







 本文详细介绍了scapy库在数据包分析中的基本函数,如rdpcap(), show()和sessions()方法,以及如何提取数据包的源IP地址、会话分组和内容。通过实例展示了如何在不同层次提取数据包信息,适合想要学习数据包分析的读者。"
50755827,4994469,理解与实践:系统调用的封装技术,"['操作系统', 'C语言', '系统编程', 'Linux内核']
本文详细介绍了scapy库在数据包分析中的基本函数,如rdpcap(), show()和sessions()方法,以及如何提取数据包的源IP地址、会话分组和内容。通过实例展示了如何在不同层次提取数据包信息,适合想要学习数据包分析的读者。"
50755827,4994469,理解与实践:系统调用的封装技术,"['操作系统', 'C语言', '系统编程', 'Linux内核']
在上一篇文章中讨论了在windows下安装配置scapy环境,这章我们讲解析如何使用scapy进行数据包分析。
基本函数介绍
rdpcap()
该方法是在解析数据包的时候读入pcap文件所需要调用的方法。调用当方式:
path_pcap='this is the path of pcap file'
f=scapy.rdpcap('path_pcap')该函数返回的f是一个scapy.plist.PacketList(可以看做一个list进行运算)类型可以通过f[i]来读取第i+1个数据包(因为list从0开始计算,不是第一个)例如读取第一个数据包的内容,可以使用f[0]来找到第一个数据包,使用f[0].show()或f[0].display()进行数据包格式化打印。
在调用该方法的时候会将整个pcap文件读入到内存中,这样的情况下,当pcap文件过大的时候将会出现解析速度奇慢无比。建议处理的数据包的大小不要过大。
show()方法/display()
这两种方法都可以看到数据包的层次结构,例如:
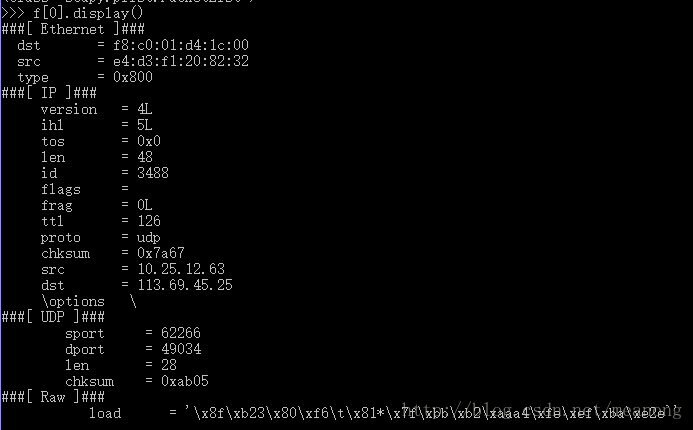
其中f[0]指第一层,通过f[0].payload可以得到该层协议的载荷部分,通过重复调用payload方法可以找到自己需要的层,并对其下的字段进行提取分析。
例如:我们可以通过以下方法获取数据包的源ip地址

通过类似的方式,我们可以对数据包的任意字段进行提取。对数据包进行整体的分析。
sessions()方法
该方法将读入的数据包列表分为对话组存储,以源IP和目的IP为分化标准,但是当源IP和目的IP位置变换的时候将会被视为不同的分组,所以在使用的时候要注意。
可以通过一下方式对sessions结果进行简略输出:
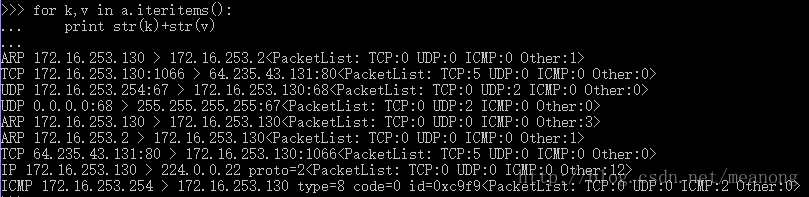
其中包含了会话分组以及对应的协议,以及对应的数据包数量。
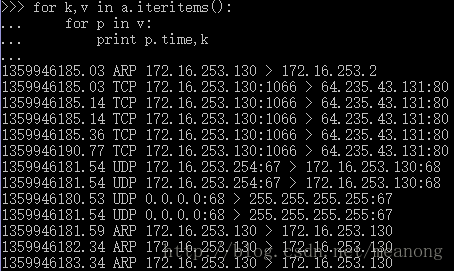
通过如下方式还可以输出对应的数据包的时间
数据包的信息提取处理大概就这么多了,有问题欢迎提问。
数据包对应内容提取
在scapy库中,数据包是按照show()的层次对每一层的数据包进行管理的。我们可以通过以下关键字
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1908
1908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









