#include<stdio.h>
int main(){
unsigned int a = 0XFFFFFFFF;//也就是32位1
unsigned int b = a + 1;
printf("%u\n",b);// b = 0
}
五、大端对齐与小端对齐
计算机中最小的内存单位是BYTE(字节) , 一个大于BYTE的数据类型在内存中存放的时候是有先后顺序的.
内存在划分地址是左高右低的,如果变量存储方式和内存划分方式一样那就是小端对齐模式,也就是高内存地址放整数的高位,低内存地址存放整数的低位,这种方式叫做倒着放,术语叫做小端对齐, x86和ARM都是小端对齐的.
高内存地址存放整数的低位,低内存地址存放整数的高位,这种方式叫做正着放,术语叫做大端对其,很多unix服务器的CPU都是大端对齐的, 例如:
#include <stdio.h>
int main()
{
// int分4个字节,每2段16进制数为一个字节,左边是高地址,右边是低地址
int a = 0xaabbccdd;
unsigned char *p = (char *)&a;
printf("%x\n", *p); //dd
printf("%x\n", *(p + 1)); //cc
printf("%x\n", *(p + 2)); //bb
printf("%x\n", *(p + 3)); //aa
}
结果是先打印dd,后打印aa, 而dd是变量的低位地址,p指针指向的是低位地址, 而p指针+1/+2/+3是地址升高的操作,说明和变量的存储方向一致,都是由低到高的过程,所以这种模式就是小端对齐模式.
或者如下例子也能说明是小端对齐
#include <stdio.h>
int main()
{
int a = 5; // 对应二进制是高位3个字节是8个0,底位1个字节才存放5的值
char *p = (char *)&a;
printf("%d\n", p[0]); // 5
printf("%d\n", p[1]); // 0
printf("%d\n", p[2]); // 0
printf("%d\n", p[3]); // 0
// 下面指针递增,表示内存地址从小到大变化,对应的数值也是从低位到高位,表示小端对齐
printf("%d\n", *p); // 5
printf("%d\n", *(p + 1)); // 0
printf("%d\n", *(p + 2)); // 0
printf("%d\n", *(p + 3)); // 0
}
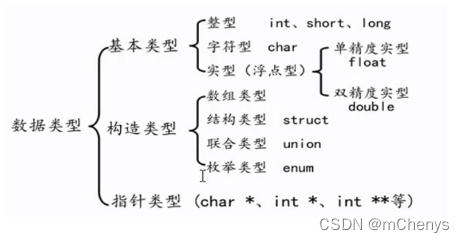
六、数据类型分类
七、char类型
‘单引号引起来的就是char的常量,比如’a’
“双引号引起来的就是字符串常量,比如"a”
char 在内存中占1个BYTE, 由于C语言中没有BYTE类型, 所以可以用char来代替.这点和java不一样,java的char是占2个字节的.
unsigned char 的取值范围: 0-255
char 的取值范围:-128 ~ 127
#include<stdio.h>
int main(){
char a = 10;
char b = 'a';
printf("%d\n",a); //10 char的本质是一个BYTE大小的整数
printf("%u\n",b); //97 对应的其实是a的ASCII码
printf("%c\n",97); //b %c是直接输出字符
return 0;
}
7.1 格式说明符中的类型
(1)%ld表示数据按十进制有符号长型整数输入或输出。
(2)%d表示数据按十进制有符号整型数输入或输出。
(3)%u表示数据按十进制无符号整型数输入或输出。
| 字符 | 对应数据类型 | 含义 |
|---|---|---|
| d | int | 接受整数值并将它表示为有符号的十进制整数 |
| hd | Short int | 短整数 |
| hu | Unsigned short int | 无符号短整数 |
| o | unsigned int | 无符号8进制整数 |
| u | unsigned int | 无符号10进制整数 |
| x / X | unsigned int | 无符号16进制整数,x对应的是abcdef,X对应的是ABCDEF |
| f | float或double | 单精度浮点数或双精度浮点数 |
| e | / E double | 科学计数法表示的数,此处"e"的大小写代表在输出时用的“e”的大小写 |
| c | char | 字符型,可以把输入的数字按照ASCII码相应转换为对应的字符 |
| s | / S char * / wchar_t * | 字符串。输出字符串中的字符直至字符串中的空字符(字符串以’\0‘结尾,这个’\0’即空字符) |
| p | void * | 以16进制形式输出指针 |
| % | % | 输出一个百分号 |
printf附加格式
| 字符 | 含义 |
|---|---|
| l | 附加在d,u,x,o,ld前面,表示长整数 |
| - | 左对齐 , 符号后面接数字 |
| m | (代表一个整数) |
| 0 | 将输出的前面补上0直到占满指定列宽(0后面的数字代表列宽)为止不可以搭配使用- |
| N(代表一个整数) | 宽度至少为n位不够以空格填充 |
八、浮点类型
3.14这个数就是一个浮点常量, 3f是一个浮点类型的常量
float a;//定义一个浮点类型的小数变量, 名字是a ,默认保留小数点6位.
double b;//定义了一个double类型的变量,名字是b
long double c ;//定义了一个long double类型的变量,名字叫c
注意:不能使用整形的输出转移符来输出一个浮点数,必须使用%f或者%lf.
8.1 小数的四舍五入
#include<stdio.h>
int main(){
double a = 4.5;
int b = a + 0.5;
a = b;
printf("%f\n",a); //5.000000
printf("%lf\n",a); //5.000000
}
九、联合体
联合union是一个能在同一个存储空间存储不同数据类型的类型,联合体所占的内存长度等于其最长成员的长度,也有叫做共同体,联合体虽然可以有多个成员,但同一时间只能存放其中一种, 每个成员的修改,都会导致其他成员的修改。
#include<stdio.h>
union student
{
int a;
char b;
short c;
int d;
};
int main()
{
union student s;
printf("%u\n",sizeof(s)); //4, 因为最大成员就是int类型
s.a = 0x12345678; //给s.a赋值为十六进制的0x12345678
printf("s.a= %x\n",s.a);
s.b = 0; //修改了b, 由于b占了1/4的int , 所以会把s.a的值修改了
printf("s.a= %x\n",s.a); //0x12345600
s.d = 0; //修改s.d,也会影响到s.a, 由于s.d是int ,所以s.b的值全部被修改了
printf("s.a= %x\n",s.a); //0
return 0;
}
十、枚举enum
可以使用枚举声明代表整数常量的符号名称,关键字enum创建一个新的枚举类型,实际上枚举内的成员都是int类型的常量. 默认第一个成员的值是0, 后面的成员的值总是等于其上一个成员的值+1, 当然你也可以定义的时候手动赋予一个值, 那么该值后面的成员的值就是当前成员的值+1
#include<stdio.h>
//定义一个颜色枚举
enum color {red = 100,green,yellow=10,blue,white,black};
//定义一个性别枚举
enum sex {man,woman};
struct student
{
char name[10];
int age;
int sex;
};
int main()
{
enum color c = red; // 枚举类型的变量可以这样赋值
printf("c=%d,green=%d\n",c,green); // 也可以直接使用 c=100,green=101
struct student s;
s.sex = man; // 直接使用枚举赋值给int类型的变量,因为枚举的成员就是int类型的常量
printf("sex=%d\n",s.sex); // sex=0
return 0;
}
既然枚举的成员是int类型的常量, 那就不能对其成员取地址,编译器回报红
red是int类型的常量,等效于CPU的立即数, 是不能取地址的, 而字符串常量是存在内存中的,所以是可以取地址的.

十一、typedef定义类型
typedef是一种高级数据特性,他能使某一类型创建自己的名字, 说白了就是给已有类型取个别名.
typedef unsigned char BYTE
- 与#define不同,typedef仅限于数据类型,而不是表达式或具体的值,
- typedef是编译器处理的,而不是预编译指令
- typedef比#define灵活
- 使用typedef可以增加程序的可移植性
#include<stdio.h>
typedef char* STRING; // 给char * 取别名
typedef unsigned char BYTE; // 给char 取别名
// 定义结构体, 结构体后续文章会介绍, 可以把它理解成一种数据类型
struct student
{
// 在结构体中使用别名
STRING name;
BYTE age;
};
typedef struct student Student; // 结构体类型也可以取别名
int main()
{
Student s = {"abc", 12}; // 使用别名创建结构体
STRING name = "hello world";
BYTE age = 20;
s.name = name;
s.age = age;
printf("name=%s,age=%d\n",s.name,s.age);
return 0;
}
十二、运算符
12.1 ++和–运算符
++ 表示自增, 分为前置++和后置++
– 表示自减, 分为前置–和后置–
如果++和-- 存在表达式,那么前置和后置的意义是不一样的,比如int b = ++a 和 int b = a++ 得到的b的值是不一样的.前面的b会比后面的大1.
#include<stdio.h>
int main()
{
int a = 0;
int b = a++;
printf("a=%d,b=%d\n",a,b); // a=1 , b =0
return 0;
}
12.2 逗号运算符
逗号表达式先求逗号左边的值,然后求右边的值,整个语句的值是逗号右边的值。
int a = 2;
int b = 3;
int c = 4;
int d = 5;
int i = (a = b, c + d); //结果是9 也就是逗号右边的值
12.3 运算符优先级

12.4 强制转化运算符
两个整数计算的结果还是整数
浮点数与整数计算的结果是浮点数
浮点数与浮点数计算的结果还是浮点数
int a =5;
double d = (double)a; //表示强制把a强制位double类型,结果就是5.000000
12.5 关系运算符
在C语言中0代表假,非0代表真
< ,<=,>,>=,==,!= //前4个的优先级相同且大于后2个的优先级, 后2个的优先级相同.
12.6 逻辑运算符
&&(条件与)
当运算符左右都是真的时候,那么整个表达式的结果为真
只要左右有一个值为假,那么整个表达式的结果为假,并且左边为假时可以不用考虑右边了。
||(条件或)
当运算符左右只要有一个值是真的时候,那么整个表达式的结果为真
除非左右两个值都是假,那么整个表达式的结果为假,并且左边为真时可以不用考虑右边了。
十三、语句的使用
13.1 if语句
单分支,当条件是真的时候,复合语句才能被执行,如果条件为假的时候,复合语句不执行
if (条件)
{
//复合语句
}
双分支,如果条件为真,那么执行复合语句1,否则执行复合语句2
if (条件)
{
复合语句1
}
else
{
复合语句2
}
多重if,当有多个else的时候,else总是和上方最近的那个if语句配对。
if (条件1)
{
复合语句1
}
else if (条件2)
{
复合语句2
}
else if (条件3)
{
复合语句3
}
else
{
复合语句4
}
13.2 switch语句
switch (i)
{
case 0:
printf("i = 0\n");
break;//跳出switch的复合语句块
case 1:
printf("i = 1\n");
break;
case 2:
printf("i = 2\n");
break;
default://如果有所条件都不满足,那么执行default语句
printf("error\n");
}
switch与if的用法区别:
当条件很复杂,一个条件中有&&,|| ,!存在,那么用if语句,如果条件很简单,但分支很多,那么适合用switch。
13.3 三目运算符
先求?左边的条件,如果条件为真,那么等于:号左边的值,否则等于:号右边的值
int i = -8;
int x = (i < 0) ? -i: i; // x=8
//求最大值
int c = (a > b) ? a : b;
12.4 无条件跳转goto语句
无条件跳转goto,不建议使用goto语句,goto语句会使你的程序可读性变的很差
#include<stdio.h>
int main(){
goto end; //无条件跳转到end去执行
int a=0;
printf("a=%d",a);
end: //标号
return 0;
}
13.5 while语句
while(条件),如果条件为真,循环继续,条件为假,循环结束
while (1)//是死循环的写法
#include<stdio.h>
int main(){
int a ;
while(a!=10){
a++;
printf("a=%d",a);
}
return 0;
}
13.6 continue与break语句
循环遇到continue语句,不再执行continue下面代码,而是直接返回到循环起始语句处继续执行循环;
循环遇到break语句,立刻终断循环,循环结束。
13.7 do-while与while语句的区别
对于do while来讲,循环的复合语句至少可以被执行一次, 它是先循环, 在判断条件;
对于while来讲,有可能复合语句一次执行机会都没有, 它是先判断条件,再决定是否循环。
do
{
条件成立时执行的复合语句
}while (条件);
13.8 for语句
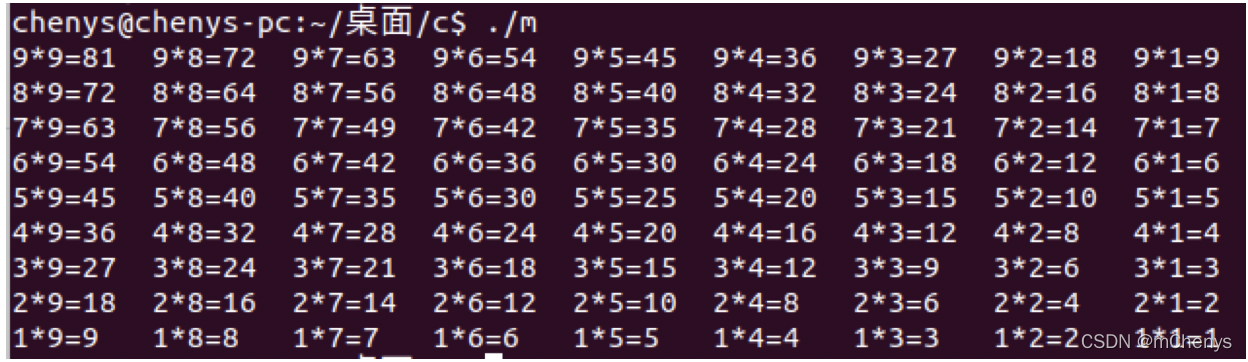
for语句在循环的时候可以明确的知道循环的次数
#include<stdio.h>
int main(){
int i,j;
for(i=9;i>0;i--)
{
for(j=9;j>0;j--)
{
printf("%d*%d=%d\t",i,j,i*j);
}
printf("\n");
}
return 0;
}
上面输出的结果是99乘法表:
13.9 综合练习
1) 求整数位数
#include<stdio.h>
int main()
{
int a;
scanf("%d",&a); // 这个函数式读取控制台输入的值,&a表示取地址,后续文章会介绍
int count=0;
while(a>0)
{
count++;
a/=10;
}
if(count ==0)
{
count =1;
}
printf("%d个\n",count);
return 0;
}
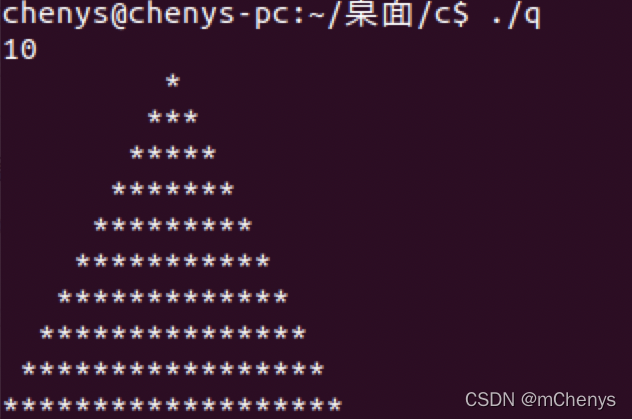
2) 使用*号在控制台输出等腰三角形
#include<stdio.h>
int main()
{
int num;
scanf("%d",&num); // 控制三角形的行数
int i,j;
for(i=1;i<=num;i++) //外循环控制行数
{
int a;
for(a=0;a<num-i;a++) //空格数=总行数-i
{
printf(" ");
}
for(j=0;j<2*i-1;j++)
{
printf("%s","*"); //*数=2*行数-1
}
printf("\n");
}
return 0;
}
如下是一个10行的等腰三角形效果图














 2388
2388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









