







查询前几的问题
- 目标:查询每天消费前2的数据信息
- 数据源样式:(表名:sale)

- 输出

- 方法1:使用自连接
SELECT a.姓名, a.日期, a.消费 FROM sale a LEFT JOIN sale b ON a.日期 = b.日期 AND a.消费 < b.消费 GROUP BY a.姓名, a.日期, a.消费 HAVING count( b.姓名 ) < 2 ORDER BY a.日期 DESC, a.姓名 DESC; - 方法2:使用用户变量
SET @num := 0; SET @date := ""; SELECT 姓名,日期,消费 FROM ( SELECT 姓名,日期,消费, @num := IF ( @date =日期, @num + 1, 1 ) num, @date := 日期 date FROM ( SELECT 姓名,日期,消费 FROM sale ORDER BY 日期 DESC,消费 DESC ) t1 ) t2 WHERE t2.num < 3;
查询连续n天在线
-
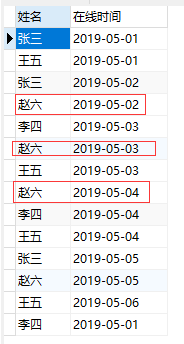
目标:查询连续三天在线的用户
-
数据源样式:(表名:user)
-
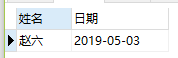
输出:
-
timestampdiff函数:TIMESTAMPDIFF(interval,datetime_expr1,datetime_expr2)
- interval参数(计算差):
- SECOND 秒 SECONDS
- MINUTE 分钟 MINUTES
- HOUR 时间 HOURS
- DAY 天 DAYS
- MONTH 月 MONTHS
- YEAR 年 YEARS
- interval参数(计算差):
-
sql如下:
SET @num := 0; SET @NAME := ""; SET @date := "2020-1-1"; SELECT 姓名,日期 FROM ( SELECT 姓名,日期, @num := IF ( @NAME = 姓名 AND TIMESTAMPdiff( DAY,日期, @date ) = 1, @num + 1, 1 ) num, @date := 日期 date, @NAME := 姓名 NAME FROM ( SELECT 姓名,日期 FROM USER ORDER BY 姓名,日期 DESC ) t1 ) t2 WHERE t2.num = 3; -
当然,我们也可以用三表自连接,sql如下:
SELECT DISTINCT t1.姓名 FROM USER t1, USER t2, USER t3 WHERE t1.`姓名` = t2.`姓名` AND t1.`姓名` = t3.`姓名` AND timestampdiff( DAY, t1.日期, t2.日期 ) = 1 AND timestampdiff( DAY, t2.日期, t3.日期 ) = 1; -
输出如下:

求中位数、众数
- 目标:求score中位数
- 数据样式:(表名:student)

- 输出:

- sql如下:
SELECT ( t1.score + t2.score ) / 2 median FROM student t1 JOIN student t2 WHERE t1.score > t2.score ORDER BY ( t1.score - t2.score ) ASC LIMIT 1;
- 目标:求众数
- 数据源如下:(表名:score)

- 输出如下:
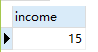
- sql:
SELECT income FROM score GROUP BY income HAVING count( * ) >= ALL ( SELECT count( * ) FROM income GROUP BY income );
转置查询
- 目标:转置course字段
- 数据源样式:(表名:teacher)
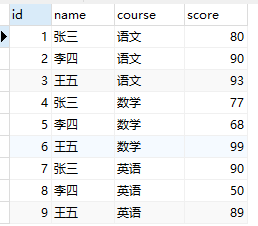
- 输出:

- sql如下:
逆向转置成原来表SELECT NAME, sum( CASE course WHEN "语文" THEN score END ) 语文, sum( CASE course WHEN "数学" THEN score END ) 数学, sum( CASE course WHEN "英语" THEN score END ) 英语 FROM teacher GROUP BY NAME;select name ,course ,score from ( -- 逐块union起来 select name ,'语文' as course ,语文 as score from transpose_table union all select name ,'数学' as course ,数学 as score from transpose_table union all select name ,'英语' as course ,英语 as score from transpose_table ) uu
差集、交集、并集
-
目标:查询求两长表某字段的差集、交集、并集(这里假设取year字段)
-
数据源样式:(表名:test1,test2)
-
test1
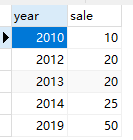
-
test2
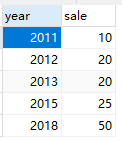
-
交集sql如下:
# 使用内连接 SELECT t1.YEAR FROM test1 t1 INNER JOIN test2 t2 ON t1.YEAR = t2.YEAR; # 使用in子查询 SELECT YEAR FROM test1 WHERE YEAR IN ( SELECT YEAR FROM test2 ); # 使用exists子查询 SELECT YEAR FROM test1 WHERE EXISTS ( SELECT 1 FROM test2 WHERE test2.YEAR = test1.YEAR ); -
交集输出如下:

-
差集:test1剔除test2(稍微修改下查询语句就可以了)
-
输出如下:
# 使用左连接 SELECT t1.YEAR FROM test1 t1 LEFT JOIN test2 t2 ON t1.YEAR = t2.YEAR and t2.year is null; # 使用in子查询 SELECT YEAR FROM test1 WHERE YEAR NOT IN ( SELECT YEAR FROM test2 ); # 使用exists子查询 SELECT YEAR FROM test1 WHERE NOT EXISTS ( SELECT 1 FROM test2 WHERE test2.YEAR = test1.YEAR ); -
并集
SELECT YEAR FROM test1 UNION -- 如果没有重复可以使用union all SELECT YEAR FROM test2; -
剔除交集
# coalesce函数:返回第一个非null的值 SELECT COALESCE ( t1.yeart, 2.YEAR ) FROM test1 t1 OUTER JOIN test2 t2 ON t1.YEAR = t2.YEAR WHERE t1.YEAR IS NULL OR t2.YEAR IS NULL;
行计算:相邻日期的字段差
- 目标:计算邻近日期之间sale差(日期不相邻)
- 用途:这种通常用于时间序列计算。
- 数据源式样:(表名:test1)

- 输入如下:
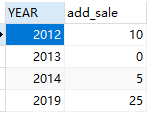
- sql如下:
SELECT t1.YEAR, t1.sale - t2.sale sub_sale FROM test1 t1 JOIN test1 t2 WHERE t1.YEAR > t2.YEAR AND ( t1.YEAR, t1.YEAR - t2.YEAR ) IN ( SELECT t1.YEAR, min( t1.YEAR - t2.YEAR ) min_year FROM test1 t1 JOIN test1 t2 WHERE t1.YEAR > t2.YEAR GROUP BY t1.YEAR, t1.sale );
计数、百分比
- 目标:计算成绩各个分段的计数及百分比
- 数据源样式:(表名:score)

- 输出:
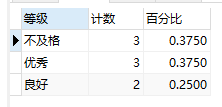
- sql如下:
set @cnt := (select count(*) from score); -- 创建一个用户变量,用于统计记录条数 SELECT CASE WHEN score < 60 THEN "不及格" WHEN score < 80 THEN "良好" ELSE "优秀" END "等级", count( * ) "计数", count( * ) / @cnt "百分比" FROM score GROUP BY CASE WHEN score < 60 THEN "不及格" WHEN score < 80 THEN "良好" ELSE "优秀" END;
累计值与移动累计值
- 目标:累计值,移动累计值(如果计算平均值的话,将sum函数改为avg平均数函数即可)
- 数据源样式(表名:test1)

- 累计值sql
SELECT YEAR,sale, ( SELECT sum( sale ) FROM test1 t2 WHERE t1.YEAR >= t2.YEAR ) "cumsum" FROM test1 t1 ORDER BY YEAR; # 当然我们也可以使用用户变量,实际这种方法很多地方都可以适用,而且效果好。 SET @cumsum := 0; SELECT t2.YEAR, t2.sale, @cumsum := @cumsum + sale cumsum FROM ( SELECT YEAR, sale FROM test1 ORDER BY YEAR ) t2; - 输出:
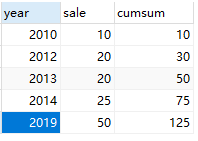
- 移动累计值sql(2条记录,不足2条按照2条算):
SELECT YEAR ,sale, ( SELECT sum( sale ) FROM test1 t2 WHERE t1.YEAR >= t2.YEAR AND ( SELECT count( * ) FROM test1 t3 WHERE t3.YEAR BETWEEN t2.YEAR AND t1.YEAR ) <= 2 ) mvg_sum FROM test1 t1 ORDER BY t1.YEAR; - 输出:

- 移动累计值sql(2条记录,不足2条记录为null)
SELECT YEAR ,sale, ( SELECT sum( sale ) FROM test1 t2 WHERE t1.YEAR >= t2.YEAR AND ( SELECT count( * ) FROM test1 t3 WHERE t3.YEAR BETWEEN t2.YEAR AND t1.YEAR ) <= 2 # 注意这里不能直接等于2. HAVING -- where不能用聚合函数count,所以这里使用having过滤。 count( * ) = 2 ) mvg_sum FROM test1 t1 ORDER BY t1.YEAR; - 输出:

生成连续序列
- 目标:生成0-99序列
- 数据源样式:(表名:number)
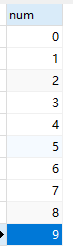
- 输出如下:

- sql如下:
SELECT t1.num * 1+ t2.num * 10 num FROM number t1 JOIN number t2 ORDER BY num ASC;
重叠时间冲突问题
- 目标:找到hotel预约时间冲突的人信息
- 数据源样式:(表名:hotel)
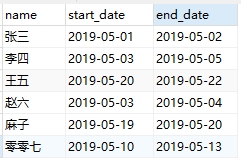
- 输出:
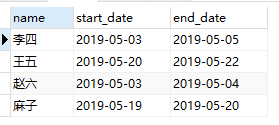
- sql如下
SELECT t1.NAME, t1.start_date, t1.end_date FROM hotel t1 WHERE EXISTS ( SELECT 1 FROM hotel t2 WHERE t1.NAME != t2.NAME AND ( t1.start_date BETWEEN t2.start_date AND t2.end_date OR t1.end_date BETWEEN t2.start_date AND t2.end_date ) );
查询两者同时活跃问题
- 需求是这样的,有一张月活跃表,存储各个游戏当月活跃的日志;主要字段为数据月份statis_month,用户账号:uin,游戏id:gameappid;现在统计近一年各个月份当月既在A【gameappid:123】游戏活跃又在B【gameappid:456】游戏活跃的用户量级别;
- 表名:f_m_game_active
select statis_month
,count(uin) as uv
from
( -- 用户月份既活跃A游戏,又活跃B游戏
select uin,statis_month
from f_m_game_active
where statis_month between 201908 and 202007
and gameappid in ('123','456')
group by uin,statis_month
having count(uin) = 2 -- 两款游戏当月有两条记录,表示当月两款游戏活跃;无需使用左表join右表方式
) t
group by statis_month;















 9428
9428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









