







前言
在进行Intel oneAPI异构计算学习之后,又有了交叉熵并行实现的需求,遂以此记录。
实现
这里主要是利用Intel的JupyterLab在CPU和GPU当中进行计算,通过CPU计算验证GPU并行计算的结果,并统计时间和效率。
交叉熵
交叉熵(cross entropy)在神经网络当中经常被用作损失值,要说清楚交叉熵的概念,还需要从熵说起。
熵
熵是数学中用来量化不确定性的概念,即不确定性有多大,对应熵有一个多大的值。以掷骰子为例,一个六面的骰子如果每一面都是6点,那么掷骰子得到6的概率就是100%,而得到其他点数的概率为0,因此我们对结果十分确定,此时熵为0;
当骰子6面各不相同 ,掷骰子的结果均匀分布在1、2、3、4、5、6六点当中,此时熵最大,可以类比气体混合和固体溶解等自然界的熵增过程。
交叉熵的概念
熵是表达不确定性的概念,那么交叉熵是描述实际输出的可能性与预测可能性之间的匹配程度的指标。也就是预测结果和实际输出结果的概率分布越相近,其交叉熵越低。
反之两个概率差异越大,其交叉熵越大。
交叉熵计算
对于一个二维输入x[M][N] ,M代表分类数,N为特征数,计算其交叉熵作为损失值loss[N]。
Log Softmax:
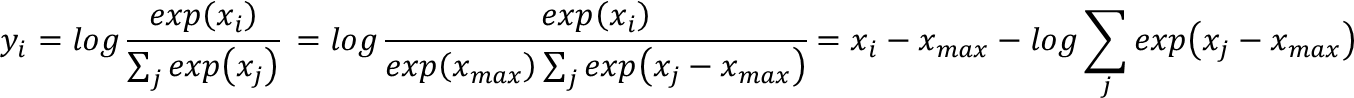
Select:

Update:

整体计算过程如下图所示:
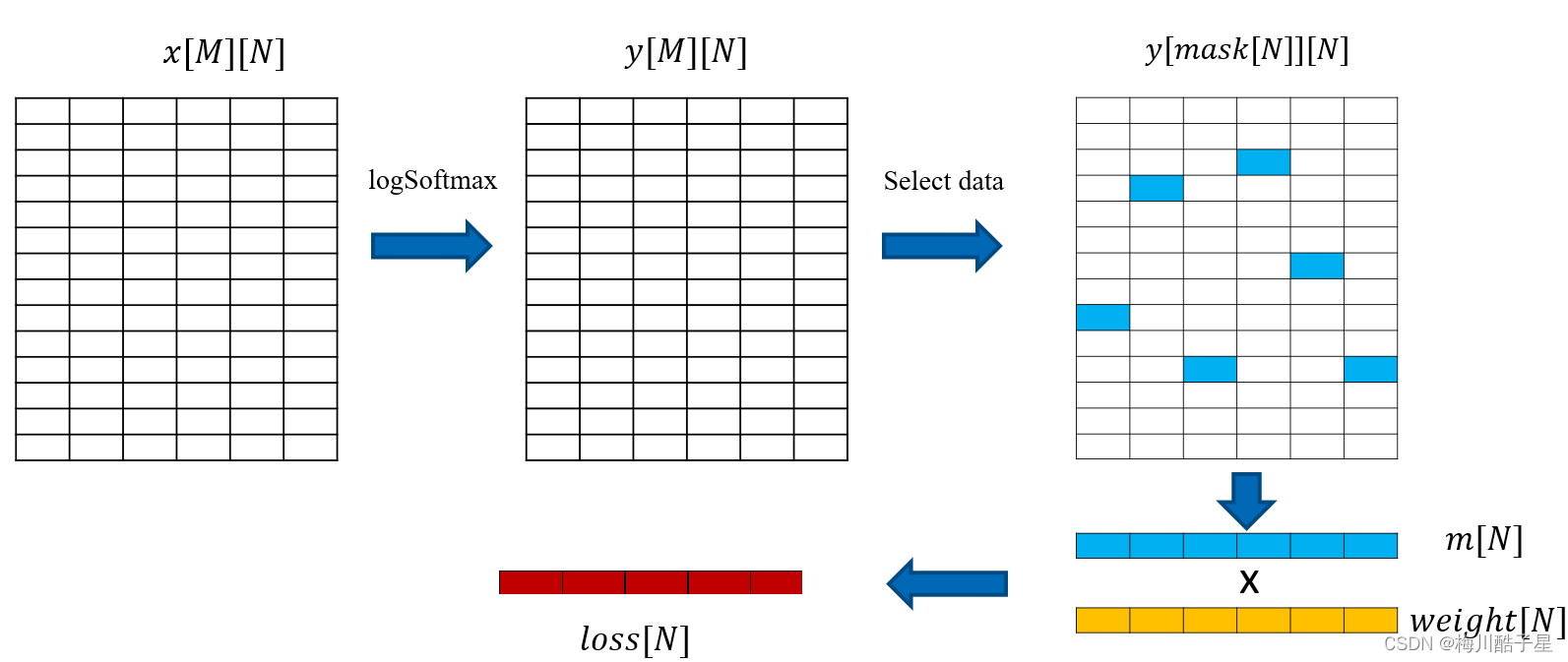
任务目标
- 输入一个三维矩阵x[K][M][N],K=128, M=32, N=8192, 其中K为batchsize,M为category,N为feature, 二维坐标数组mask[K][N], 权重数组weight[K][N]。
- K维度相互独立,在每一个面做上述二维的cross entropy计算。
- 最终结果为二维数组loss[K][N]。
- 设计相应的GPU程序,要求结果和CPU计算结果误差绝对值在0.001之内。
- 用时间来衡量程序的性能,越小越好,给出相关的实验数据和分析。
实现
根据上面的计算过程,以下代码包括两个主要部分,一个是CPU交叉熵计算,另一部分是GPU交叉熵计算,
详细步骤见下方代码以及注释部分。
%%writefile lab/cross_entropy.cpp
#include<iostream>
#include<chrono>
#include<cmath>
#include<CL/sycl.hpp>
#define random_float() (rand() / double(RAND_MAX));
using namespace std;
using namespace sycl;
// Input size
constexpr int K = 128;
constexpr int M = 2048;
constexpr int N = 128;
constexpr int iterations = 10;
//GPU计算
float gpu_kernel(float* X, int* mask, float* weight, float* loss, queue& q) {
float duration = 0.0;
auto e = q.submit([&](handler& h) {
//对于该计算,K维度和N维度相互独立,这里也用K*N作为并行化的range
h.parallel_for( K*N, [=](auto& idx) {
//K为行,下面是行列值的计算
int row = idx / N ;
int col = idx % N ;
float exp_sum = 0.0;
for (int i = 0; i < M; ++i) {
exp_sum += exp(X[row * M * N + i * N + col]); //计算每一个M列的exp值之和
}
int mask_id = mask[row * N + col]; //选择K,N二维列表对应掩膜值
loss[row * N + col] = weight[row * N + col] * log(exp(X[row * M * N + mask_id * N + col]) / exp_sum);//找出对应的xi值,计算yi值,并乘以对应的权重值得到loss值
});
});
e.wait();//阻塞等等该计算完成
// 获取GPU kernal的开始和介绍时间戳之差(ns),转换成ms
duration = (e.get_profiling_info<info::event_profiling::command_end>() - e.get_profiling_info<info::event_profiling::command_start>()) / 1000.0f / 1000.0f;
return duration;
}
//CPU计算
float cpu_kernel(float* X, int* mask, float* weight, float* loss) {
double duration = 0.0;
chrono::high_resolution_clock::time_point s, e;
s = chrono::high_resolution_clock::now();//获取运算开始时间戳
for (int i = 0; i < K; ++i) {
for (int j = 0; j < N; ++j) {
float exp_sum = 0.0;
for (int k = 0; k < M; ++k) {
exp_sum += exp(X[i * M * N + k * N + j]);//计算每一个M列的exp值之和
}
//计算过程与GPU相同
int mask_id = mask[i * N + j];
loss[i * N + j] = weight[i * N + j] * (log(exp(X[i * M * N + mask_id * N + j]) / exp_sum));
}
}
e = chrono::high_resolution_clock::now();
duration = chrono::duration<float, milli>(e - s).count();//计算CPU时间差(ms)
return duration;
}
//对比CPU和GPU计算结果,值相差超过0.001认为计算错误
int verify(float* data_host, float* data_device) {
int errCount = 0;
for (int i = 0; i < K * N; ++i) {
if (fabs(data_host[i] - data_device[i]) > 0.001) ++errCount;
}
return errCount;//返回统计的错误的值数量
}
void run(queue& q) {
//在主机当中申请存储数据的变量
float* X_cpu = malloc_host<float>(K * M * N, q);//输入变量,大小为K*M*N
int* mask_cpu = malloc_host<int>(K * N, q); //计算维度在K*N是独立的,因此这两个变量是K*N
大小
float* weight_cpu = malloc_host<float>(K * N, q);
//申请GPU当中变量
float* X_gpu = malloc_device <float>(K * M * N, q);
int* mask_gpu = malloc_device <int>(K * N, q);
float* weight_gpu = malloc_device <float>(K * N, q);
//用UMS存储GPU计算结果,便于获取
float* loss_gpu = malloc_shared <float>(K * N, q);
//CPU计算结果
float* loss_cpu = malloc_host<float>(K * N, q);
//随机生成输入值
for (int i = 0; i < K * M * N; ++i) {
X_cpu[i] = random_float();
}
//初始化中间变量
for (int i = 0; i < K * N; ++i) {
loss_gpu[i] = 0.0;
loss_cpu[i] = 0.0;
mask_cpu[i] = i % M;
weight_cpu[i] = random_float();
}
//将变量值拷贝到GPU当中
q.memcpy(X_gpu, X_cpu, sizeof(float) *K * M * N).wait();
q.memcpy(mask_gpu, mask_cpu, sizeof(int) * K * N).wait();
q.memcpy(weight_gpu, weight_cpu, sizeof(float)* K * N).wait();
float duration_cpu = 0.0;
float duration_gpu = 0.0;
//统计多次计算耗时,求平均值
int warmup = 10;
for (int i = 0; i < iterations / 2 + warmup / 2; ++i) {
float duration = cpu_kernel(X_cpu, mask_cpu, weight_cpu, loss_cpu);
if (i >= warmup / 2) duration_cpu += duration;
}
duration_cpu /= iterations / 2;
for (int i = 0; i < iterations + warmup; ++i) {
float duration = gpu_kernel(X_gpu, mask_gpu, weight_gpu, loss_gpu, q);
if (i >= warmup) duration_gpu += duration;
}
duration_gpu /= iterations;
printf("Cross Entropy Input Size: K: %d, M: %d, N: %d, Total : %d\n"
"GPU time: %lf (ms)\n"
"CPU time: %lf (ms)\n",
K, M, N, K * M * N, duration_gpu, duration_cpu);
int errCount = 0;
errCount = verify(loss_cpu, loss_gpu);
printf("%d errors in loss_gpu\n", errCount);//检验结果
// free all memory in host
free(loss_cpu, q);
free(X_cpu, q);
free(mask_cpu, q);
free(weight_cpu, q);
// free all memory in device
free(loss_gpu, q);
free(X_gpu, q);
free(mask_gpu, q);
free(weight_gpu, q);
}
int main() {
//指定enable_profiling()属性
auto propList = property_list{ property::queue::enable_profiling() };
//GPU选择器
queue my_gpu_queue(gpu_selector{}, propList);
run(my_gpu_queue);
return 0;
}
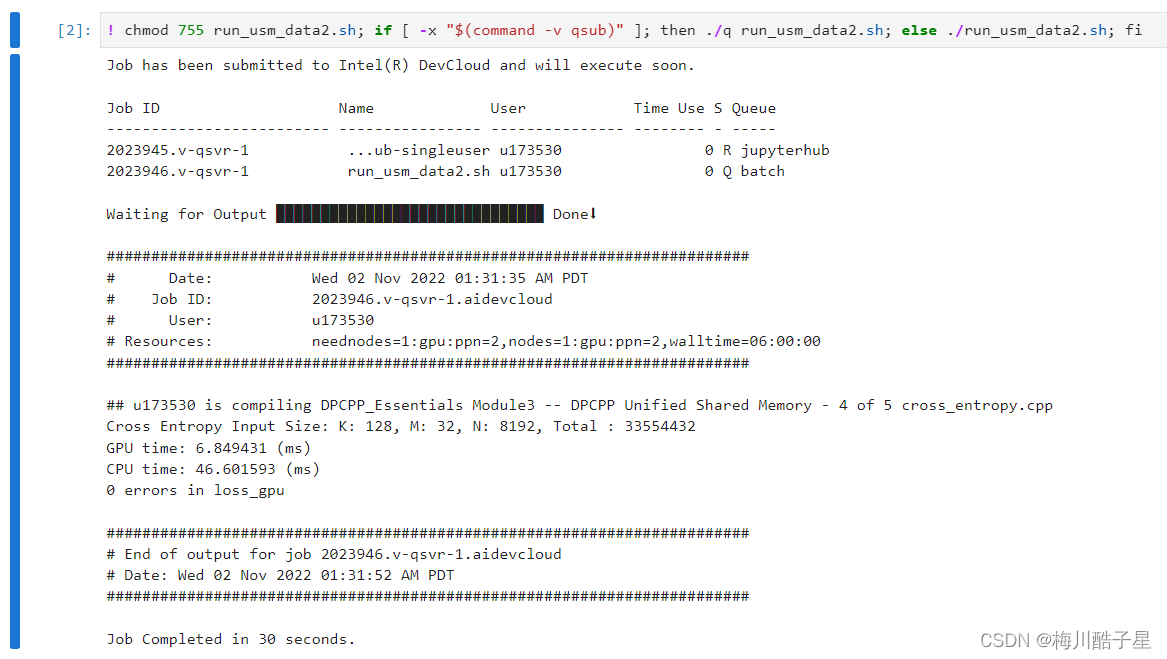
运行结果
CPU运算平均耗时约47ms,GPU耗时约7ms,加速比约为7。
改进优化
在上面的步骤当中,我们可以看出,输入的维度是K*M*N,无相关性的维度是K*N,因此在K*N维度上可以直接进行并行化,这在K和N较大时其加速比较大,但是如果M较大的话,GPU并行程度低,其加速比就会降低。
在对M维计算时,其exp值被重复计算了两次,并且求和过程没有进行并行化,因此这些地方都可以进行优化,后面再继续更新。














 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









