









文章目录
- 优化前相关
- 基本概念
- job、stage、task
- shuffle
- 宽依赖与窄依赖
- 对map算子和reduce理解
- 执行计划
- 1. 查看执行计划
- 2. DAG拆分
- 3. CountDistinct与数据膨胀
- 4. 案例-语句合理性分析
- 5. 开窗函数的执行计划
- 6. 多维聚合的执行计划
- 参数优化
- 1. 资源配置
- 1.1 集群资源合理分配
- 1.2 driver资源分配
- 1.3 executor资源分配
- 2. shuffle优化
- 2.1 spark的shuffle机制
- 2.2 增加shuffle并行度
- 2.3 动态分区机制
- 2.4 增加shuffle write的buff大小
- 2.5 调整shuffle read数据量大小
- 2.6 调整重试间隔时间
- 2.7 使用适当shuffle类型
- 2.8 shuffle压缩
- 2.9 限制文件拉取
- 2.10 内存动态管理
- 2.11 Spark.Shuffle.service.enabled服务
- 3. map端task个数调整
- 4. 加速spark_df与pandas_df之间的转化
- 5. 广播join
- 6. join倾斜
- 7. CBO优化
- SQL优化
- 1. 数据倾斜
- 1.1 什么是数据倾斜
- 1.2 倾斜key抽样
- 1.3 过滤倾斜的key
- 1.4 增加shuffle并行度
- 1.5 双重聚合
- 1.6 使用mapjoin
- 1.7 join中倾斜key单独摘出来操作
- 1.8 多表join倾斜特殊情况
- 2. 调整join关联的顺序
- 3. 数据累全量
- 4. 数据预聚合
- 5. 多维分析的union改写
- 6. 全局排序问题
- 7. 小表leftjoin大表
- 8. 同一个字段多个countdistinct
- 9. 结合业务具体情况优化
- 其他优化
- 1. 本地化执行
- 2. 限制申请资源
- 3. 合并输出小文件
- 4. 持久化
- 5. With视图
- 6. 尽可能使用高性能算子
- 7. 作业的拆解与关键链路优化
- 参考
优化前相关
在实际生产优化中,很多开发同学一上来就看sql执行资源分配够不够,数据有没倾斜,与业务脱离的技术层通常摸不到业务的核心需要,这使得实际优化受限;比如一条任务跑了六七个小时,实际业务设计就是不合理的或者有更好更快的实现方式。
所有动作都要以最终根本目的为导向,在有限的责任范围内尽可能做到目标评测指标最好;如果需求不合理,可以协商调整亦或排期其他更高优先级需要;
笔者举个例子,当笔者在解决一实际生产问题时,曾苦恼一调整没有良好的实现方法,经沟通,该需求可以下线,无须处理,那浪费时间其实没有必要;
需求是指向人的,需求背后有更更深层次的需求,作为一名资深的开发跟业务协调,更应该去琢磨业务需要,深层考量,而非仅仅是开发实现层面;产品工程思维才是一个开发的进阶;
反过来,也会遇到这样一类业务,做需求只讲输出不言背景。这样一方面开发成长受限,协作表现可能不理想,一方面不能很好的调动开发资源,仅受限局限视角的具体实现。
对于基础表结构,一般是事先设定好的;但对于外在数仓、表设计也是我们需要考量的一个点,比如数仓设计,全量增量、不同颗粒度,良好的设计能节约很多计算存储资源;
其次再就是语句合理性分析,这块可以结合执行计划读,比如实现该需求,使用怎样的逻辑处理会更快些,资源消耗会更少些;
最后再就是资源、参数优化。
如果语句,业务逻辑没啥问题,重点考虑数据倾斜,资源配置,这部分通常能显著提升计算时效;
本内容仅针对yarn调度环境,spark版本:2.4.3,其他版本或有些许差异;
基本概念
简要说明自己对几个基本概念的理解
job、stage、task
在SparkSQL中,一般每提交一条sql都会生成一个job,通过行动算子触发执行;
一个job就好像一个项目,项目下的工作可能会包含多个阶段stage,不同阶段(stage)之间工作路径可
能有并行(比如读不同表),可能有依赖;每个阶段(stage)下包含若干工作单元(task);
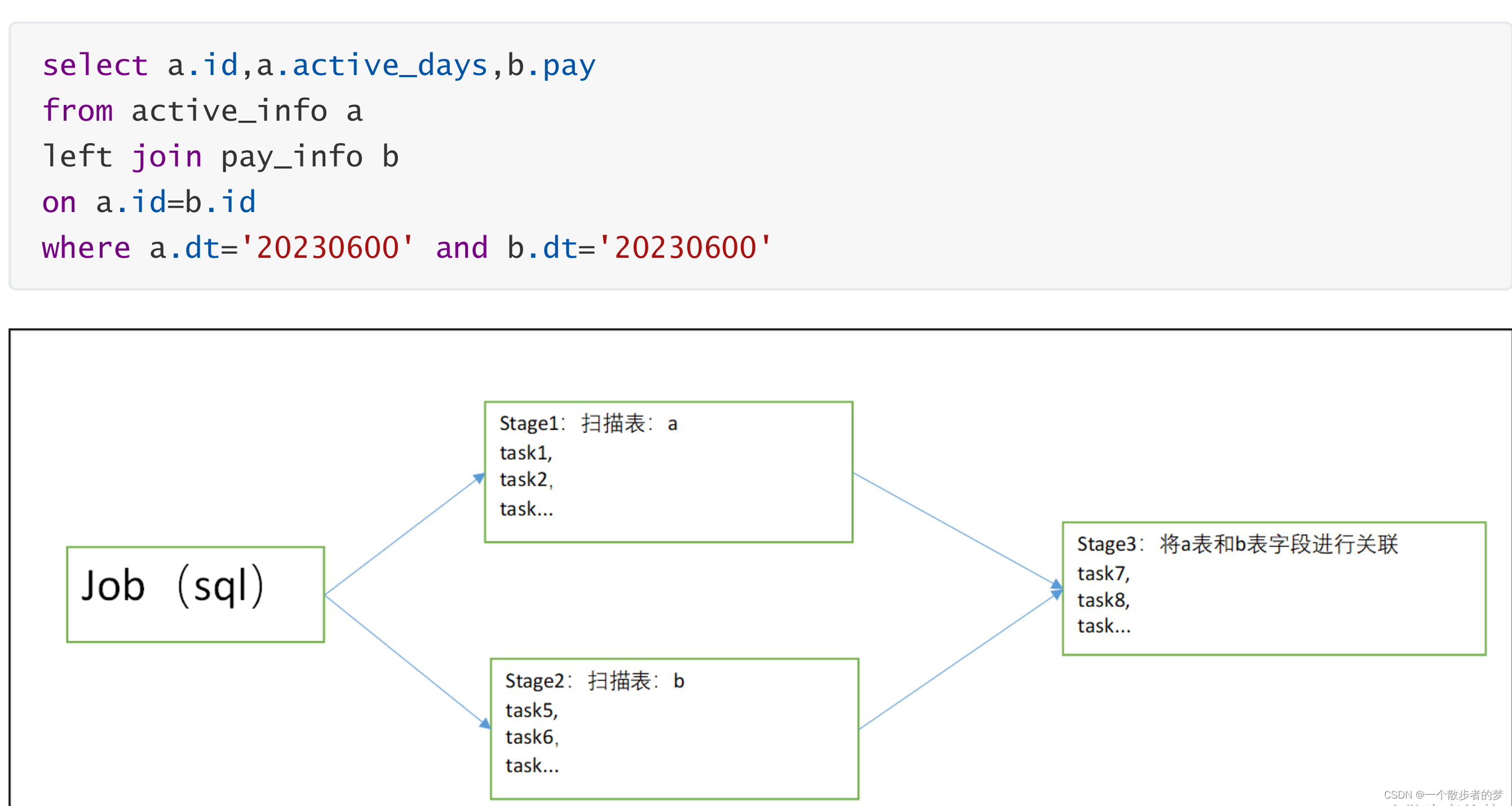
sql优化会将谓词前推(具体看执行计划),上面a表和b表的dt='20230600'筛选条件会在map端过滤掉,逻辑结果是left join实际就是两个表内连接join;如果实现左连接,需要把b.dt='20230600’条件放在on关键字后面作为关联条件;
select a.id,a.active_days,b.pay
from active_info a
left join pay_info b
on a.id=b.id and b.dt='20230600'
where a.dt='20230600'
初始化SparkSession时会生成一个applicationid,该Session下执行多条sql语句都是在同一个id下;这点跟hive会有所区别,hive提交一条sql语句:每个mr对应一个applicationid;上面的sql语句,hive中如果没合并文件、数据倾斜等参数设置,通常对应一个MR,map端扫描a表和b表,reduce端做join关联操作;
hive中,会将每个作业拆分成若干个stage,一个stage可以是一个MR阶段,也可以是抽样、数据合并union,limit;
默认同一时间只执行一个stage,如果不同stage没有依赖,可通过并行参数set hive.exec.parallel=true开启并行执行(该并行指的是job并行,比如union all中多段子查询并行执行)可通过set hive.exec.parallel.thread.number=16设置并发数
shuffle
不同计算节点之间发生了数据混洗,下游计算需要依赖于上游task全计算完后才能执行;
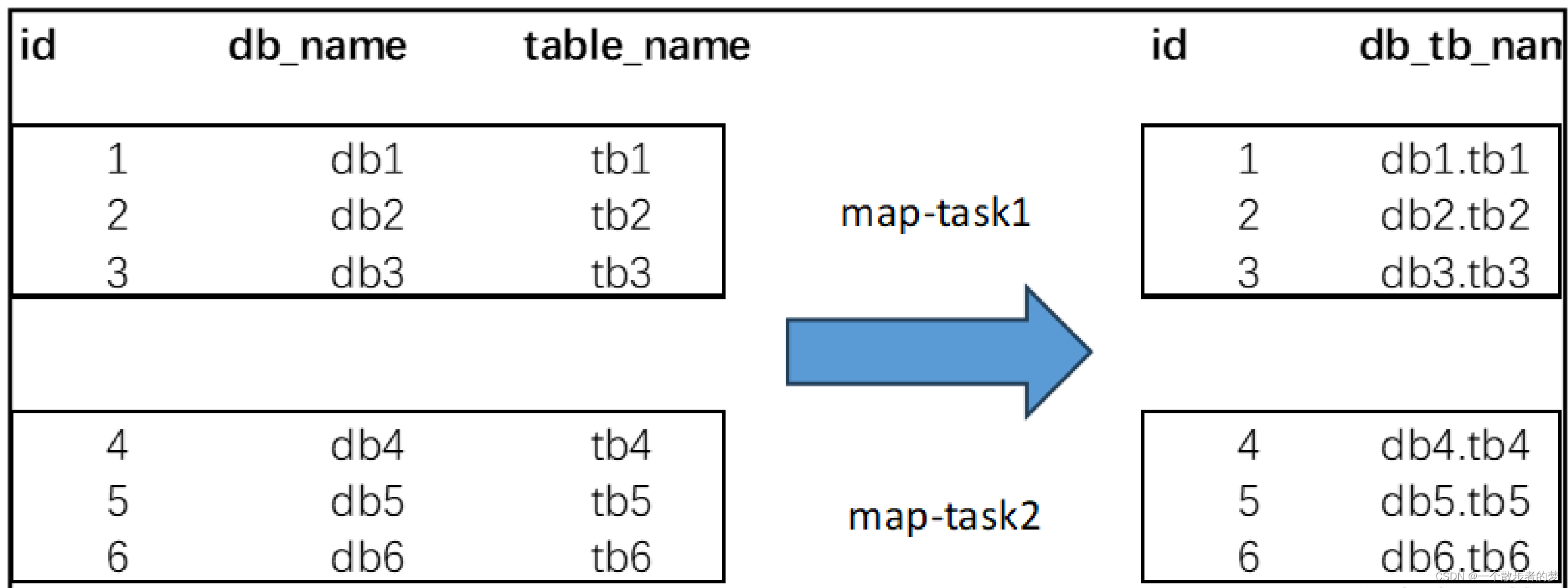
无shuffle:
我们可以大概认为就对对每一条数据进行map映射,不同行数据处理之间互不干扰
select id,concat(db_name,'.',table_name) as db_table_name
from table_name a
有shuffle:
类似于sql中的普通join,groupby,开窗函数等
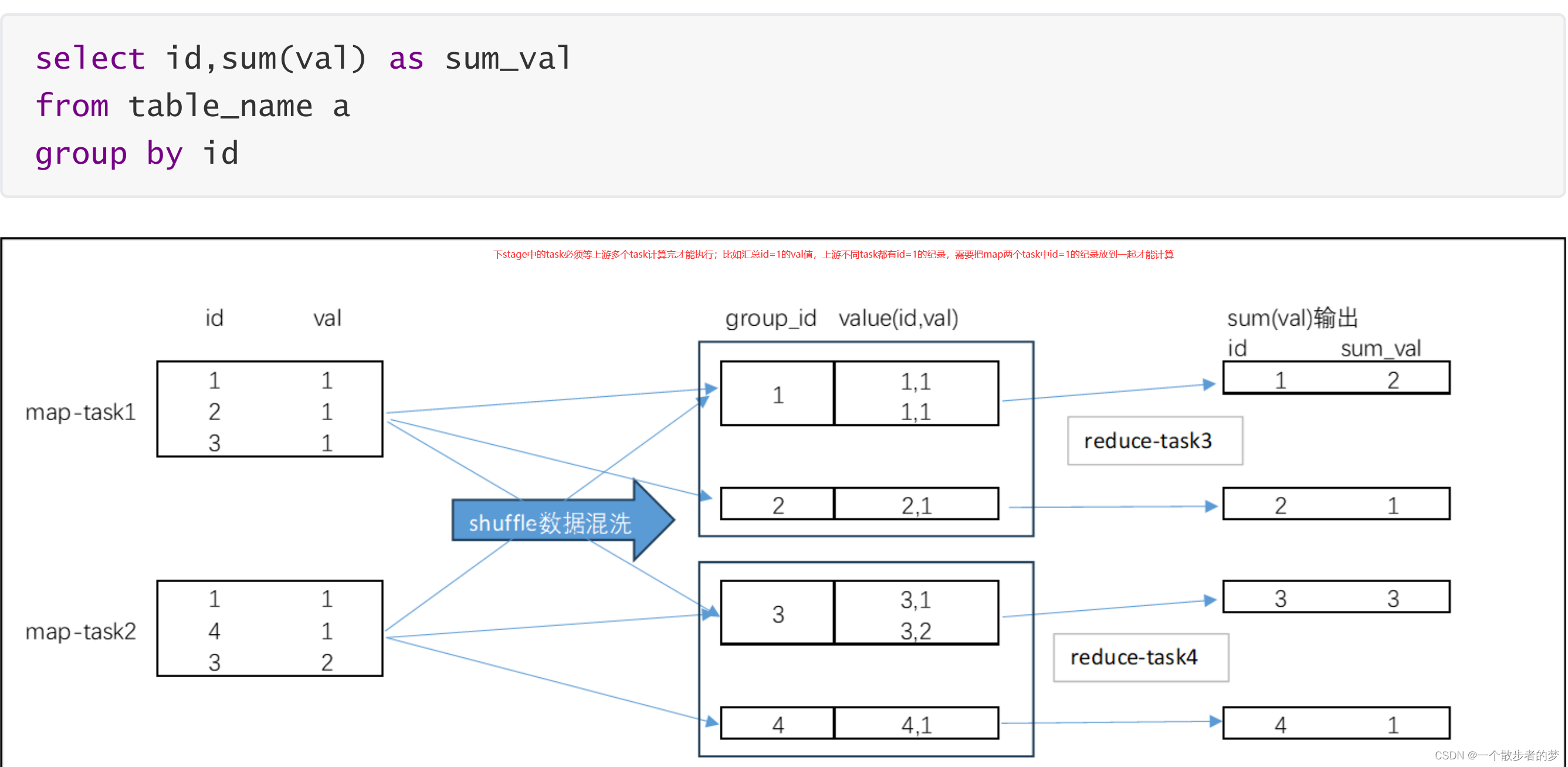
SparkSQL中,reduce阶段task个数,通过spark.sql.shuffle.partitions参数设置;以上截图只是一个样例,实际task个数不一定是2个,如果开启分区动态参数,数据量少,可能合并到一个task里;
宽依赖与窄依赖
spark的宽依赖和窄依赖也是按照有无shuflle来划分的,上下游计算中间如果没有shuflle,则是窄依赖;反之存在shuffle则为宽依赖,下游task计算依赖上游多个task;
窄依赖(无shuffle)划分到同一个stage里,该stage里不同的task可以并行执行;
对map算子和reduce理解
map即针对每一条记录应用特别的函数进行转化,map的返回可以是多行记录;像SQL里的 mapjoin ,lateral view explode 都是map端操作
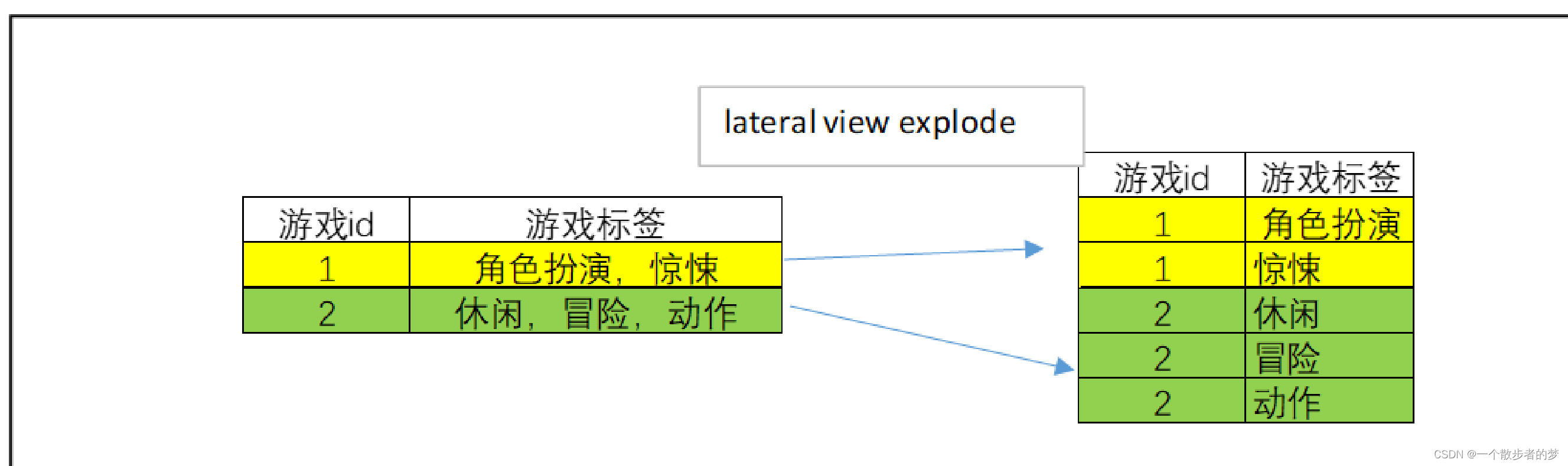
以上案例,map对每一行输入返回多行输入,都是在map端运行的,不存在shuffle;
reduce计算: 即shuflle后的数据计算,这计算可以是分组后的数据聚合,普通join字段关联,也可以是开窗函数,比如row_number的排序;
执行计划
1. 查看执行计划
explain():只展示物理执行计划。(使用较多)explain(mode="simple"):只展示物理执行计划。explain(mode="extended"):展示物理执行计划和逻辑执行计划。explain(mode="codegen"):展示要 Codegen 生成的可执行 Java 代码。explain(mode="cost"):展示优化后的逻辑执行计划以及相关的统计。explain(mode="formatted"):以分隔的方式输出,它会输出更易读的物理执行计划,并展示每个节点的详细信息。
初始化SparkSession后便可以调用:spark.sql(sql_str).explain()查看执行计划;
如果是在写sql的框里,查看执行计划,同hive;在sql前加上explain关键字即可;
执行计划样例:
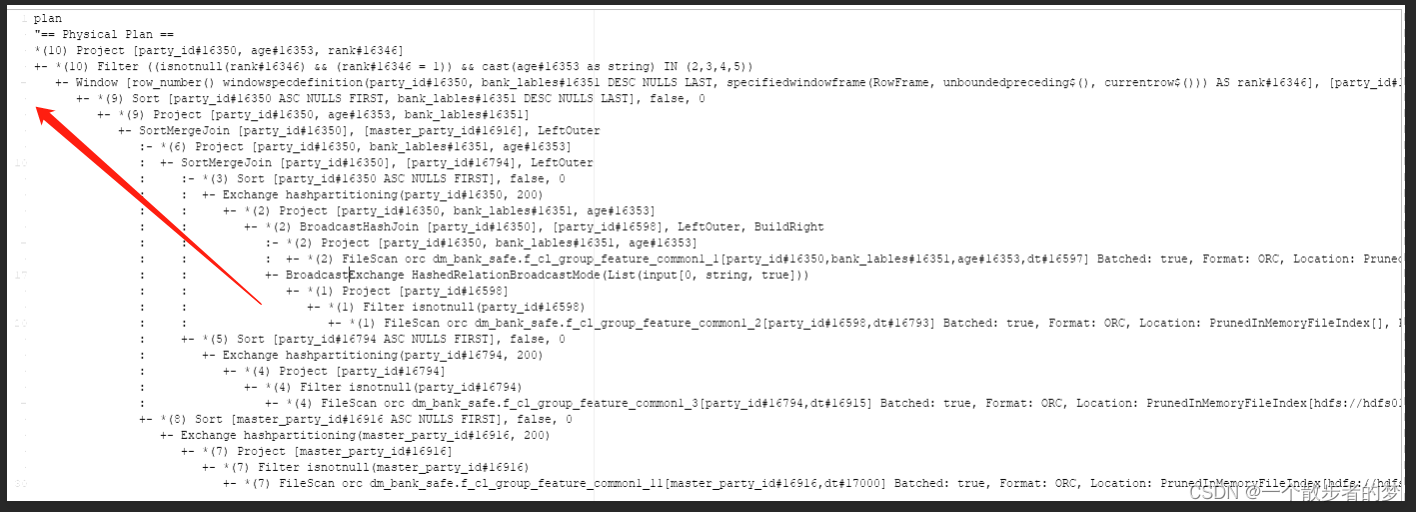
中间的虚竖线连接的是关联的两个数据块,查看顺序从内侧往外侧看;外层的stage依赖内层的stage
执行计划中几个关键字:(行开头的单词)
FileScan:表扫描
Filter:过滤
Project:列裁剪优化,选取需要的字段
HashAggregate:聚合计算,如果在map端表示map预聚合
Exchange hashpartitioning:shuflle混洗,hash分区
HashAggregate:聚合计算
Sort:排序
SortMergeJoin:join关联
Window:开窗函数计算
BroadcastExchange:小表广播
BroadcastHashJoin:广播join
2. DAG拆分
DAG遇到宽依赖(shuffle),划分一个新的stage,窄依赖划到同一个stage。同一个stage的task可以并行执行;
宽依赖指的是下游task依赖于上游两个或多个task
比如如下的sql:t3和t4都是小表,走的mapjoin(我们假设开启了小表自动广播join)
select t3.group_field3,t4.group_field4
,sum(t2.val) as sum_val
from
(
select id
from tablename1 t0
group by id
) t1
join tablename t2
on t1.id=t2.id and t2.field_name = 'xxxx'
join small_tablename3 t3 -- 小表mapjoin
on t1.key_field1 = t3.key_field3
join small_tablename4 t4 -- 小表mapjoin
on t1.key_field2 = t4.key_field4
group by t3.group_field3,t4.group_field4
在SparkSQL中stage划分是这样的:
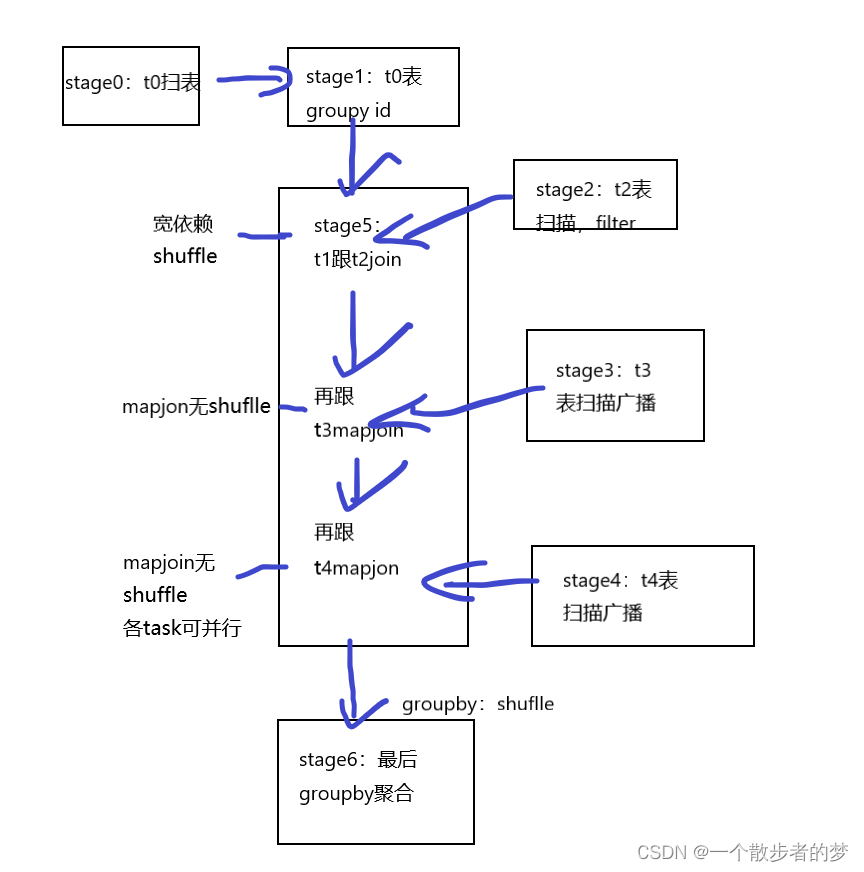
走mapjoin不同task之间没有依赖关系,可以并行处理;故划分到同一个stage
如果对应hive的执行计划,在没有其他特别情况下(比如倾斜参数增加的mr)该段sql划分为5个MR:
MR-1:t0表groupby id去重
MR-2:t1跟t2join
MR-3:MR-2的结果跟t3mapjoin(mapjoin只有map没有reduce)
MR-4:MR-3的结果跟t4mapjon
MR-5:MR-4的输出按t3.group_field3,t4.group_field4分组求和
hive的参数set hive.auto.convert.join.noconditionaltask=true可以控制,一个stage里进行多个小表mapjoin,这样可以规避中间数据落地临时文件,磁盘io消耗;sparksql机制默认是这样,在一个stage里;
在多表关联时,如果关联字段使用的是同一个key字段,执行计划可能会做出优化,将多表关联划分为一个MR,因为key字段都是一样的,比如如下一段sql(key字段都是id):
select *
from table1 t1
join table2 t2
on t1.id=t2.id and t2.field_name='xxx'
join table3 t3
on t1.id=t3.id
map阶段分别读取t1,t2,t3表数据,shuffle的key字段是三个表的字段id;如果有filter过滤,在map端执行;reduce再对三表进行join输出;
3. CountDistinct与数据膨胀
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.Builder()\
.appName('test')\
.enableHiveSupport()\
.getOrCreate()
当只有一个distinct时,spark数据无膨胀;
sql = """
select level
,count(distinct from_table) as cnt
from dw_pub_safe.dw_pub_table_rely_pfd
where level > 3+7
group by level
"""
spark.sql(sql).explain()
执行计划如下:我们可以看到分成了三个stage,对常量进行了优化,预先计算好,中间有两次shuffle,额外进行了优化处理(count distinct的优化);
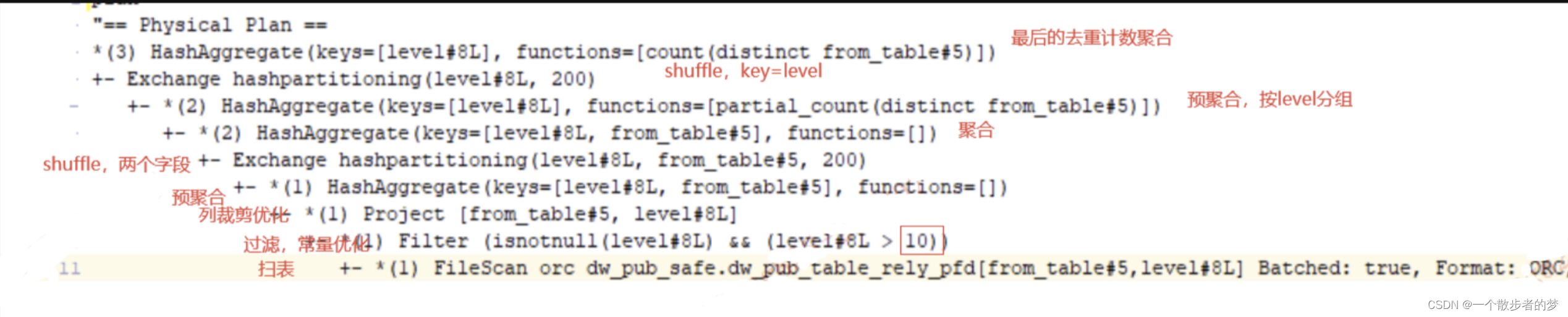
该段sql,如果是hive执行计划,没其他特殊情况,通常是一个mr过程
这个执行计划实际等价于如下sql:
select level
,count(1) as cnt
from
( -- 按level,from_table分组
select level
,from_table
from dw_pub_safe.dw_pub_table_rely_pfd
where level > 10 -- 3+7
group by level,from_table
) t
group by level
如果from_table的枚举值有限,将两个stage改成三个stage,会增加task开销,第一阶段map端聚合后数据量已经很少了,直接count distinct速度也很快;这时候可以考虑关闭成本优化参数:spark.sql.cbo.enabled 再看执行计划如何
SQL优化,在实际生产中,一个任务通常要跑批很长时间,查看执行计划通常是我们优化过程中的第一步
如果存在多个countdistinct算子(大于1),每增加一个,数据膨胀一倍。比如如下sql,shuffle数据量是tablename的三倍(有两个countdistinct)
select 用户id
,sum(销售额)as sales
,count (distinct 产品分类) as discat
,count (distinct 产品名称)as dis pro
from tablename
group by 用户id
在spark的执行计划中,基本等价于如下:
Select 用户id
,count (case when 1abel=1 then 产品分类)as dis_cat
,count (case when label=2 then产品名称)as dis pro
,sum (case when label=0 then sales) as sales
from
( -- map端预聚合,reduce再聚合,计算销售额
select 用户id,产品分类,产品名称,labe1
,sum(销售额)as sales
from
(
select 0 as label,用户id,销售额,nu11 as 产品分类,nul1 as产品名称 from tablename
union all -- 每多1个countdistinct,数据膨胀增加一倍:产品分类
select 1 as label,用户id,销售额,产品分类,null as 产品名称 fromm tablename
union all -- 每多1个countaistinct,数据膨胀增加一倍:产品名称
select 2 as label,用户id,销售额,nu11 as 产品分类,产品名称 from tablename
) uu
group by 用启id,产品分类,产品名称,label
) t
group by 用户id
spark会为每一次膨胀数据增加一个标记,一个标记数据用于计算max,min,sum等聚合,其他每个标记对应的数据用作于一个countdistinct计算
hive中,如果只有一个countdistinct时,是没有数据膨胀的,比如如下一段sql执行逻辑:
select field_name1,count(distinct field_name2) as dis_cnt
from db_table_name
group by field_name1
map端先按groupby字段(即field_name1)和countdistinct字段(即field_name2)预聚合,然后按groupby字段分区(reduce分区),reduce再按groupby字段分组,对countdistinct字段进行去重计数;
一般进行分组统计,分组字段的枚举值个数是比较少的,去重计数字段如果枚举值个数也比较少,即使分组字段有倾斜,使用hive一个mr计算也会很快;因为有预聚合在,map端预聚合后输出数据量很少;
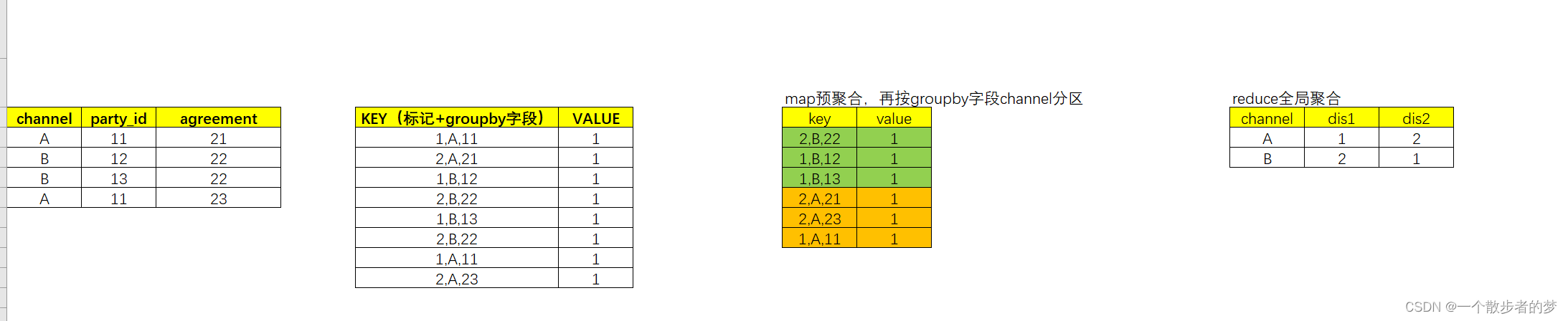
hive中如有多个countdistinct时,每一个数据膨胀一倍,类同spark,对每个去重计数字段,map时会加上一个标记,map预聚合,reduce再全局聚合,map端大概效果如下:
select channel
,count(distinct party_id) as dis1
,count(distinct agreement) as dis2
from db_table_name
group by channel
原本4行数据,两个countdistinct膨胀2倍到8行数据;key给去重加上的标记跟spark会有些许区别,一个是从1开始,一个序号是从0开始;具体可以查看执行计划;
4. 案例-语句合理性分析
有下面一段sql:

这段sql其实一眼就可以看出来,在多表关联后再进行开窗过滤,显然显著增加了计算开销;我们看下执行计划:
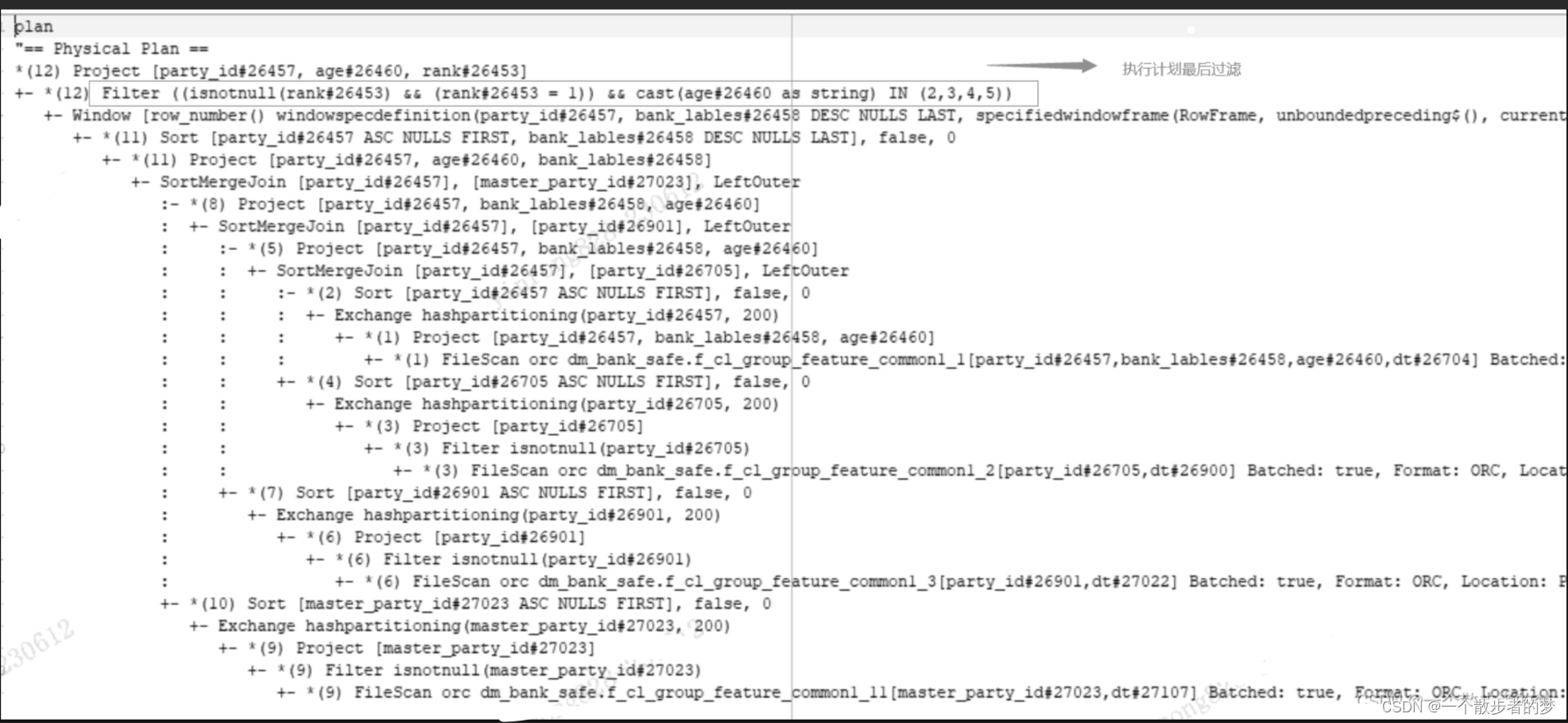
任务进行了三次shuflle(join),每次shuflle都是t1表20230608整个分区的数据。row_number开窗的计算开销是不可规避的,将age前置过滤再进行开窗筛选rnk=1,在此过滤基础上再进行join能极大减少shuflle开销及计算;
然后我们看这个开窗函数是干啥用的:按party_id分区排序取party_id?一个去重操作,强行用了一个开窗,这就是sql语句设计的不合理;
调整后的sql如下:
select * -- 若干使用字段省略
from
(select party_id from table1 where dt='20230608' and age in ('2','3','4','5') group by party_id) t1
left join table2 t2
on t1.party_id=t2.party_id
left join table3 t3
on t1.party_id=t3.party_id
left join table4 t4
on t1.party_id=t4.master_party_id
在实际优化过程中,我们不光要考虑执行计划,还要考虑语句本身的合理性
5. 开窗函数的执行计划
sql语句:

执行计划:

开窗函数shuffle时按照parition by 的字段分组,在这里有两端shuffle,第一段按from_table字段分组,进行了max和count聚合,max_level和from_table_cnt两个字段由于是partition by同一个字段,在同一个stage里边;第二段shuffle按to_table字段分组,统计to_table_cnt字段
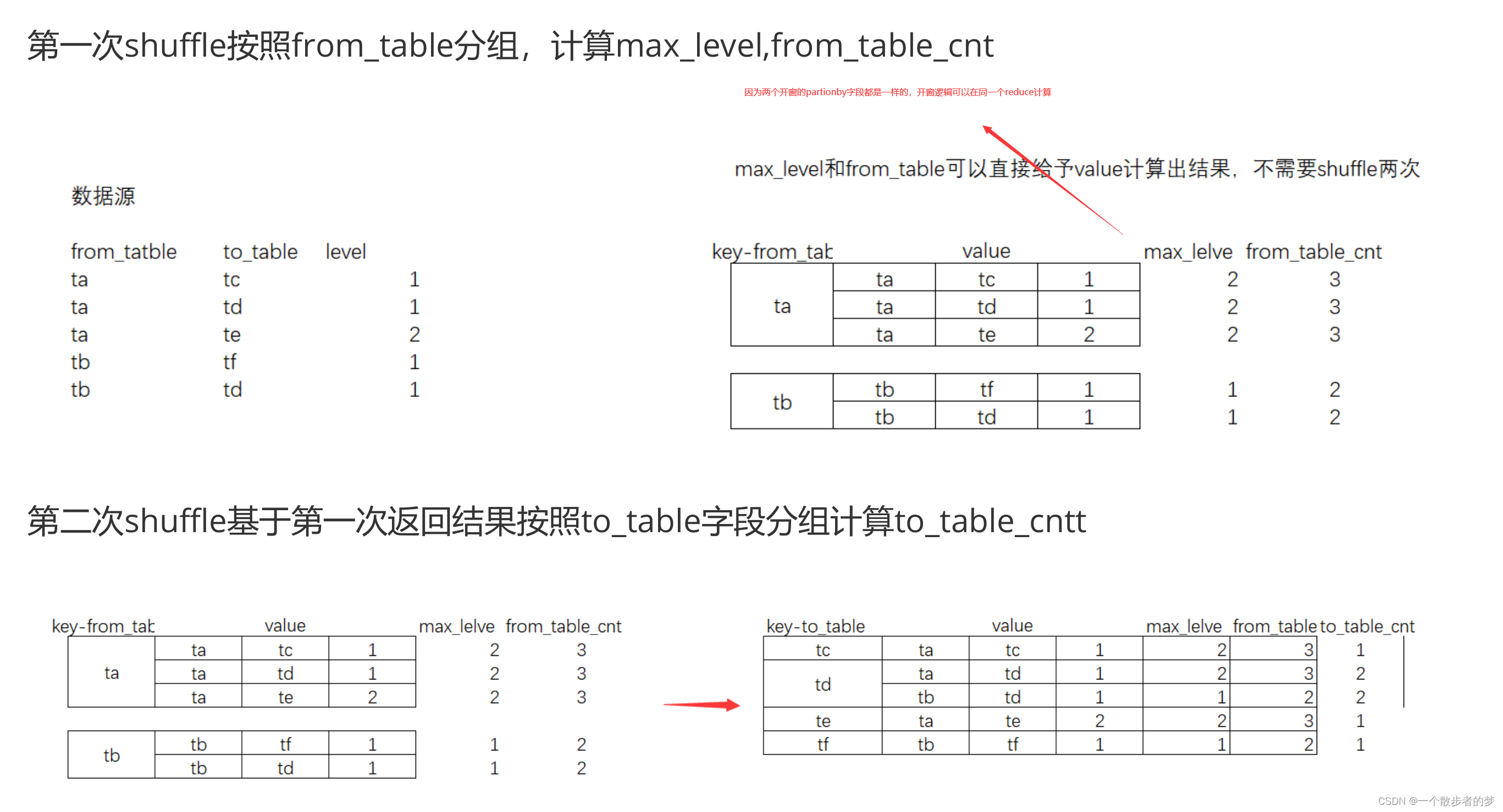
案例:
这里写了一段sql,先进行groupby聚合,在此基础上先进行了两个NTILE百分位窗口,最后再套上了一个row_number窗口函数;三个窗口函数的PARTITION BY字段都是PRODUCT_TABLE_NAME

HIVE的执行计划,计算是4个STAGE,第一个stage:groupby聚合;第二个stage:nitle开窗;第三个stage:ntile开窗;第四个stage:row_number开窗;HIVE每个mr都会将结果写到磁盘,一共发生了4次Shuffle;
Spark的执行计划:
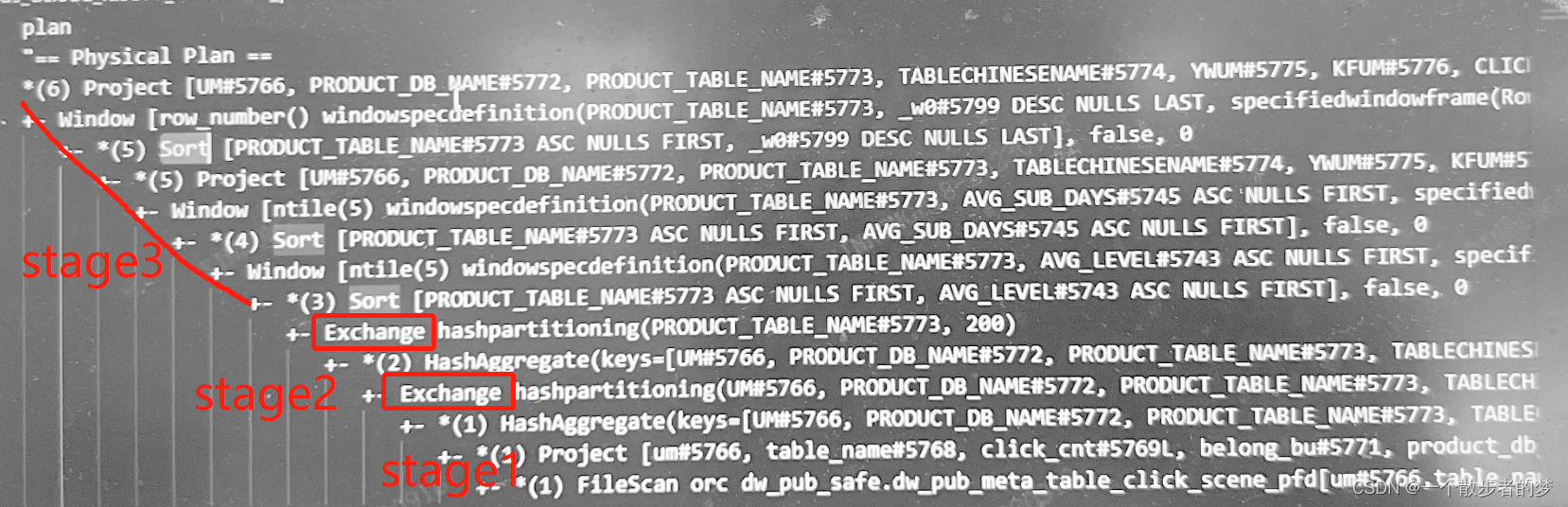
一共之发生了两次shuffle;共3个stage;
- stage0:数据读取,shuffle write
- stage1:groupby聚合,shuffle write
- stage2:三个开窗函数计算(如果最后落地hive表,这里会有output)
为什么三个开窗函数,明明sql写在不同的查询段里,划到了一个stage,这里三个开窗函数的partition by字段都是一样的(shuffle逻辑同),map端shuffle后,在reduce端依次进行三次排序即可;三个开窗函数不需要再按partition by字段重新混洗;
6. 多维聚合的执行计划
多维聚合,写下下面一段sql
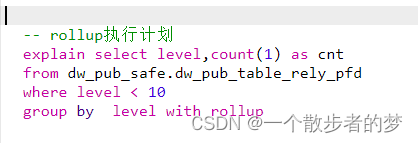
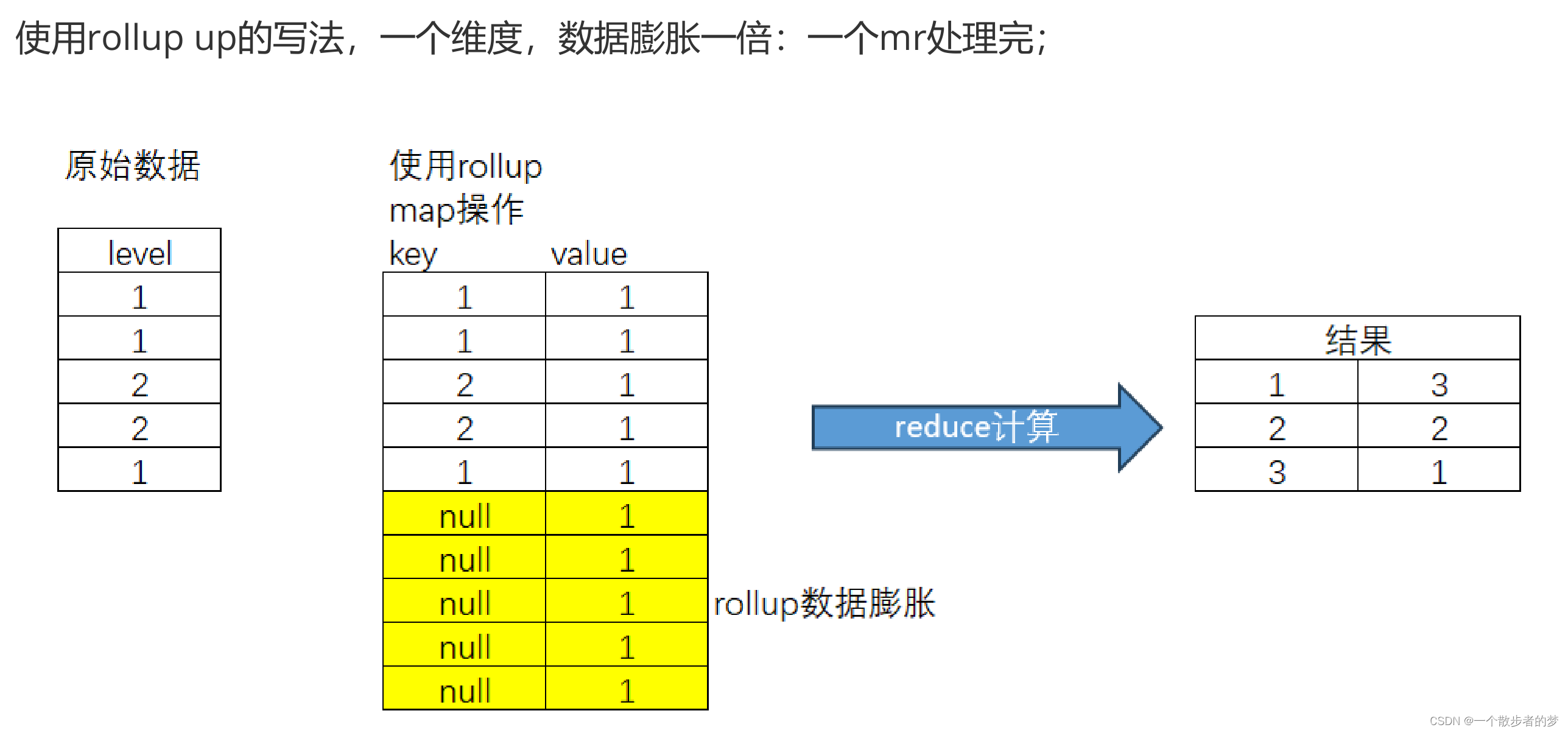
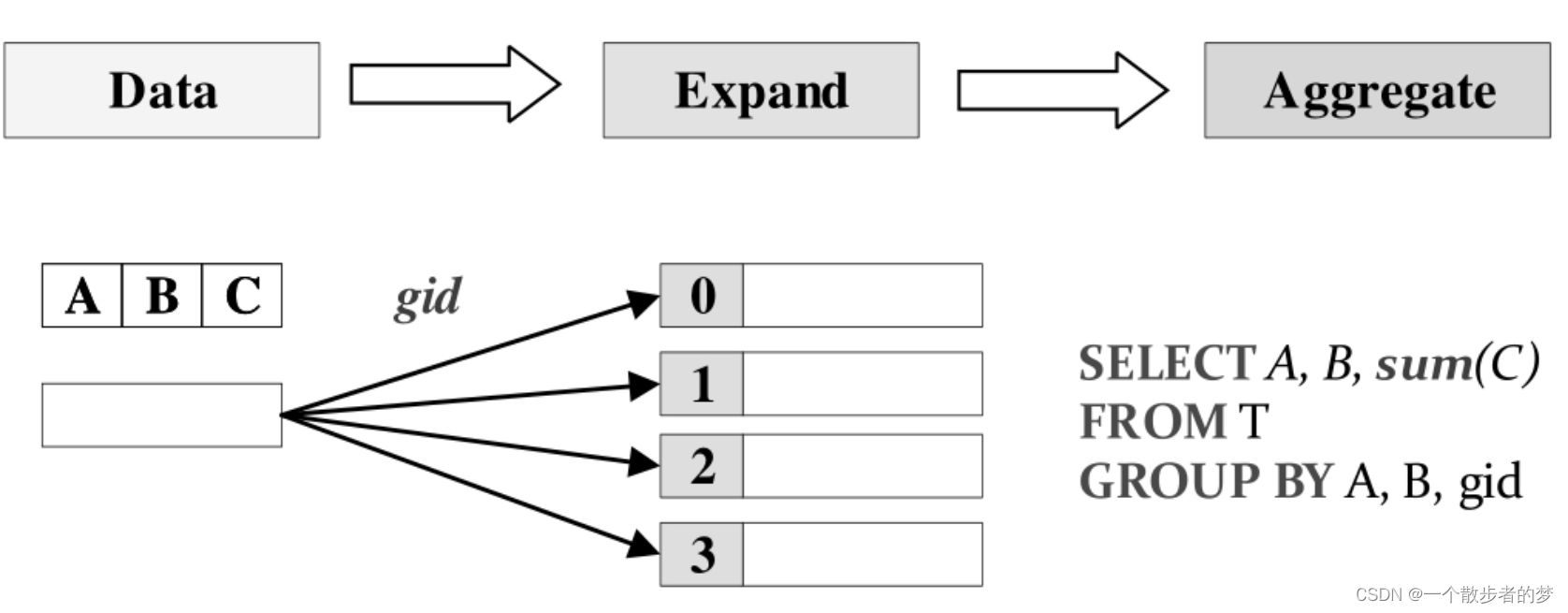
我们看下sql的执行计划:每一组grouping sets数据会使数据量expand膨胀一倍,在执行时为每一组grouping sets生成一个spark_grouping_id标识,最后在key中,加入了spark_grouping_id

参数优化
1. 资源配置
1.1 集群资源合理分配
在允许的情况下,为作业配置尽可能多的资源;
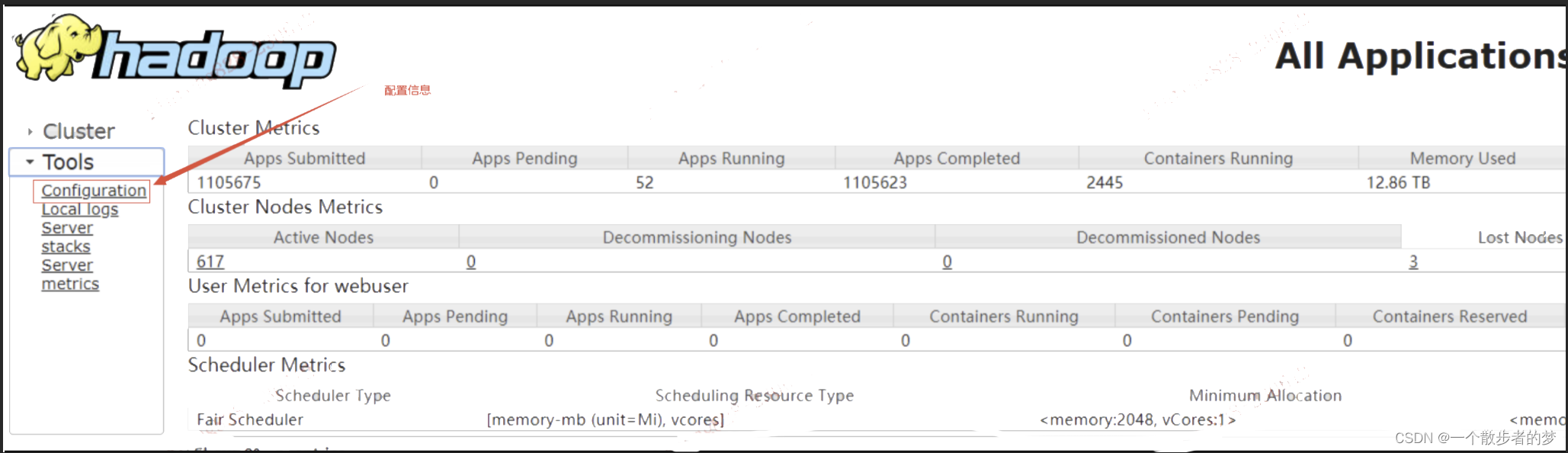
yarn单节点参数:内存yarn.nodemanager.resource.memory-mb;cpu核数:yarn.nodemanager.resource.cpu-vcores;可以结合服务器台数计算集群总分配资源及集群资源使用情况,合理分配spark计算资源;
一个executor寄存于一个yarn的Container,一个executor设置的内存和cpu核心数要小于yarn对Container资源配置
单个Container在yarn中的配置参数
最大cpu数:yarn.scheduler.maximum-allocation-vcores
最大内存:yarn.scheduler.maximum-allocation-mb
更多属性可以看yarn的配置文件或者yarn后台Configuration查看
1.2 driver资源分配
dirve端主要负责:
-
用户程序/SQL转化成JOB,DAGScheduler 来把一个 Job 根据宽依赖划分为多个Stage(同一个stage的task可以并行执行)
-
分发任务给Executor及跟踪task执行情况
-
提供UI、内存、广播管理等
相关参数:
spark.driver.cores:在cluster模式下,用几个core运行驱动器(driver)进程,结合实际情况分配。一般计算都在executor计算,driver不用太大的,按默认就好;
spark.driver.maxResultSize:Spark action算子返回的结果最大多大。至少要1M,可以设为0表示无限制。如果结果超过这一大小,Spark作业(job)会直接中断退出。但是,设得过高有可能导致驱动器OOM(out-of-memory)(取决于spark.driver.memory设置,以及驱动器JVM的内存限制)。设一个合理的值,以避免驱动器OOM。
机器学习,有的会调用spark_df.toPandas()将数据回收到driver节点,再调用相关模型训练。这时候要考虑数据集大小,适当调大该参数;如果数据集大,字段多,集群资源有限内存OM,则考虑减少训练样本量;
spark.driver.memory:驱动器进程可以用的内存总量(如:1g,2g)。注意,在客户端模式下,这个配置不能在SparkConf中直接设置(因为驱动器JVM都启动完了呀!)。驱动器客户端模式下,必须要在命令行里用 –driver-memory 或者在默认属性配置文件里设置。计算不在driver,该内存一般不用调整,如果存在广播join或者数据缓存,可以根据实际情况适当调大些;
1.3 executor资源分配
spark.executor.memory:单个执行器内存大小,默认1G;保证作业正常运行,集群一般默认配置2-5G
spark.executor.instances:executor个数
spark.executor.cores:每个执行器分配的cpu核数(逻辑核),一般不超过4个;
spark.dynamicAllocation.enabled:是否开启动态资源分配,默认是false;开启后spark.executor.instances固定配置将失效;如开启同时还和以下配置相关:
spark.dynamicAllocation.minExecutors:动态分配开启后,最小executor数
spark.dynamicAllocation.maxExecutors:动态分配开启后,最大executor数
spark.dynamicAllocation.initialExecutors:动态分配开启后,执行器的初始个数
一个c处理一个task,在磁盘io时可能会有性能浪费,官方推荐一个c处理2-3个task;并行处理task的个数=spark.executor.instances * spark.executor.cores;比如设置spark.executor.instances为2个,每个executorspark.executor.cores分配3个核,同一时间能执行2*3=6个task
每个task分配内存:spark.executor.memory / spark.executor.cores,每个task期望处理数据量应尽可能小于该值,以防shuffle过程OOM
需要注意的是,spark.task.cpus参数设定一个task交由几个c来完成,默认是1;资源并行计算度准确来说,应该为:spark.executor.instances * spark.executor.cores / spark.task.cpus,单个task分配的内存同样要考虑这种情况;
2. shuffle优化
2.1 spark的shuffle机制
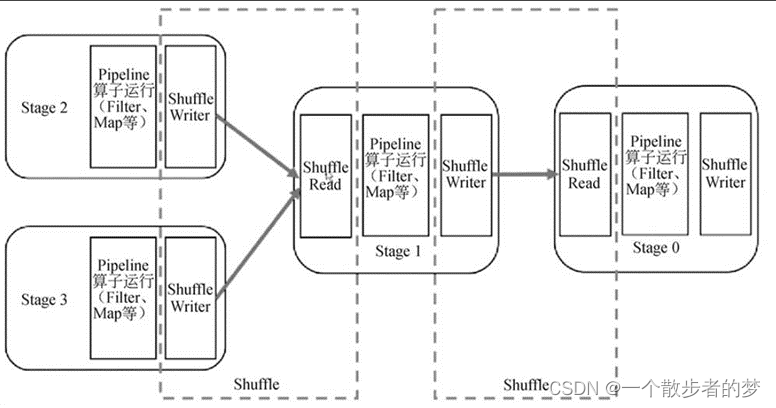
在SparkSQL中,一个stage是一个可以并行执行的task集合;除了最后一个stage文件output输出没有ShuffleWrite外(ResultStage),其余都是ShuffleMapStage,会发生数据混洗;
从多个stage角度来讲,假设一个作业依赖是:stage1 -> stage2 -> stage3,
其中,stage1是stage2的ShuffleMapStage,stage2是stage1的reduce,stage2同时是stage3的ShuffleMapStage;
map task经由buffer将分区partition写入磁盘,下游reduce端从上游stage抓取数据中间也有一个buffer;
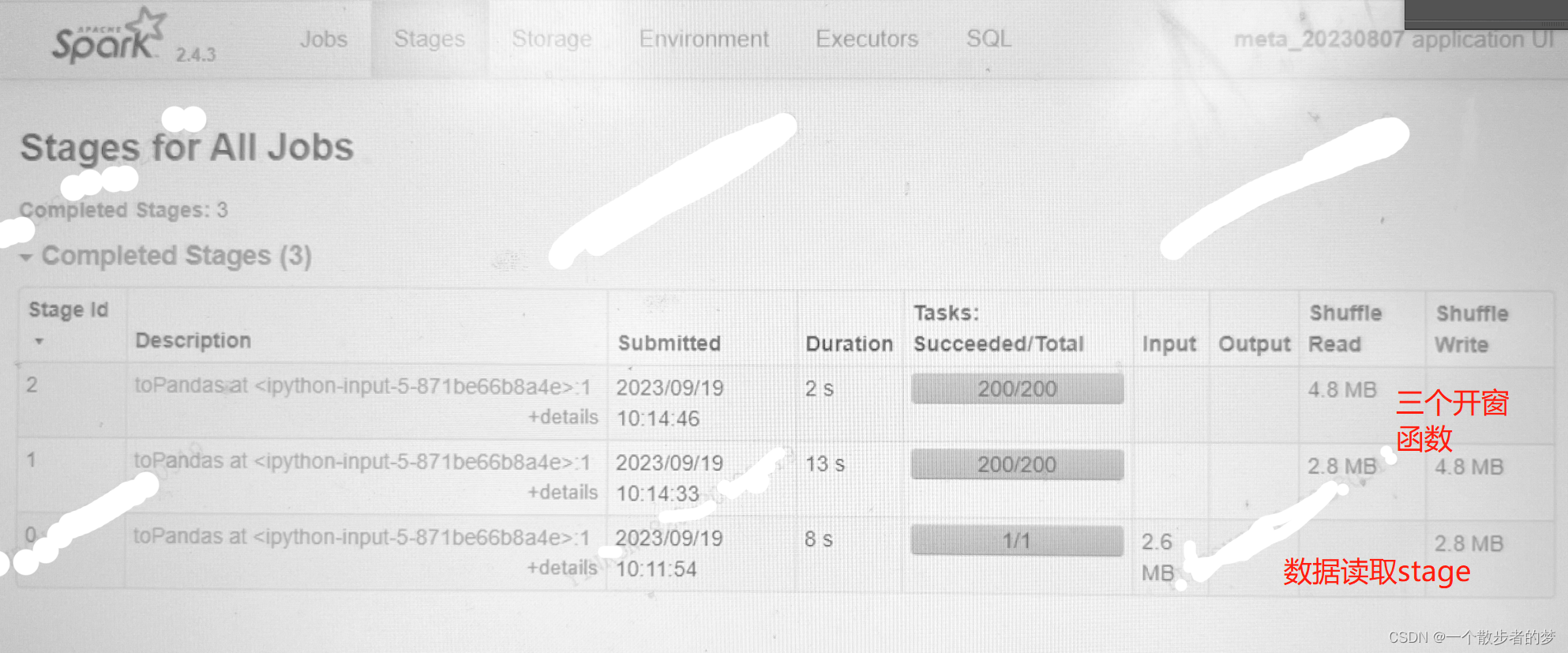
在Spark UI中stage页面:
数据读取及shuffle写stage:参与input和shuffle write(下截图第2/3个stage)
中间stage是shuffle read和shuffle write(下截图红色框的两个stage);
结果stage是shuffle read及output(下截图最上面一个stage,拉取数据计算后直接输出);
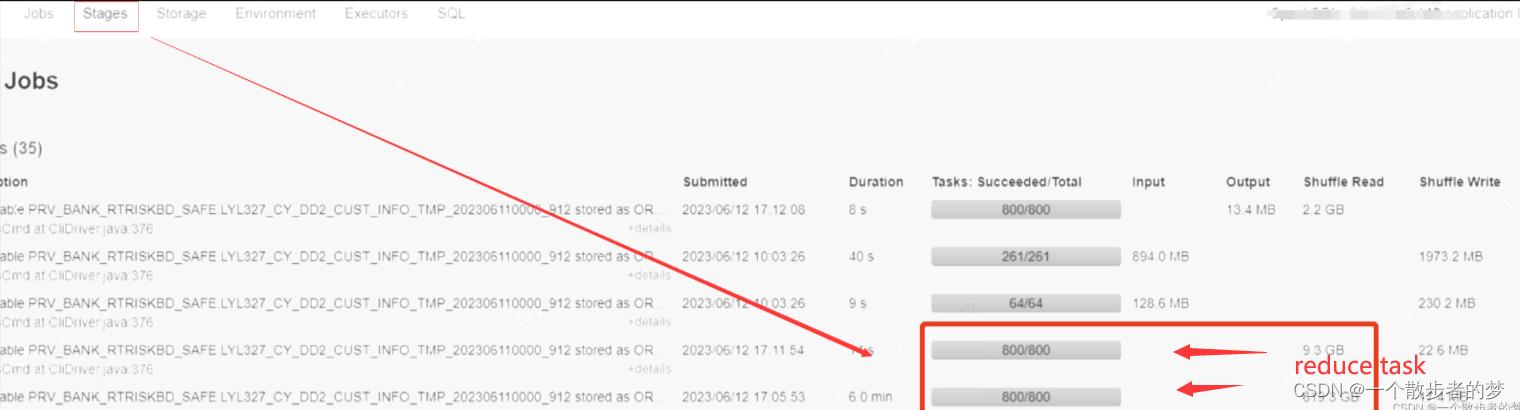
1.x旧版本的Hash Shffle
Spark.Shuffle.manager默认值:Sort。参数说明:设置ShuffleManager的类型。Spark 1.5以后,有3个可选项:Hash、Sort和Tungsten-Sort。
HashShuffleManager是Spark 1.2以前的默认选项,但是Spark 1.2以及之后的版本默认都是SortShuffleManager。
HashShuffleManager中每个map task会生成reduce个数的partition;假设m个map task,reduce个数是r个(取决于spark.sql.shuffle.partitions及动态调整参数),在map端会产生m*r个文件块,即:每个map task,产生reduce个数对应个数的文件;
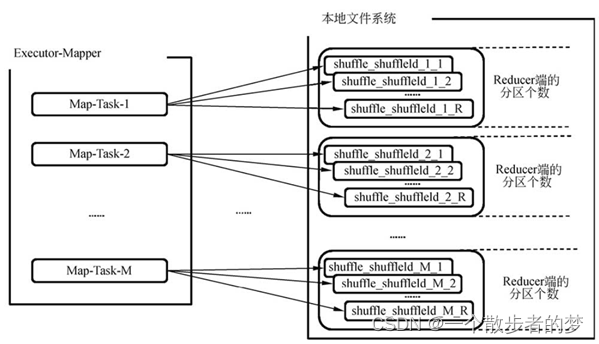
map端一个1t的文件按128m切割,粗估1w个map task,咱们当前集群设置shuffle.partitions个数800,数据量大资源有限的情况下可能设置成2000(reduce个数),按照该种方式,生成文件数10000*2000=2kw,光是文件句柄存储就有2kw条记录;
shuffle写,一个executor中,buffer内存占用为:每个executor分配cpu数 / 每个task计算cpu数 * reduce个数 * 每个buffer配置大小(默认32k)
文件数体量大,一方面会增加对文件系统的压力,磁盘io耗时长。此外,每个map task在写partition文件时都有一个buffer,buffer数多,内存开销大;相较sort shuffle优点是避免了排序开销;
如果map端是100个task,shuffle.partitions设置是800(reduce task个数),第一个task写800个文件要生成800个buff,Buffer0,Buffer1,…Buffern;第二个task仍然要再开辟800个buffer;Buffer一共开辟8w次,产生了8w个本地文件;(下截图map-4个task,reduce-3个task)
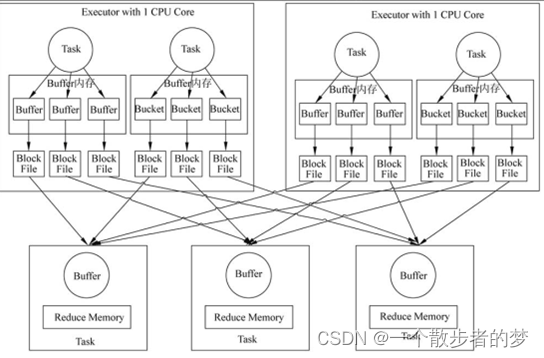
生成的各个文件位于本地文件系统的指定目录中,该目录地址由配置属性spark.local.dir设置;
为减少文件个数,spark引入了文件合并机制,可通过spark.shuffle.consolidateFiles参数配置;开启consolidateFiles后(true),文件写入机制如下:
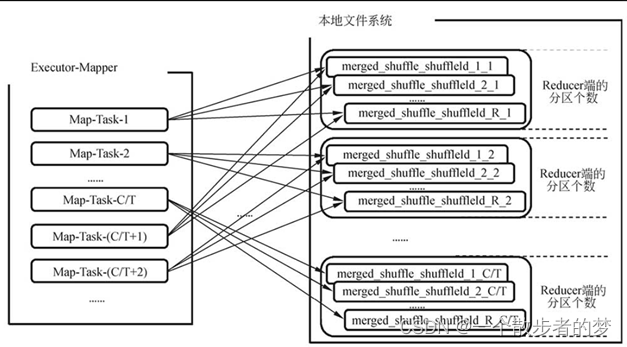
C是executor.cores个数,T是每个task分配计算cpu核数(可通过spark.task.cpus参数配置,默认为1),R是reduce个数
在Mapper端,Task会复用文件组,在一个executor中,最大并行个数为C/T,因此文件组最多分配C/T个,当某个Task运行结束后,会释放该文件组,之后调度的Task则复用前一个Task所释放的文件组,因此会复用同一个文件。最终在该工作点上生成的文件总数为C/TR,如果executor个数为E,则总的文件数为EC/T*R。
虽然减少了产生文件数,文件数体量还是很大;假设一个task有一个c完成,任务配置一共是200个c,作业2000个分区,那么文件数则为:200*2000=40w
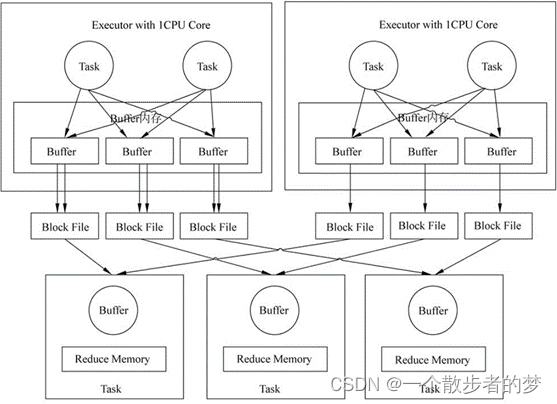
该配置下,进程中所有的Task共用不同的Buffer。例如,第一个Task开辟了Buffer0、Buffer1、Buffer2,第二个Task不需要再开辟Buffer0、Buffer1、Buffer2。
以上Shuffle机制方式在spark2.4.x版本已经废弃
不同于Hash Shuffle会生成很多个文件,Sort-Based Shuffle每个task只会输出两个文件,一个文件是实际数据块,按partitionid排序,另外一个是partition索引文件index;下游reduce作业先读取index文件,根据它的命名规则进行解析去File里获取自己处理的分区部分;
效果如下:
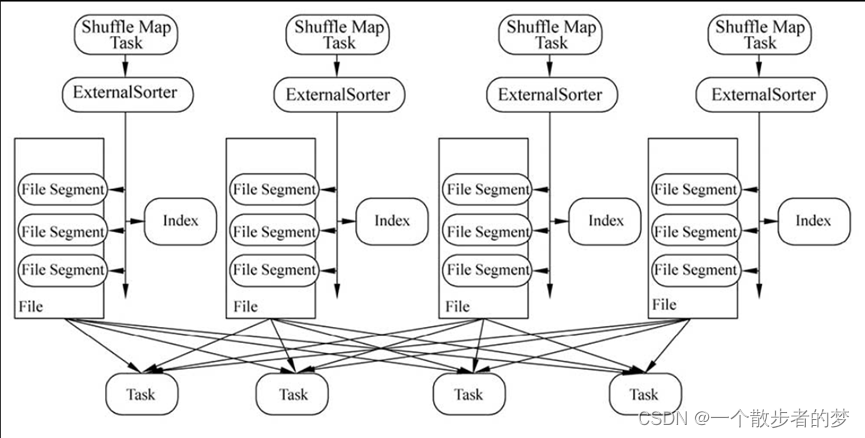
Bypass机制是新版本下的“Hash Shuffle”机制;参数:Spark.Shuffle.Sort.bypassMergeThreshold,默认200;当ShuffleManager为SortShuffleManager时,如果Shuffle Read Task的数量小于这个阈值,且map端没有聚合时,Shuffle Write不会进行排序操作,按照未经优化的HashShuffleManager方式去写数据,但是最后会将每个Task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
同Hash Shuffle一样大的,文件数多,意味着需同时打开多个文件,内存消耗会大些;
2.2 增加shuffle并行度
参数:spark.sql.shuffle.partitions,shuffle后partition的个数,默认是200;设置partition个数一般参考SparkUI执行计划exchange(shuffle)中最大数据量大小,结合每个task预设处理数据量大小设置;
为什么按shuffle最大数据量估partition个数:如果按小了估,分区数少,一旦某个stage数据量大,单个分区(task)处理数据量大,可能executor内存不够;
比如shuffle数据量大小是1个T,每个task预处理2个G大小数据,这样可以设置partitions为500个;(考虑到可能存在数据倾斜,jvm开销等,executor内存适当调大点)
在实际生产中,比如一段sql,可能会涉及多次shuffle;每次shuffle数据量大小不一致;按最大shuffle数据量设置partition个数,可能使得有的shuffle阶段单个task处理数据量很少,资源不能有效利用;
比如如下sql:t1和t2表join,假设shuffle数据量为1个T,设置500个partition是可以的,但到跟T3进行join时,shuflle数据量只有20g,500个partition每个parition就只有0.04个g,单个task处理数据量太小,task数据个数多,消耗大;
select t1.id,t2.sales,t3.product_type
from tablename1 t1
join tablename2 t2
on t1.id=t2.id
join tablename3 t3
on t1.product_id -= t3.product_id
比如下面的截图:
红色框的,shuffle read,一个9.3GB,一个619GB,都是800个task,9个GB的数据800个分区,意味着一个task仅仅处理11MB的数据,调度的开销甚至会大于数据处理的开销,这时候要考虑减少分区数;
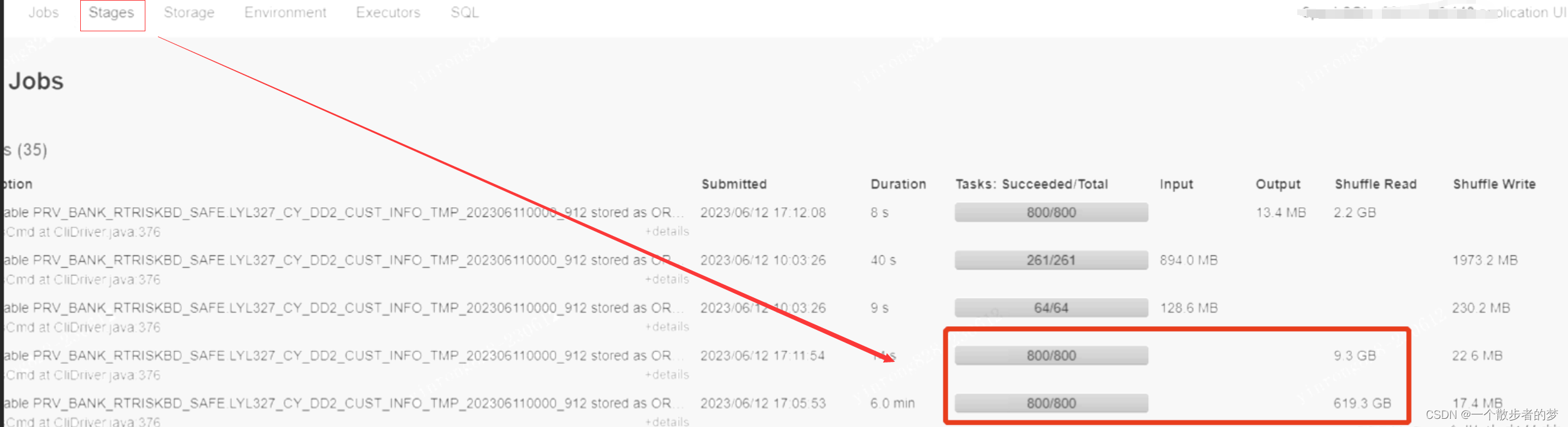
如果集群cpu资源够多,为了提升计算效率,我们可以把executor个数给设置大些;在一定的内存下,增加executor个数,如果分配到单个task内存减少,这时候可以考虑增加spark.sql.shuffle.partitions减少单个task处理数据量;
其他,一般设置合理分区数,我们的根本目的还是希望每一个task能适配合适的计算量。在groupby聚合中,我们要考虑到预聚合数据量的减少(sparkui中可以看到map后shuffle write数据量);比如一个表有1000亿行,数据量很大,我们一般理解可能要把partition个数设置多谢,但如果没有去重计数,groupby分组字段组合枚举值个数有限,比如只有10个,那买个map task在聚合后最多只会输出10行记录,即使map task很多,最后到reduce数据量也很少,这种情况,要把partition适当调小点;
同样的,如果reduce计算逻辑比较复杂,也可以考虑适当减少每个reduce处理数据量;
在hive中,reduce个数有两种设置方法,其一通过参数写死制定个数(除了特殊情况,比如就一个countdistinct,那会只有一个reduce)
mapred.reduce.tasks:设置Reducer的数量,默认值是-1,代表由系统根据需要自行决定Reducer的数量。
方式二,由两个参数控制
hive.exec.reducers.bytes.per.reducer:设置每个Reducer所能处理的数据量,在Hive 0.14版本以前默认是1000000000(1GB), Hive 0.14及之后的版本默认是256MB。输入到Reduce的数据量有1GB,那么将会拆分成4个Reducer任务。单位是b
hive.exec.reducers.max:设置一个作业运行的最大Reduce个数,默认值是999。
按hive.exec.reducers.bytes.per.reducer每个task处理大小估reduce个数,但reduce个数上限不超过hive.exec.reducers.max
一般推荐使用方式二配置,这是基于数据量动态设置;方式二的数据量是根据表filter前数据量估算的,如果一个作业本身可能数据量很大,但是经过filter后或者预聚合后数据量很少,这种情况下,可以根据实际情况采用方式一手动指定reduce个数,或者适当调大hive.exec.reducers.bytes.per.reducer减少reduce个数;
map写入临时文件如果数据量很大,按hive.exec.reducers.bytes.per.reducer估算上限超过hive.exec.reducers.max,这时候可以根据实际情况,适当调大hive.exec.reducers.max;(不然有可能内存不足,当然你也可以增大reduce内存)
2.3 动态分区机制
spark.sql.adaptive.enabled:是否开启调整partition功能,如果开启,spark.sql.shuffle.partitions设置的partition可能会被合并到一个reducer里运行。平台默认开启,同时强烈建议开启。理由:更好利用单个executor的性能,还能缓解小文件问题。
在spark 3.0版本中,开启该参数,执行可以动态切换join策略;比如一个占用内存经过filter,join等算子操作后,输出数据小能载入内存广播join,这时候该stage会由sort join转化为broadcast join;
spark.sql.adaptive.shuffle.targetPostShuffleInputSize:和spark.sql.adaptive.enabled配合使用,当开启调整partition功能后,当mapper端两个partition的数据合并后数据量小于targetPostShuffleInputSize时,Spark会将两个partition进行合并到一个reducer端进行处理。平台默认为67108864(64M),用户可根据自身作业的情况酌情调整该值。当调大该值时,一个reduce端task处理的数据量变大,最终产出的数据,存到HDFS上的文件也变大。当调小该值时,相反。
如果数据量很大,而集群内存资源有限,出现OM内存不够,这时候首先应考虑增加spark.sql.shuffle.partitions个数;
2.4 增加shuffle write的buff大小
spark.shuffle.file.buffer:默认32k,每个混洗输出流的内存buffer大小。这个buffer能减少混洗文件的创建和磁盘寻址。每32k数据write一次,下游shuffle read task也是先将数据载入缓冲区计算,等32k满了再溢写磁盘;增大该参数可以减少io次数(shuflle数据总量还是一样的),内存大可以适当调整,2倍,3倍;减少可以提升任务稳定性,内存占用(内存不够,一般不会优先调该参数,除非万不得已);
2.5 调整shuffle read数据量大小
spark.reducer.maxSizeInFlight:map任务输出同时reduce任务获取的最大内存占用量。每个输出需要创建buffer来接收,对于每个reduce任务来说,有一个固定的内存开销上限,所以最好别设太大,除非你内存非常大。
默认48m,可以根据资源情况适当调大点,
比如96m:set spark.reducer.maxSizeInFlight=96m可以减少文件拉取次数;官网上提示,实践性能会有1%~5%的提升。过大可能会影响网络稳定性,数据读取失败;
2.6 调整重试间隔时间
spark.shuffle.io.retryWait:混洗重试获取数据的间隔时间。默认最大重试延迟是15秒,设置这个参数后,将变成maxRetries* retryWait。
默认5s,可以考虑适当调大,比如60秒,过大就没有必要了,可能问题出在别的地方;
2.7 使用适当shuffle类型
可通过spark.shuffle.manager参数设置
HashShuffle
HashShuffle不会排序,每个map会按照shuffle partition个数R生成R个文件,结果就是M个map最后生成了M*R个文件,极大增加了文件io开销;
考虑到文件数太多,Spark引入了Consolidation机制,优化后的HashShuffle,每个Executor中同一个partition的数据会合并到一个文件,最后也就是E个Executo,每个executor分配C个cpu,每个task分配T个cpu,最后输出E*C/T*R个文件;
早期版本存在该种shuffle类型,在2.0后统一成了SortShuffle
SortShuffle
不同于HashShuffle,SortShuffle会对mapTask的数据进行排序,每个Map数据会产生一个文件和一个索引文件,索引文件记录partition的位置及偏移量;
三种类型:
Sort Shuffle在map端有三种实现,分别是UnsafeShuffleWriter、BypassMergeSortShuffleWriter、SortShuffleWriter。
ShuffleWriter实现选择
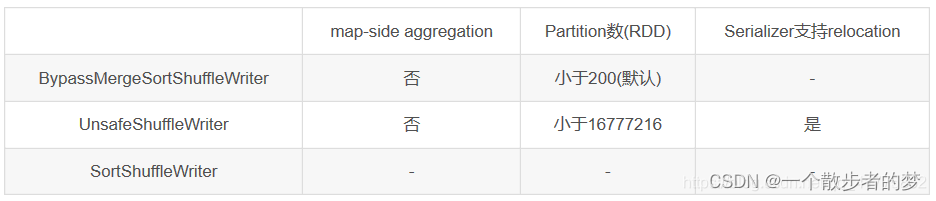
没有map端聚合操作,且RDD的Partition数小于200,使用BypassMergeSortShuffleWriter。
spark.shuffle.sort.bypassMergeThreshold 默认值:200
当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
没有map端聚合操作,RDD的Partition数小于16777216,且Serializer支持relocation,使用UnsafeShuffleWriter。
上述条件都不满足,使用SortShuffleWriter。
Serializer支持relocation是指,Serializer可以对已经序列化的对象进行排序,这种排序起到的效果和先对数据排序再序列化一致。Serializer的这个属性会在UnsafeShuffleWriter进行排序时用到。支持relocation的Serializer是KryoSerializer,Spark默认使用JavaSerializer,通过参数spark.serializer设置。
2.8 shuffle压缩
spark.shuffle.compress:默认true,是否压缩map任务的输出文件。通常来说,压缩是个好主意。压缩算法取决于 spark.io.compression.codec;
这里有一个shuffle数据大小,与压缩与解压的考量,如果shuflle是瓶颈,数据量很大,可以使用压缩;如果压缩与解压缩的消耗超过了减少数据量传输带来的效用提升,则设置为False;
计算作业为cpu密集型,网络带宽够大,这时候可以设置为False;IO密集型可以考虑开启该参数;
2.9 限制文件拉取
spark.reducer.maxReqsInFlight:此配置限制在任何给定点获取块的远程请求数。当集群中的主机数量增加时,可能会导致到一个或多个节点的大量入站连接,从而导致worker在负载下失败。通过允许它限制fetch请求的数量,可以缓解这种情况。
spark.reducer.maxBlocksInFlightPerAddress:此配置限制每个reduce任务从给定主机端口获取的远程块的数量。当在单个获取中或同时从给定地址请求大量块时,这可能会使服务 Executor 或 NodeManager 崩溃。当启用 External Shuffle 时,这对于减少 NodeManager 上的负载特别有用。可以通过将其设置为较低的值来缓解此问题。
同一节点请求数多大,N个reduce从同一节点拉取数据,系统可能会负载。
2.10 内存动态管理
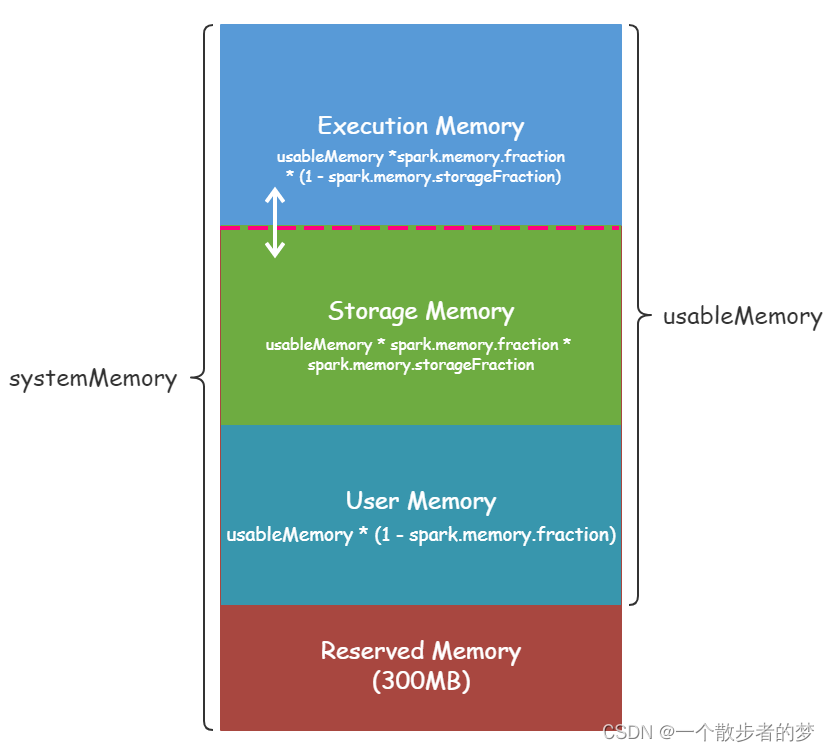
spark.memory.fraction:在Spark 1.6版本中默认0.75,即Spark Memory(Execution Memory + Storage Memory)默认占整个usableMemory(systemMemory - Reserved Memory)内存的75%,而在Spark 2.x版本中默认0.6,默认占usableMemory内存的60%。
spark.memory.storageFraction:默认0.5,代表Storage Memory占用Spark Memory百分比,(1 - spark.memory.storageFraction)代表Execution Memory占用Spark Memory百分比,默认值0.5表示Spark Memory中Execution Memory和Storage Memory各占一半。
如果没有|较少使用广播变量|cahe,可以将该参数调小点;
Execution Memory与Storage Memory彼此之间可以相互共享,当Execution Memory有空闲,Storage Memory不足时,Storage Memory可以借用Execution Memory,反之亦然。Execution Memory可以让Storage Memory写到磁盘,收回被占用的空间。如果Storage Memory被Execution Memory借用,因为实现上的复杂度,却收回不了空间。
估算 Other 内存=自定义数据结构 *每个 Executor 核数
估算 Storage 内存=广播变量 + cache/Executor 数量
估算 Executor 内存=每个 Executor 核数 *(数据集大小/井行度)
2.11 Spark.Shuffle.service.enabled服务
启用外部Shuffle Service,Shuffle Service保留由Executor写入的Shuffle文件,以便Executors可以安全地删除。必须首先把Spark.dynamicAllocation.enabled设置为true,才可以启动这个外部Shuffle Service。NodeManager中一个长期运行的辅助服务,用于提升Shuffle计算性能。Shuffle Service默认为false,表示不启用该功能。
开启动态资源分配后,必须开启该服务;动态资源开启后,spark会再一个应用未结束前,将已经完成任务处于空闲的executor释放,executor释放后,输出文件也会一并被删除,无法供下游stage使用;
3. map端task个数调整
发生shuffle后task个数取决于参数spark.sql.shuffle.partitions,map端task个数取决于如下两个参数:
spark.sql.files.maxPartitionBytes:一个分区最大字节数,默认128m。调大/减少该值可以减少/增加maptask个数
这两个参数一般不用调整;
如果源表字段比较多,逻辑比较简单,资源多,可以考虑增大该参数,比如256m以减少task个数;如果字段少,map逻辑比较复杂,保持默认值或适当调小点,增加map端task个数,减轻单个task计算压力;
spark.files.openCostInBytes:默认4m,打开文件开销;当hdfs存在小文件时,会将小文件进行合并。
n 个文件大小 + n * spark.files.openCostInBytes < spark.sql.files.maxPartitionBytes < (n+1) 个文件大小 + (n+1) * spark.files.openCostInBytes ,在这个范围内,尽可能多的小文件划分到一个map task。划分一个task,小文件总大小加文件打开开销尽可能的接近maxPartitionBytes这个值
比如存在20个小文件,每个文件大小是8m,那这20个文件预估2个task,每10个文件一个task处理:10 * (8 + 4) = 120 < 128
4. 加速spark_df与pandas_df之间的转化
提速,可以添加参数:spark.conf.set("spark.sql.execution.arrow.enabled",True)
在spark_df.toPandas()过程,会将数据回收到driver内存中,如果内存溢出需调整回收driver最大内存参数spark.driver.maxResultSize,
样例如下:设置最大32g
spark = spark = SparkSession.Builder()\
.config("spark.driver.maxResultSize","32g")\
.enableHiveSupport()\
.getOrCreate()
5. 广播join
将数据先回收至driver端,再广播至各个executor;类似与hive中的mapjoin
参数:spark.sql.autoBroadcastJoinThreshold为-1时,表示禁用广播join,默认是小表10mb,开启小表广播join;
reduce端join转至map端join,不存在shuflle,显著提升计算性能;
spark.broadcast.compress:是否在广播变量前使用压缩。默认true,推荐;
在实践中发现有个别情况,大表也被广播了,如果不确定自动广播执行,这时候可以关闭该参数,通过hint写法(比如:/*+mapjoin(smalltable)*/),手动指定小表广播;
6. join倾斜
如下几个参数生效版本:3.0
spark.sql.adaptive.skewJoin.enabled,默认 true,当 和 spark.sql.adaptive.enabled'为 true 时,Spark 通过拆分(并在需要时复制)倾斜分区来动态处理随机连接(排序合并和随机哈希)中的倾斜。
spark.sql.adaptive.skewJoin.skewedPartitionFactor:如果分区的大小大于此因子乘以中值分区大小,并且也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes,则认为该分区是偏斜的
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes:如果分区的大小(以字节为单位)大于此阈值,并且也大于spark.sql.adaptive.skewJoin.skewedPartitionFactor乘以中位数分区大小,则认为该分区是偏斜的。理想情况下,此配置应设置为大于spark.sql.adaptive.advisoryPartitionSizeInBytes(spark进行拆分后,推荐分区大小)
hive中,通过hive.optimize.skewjoin=true参数设置
7. CBO优化
spark.sql.cbo.enabled:配置开启 CBO 后,CBO 优化器可以基于表和列的统计信息,进行一系列的估算,最终选择出最优的查询计划。 比如:Build 侧选择、优化 Join 类型、优化多表 Join 顺序等。
具体看执行计划
SQL优化
1. 数据倾斜
这块主要讲sql语句优化,HIVE大体上适用,重点在数据倾斜;一般倾斜出在reduce端;map端如果数据压缩格式不可分割,也可能会由于数据文件大小差异大导致倾斜,不过此类情况少见;
1.1 什么是数据倾斜
现在一般公司不差计算资源,如果是定时调度作业,数据计算大的任务,可以放到集群闲的时候调度,比如晚上,根据集群资源占用情况,往上堆资源,你会发现一个数据量百tb级别的作业也可以刷得很快;
大数据数据量大,一般不是问题,主要怕数据倾斜,一般发生在reduce端;倾斜是shuffle后,某个key或者少量key数据量远远大于其他key;这样就会造成99%的task可能几分钟计算完,剩下个别task承担了大量的数据,迟迟没跑完;
解决数据倾斜,也就是尽量保证各个task处理的数据量差异不要很大(根本上应该讲各个task计算量),各个task负载均衡,尽可能快地完成作业计算;
有数据倾斜,是否一定要处理:不是;倾斜根本上是数据分布不均匀,绝对意义上说,每个作业都会存在数据倾斜,只是倾斜程度不一样;即使一个作业数据倾斜程度比较重,但如果计算时效在我们接受的范围内,其实也没必要处理;比如1分钟,和5分钟,对实际生产可能没什么区别;执着于数据倾斜处理,可能会延误业务需求;
怎么识别数据倾斜:如果一个作业计算时间过长(不能接受),可以查看SparkUI,查看各个stage下(先挑跑批时间最长stage看),task的计算时间;
比如下面截图,这个stage中,task最长计算时间10s,中位数和上四分位不超过20ms,是有明显倾斜;但该stage整体计算时间比较短,多几秒少几秒,倾斜影响基本可以忽略;

怎么定位倾斜位置:结合执行计划判断
作业跑批时间长不一定有数据倾斜,可能是数据量大资源少;
1.2 倾斜key抽样
在Spark算子中可以使用df.sample(n)抽样找出倾斜异常key,
使用SQL抽样,我们可以这样:
-- 抽样
select field_key
,count(1) as cnt
from table_name
where rand() < 0.01 -- 根据实际数据量,抽样
group by field_key
having count(1) > 10000 -- 根据业务实际情况,筛选大key
order by cnt desc -- 按数据量进行排序
limit 20 -- 查看数据量最多的20个key
1.3 过滤倾斜的key
比如业务中爬虫异常key,null,df.filter(func)过滤掉倾斜key。如果key中的null倾斜需要保留,我们可以将null数据单独拿出来进行处理,比如:
-- 假设a.mobile存在大量的null倾斜
select a.id
,a.mobile
,b.fields
from table_a
left join table_b
on nvl(a.mobile,rand()) = b.mobile
-- 或者使用union all改写,单独摘出来再拼接上去
select a.id
,a.mobile
,b.fields_name
from table_a a
left join table_b b
on a.mobile=b.mobile
where a.mobile is not null
union all
select a.id,a.mobile,null as fields_name
from table_a a
where a.mobile is null
-- 过滤异常key
select groupby_field
,count(1) as cnt
from table_a
where groupby_field <> '异常key'
group by groupby_field
nvl(a.mobile,rand()) = b.mobile会将key是null打散shuffle到不同分区里;但null这部分数据还是会有shffle,会有网络传输;如果使用union all改写,该null部分则不需要发生shuffle,如果null数据量很大,建议union实现方式;当然,如果理想最好直接把这部分在map端给剔除掉,这里主要看业务是否要保留该部分数据;
1.4 增加shuffle并行度
如果各个key的数据量整体差异不大,task < executor_num(executor个数) * executor_cores(每个executor的核心数),我们可以考虑增加task数量,来充分利用计算资源;
在SparkSQL中使用spark.sql.shuffle.partitions参数设置并行度(默认是200),一般设置每核跑2-3个task(官方推荐),磁盘io时可以充分利用计算资源。spark.default.parallelism只对rdd生效,在sparksql中并行度由spark.sql.shuffle.partitions决定。
有时候reduce任务内存溢出,并不是要单单去调整内存大小,可以增加shuflle.partition的个数,减少单个task数据量大小。如果不确定,可以先调大点,让任务先跑起来,再视实际跑批时效微调节;
spark中有很多算子有指定并行度参数,比如:
textFile(xx,minnumpartition)
sc.parallelize(xx,num)
sc.makeRDDD(xx,num)
sc.parallelizePairs(List[Tuple2],num)
redduceByKey(xx,num),groupByKey(xx,num),join,distinct
repartition,coalesce
增加shuffle partition的个数,适用于多个大key的情况,单个分区记录行减少。对于单个key数据量过度倾斜,不适用,不论怎么分区都会存在倾斜。

1.5 双重聚合
类似于hive中的groupby倾斜参数set hive.groupby.skewindata=true,用两个mr计算作业,第一个mr中的key随机分发聚合,第二个mr做全局聚合;比如:
select groupby_field
,sum(cnt) as cnt -- 全局聚合
from
( -- key打散聚合
select ceiling(rand() * 10) as rnd -- 添加随机数打散
,groupby_field -- 分组字段
,count(1) as cnt
from table_name
group by ceiling(rand() * 10),groupby_field
) t
group by groupby_field
以上方式,如果明确倾斜的key更合适的操作应该是对指定倾斜key打散,其他的不做打散。以上sql案例会把原来不需要打散的key也一并打散了
如果是hive作业,也可以考虑把倾斜的key和非倾斜的key拆开,分别groupby聚合后再unionall起来。
Hive以上groupby倾斜参数不适用于count (distinct xxx)
在实践中,某些案例我们发现hive使用该参数,相比原倾斜作业,跑批时间是减少了,但就效果而言,不如手动打散处理
1.6 使用mapjoin
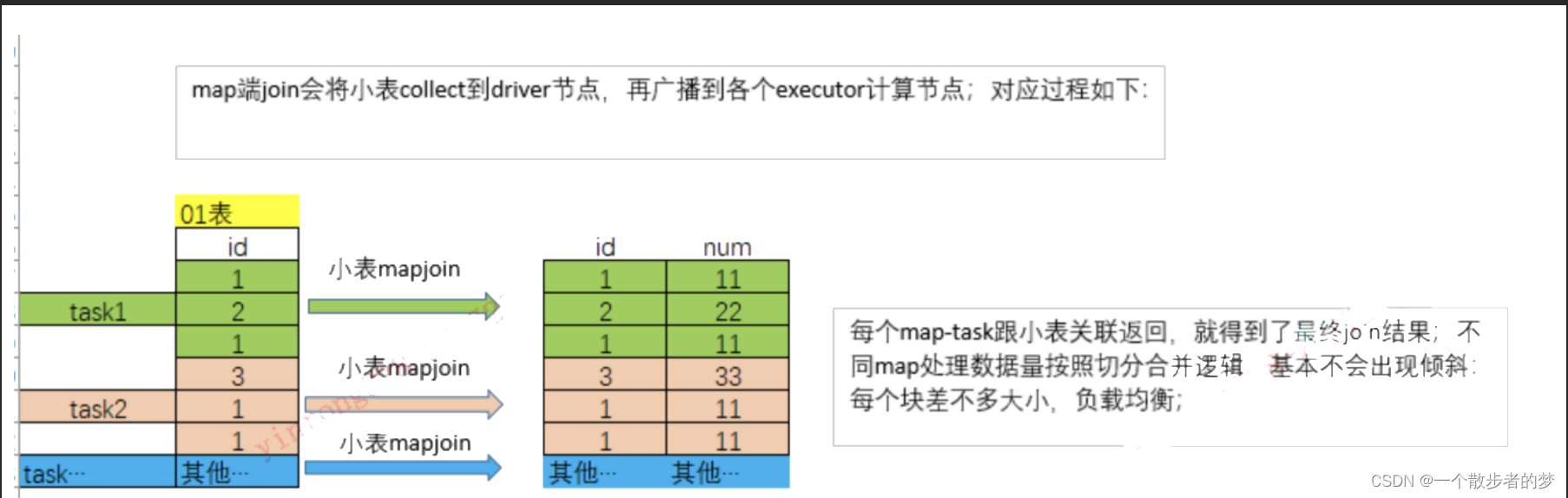
如果存在小表情况下,可以使用mapjoin,将小表回收到driver端,再广播到各个执行的executor上应用map关联;此场景使用于大表join小表的情况;
这里需要注意,在外连接时,比如left join或者right join,full join,小表是主表,mapjoin不生效
select /*+mapjoin(b)*/ a.id
,b.fields_name
from table_a a
join table_b b -- b小表
on a.id=b.id
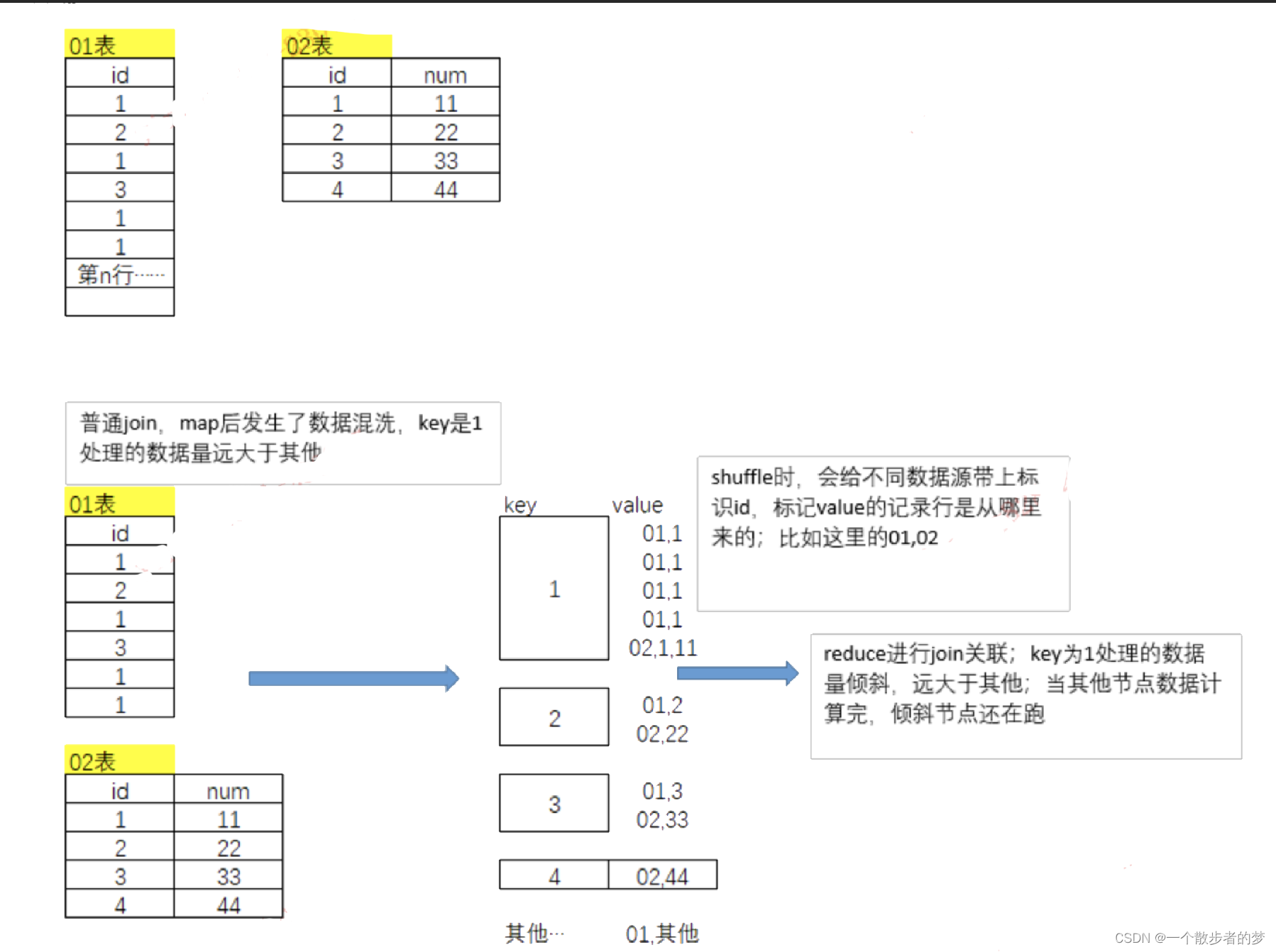
正常的shuffle join过程:两个表用id字段关联,01表id倾斜,导致id为1的纪录都分到一个task里边,该task计算时间远大于其他
适用mapjoin过程:把小表广播到每个executor中,因为map端数据量按分块,基本都差不多,各个task处理时间也就差不多;
1.7 join中倾斜key单独摘出来操作
在hive中会有join倾斜参数,hive.optimize.skewjoin=true;它会将join作业拆分成两个MR,对于倾斜健部分单独摘出来使用mapjoin处理,非倾斜键走正常reduce的join。在spark中,如果倾斜键数据符合大表+小表原则,也可以使用该策略。如果倾斜健两个表的数据都比较大,大表倾斜部分同一个key添加n种前缀,小表膨胀倾斜健部分膨胀n倍,倾斜部分join,再union 非倾斜部分join
select a.id,a.field_a,b.field_b
from
( -- 加入随机数
select id,field_a,ceiling(rand()*10) as rnd_name
from table_a
where id in ('倾斜健')
) a
join
( -- 数据膨胀
select id,subview.rnd_name,field_b
from table_b b
lateral view explode(array(1,2,3,4,5,6,7,8,9,10)) subview as rnd_name
where b.id in ('倾斜健')
) b
on a.id=b.id and a.rnd_name=b.rnd_name
union all -- 拼接非倾斜部分的join
select a.id,a.field_a,b.field_b
from table_a a
join table_b b
on a.id=b.id
where a.id not in ('倾斜健') and b.id not in ('倾斜健')
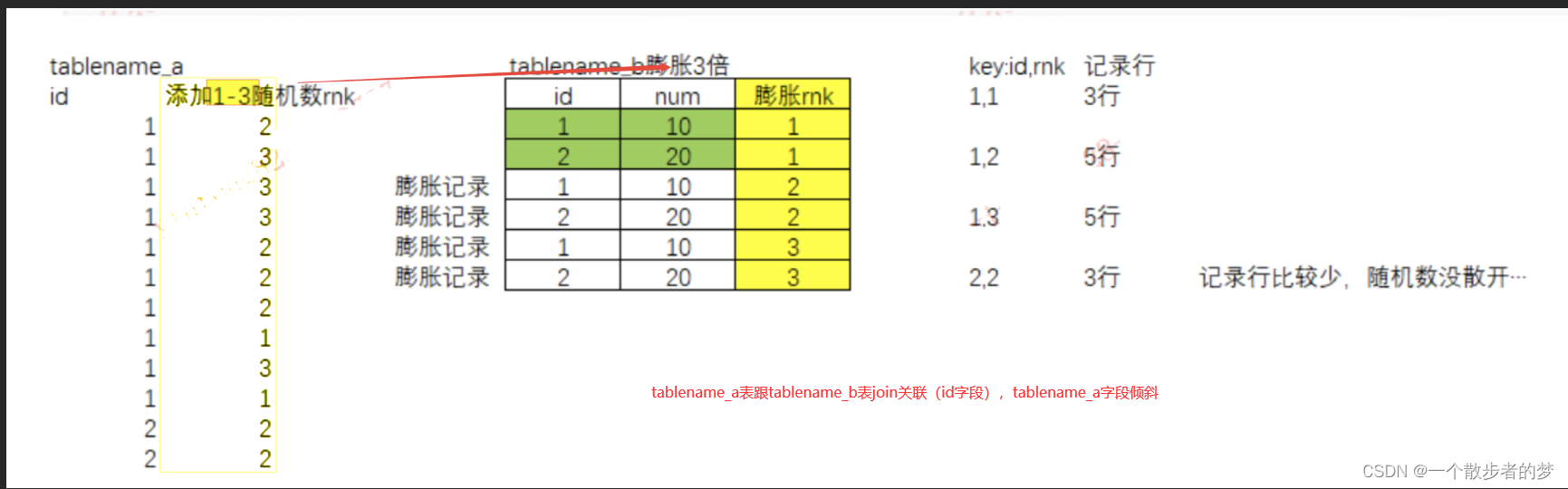
两个表笛卡尔积,通常会扔到单个reduce-task里处理,在优化方面也可以参考该策略,大表添加随机数1~n,小表膨胀n倍,增加task个数,减少单个reduce-task处理数据量;
使用添加随机数+数据膨胀这种方法,一定程度上解决了数据倾斜,但数据膨胀增加了shuffle数据量,增加了磁盘io,排序计算,网络传输开销;膨胀的倍数不宜过大,这里要根据实际情况权衡;
如果明确倾斜键,大表join大表,也可以针对指定倾斜键打散
select a.id,a.field_a,b.field_b
from
( -- 加入随机数
select id,field_a
,case when id in ('倾斜健') then cast(ceiling(rand()*10) as string) else '0' end as rnd_name
from table_a
) a
join
( -- 数据膨胀
select id,subview.rnd_name,field_b
from table_b b
lateral view explode(split(case when id in ('倾斜健') then'0,1,2,3,4,5,6,7,8,9,10' else '0' end,',')) subview as rnd_name
where b.id in ('倾斜健')
) b
on a.id=b.id and a.rnd_name=b.rnd_name
这样,对于较小表,非倾斜部分没必要跟着一起膨胀了。当然如果数据量不大,比如就一两百万,整体膨胀个几十倍问题也不大
1.8 多表join倾斜特殊情况
有如下一段sql,我们从日志里发现了倾斜
select a.filed_aa,c.field_cc
,count(b.id) as cnt
from table_a a
join table_b b
on a.field_b=b.field_b
join table_c c
on a.field_c=c.field_c
group by a.filed_aa,c.field_cc
该sql,三个表都是大表,表a和表c数据量1个亿+,表b数据量100亿+,通过统计key的分布,我们发现倾斜出在表b上,表b的field_b分布极为不均衡;这类情况mapjoin不合适,都是大表;也不完全一定要按打散b表的field_b字段,膨胀a表field_a字段处理;如果b表的field_b字段先groupby聚合能解决这个倾斜问题,那么逻辑可以这样改写:
select a.filed_aa,c.field_cc
,sum(b.cnt) as cnt
from table_a a
join ( select field_b,count(1) as cnt from table_b group by field_b) b -- 如果聚合后解决了field_b倾斜问题
on a.field_b=b.field_b
join table_c c
on a.field_c=c.field_c
group by a.filed_aa,c.field_cc
此类优化方案还是要视具体情况分析
2. 调整join关联的顺序
假设我们有这样一条sql:
记录:t1表10亿,t2表用户维度维表:1亿;t3表用于关联过滤:20万;
t1表与t2表join的记录行10亿,再与t3表关联的记录行是1千万;
查看执行计划,计算顺序是从上往下走,这时候可以调整join中表顺序,先t1与t3表join,减少后续join构成shuffle数据量
select t1.id,t1.name,t2.age,t3.sales,t4.product_type
from table_name1 t1
join table_name2 t2
on t1.id=t2.id
join table_name3 t3
on t1.type=t3.type
left join table_name4 t4
on t1.join_field = t4.join_field
调整后为:
select t1.id,t1.name,t2.age,t3.sales,t4.product_type
from table_name1 t1
join table_name3 t3
on t1.type=t3.type
join table_name2 t2
on t1.id=t2.id
left join table_name4 t4
on t1.join_field = t4.join_field
有的cbo成本会对执行逻辑优化,具体查看执行计划确定物理执行过程
3. 数据累全量
比如拉取最近30天日活用户,当前数据仓库有一张日活跃表,日分区;每次作业需要拉取近30天分区数据,数据量极大
这时候可以建一张中间表,记录近30天活跃用户以及用户最后活跃字段,库表名:table_name1
select user_id
,max(dt) as last_active_date -- 最后活跃日期
from user_active_info
where dt >='20230501' and dt <= '20230530'
group by user_id
然后该中间表修改任务,当天分区为,昨日数据剔除最后活跃日期在29天 + 当天活跃信息,按用户去重
select user,max(last_active_date) as last_active_date
from
( -- 昨天近29d活跃+当日活跃=截止当日近30d活跃
select user_id,last_active_date
from table_name1
where dt='20230530' and last_active_date>='20230502'
union all
select user_id,'20230531' as last_active_date
from user_active_date
where dt='20230531'
) uu
group by user_id
4. 数据预聚合
对于在join过程中,子表如果提前聚合能显著减少后续shuffle数据量,允许的话应事先按key聚合
比如下面一段sql:t1表取了31d的数据,假设每天数据量10亿,31d去重数据量在12亿,不去重31d数据量310亿,那在join关联时应尽可能做事先去重,这样每阶段该表shuffle数据量只有12亿;
select t1.id,t2.field1,t3.field2
from table_name1 t1
left join table_name2 t2
on t1.id=t2.id and t2.dt='20230531'
left join table_name3 t3
on t1.id-t3.id and t3.dt='20230531'
left join table_name4 t4
on t1.type=t4.type and t4.dt='20230531'
where t1.dt >= '20230501' and t1.dt<='20230531'
5. 多维分析的union改写
比如如下一段sql:
select case when grouping(key_field)=-1 then '-914' -- 全局求和
else key_field end as key_field
,sum(sales) as sales
from tablename
group by key_field with rollup
执行时,数据会膨胀一倍,倘若维度多,数据量大,shuffle性能比较差,资源有限可能会出现OOM;
这时候可以考虑使用union all改写策略,每维度读一次数据聚合再union all起来,改写如下:
select '-914' as key_field -- 全局求和
,sum(sales) as sales
from tablename
union all
select key_field
,sum(sales) as sales
from tablename
group by key_field
两者区别:数据量比较小,适合使用rollup,cube等多维聚合操作;
多维聚合看,数据量大使用union all改写可能会更为合适:分别读取 + 聚合计算 + union
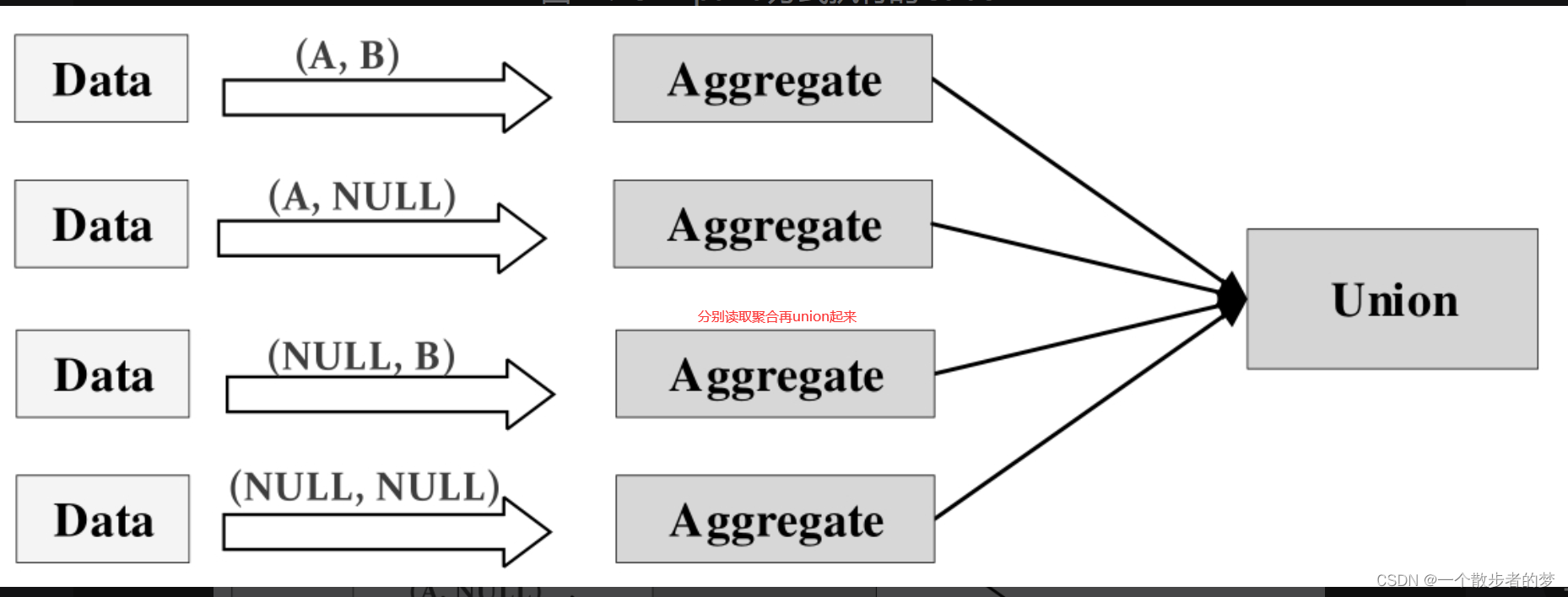
腾讯的tdw对多维聚合函数逻辑进行了union改写;
6. 全局排序问题
对于全局排序,直接使用orderby,会扔到一个reduce-task里;如果数据量大,一方面内存扛不住,另一方面即使内存足够大,一个task不知道要干到什么时候了;这时候可以考虑分而治之的方式;
假设我们有一个表,表名:tablename1,数据有100亿行,按字段p进行row_number全局排序,这时候我们可以这样处理,先求出字段p归一化的对应的值,pn归一化转化公式为:pn-min(p字段)/(max(p字段)-min(p字段);归一化后的值在0-1之间
这里可以先计算出字段的最大值,最小值,将得到的结果表mapjoin到明细表;假设这个字段命名为p1
with t1 as
(
select id,p1,ceil(p1*1000) as sub_level,
row_number() over(partition by ceil(p1*1000) order by p1) as sub_order
from table_source
),
t2 as (
-- 获取每个分桶的起始排序(使用sum over累加计算得出的当前分桶与比他小的分桶累计了多少条记录)
select sub_level,(sum(cnt) over(order by sub_level) - cnt) as base_order
from
(
-- 获取每个分桶的数量
select sub_level,count(1) as cnt
from t1
group by sub_level
) t
)
-- 起始排序 + 组内排序就是全局排序
select id,p1
,base_order + sub_order as global_order -- 全局排序字段
from t1
left join t2 on t1.sub_level = t2.sub_level
该方式将p值数据打散成1000份,分到1000个reduce里,每个reduce内做局部排序,最后再全排;这样能避免100亿行数据分到1个task里;如果切片后数据存在倾斜,可以将切片数再设置大点,亦或看下切片总记录行,使用case when手工做下切片调整,把倾斜的key使用随机数再打散;
参考:https://blog.csdn.net/eaglejava2015/article/details/126594170
假设将p值切成了5个分片,计算结果如下:
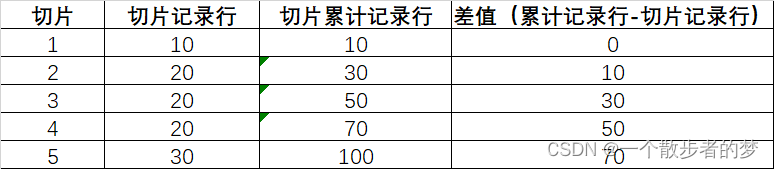
这时,如果一条记录p2在切片2上,在切片2的局部排序是14,那p2的全局排序是差值+局部排序=10+14=24
7. 小表leftjoin大表
小表走map端join有其适用范围,当外连接,小表是主表时不适用;这时候会走shufflejoin;这种情况可以考虑如下改写
旧sql逻辑:
select a.id,a.sales_name,b.num
from tablenamea a -- 小表
left join tablenameb b
on a.id=b.id
优化后的sql逻辑为:
select a.id,a.sales_name,b.num
from tablenamea a -- 小表
(
select a.id,a.sales_name,b.num
from tablenamea a -- 小表
join tablenameb b -- 这里改成join,走mapjoin
on a.id=b.id
) b
on a.id=b.id
这里首先还是看执行计划,如果旧sql逻辑直接走的是一段shufflejoin,可以考虑如此改写;
前后的区别时,两者都有一次shuffle,但是优化后的逻辑,大表join小表走的是mapjoin,shuffle的数据量接近小表数据量(大表小表join后的数据量+小表数据量);而优化前的shuffle数据量为大表+小表数据;
此种改写,大表越大(比如日志表),运行速度提升越明显
8. 同一个字段多个countdistinct
如果分组聚合后是对同一个字段进行去重计数只是条件不同时,每个countdistinct数据会膨胀一倍,为减少数据量,可以考虑如下改写方案:
原sql
select group_field
,count(distinct case when flag1=1 then userid end) as dis1
,count(distinct case when flag2=1 then userid end) as dis2
,..... 此处省略若干字段
,count(distinct case when flagn=1 then userid end) as disn
from db_table_name
group by group_field
改写后的sql:做了两阶改写,多了一个mr,但没有数据膨胀
select group_field
,count(case when flag1=1 then userid end) as dis1
,count(case when flag2=1 then userid end) as dis2
,..... 此处省略若干字段
,count(case when flagn=1 then userid end) as disn
from
(
select group_field,userid
,max(flag1) as flag1
,max(flag2) as flag2
,...
,max(flagn) as flagn
from db_table_name
group by group_field,userid
) t
group by group_field
9. 结合业务具体情况优化
合理评估业务需求,降低任务计算开销;更多优化策略,具体问题具体分析;
其他优化
1. 本地化执行
适用于数据量比较小的情况,比如十万级别,初始化Session时制定master为local即可;一般相较集群模式更快;
local[*]表示限制资源下本地所有核心数;或者也可以按需制定,比如2核:local[2]
from pyspark.sql import SparkSession
spark = SparkSession.Builder()\
.appName('app_name')\
.master("local[*]")\
.enableHiveSupport()\
.getOrCreate()
2. 限制申请资源
如果数据量小,不需要集群默认配置资源那么多,可调小资源申请,这样即便在集群资源紧张的情况下,也更容易触发调度,一定程度能避免集群资源不够而导致的调度等待;比如减少executor的个数,核数/个,内存等;
3. 合并输出小文件
对于partiton个数,最后一个reduce如果没有小文件合并,多少个task写hive表对应多少个文件块;
文件小,文件块数多,数据读取时需要更多的task开销;map如果没有文件合并,文件块大小没达到切分上限,一个文件块对应一个task;
如果作业输出数据小,可以在输出时使用coalesce或repartition算子减少分区后再写入;比如:spark_df.coalesce(1).write.formt('orc').mode('overwrite').saveAaTable("dw_pub_safe.dw_pub_xxx_nfo")
这样,到hdfs下,只会看到一个文件块;
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
repartition算子实际是调用了coalesce算子,发生shuffle;如果无需shuffle,使用coalesce会更快些;
如果处理数据量,可以考虑spark.sql.shuffle.partitions参数设置小些以减少输出文件数;
在sql中,可以考虑使用hint语法合并,比如 (tablename为表名):insert overwrite table tablename /*+coalesce(5)*/ select ...from .../
亦可以考虑在作业计算后使用hive指令合并分区文件块:
alter table tablename(dt='20231130') concatenate
4. 持久化
对于DataFrame|rdd计算优化,在代码层面,如果多次使用,应使用cache(),persist()持久化,避免DataFrame|rdd重复计算
5. With视图
在一些SQL语句中,可能会用到with语句,有的版本with子句只是一个虚拟视图,没有物化。如果对于with子表,SQL中有多次引用,with逻辑会重复计算。计算量大应该考虑将with子句建立中间落地表,以减少任务重复计算。
比如如下一段sql(大概):tmp1调用了两次,如果tmp1没有物化,那with这段逻辑即调用了两次,如果with子句逻辑复杂,重复调用多次,任务消耗就可想而言了;
with tmp1 as (select xxxx from xxxx join xxx on xxx group by xxx where xxx)
select xxxx
from tmp1
group by xxx
union all
select xxxx
from tmp1
left join xxx
on xxxx
group by xxxx
with语句可读性相对较好,也要根据实际情况考虑性能;
具体参考执行计划
6. 尽可能使用高性能算子
尽量避免shuffle类算子,尽量使用有map端聚合算子,比如reduceByKey,aggregateByKey(可以自定义map端聚合函数,自定义初始记录),combineByKey(类同aggregateByKey,初始记录为rdd数据行)
这样可以减少shuffle write数据量,shuffle读数据量,redduce端聚合次数;
尽量使用高性能算子,比如用reduceByKey取代groupByKey;使用mapPartitions取代map(在关系型数据库应该该算子,一次读取n行,相对一次读取1行可以减少连接开销);
数据filter过滤后使用coalse减少分区,使得一个task匹配适当的数据量;
7. 作业的拆解与关键链路优化
这里主要是就提升特定作业时效而言的;通常的,在数仓开发中,一个作业中间有数层加工;我们优化中间作业时效不见得能提升目标作业时效;这里要先梳理作业关键路径,再看提升哪个作业时效能提升目标作业时效;

以上情况,因为B作业没在关键链路上,缩小该作业计算耗时并不能提升C作业时效;关键链路为:A -> C
另外一方面,就目标作业而言,通常一个作业是直接依赖多个作业(表);对于作业中某部分逻辑如果能单独摘出来,而这部分依赖时效满足比较早,可以将这部分逻辑先单独拆出来前置计算;可根据实际情况,对于某些对作业时效要求比较高的作业,这块也是优化的方向;

假设结果作业依赖:A/B/C/D/F,从左往右依次为完成时间顺序
参数值默认值、具体设置以及是否生效,参考具体开发环境,不同版本可能会有所区别;
参考
- Spark官方文档:https://spark.apache.org/docs/latest/configuration.html#shuffle-behavior
- 尚硅谷Spark3.0:https://www.bilibili.com/video/BV1QY411x7xL/?spm_id_from=333.1007
- 《SparkSQL内核剖析》- 朱峰
- 《Spark技术内幕(深入解析Spark内核架构设计与实 现原理)》- 张安站
- 《Spark海量数据处理》- 范东来
- 《Spark大数据商业实战三部曲》 - 王家林、段智华
- CSDN博客:https://blog.csdn.net/qq_41775852/article/details/104805354
- CSDN博客:https://blog.csdn.net/u011598442/article/details/99797294
- CSDN博客:https://blog.csdn.net/longlovefilm/article/details/121418148

















 2201
2201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









