









为什么hdfs不适合小文件的存储?
1.因namenode将文件系统的元数据存放在内存中,因此存储的文件数目受限于 namenode的内存大小。HDFS中每个文件、目录、数据块占用150Bytes。如果存放1million的文件至少消耗300MB内存,如果要存 放1billion的文件数目的话会超出硬件能力
2.HDFS适用于高吞吐量,而不适合低时间延迟的访问。如果同时存入1million的files,那么HDFS 将花费几个小时的时间。
3.流式读取的方式,不适合多用户写入,以及任意位置写入。如果访问小文件,则必须从一个datanode跳转到另外一个datanode,这样大大降低了读取性能。
4.延长MapReduce作业的总运行时间,小文件随机寻址很慢
HDFS自带的小文件存储解决方案
hadoop自带了三种解决小文件的方案:Hadoop Archive、 Sequence File 和 CombineFileInputFormat
Hadoop Archive
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
使用方法:
对某个目录/foo/bar下的所有小文件存档成/outputdir/ zoo.har:
hadoop archive -archiveName zoo.har -p /foo/bar /outputdir
查看看
hadoop dfs -ls har:///user/zoo/foo.har存在的问题
- 1、存档文件的源文件目录以及源文件都不会自动删除需要手动删除
- 2、存档的过程实际是一个mapreduce过程,所以需要需要hadoop的mapreduce的支持
- 3、存档文件本身不支持压缩
- 4、存档文件一旦创建便不可修改,要想从中删除或者增加文件,必须重新建立存档文件
- 5、创建存档文件会创建原始文件的副本,所以至少需要有与存档文件容量相同的磁盘空间
Sequence File
sequence file由一系列的二进制的对组成,其中key为小文件的名字,value的file content。
,它可以在map/reduce过程中的input/output 的format时被使用。在map/reduce过程中,map处理文件的临时输出就是使用SequenceFile处理过的。
SequenceFile分别提供了读、写、排序的操作类。
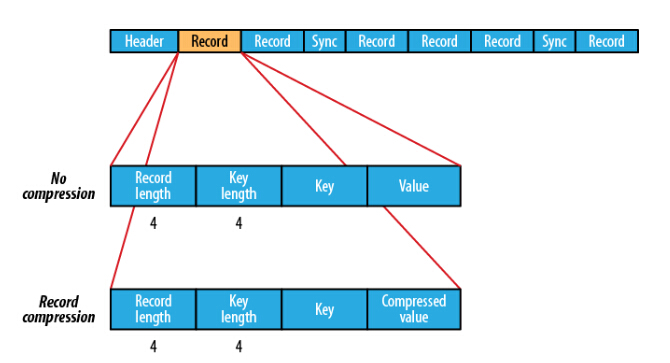
SequenceFile提供了三种压缩方式:
- 不采用压缩:CompressionType.NONE
- key/value值都压缩的方式存储:CompressionType.RECORD
- 压缩value值不压缩key值存储的存储方式:CompressionType.BLOCK
使用方式
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.SequenceFile.Reader;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.Text;
/**
* @version 1.0
* @author Fish
*/
public class SequenceFileWriteDemo {
private static final String[] DATA = { "fish1", "fish2", "fish3", "fish4" };
public static void main(String[] args) throws IOException {
/**
* 写SequenceFile
*/
String uri = "/test/fish/seq.txt";
Configuration conf = new Configuration();
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
Writer writer = null;
try {
/**
* CompressionType.NONE 不压缩<br>
* CompressionType.RECORD 只压缩value<br>
* CompressionType.BLOCK 压缩很多记录的key/value组成块
*/
writer = SequenceFile.createWriter(conf, Writer.file(path), Writer.keyClass(key.getClass()),
Writer.valueClass(value.getClass()), Writer.compression(CompressionType.BLOCK));
for (int i = 0; i < 4; i++) {
value.set(DATA[i]);
key.set(i);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
/**
* 读SequenceFile
*/
SequenceFile.Reader reader = new SequenceFile.Reader(conf, Reader.file(path));
IntWritable key1 = new IntWritable();
Text value1 = new Text();
while (reader.next(key1, value1)) {
System.out.println(key1 + "----" + value1);
}
IOUtils.closeStream(reader);// 关闭read流
/**
* 用于排序
*/
// SequenceFile.Sorter sorter = new SequenceFile.Sorter(fs, comparator, IntWritable.class, Text.class, conf);
}
}存在的问题
优点
- 1支持压缩,且可定制为基于Record或Block压缩(Block级压缩性能较优)
- 2本地化任务支持:因为文件可以被切分,因此MapReduce任务时数据的本地化情况应该是非常好的。
缺点
需要一个合并文件的过程,且合并后的文件将不方便查看。
CombineFileInputFormat
Hadoop内置提供了一个 CombineFileInputFormat 类来专门处理小文件,其核心思想是:根据一定的规则,将HDFS上多个小文件合并到一个 InputSplit中,然后会启用一个Map来处理这里面的文件,以此减少MR整体作业的运行时间。
CombineFileInputFormat类继承自FileInputFormat,主要重写了List getSplits(JobContext job)方法;这个方法会根据数据的分布,mapreduce.input.fileinputformat.split.minsize.per.node、mapreduce.input.fileinputformat.split.minsize.per.rack以及mapreduce.input.fileinputformat.split.maxsize 参数的设置来合并小文件,并生成List。其中mapreduce.input.fileinputformat.split.maxsize参数至关重要,下面是分区规则
- 当mapreduce.input.fileinputformat.split.maxsize > mapreduce.input.fileinputformat.split.minsize > dfs.blockSize的情况下,此时的splitSize 将由mapreduce.input.fileinputformat.split.minsize参数决定。
- 当mapreduce.input.fileinputformat.split.maxsize > dfs.blockSize > mapreduce.input.fileinputformat.split.minsize的情况下,此时的splitSize 将由dfs.blockSize配置决定。(第二次优化符合此种情况)
- 当dfs.blockSize > mapreduce.input.fileinputformat.split.maxsize > mapreduce.input.fileinputformat.split.minsize的情况下,此时的splitSize 将由mapreduce.input.fileinputformat.split.maxsize参数决定。
有以上的计算规则最终确定了CombineFileInputFormat分区的大小。
其中
mapreduce.input.fileinputformat.split.minsize设置,默认是1,最大字节数由mapreduce.input.fileinputformat.split.maxsize设置,默认是Long.MAX_VALUE。
用公式计算就是:
splitSize = Math.max(minSize, Math.min(maxSize, blockSize))可以参考:http://blog.csdn.net/beliefer/article/details/51122009
使用
CombineTextInputFormat使用起来特别简单:
1.在conf设置
Configuration conf = new Configuration(getConf());
conf.set("mapreduce.input.fileinputformat.split.maxsize", ONE_MB * 32);2.在inputformat中设置
setInputFormatClass(CombineTextInputFormat.class);引用:
https://www.iteblog.com/archives/2139.html
http://www.open-open.com/lib/view/open1330605869374.html














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









