






最近做一个学习项目,主要是爬取b站的动画评分并将数据可视化处理。之前并没有学过任何相关知识,也算是从零开始。必定会有很多的错误,还希望大家能够指出,万分谢谢。
主要的步骤有三步。
爬虫爬取评分并将其保存。
用pyechart库进行数据可视化处理
用pyside6来进行GUI界面开发
这一篇文章主要记录爬虫的学习过程
爬虫爬取B站动画评分
爬虫的入门视频看的是B站的《python爬虫入门实战案例教程-入门到精通(收藏版)》。这里先简单解释下基础的概念。
HTML:就是编写网页使用的语言,它定义了一个网页的组成。HTML结构都是由标签组成。例如
<html>
#<>中间的字母,就是‘标签’。
<head>
<meta charset="utf-8">
</head>
<body>
<h1>我是一级标题</h1>
# 标签通常是成对出现的。前面有<h1>,后面就有</h1>
<h2>我是二级标题</h2>
<h3>我是三级标题</h3>
<p>我是一个段落。一级标题、二级标题和我,我们三个一起组成了body。
</p>
</body>
</html>在实际爬虫中,通常需要先分析网页的结构,找到我们感兴趣内容在哪里,并通过一些方法提取出它们。
在任意网页上点击鼠标键右键,点击检查
组成这个网页的HTML非常复杂,难以找到想要的信息
可以先选中任意元素,例如文字,图像等再检查就可以直接跳到想要的信息了
requests:向网页发送HTTP请求并得到返回的HTML数据。直白说就是模拟人类访问网站。不少网站有反爬虫机制,也是通过requests来绕开这些机制。
BeautifulSoup:解析HTML发来的数据。
决定采用requests和BeautifulSoup库。不多逼逼,直接开爬。
先打开动画评分网页
奇幻世界舅舅第13集-番剧-全集-高清独家在线观看-bilibili-哔哩哔哩
随便检查一个评论
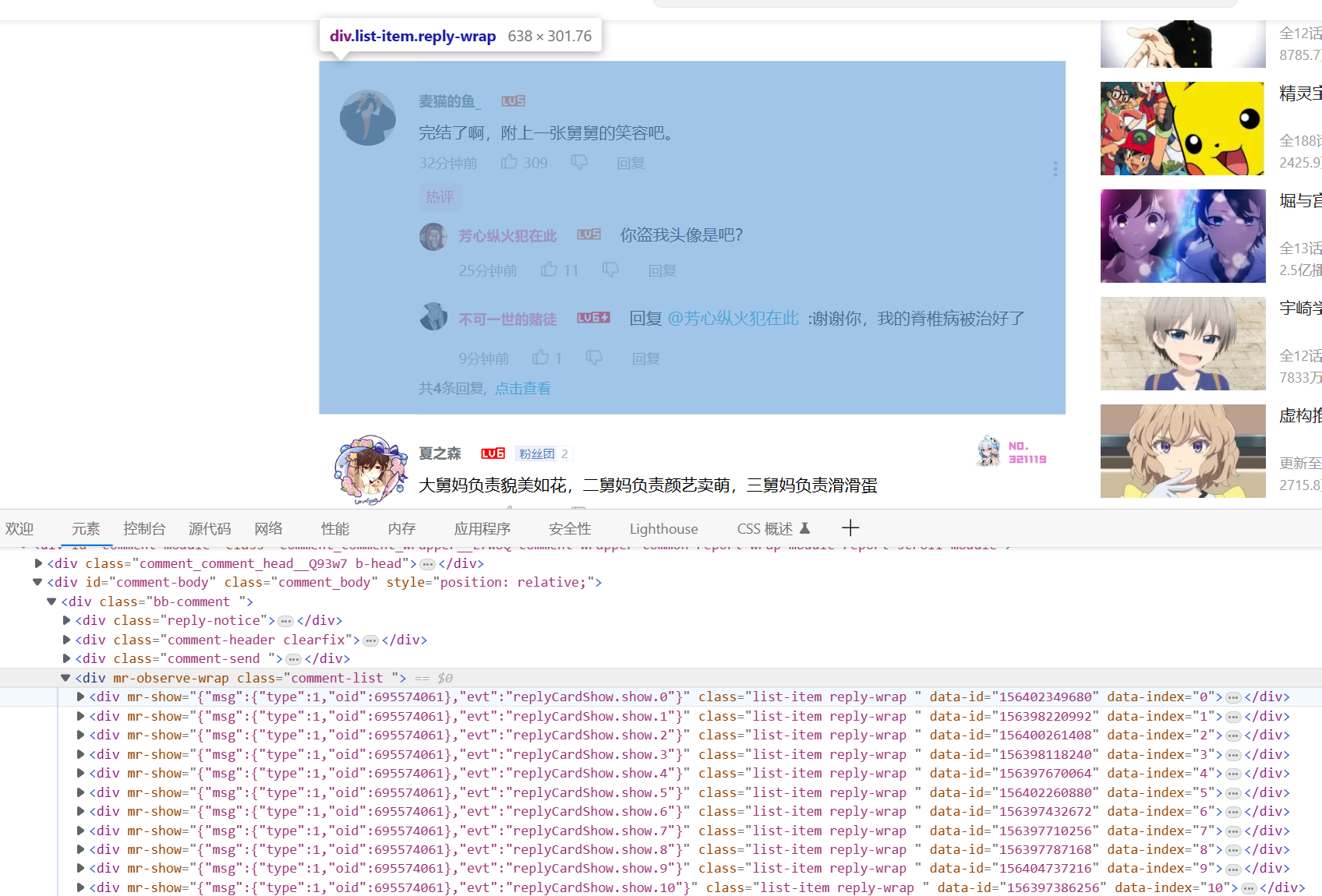
可以看见评论都放在"div","class="comment-list ""下面。那么直接爬取这段的信息即可。上代码!
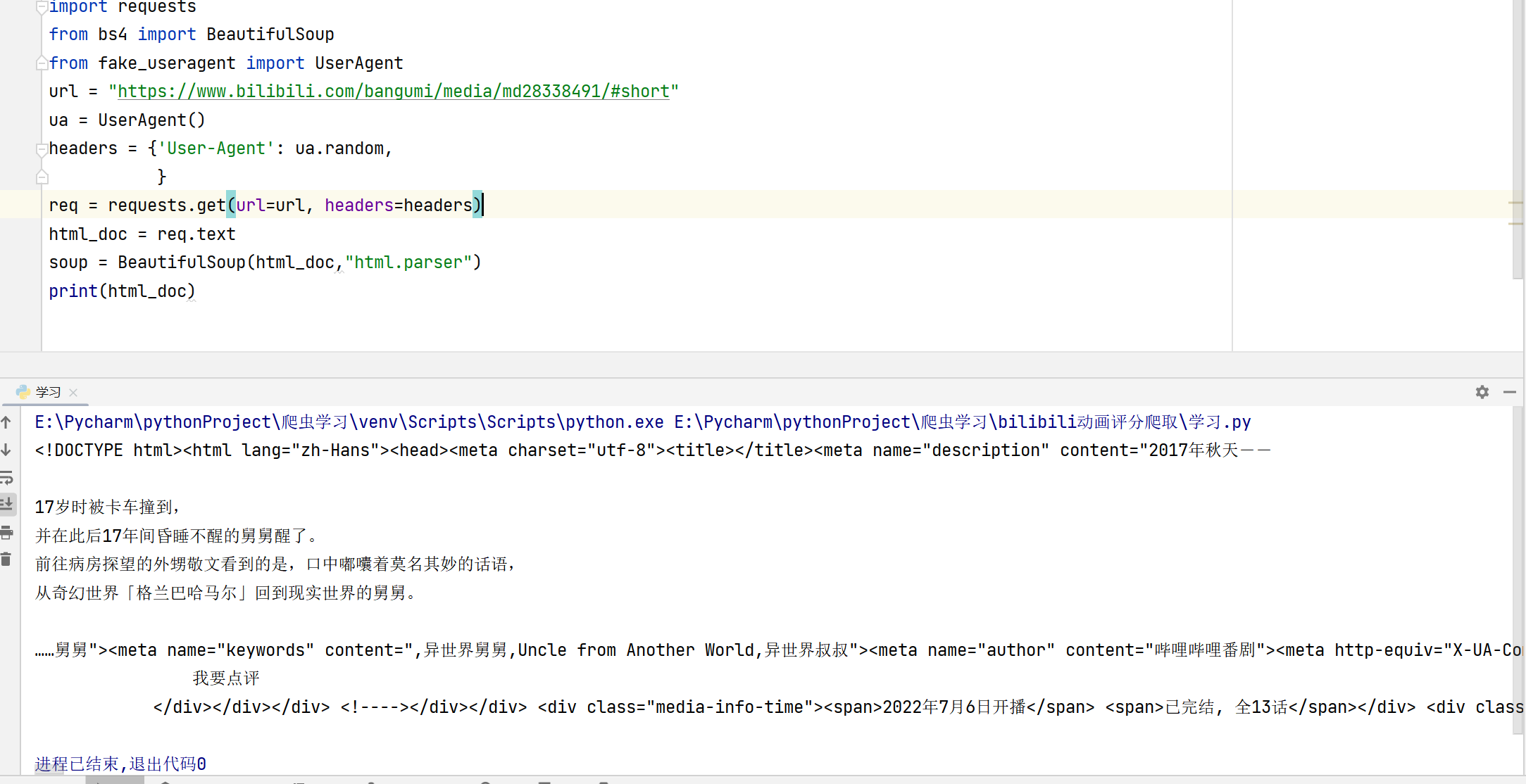
headres输入的是爬虫的头文件。一般来说网站都是通过头文件来判断请求的访问是人类还是爬虫。
对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
头文件中最常见的是User-Agent, 即用户代理,简称“UA”,它是一个特殊字符串头。网站服务器通过识别 “UA”来确定用户所使用的操作系统版本、CPU 类型、浏览器版本等信息。而网站服务器则通过判断 UA 来给客户端发送不同的页面。
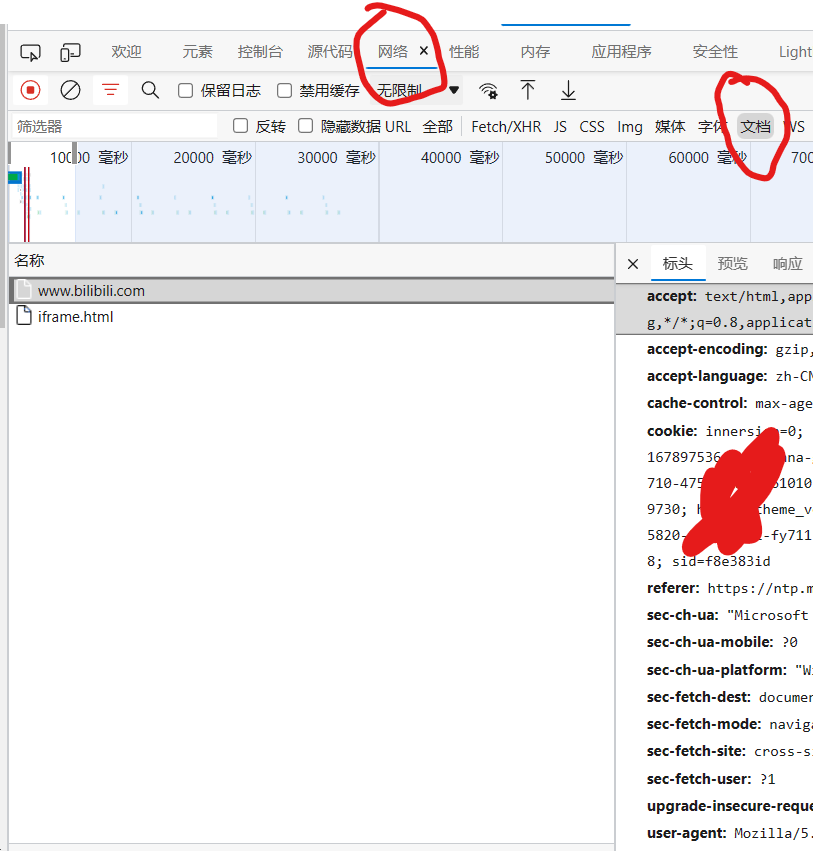
在检查中选择网络-文档,拉到最下面就可以看见请求头了。
一般来说headers里只要加入user-agent 就好了。可以选择去要爬取的网站下找到,也可以去保存一些常用的user-agent。这里我采用随机UA库。导入fake_useragent库后输入下面的代码即可。
from fake_useragent import UserAgent
ua = UserAgent()
"User-Agent ":ua.random#在headers中加入分析上图爬取到的信息,发现获得的信息远少于我们在网页上看到的信息。一顿查找后怀疑有数据是采用动态的方式加载的,也就是js。
关于js解释可以参考这篇文章
网络数据抓取-JS动态生成数据-Python-requests爬虫 - 简书 (jianshu.com)
关于静态网站与动态网站的个人理解:
一般的网站是静态界面,也就是说进入到网址后所有的信息都直接呈现在网页上,如此可直接通过爬虫爬取网站的内容。而动态加载的网页并不直接将信息放在网页上,而是在网页上存放链接(URL),链接导向内容,用户点击内容后访问链接并取得其中的内容。
所以对于这种网站我们普通爬取后得到的内容要远少于我们在网站上看到的内容。
对于这种网站要花更多的心思。总之,还是要回到要爬取的对象上来
首先先检查-网络
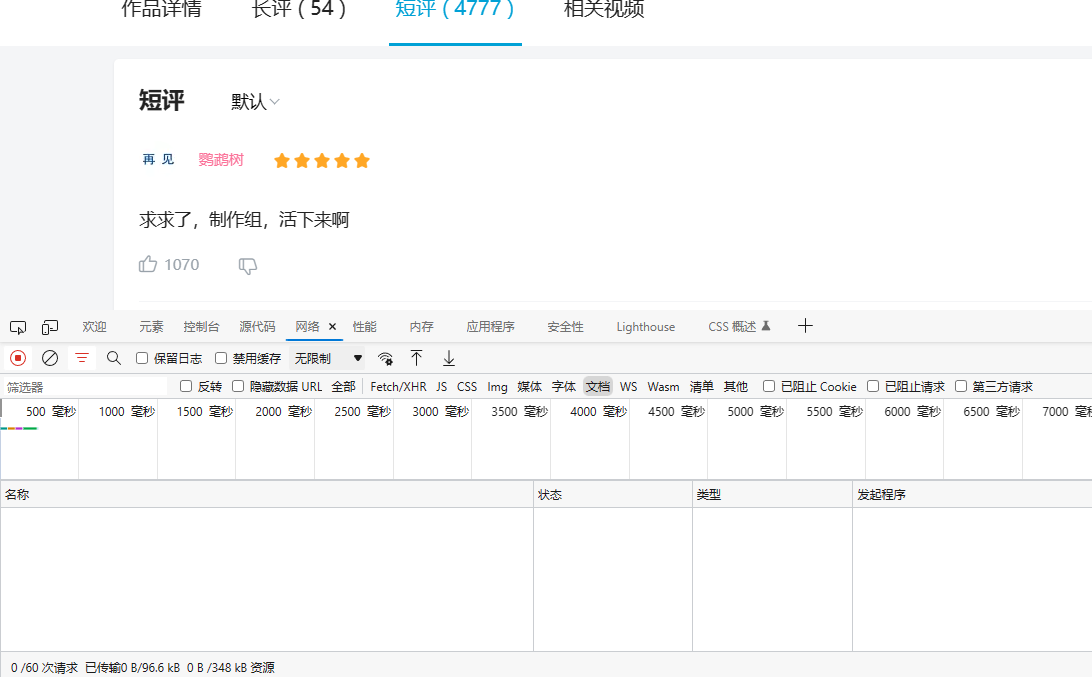
此时是一片空白的,刷新一下网络并来到Fetch/XHR
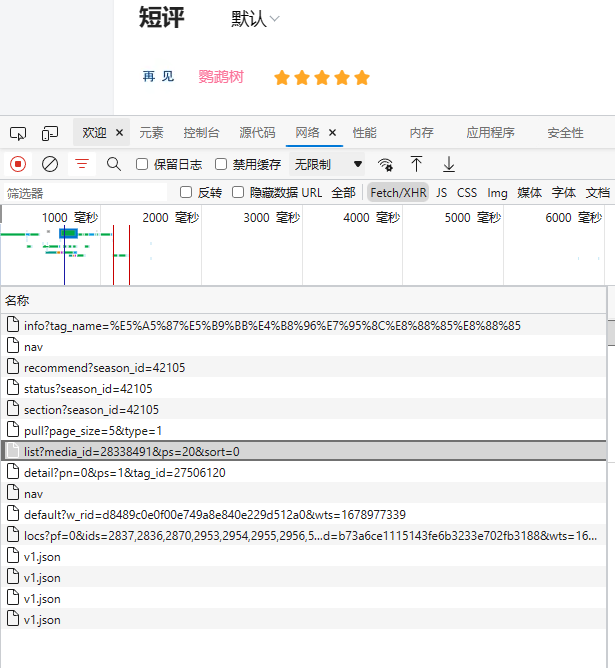
可以看到这里刷新了很多的数据,一般要找的信息就在这里,如果没有可以顺着Fetch/XHR,JS,CSS等一直找下去,虽然方法比较笨但也能找到。
总之先来分析一下数据吧。
随便点一个,看看它的负载或预览。
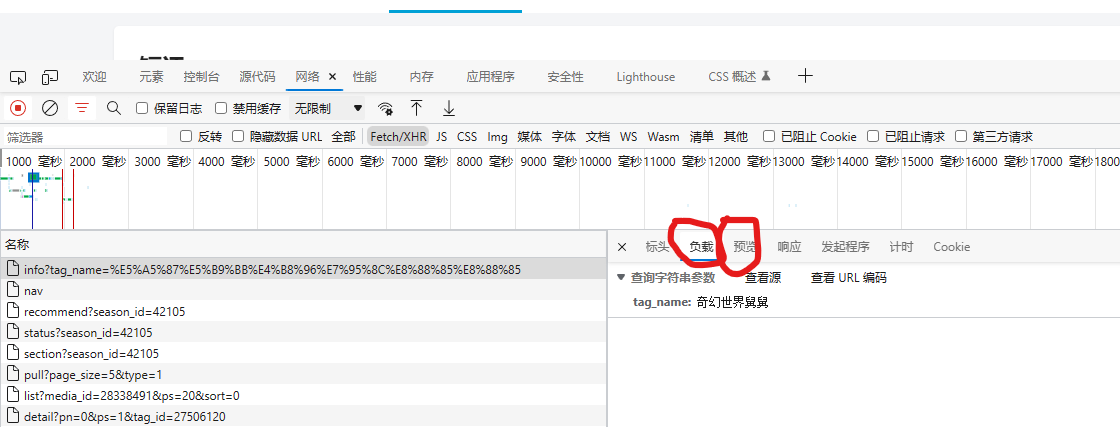
预览这里可以把代码展开来还是挺好看的
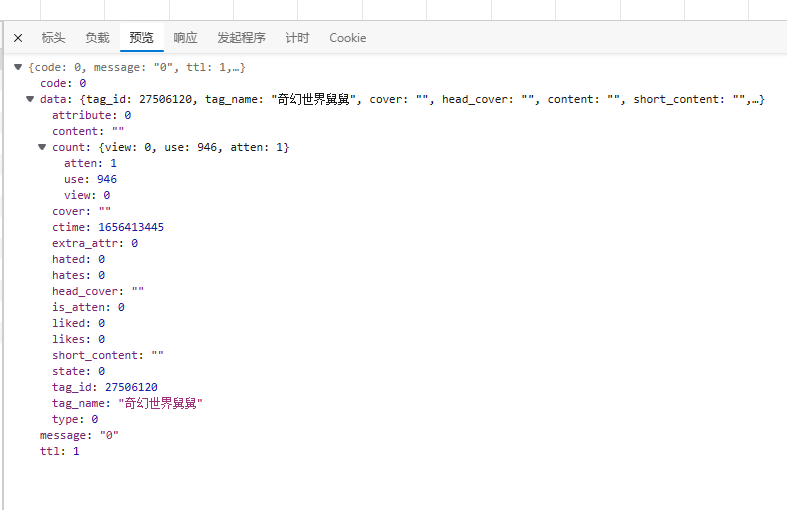
或者也可以复制url在新的页面打开

复制这串url在新的页面打开

打开后是这样的
显然上面没有我们想要的内容,继续往下找~

最后找到这个,很明显就是我们苦苦寻找的评论内容
也就是说,评论的内容藏在这个url里面
https://api.bilibili.com/pgc/review/short/list?media_id=28338491&ps=20&sort=0
分析可得,一个URL(或者说一页)里有20条评论。"https://api.bilibili.com/pgc/review/short/list?media_id="是所有动画统一的,"28338491"是动画的评论编号。"&ps=20&sort=0"是统一的。多刷新几条URL看看。
第二条:
https://api.bilibili.com/pgc/review/short/list?media_id=8892&ps=20&sort=0&cursor=83592993821690
第三条:
https://api.bilibili.com/pgc/review/short/list?media_id=8892&ps=20&sort=0&cursor=83584403859087
可以看出与前面的分析无误。但第二条开始尾巴就跟了个"cursor=\d+"。\d+在python的正则表达式中表示任意的一串数字。
一开始我还不理解这串数字有什么规律,再网上找了又找也没有任何发现。后来从页面的内容去寻找线索时惊讶的发现下一个URL的信息就藏在上一个的URL中。
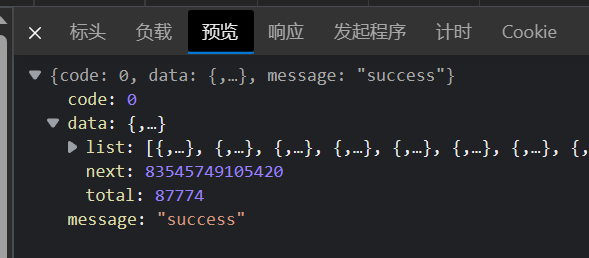
某一URL的的内容预览
所以现在思路很简单了。首先获得动画的评论编号,这样我们就得到了第一页的URL链接,从第一个连接中获得下一个链接的信息。重复就可以爬取所有的评论内容。
# URL处理代码如下所示
def url_manager(next_url):
next_md = '1177' # CLANNAD
if(next_url == 1):
url = f"https://api.bilibili.com/pgc/review/short/list?media_id={next_md}&ps=20&sort=0"
else:
url = f"https://api.bilibili.com/pgc/review/short/list?media_id={next_md}&ps=20&sort=0&cursor={next_url}"
return url顺带一提,如果要爬取多部的动画,那么就需要获得动画的md号。可以在番剧索引页面中批量获取。处理过程与爬取评论相似这里就不再赘述。
取得网页内容后只需要把其中的评论提取出来就行了。因为内容都是用字典与列表嵌套的并不难提取,耐心分析结构即可。















 753
753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









