






- 代码第一次编写
-
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx' page_text = requests.get(url=url, headers=headers).content # 实例化及获取验证码图片 tree = etree.HTML(page_text) src = 'https://so.gushiwen.cn/' + tree.xpath('//*[@id="imgCode"]/@src')[0] img_date = requests.get(url=src, headers=headers).content # 将验证码图片保存到本地 with open('./card.jpg', 'wb')as fp: fp.write(img_date) time.sleep(1) text = pytesseract.image_to_string(Image.open('card.jpg')) print(text) # 模拟登录 load_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx' load_data = { 'from': 'http://so.gushiwen.cn/user/ collect.aspx', 'email': '', 'pwd': '', 'code': text, 'denglu': '登录' } login_text=requests.post(url=load_url, data=load_data,headers=headers).text with open('login.html','w',encoding='utf-8') as fp: fp.write(login_text)
古诗文网有两个问题:1.__VIEWSTATE参数是动态的;2.登录时状态码是302,发生了重定位。
暂时先学到这里,之后有其他的办法再作以修改
代码编写于2023.8.4 代码正常运行 提示验证码错误
- 代码第二次编写
import requests
from lxml import etree
import pytesseract
import ddddocr
if __name__ == '__main__':
session = requests.Session()
# 古诗文网登录页面url
get_url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
# 模拟登录请求头
get_header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0'
}
# 请求url获取text
page_text = requests.get(url=get_url, headers=get_header).text
# 解析HTML
tree = etree.HTML(page_text)
# 定位src属性并拼接获得最终验证码url
src_url = 'https://so.gushiwen.cn' + tree.xpath('//*[@id="imgCode"]/@src')[0]
# 请求验证码url获取二进制
src_data = session.get(url=src_url, headers=get_header).content
# 将获取的的二进制数据写入到当前目录下获得code.jpg
with open('./code.jpg', 'wb') as fp:
fp.write(src_data)
#pytesseract识别验证码
# code = pytesseract.image_to_string('code.jpg')
# print(code)
#ddddocr识别验证码
ocr = ddddocr.DdddOcr()
text2 = ocr.classification(src_data)
print('ddddorc识别出的验证码为:', text2)
# 模拟登录
__VIEWSTATE = tree.xpath('//*[@id="__VIEWSTATE"]/@value')[0]
__VIEWSTATEGENERATOR = tree.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')[0]
login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data = {
'__VIEWSTATE': __VIEWSTATE,
'__VIEWSTATEGENERATOR': __VIEWSTATEGENERATOR,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '',
'pwd': '',
'code': text2,
'denglu': '登录',
}
gushiwen = session.post(url=login_url, headers=get_header, data=data).text
with open('./gushiwen.html', 'w', encoding='utf-8') as fp_h:
fp_h.write(gushiwen)pytesseract识别的准确率以及训练的成熟度不是很高 更换ddddocr之后就好多了
就是跳转到的HTML页面不好看
代码修改于2023.8.15 代码正常运行 运行结果大致正常
- 代码第三次编写
以下代码承接模拟登录
# 收藏页面的标头
cookie = '收藏页面的cookie'
headers = {
'Cookie': cookie,
'Referer': 'https://so.gushiwen.cn/user/collect.aspx',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62'
}
# 主页的url
main_url = 'https://www.gushiwen.cn/'
# 收藏页的url
collect_url = 'https://so.gushiwen.cn/user/collect.aspx?type=m&id=4752846&sort=t'
# 主页的响应数据
gushiwen = session.post(url=main_url, headers=get_header, data=data).text
# #查看session内携带的cookie
# cookies_dict = requests.utils.dict_from_cookiejar(session.cookies)
# # 把cookies转化成字典。
# print("cookie:" + str(cookies_dict))
# 收藏页的相应数据
response = session.post(url=collect_url, headers=headers).text
with open('./gushiwen.html', 'w', encoding='utf-8') as fp_h:
# 写入
fp_h.write(response)
打印session,发现携带的cookie内容与网页内的cookie不一致,于是手动使用cookie,此处在请求中额外携带cookie
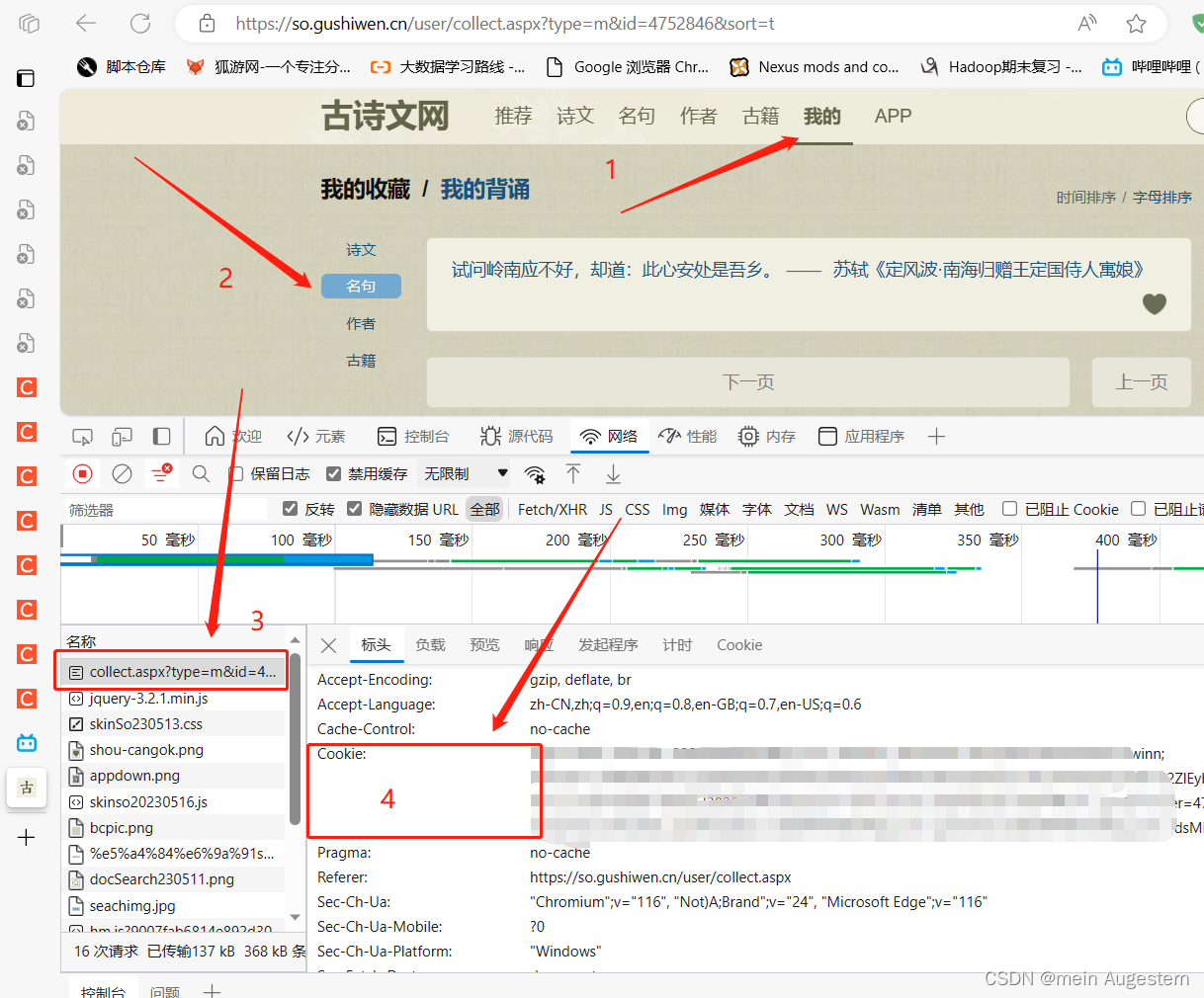
代码修改于2023.8.31 代码正常运行 运行结果大致正常















 3294
3294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









