






英特尔oneAPI简介
Intel oneAPI是一个跨行业、开放、基于标准的统一的编程模型,旨在提供一个适用于各类计算架构的统一编程模型和应用程序接口。也就是说,应用程序的开发者只需要开发一次代码,就可以让代码在跨平台的异构系统上执行,底层的硬件架构可以是CPU、GPU、FPGA、神经网络处理器等。由此可见,使用oneAPI编写的程序既可以利用加速器提高程序性能,又具有可移植性。
一个oneAPI运行环境由一个主机和一系列设备组成。主机通常是一个多核CPU,而设备是一个或多个GPU、FPGA,或是其他加速器。主机的处理器也可以进行并行计算。
oneAPI为一系列的数据并行加速器提供了一个通用的开发者接口(见下图)。
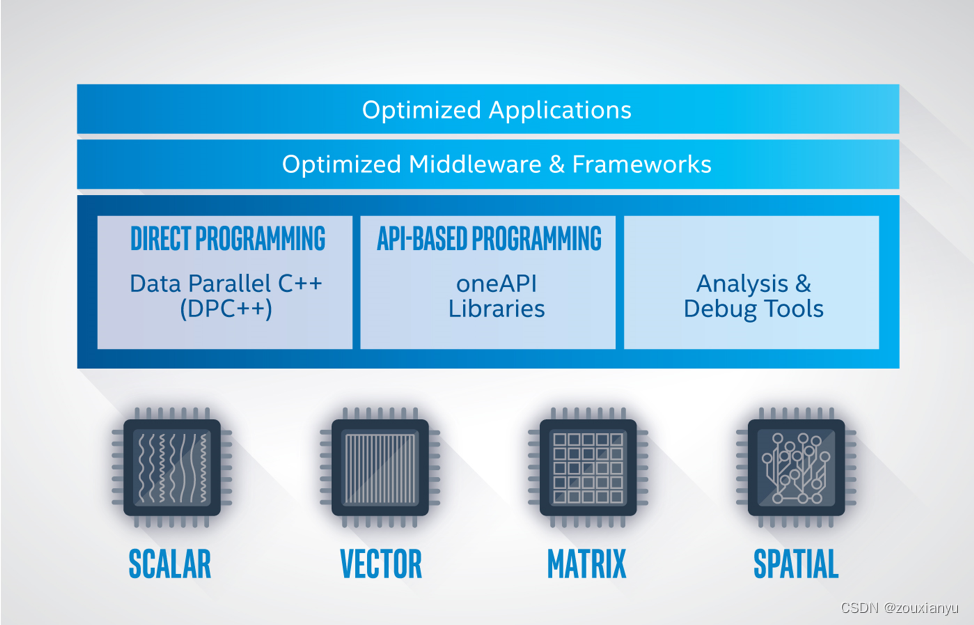
英特尔DevCloud简介
英特尔DevCloud是一个可以在线开发oneAPI程序的平台,DevCloud除了预装了oneAPI开发套件之外,还提供了有关oneAPI的教程,并且免费提供GPU、FPGA等加速器资源供我们使用,因此我们可以很方便地在DevCloud上学习oneAPI知识,并测试我们自己开发的oneAPI程序。
问题描述
高斯消元法
高斯消元法(Gaussian elimination)是求解线性方阵组的一种算法,它也可用来求矩阵的秩,以及求可逆方阵的逆矩阵。它通过逐步消除未知数来将原始线性系统转化为另一个更简单的等价的系统。它的实质是通过初等行变化(Elementary row operations),将线性方程组的增广矩阵转化为行阶梯矩阵(row echelon form)。
算法分析
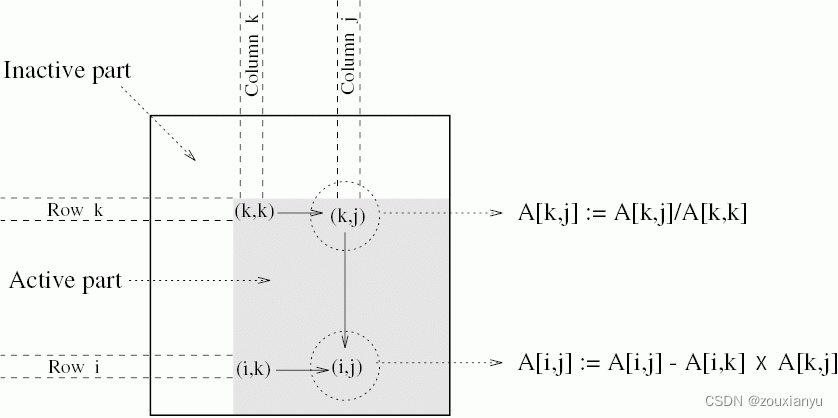
高斯消去的计算模式如上图所示,在第k步时,首先将第k行除以A[k,k],此时A[k,k] = 1,然后再将第k行到第n行减去第一行乘以A[i,k],此时位于A[k,k]下方的所有元素全部为0。总共进行n步操作后,矩阵A就变成了对角线元素全为1的上三角矩阵。
算法伪代码如下:
procedure LU (A)
begin
for k := 1 to n do
for j := k+1 to n do
A[k, j ] := A[k, j]/A[k, k];
endfor;
A[k, k] := 1.0;
for i := k + 1 to n do
for j := k + 1 to n do
A[i, j ] := A[i, j ] − A[i, k]×A[k, j];
endfor;
A[i, k] := 0;
endfor;
endfor;
end LU算法设计
串行算法
串行算法的代码与伪代码类似,具体代码如下:
for (int k = 0; k < n; k++) {
for (int j = k + 1; j < n; j++) {
m[k][j] = m[k][j] / m[k][k];
}
m[k][k] = 1;
for (int i = k + 1; i < n; i++) {
for (int j = k + 1; j < n; j++) {
m[i][j] = m[i][j] - m[i][k] * m[k][j];
}
m[i][k] = 0;
}
}并行算法
观察串行算法,可以发现在第k步中包含两个部分,第一个部分是一个1重循环,作用是将第k行每个元素都除以A[k,k],第二个部分是一个2重循环,作用是将右下角的k*k大小的矩阵的第一列全部消成0。我们可以对这两个部分进行并行化处理。
基于buffer实现并行算法
首先我们创建一个任务队列,用于给加速器提交任务:
queue q;我们还可以在创建队列时,将队列绑定到不同设备上,例如:
- queue(cpu_selector{});
- queue(gpu_selector{});
可以由此指定我们的并行代码要在什么设备上执行,我们不需要了解GPU/FPGA等加速器具体的编程语言,就可以将计算任务以统一的编程方式卸载到这些加速器上。
然后创建一个n*n大小的矩阵:
const int n = 1024;
buffer<float, 2> buf(range(n, n));针对第一个部分,我们可以使用parallel_for语句将其卸载到加速器上并行计算,具体代码如下:
q.submit([&](handler& h) {
accessor m{ buf, h, read_write };
h.parallel_for(range(n - k), [=](auto idx) {
int j = k + idx;
m[k][j] = m[k][j] / m[k][k];
});
});针对第二个部分,我们仍然可以使用parallel_for,不过需要注意的是,这里使用的不再是一维的数据划分,而是二维的数据划分,具体代码如下:
q.submit([&](handler& h) {
accessor m{ buf, h, read_write };
h.parallel_for(range(n - (k + 1), n - (k + 1)), [=](auto idx) {
int i = k + 1 + idx.get_id(0);
int j = k + 1 + idx.get_id(1);
m[i][j] = m[i][j] - m[i][k] * m[k][j];
});
});除此之外,还有一点需要注意,由于A[i,k]元素在此部分中会被所有线程使用,因此不能在此阶段置0,需要等这部分全部执行完成之后再置0。因此需要补充第三个阶段,将右下角k*k大小的矩阵的第一列除A[k,k]以外的元素置0,具体代码如下:
q.submit([&](handler& h) {
accessor m{ buf, h, read_write };
h.parallel_for(range(n - (k + 1)), [=](auto idx) {
int i = k + 1 + idx;
m[i][k] = 0;
});
});在最外层n重循环执行完之后,其实只是将计算任务下发到了加速器, 这些计算任务不一定真的执行完了,因此我们需要手动调用q.wait(),等待任务队列中所有任务都执行完毕,该算法再结束。
完整代码如下:
void gauss_oneapi(buffer<float, 2>& buf, queue& q) {
device my_device = q.get_device();
std::cout << "Device: " << my_device.get_info<info::device::name>() << std::endl;
int n = buf.get_range()[0];
for (int k = 0; k < n; k++) {
q.submit([&](handler& h) {
accessor m{ buf, h, read_write };
h.parallel_for(range(n - k), [=](auto idx) {
int j = k + idx;
m[k][j] = m[k][j] / m[k][k];
});
});
q.submit([&](handler& h) {
accessor m{ buf, h, read_write };
h.parallel_for(range(n - (k + 1), n - (k + 1)), [=](auto idx) {
int i = k + 1 + idx.get_id(0);
int j = k + 1 + idx.get_id(1);
m[i][j] = m[i][j] - m[i][k] * m[k][j];
});
});
q.submit([&](handler& h) {
accessor m{ buf, h, read_write };
h.parallel_for(range(n - (k + 1)), [=](auto idx) {
int i = k + 1 + idx;
m[i][k] = 0;
});
});
}
q.wait();
}基于USM实现并行算法
USM的全称是Unified Shared Memory,程序员可以不管数据是处在主机的内存当中还是加速器的内存当中,仍然使用C/C++中的指针来访问数据,它给程序员提供了一个统一的内存视图(如下图所示),有助于程序员更快地将现有C/C++程序移植到DPC++。

但是和buffer+accessor的访问方式相比,如果对数据依赖解决不正确,可能会存在竞争,导致计算结果错误。
在申请矩阵内存时,我们可以使用malloc_shared函数:
float* buf = (float *)malloc_shared(n * n * sizeof(float), q);在访问内存时,则不需要使用accessor,直接访问buf即可。需要注意由于不再使用accessor,因此oneAPI不能推断出数据依赖,所以需要程序员手动指出数据依赖,其中有3种方式:
- q.wait()
- in_order队列属性
- h.depends_on(e)方法
由于本算法中所有kernel都是依次执行的,因此在创建队列时指定in_order属性比较方便。
queue q{property::queue::in_order()};具体算法如下:
void gauss_oneapi(float* m, int n, queue& q) {
device my_device = q.get_device();
std::cout << "Device: " << my_device.get_info<info::device::name>() << std::endl;
for (int k = 0; k < n; k++) {
q.submit([&](handler& h) {
h.parallel_for(range(n - k), [=](auto idx) {
int j = k + idx;
m[k*n+j] = m[k * n + j] / m[k * n + k];
});
});
q.submit([&](handler& h) {
h.parallel_for(range(n - (k + 1), n - (k + 1)), [=](auto idx) {
int i = k + 1 + idx.get_id(0);
int j = k + 1 + idx.get_id(1);
m[i * n + j] = m[i * n + j] - m[i * n + k] * m[k * n + j];
});
});
q.submit([&](handler& h) {
h.parallel_for(range(n - (k + 1)), [=](auto idx) {
int i = k + 1 + idx;
m[i * n + k] = 0;
});
});
}
q.wait();
}
实验设计
串行算法与基于buffer实现的并行算法的性能对比
为了对比串行算法与并行算法的性能差异,设置了不同规模的矩阵,分别测量在不同问题规模下,串行算法与并行算法的性能表现。
基于buffer实现的并行算法与基于USM实现的并行算法的性能对比
为了对比基于buffer实现的并行算法与基于USM实现的并行算法之间的性能差异,也应测量在不同问题规模下各算法的性能表现。
时间测量方法
时间测量
我们使用C++11标准中的std::chrono::high_resolution_clock测量时间,而不使用平台特定的API(如Windows平台的QueryPerformanceCounter、Linux平台的clock等),这样可以增加程序的可移植性。
除此之外,还应使用多次测量求平均的方式保证运行时间测量的准确性。
auto start = std::chrono::high_resolution_clock::now();
// your code
auto end = std::chrono::high_resolution_clock::now();预热
为了防止初始化操作、cache等其他因素影响算法执行时间的测量,因此在开始计时之前,先让算法运行一次,第一次不计入运行时间,然后再运行k次,以这k次运行的平均时间作为算法执行时间。
结果分析
测试环境
性能测试部分全部在DevCloud平台上完成。
GPU型号:Intel(R) UHD Graphics P630
CPU型号:Intel(R) Xeon(R) E-2176G CPU @ 3.70GHz
串行算法与基于buffer实现的并行算法的性能对比
| 问题规模n | 串行算法 | GPU并行算法 |
| 16 | 0.470433 | 1.42439 |
| 32 | 0.812061 | 2.292 |
| 64 | 6.41777 | 4.03059 |
| 128 | 50.598 | 5.60625 |
| 256 | 406.665 | 7.42548 |
| 512 | 3236.67 | 75.7885 |
| 1024 | 25885.7 | 590.462 |
当问题规模n非常小的情况下,串行算法的效率是最高的。因为如果我们使用GPU做并行化,那么就需要将矩阵从主机的内存复制到GPU的内存中,然后再让GPU开始计算,等GPU计算完之后,还要把矩阵再从GPU的内存复制到主机的内存中。在问题规模n非常小的情况下,这些额外的开销占比是非常大的,因此在此时GPU版本算法要比串行算法的执行时间更长。
当问题规模n比较大时,GPU并行算法耗时更短,比较符合预期效果。
基于buffer实现的并行算法与基于USM实现的并行算法的性能对比
| 问题规模n | GPU并行算法(buffer) | GPU并行算法(USM) |
| 16 | 1.42439 | 1.59059 |
| 32 | 2.292 | 2.02017 |
| 64 | 4.03059 | 2.9549 |
| 128 | 5.60625 | 4.81008 |
| 256 | 7.42548 | 5.91026 |
| 512 | 75.7885 | 89.6216 |
| 1024 | 590.462 | 616.103 |
由上表可以看出,基于buffer的GPU并行算法与基于USM的GPU并行算法之间性能差异不大,因此程序员可以使用USM更快地将现有C/C++程序移植到DPC++,并且相比于使用buffer+accessor,不会带来很多额外的性能开销。
代码
zouxianyu / oneAPI gaussian elimination · GitCode















 4047
4047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









