







文章目录
1.JMeter安装配置
1.1 软件下载
安装步骤
- 安装JDK
- 安装和系统jdk版本对应的JMeter
JMeter的打开方式
- 双击 JMeter/bin下的jmeter.bat
- 双击ApacheJmeter.jar选择使用java程序打开
- 命令行输入:java -jar ApacheJMeter.jar
1.2 汉化配置
实现JMeter界面的汉化包含两种方式:
- 临时
- 永久

2.JMeter文件目录介绍
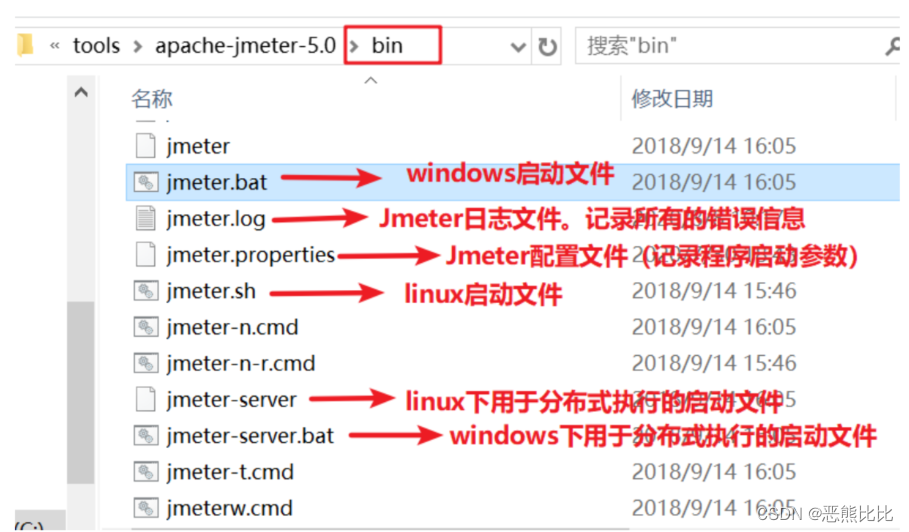
可执行文件和配置文件
jmeter.bat:windows的启动文件
jmeter.log:日志文件
jmeter.sh:linux的启动文件
jmeter.properties:系统配置文件
jmeter-server.bat:windows分布式测试要用到的服务器配置
jmeter-serve:linux分布式测试要用到的服务器配置
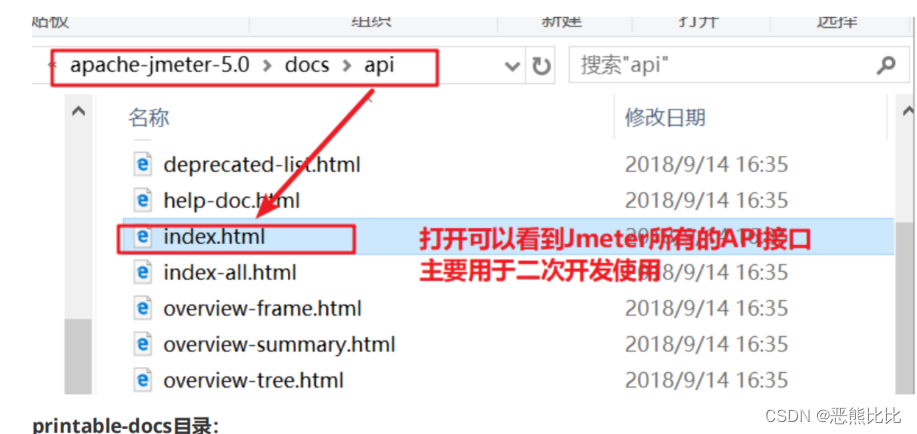
docs目录
docs:是JMeter的api文档,可打开api/index.html页面来查看
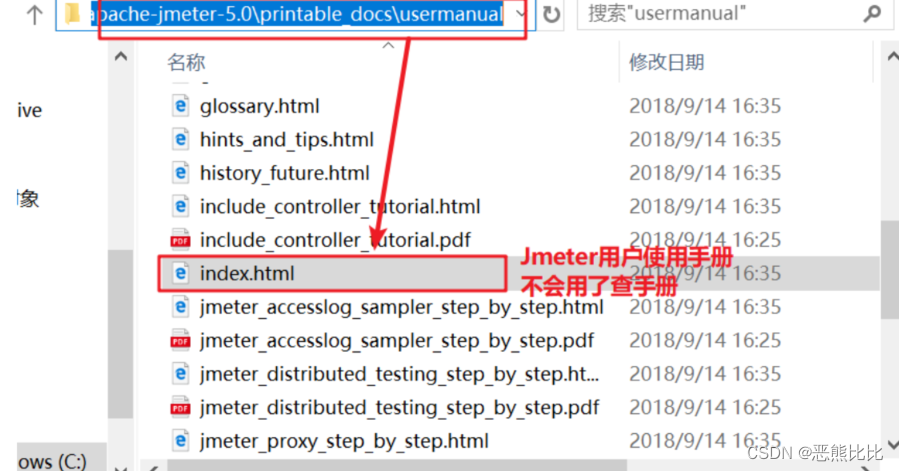
printable_docs目录
printable_docs的usermanual子目录下的内容是JMeter的用户手册文档
usermanual下component_reference.html是最常用到的核心元件帮助文档。
lib目录
该目录用来存放JMeter依赖的jar包和用户扩展所依赖的jar包
3.JMeter元件作用域和执行顺序
元件的基本介绍
元件:多个类似功能组件的容器(类似于类)
线程组:模拟的用户
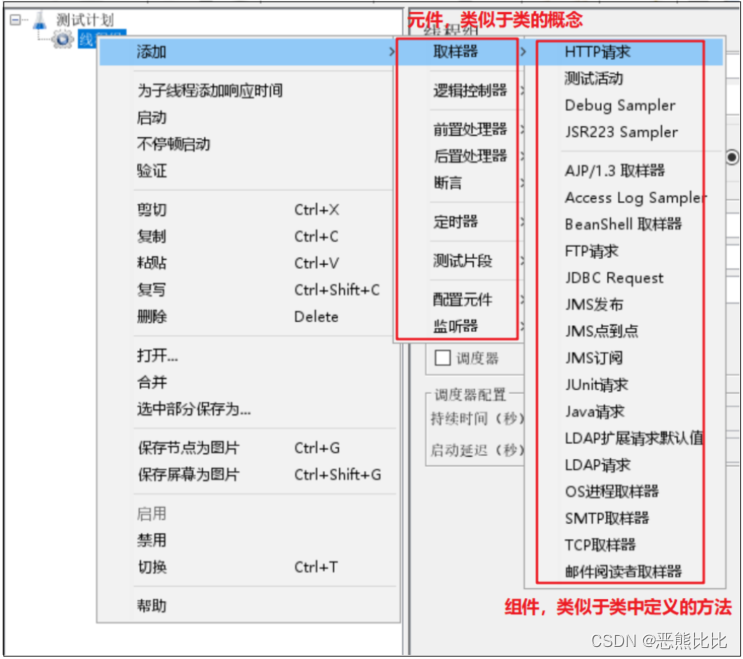
元件类型
- 取样器:发送请求。类似于自动化中的request库业务测试语句
- 逻辑控制器:控制元件执行顺序。类似于自动化中的逻辑控制语句
- 前置处理器 :对发送的请求参数进行预处理。类似于自动化中setup的参数化。
- 后置处理器 :对收到的响应数据进行处理。类似于自动化中teardown获得对应的测试结果。
- 断言:一种逻辑判断式,验证结果与开发者的预期是否相符;
- 定时器:等待一定时间。类似于自动化中的sleep语句;
- 测试片段:封装的脚本,供其他脚本调用。类似于自动化中封装的函数
- 配置元件:测试前的环境及数据配置。类似于自动化中的初始化动作
- 监听器:查看测试的结果。类似于自动化中的日志和报告。
3.1 元件作用域
作用域的应用:
- 在python中通过缩进来体现作用域
- java中通过大括号{}
元件作用域
在JMeter中,元件的作用域是靠测试计划的树形结构中元件的父子关系来确定的。
提示: 核心是取样器,其他组件都是以取样器为核心运行的,组件添加的位置不同,生效的取样器也不同。
作用域的原理:
按照jmeter测试计划的树形结构来定义作用域(有点儿类型python的缩进) 作用域的原则:
- 取样器是jmeter的核心,不作用于其他的组件
- 逻辑控制器,只对子节点起作用
- 对于其他的组件
如果父节点是取样器的话,则只对父节点起作用, 如果父节点不是取样器的话,则对父节点下的所有组件起作用
元件的执行顺序
- 配置元件(config elements)
- 前置处理程序(Per-processors)
- 定时器(timers)
- 取样器(Sampler)
- 后置处理程序(Post-processors)
- 断言(Assertions)
- 监听器(Listeners)
提示:
- 前置处理器、后置处理器、断言等元件功能对取样器起作用(如果在它们的作用域内没有任何取样器,则不会被执行)
- 如果在同一作用域范围内有多个同一类型的元件,则这些元件按照它们在测试计划中的上下顺序依次执行
3.2 线程组
说明
线程组是控制JMeter将用于执行测试的线程数,也可以把一个线程理解为一个测试用户。
添加线程组
右键点击‘测试计划’ --> 添加 --> 线程(用户) --> 线程组
线程组的特点
- 模拟多人操作
- 线程组可以添加多个,多个线程组可以并行或串行
- 取样器(请求)和逻辑控制器必须依赖线程组才能使用
- 线程组下可以添加其他元件下组件
线程组分类
- 线程组
普通的、常用的线程组,可以看做一个虚拟用户组,线程组中的每一个线程都可以理解为一个虚拟用户;
用于发送业务请求的线程组(受并行、串行配置的影响)- setUP线程组
一种特殊类型的线程组,可用于执行预测试操作
在所有的线程组之前执行(不受并行、串行配置的影响)- tearDown线程组
一种特殊类型的线程组,可用于执行测试后工作
在所有的线程组之后执行(不受并行、串行配置的影响)

线程组的属性
线程数:
需要模拟的虚拟用户数
ramp-up time:模拟的虚拟用户数全部启动所需要的时间。
- aim:为了模拟性能测试的场景,更接近用户的使用习惯(用户慢慢接入系统)
- 循环次数:设置为固定次数n时:脚本运行时发送请求的次数为n
设置循环次数为“永远”时,脚本会一直运行下去,不停止
循环次数:
- 设置为固定次数n时:脚本运行时发送请求的次数为n
- 设置循环次数为“永远”时,脚本会一直运行下去,不停止
调度器:
- 一般与循环次数为“永远”的设置配合使用
- 持续时间设置为n时:脚本的请求发送的时间为n秒
- 延迟启动设置为n时:脚本的请求发送在等待n秒后再进行
延迟创建线程直到需要
- 当启动线程发送请求时,才分配资源;
- 如果暂未启动该线程,则不分配
- 如果不勾选,在jmeter点击运行时立即分配(使用不多,了解即可,无法观察效果)
线程数m和循环次数n的关系
- 线程数:代表并发用户数,体现服务器的负载量
- 循环次数:代表执行时间
- 如果同时配置,实际发送的HTTP请求数应该为m*n
- 虽然发送请求的次数相同,但是不能相互替换
3.3 HTTP请求
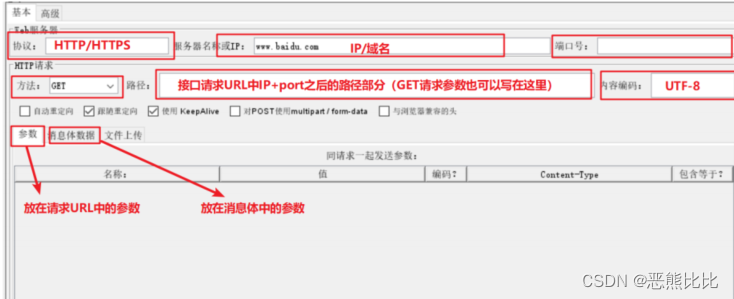
- 端口:80端口作为http协议的默认端口
案例1:发送请求时:
协议未填写,则默认为HTTP协议
端口未填写,则默认为80端口
将GET请求参数放在路径中填写
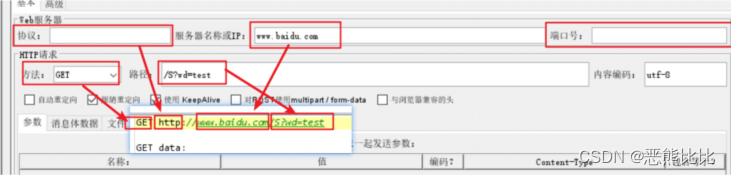
案例2:发送请求时:
协议选择HTTPS
端口号为443
将GET请求参数放在下面的参数列表中进行填写
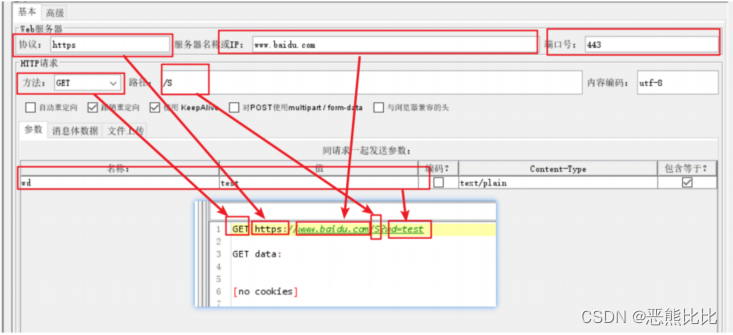
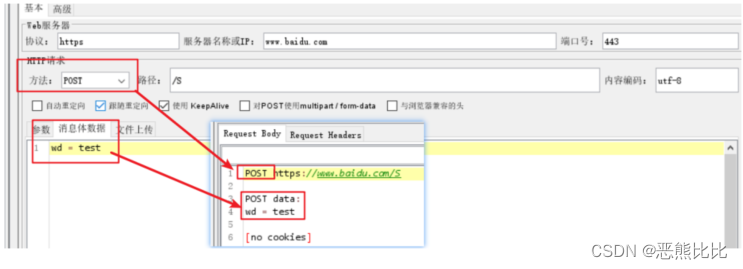
案例3:发送post请求
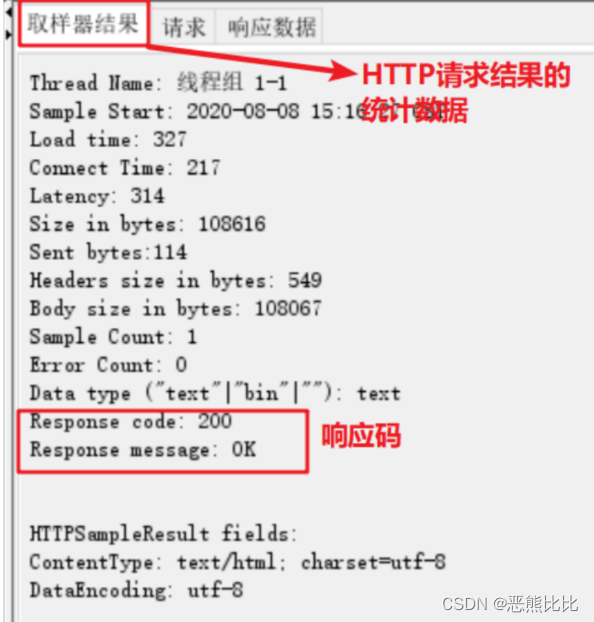
3.4 查看结果树
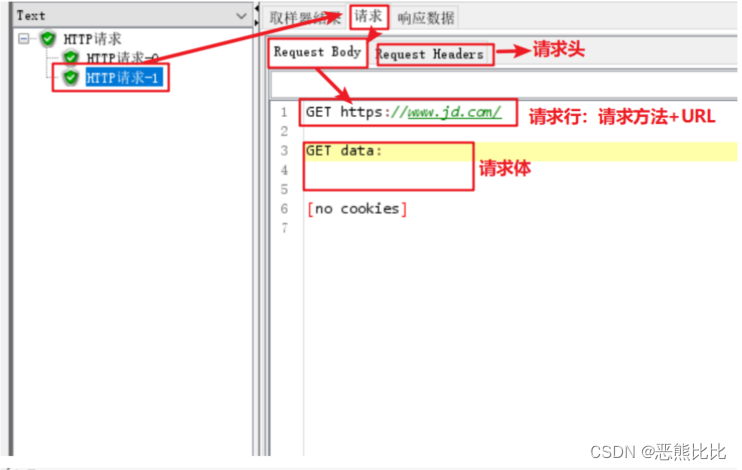
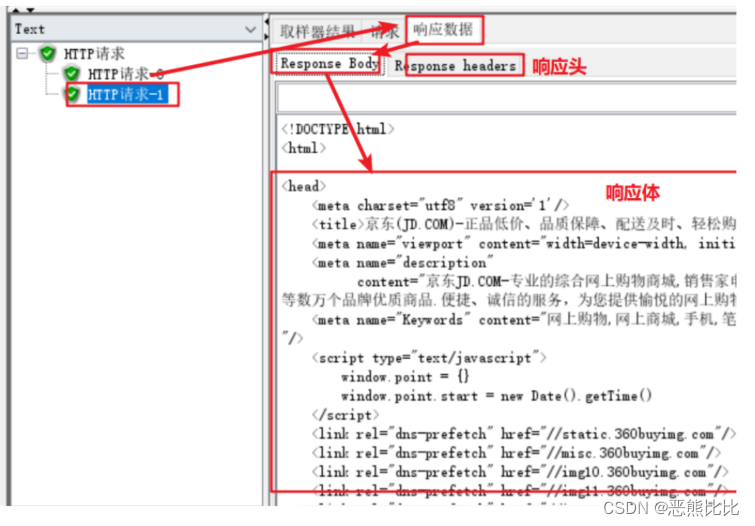
4.JMeter使用示例
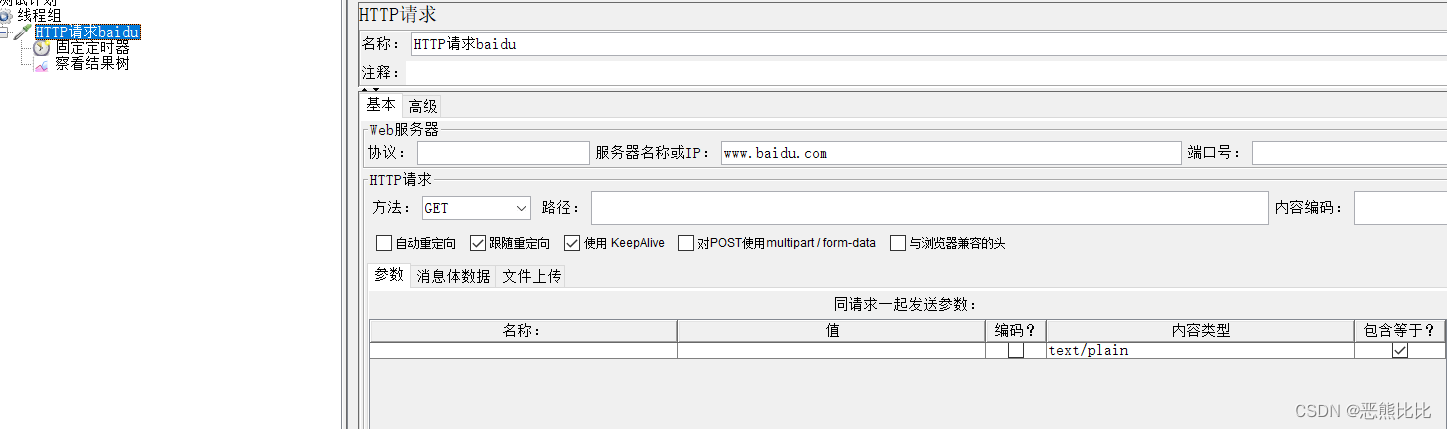
4.1 案例1:访问百度
需求:使用JMeter访问百度首页接口,并查看请求和响应信息
步骤
- 启动JMeter
- 在测试计划下天机线程组
- 在线程组添加http请求取样器
- 填写http请求的相关数据
- 在‘线程组’下添加‘察看结果树’监听器
- 点击‘启动’按钮运行,并查看结果
5. JMeter参数化
参数化使用背景
- 录制脚本中有登录操作,需要输入用户名和密码,假如系统不允许相同的用户名和密码同时登录,或者想更好的模拟多个用户来登录系统。
- 这个时候就需要对用户名和密码进行参数化,使每个虚拟用户都使用不同的用户名和密码进行访问。
参数化概念
,参数化的一般用法就是将脚本中的某些输入使用参数来代替,在脚本运行时指定参数的取值范围和规则;
这样,脚本在运行时就可以根据需要选取不同的参数值作为输入
参数的取值范围被称为数据池
参数化常用方式
- 用户定义变量
每个用户每次读取的变量值都完全相同- 用户参数
不同用户读取的变量值不同,但是同一用户在多次循环时读取的变量值是一致的- CSV Data Set Config
不同用户读取的变量值不同,同一用户在多次循环时读取的变量值也不同- 函数
每次执行读取的变量值都不同,不需要提前定义数据(适用于对数量值无明确要求,只要求不同)
配置:
- 设置:每种不同
- 引用:${参数名}
添加HTTP请求 —— 搜索请求 参数为中文时,将参数写到下方参数位置,并勾选上“编码”
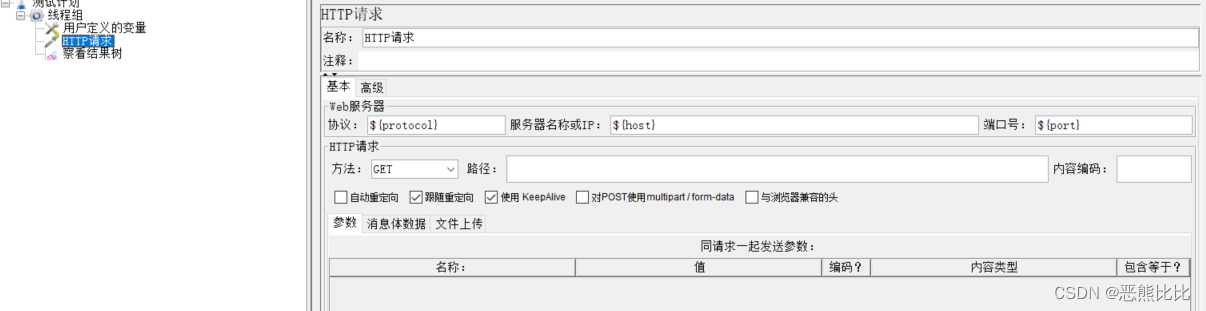
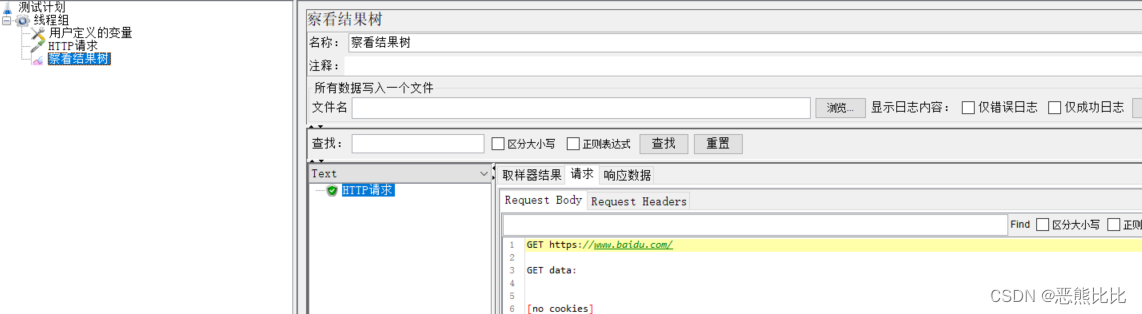
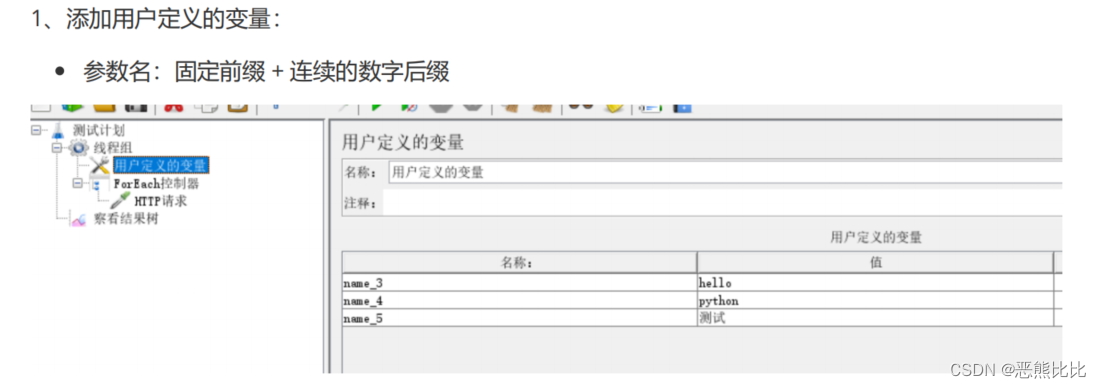
5.1 用户定义的变量
添加方式
测试计划 --> 线程组–> 配置元件 --> 用户定义的变量
场景
- 请求:https://www.baidu.com:443
- 要求:使用用户定义的变量配置被测系统的协议、域名和端口
步骤
- 添加线程组
- 添加用户变量
- 添加http请求
- 添加查看结果树

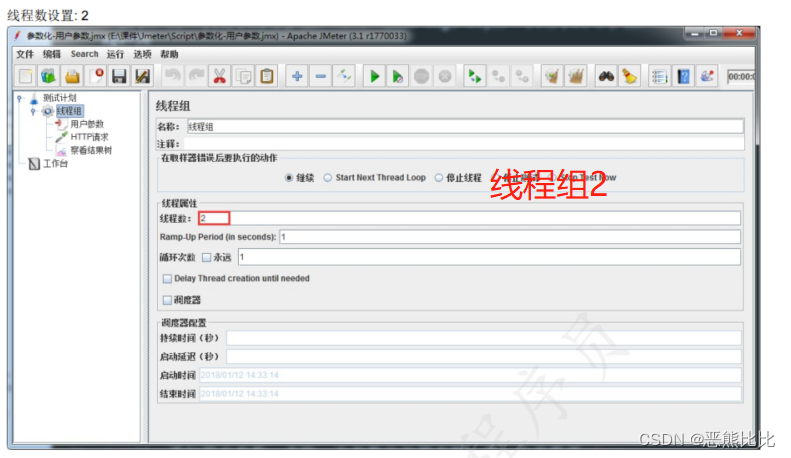
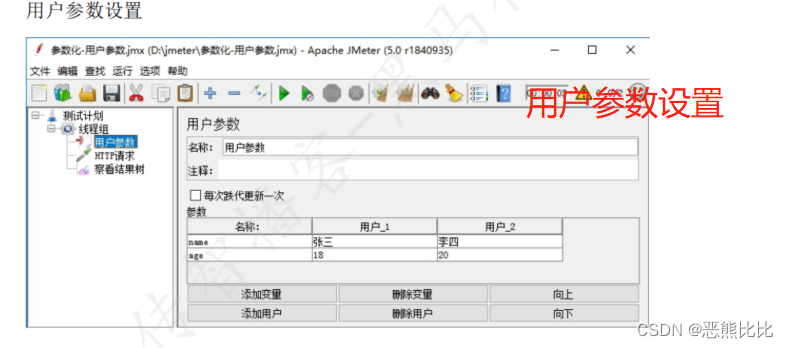
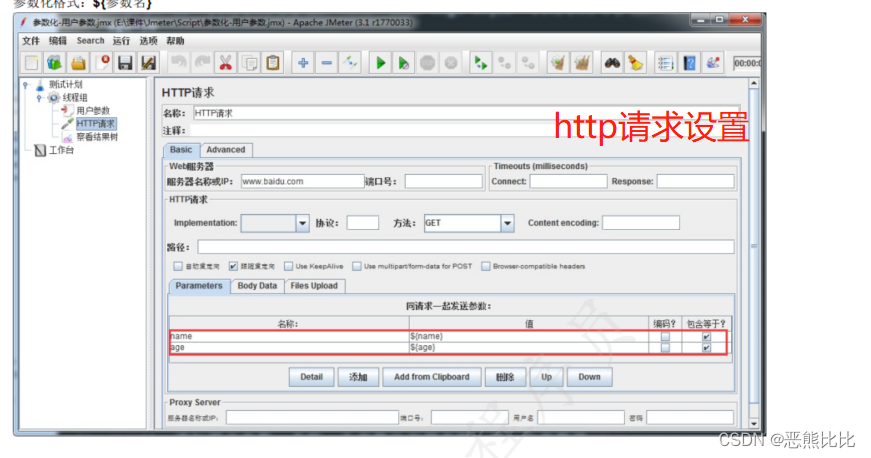
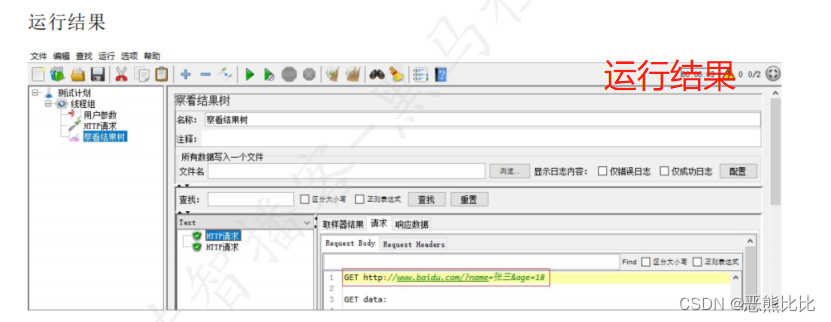
5.2 用户参数
添加方式
测试计划 --> 线程组–> 前置处理器 --> 用户参数
场景
- 请求:https://www.baidu.com
- 要求:第一次请求附带参数:name=“张三”&age=28;第二次请求附带参数:name=“李四”&age=30
操作步骤
1.添加线程组
2.添加用户参数
3.添加HTTP请求
4.添加查看结果树
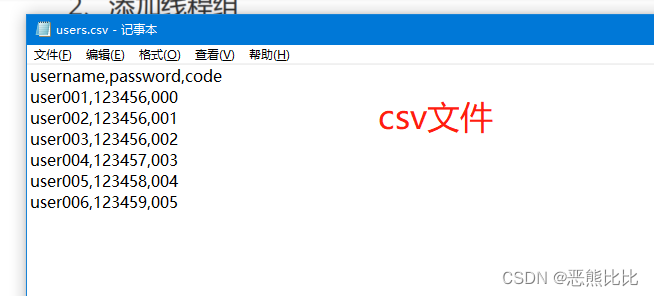
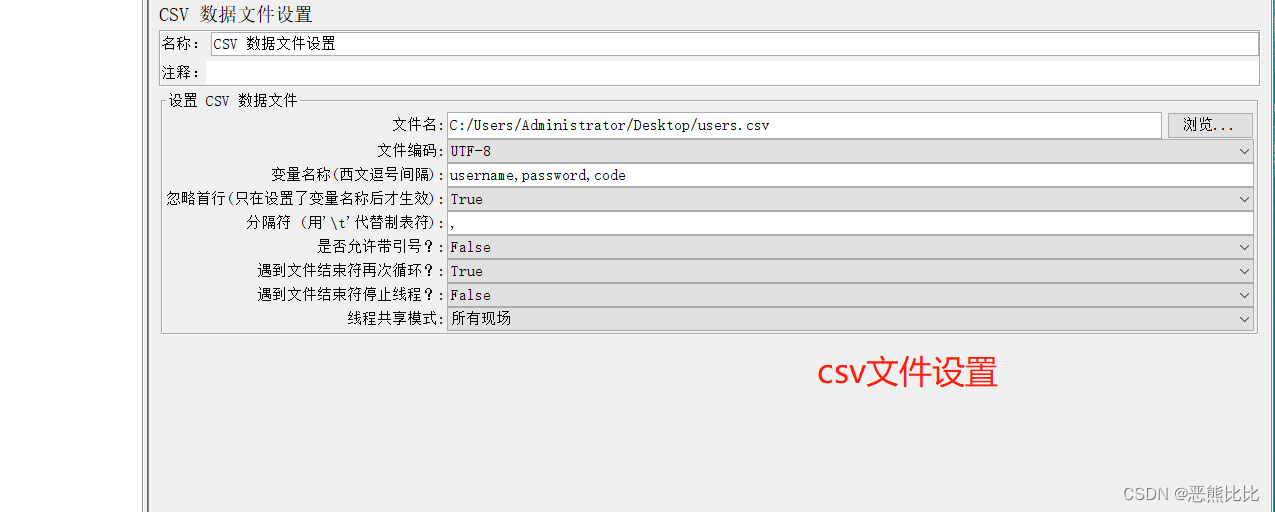
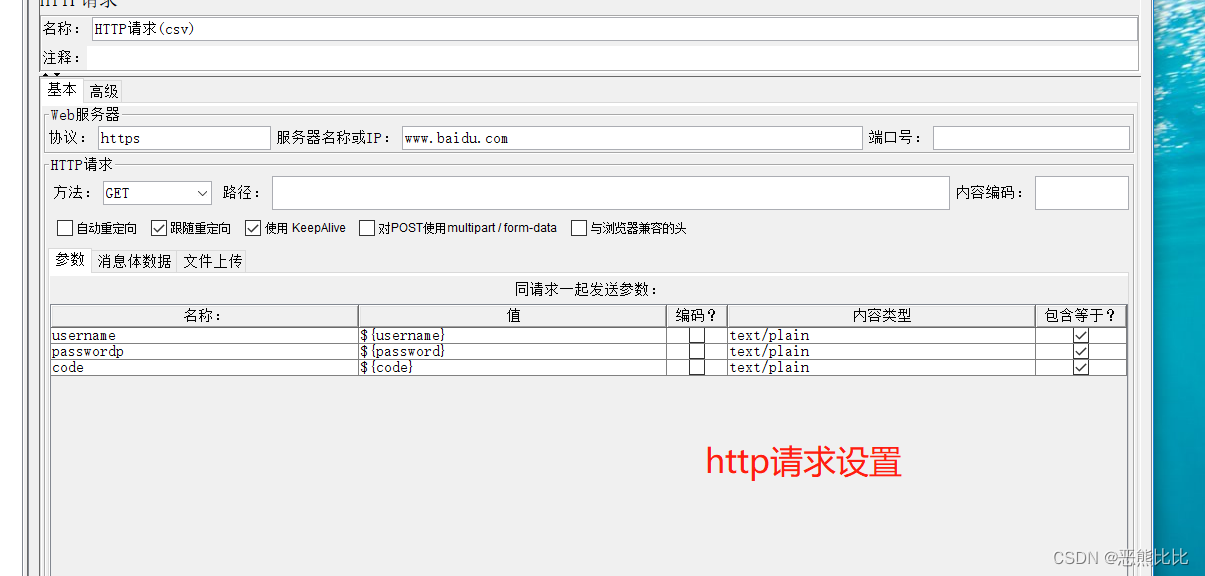
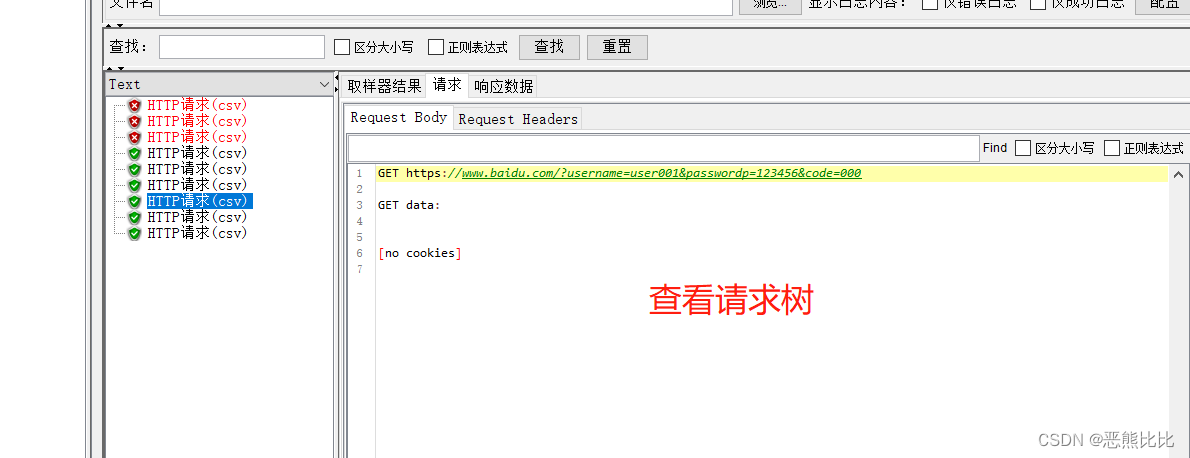
5.3 CSV Data Set Config
添加方式
测试计划 --> 线程组–> 配置元件 --> CSV 数据文件设置
场景
- 请求:https://www.baidu.com
- 要求:循环3次,每次请求时附带参数username,password,code的值不相同

操作步骤
1.定义CSV数据文件
2.添加线程组
3.添加CSV 数据文件设置
4.添加HTTP请求
5.添加查看结果树
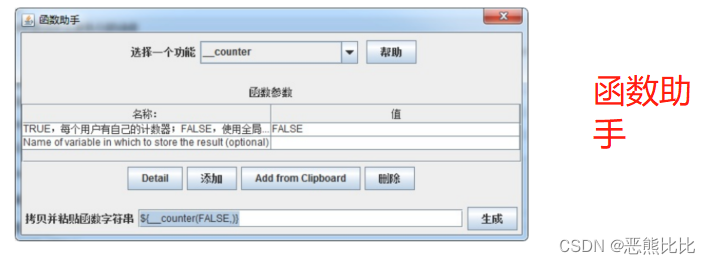
5.4 函数
计数函数,一般做执行次数统计使用;
位置:
在菜单中选择–> 选项 --> 函数助手对话框
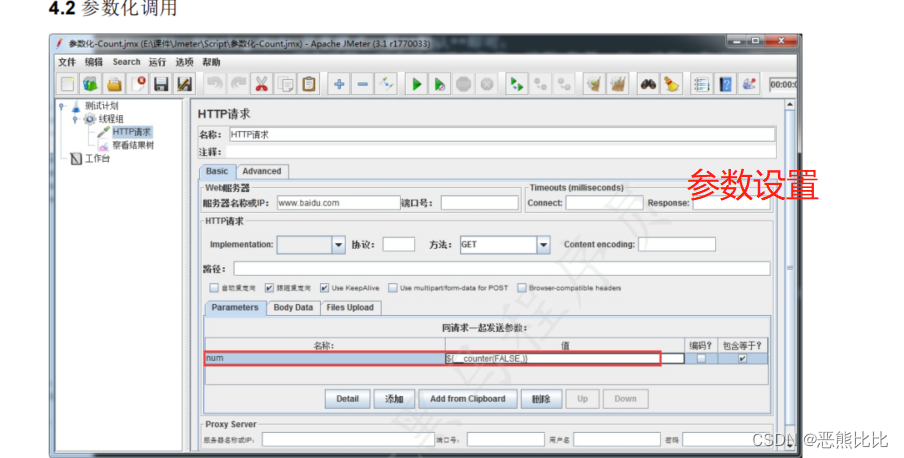
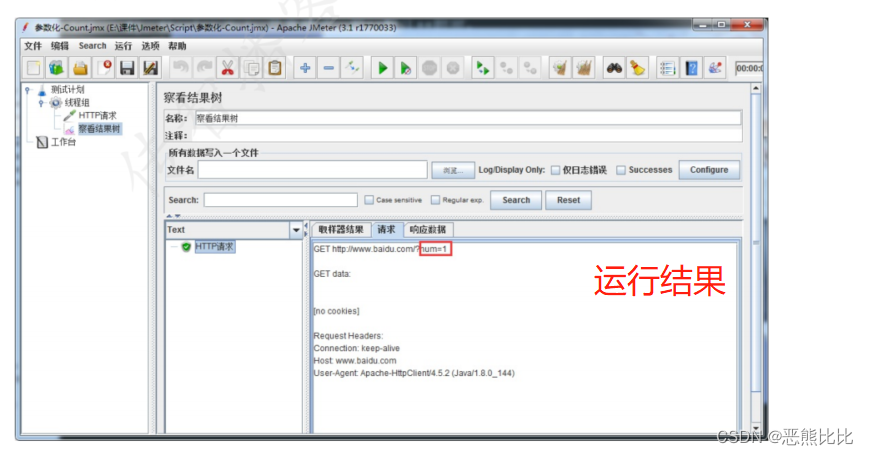
6.JMeter断言
JMeter断言
JMeter断言是在请求的返回层面增加一层判断机制;因为请求成功了,并不代表结果一定正确,因此需要检测机制提高测试准确性。
- 通过自动化的手段对请求的响应数据进行自动校验
JMeter断言类型
- 响应断言
- JSON断言
- 持续时间断言(Duration Assertion)
6.1 响应断言
添加方式
测试计划 --> 线程组–> HTTP请求 --> (右键添加) 断言 --> 响应断言
配置介绍
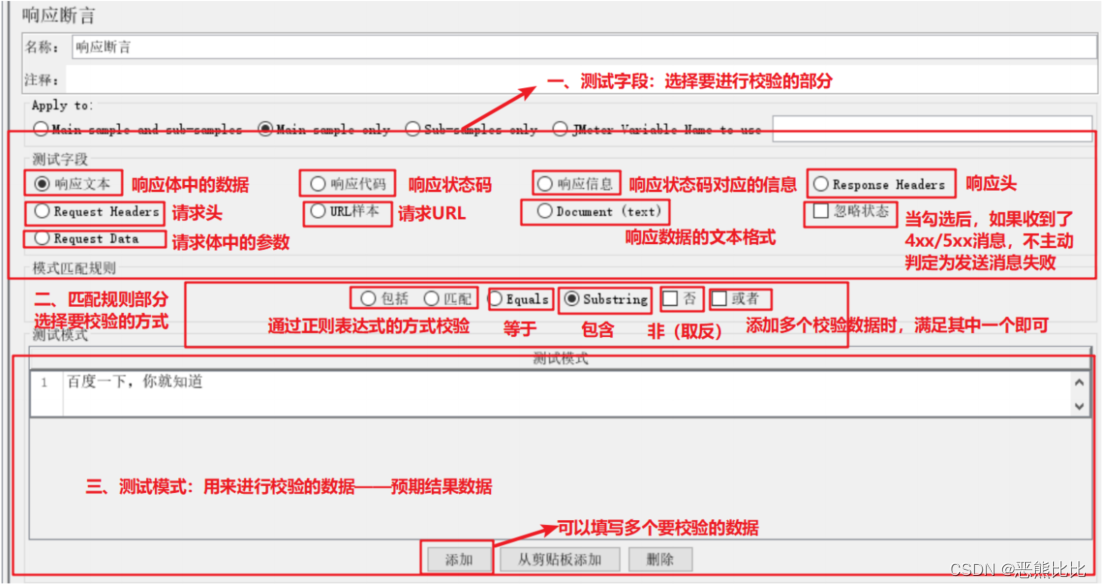
步骤
- 添加线程组
- 添加http请求
- 添加响应断言
- 添加断言结果
- 添加查看结果树
场景
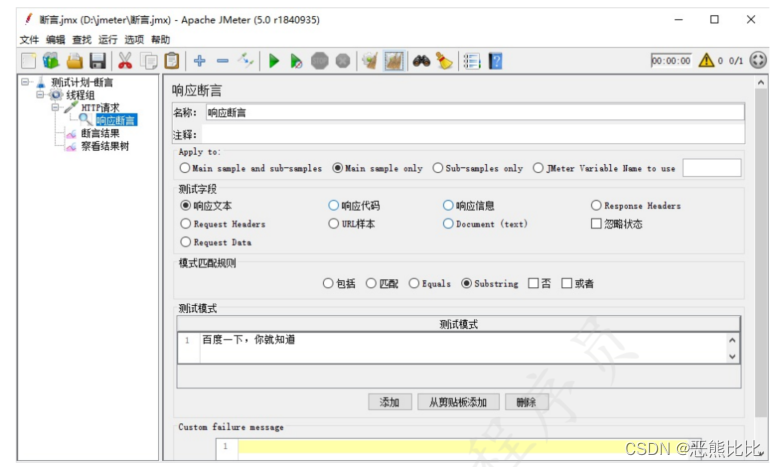
请求:https://www.baidu.com
检查:让程序检查响应数据中是否包含“百度一下,你就知道”
6.2 JSON断言
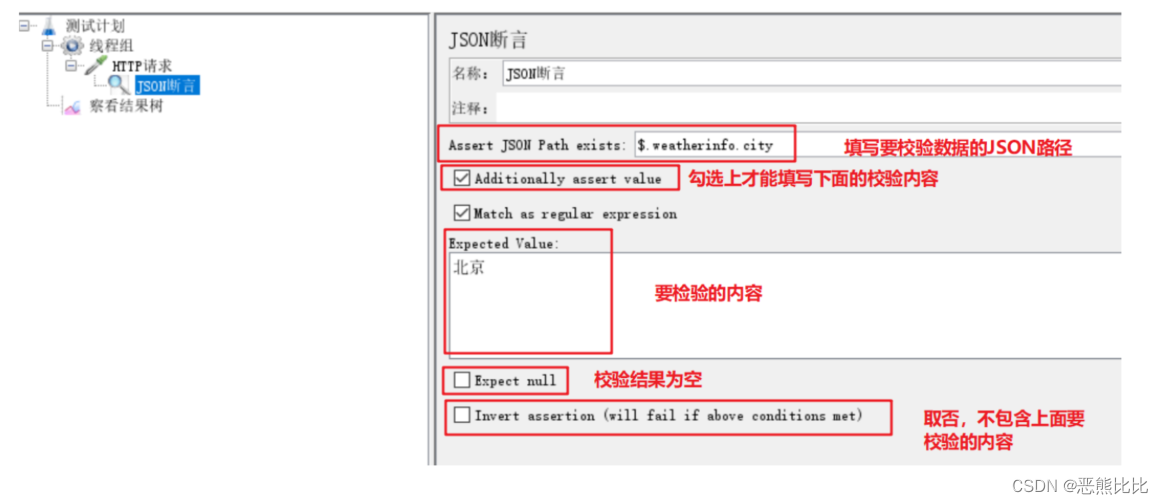
该组件用来对JSON文档进行验证,验证步骤如下:
- 首先解析JSON数据,如果数据不是JSON,则验证失败。
- 使用Jayway JsonPath 1.2.0中的语法搜索指定的路径。如果找不到路径,就会失败。
- 如果在文档中找到JSON路径,并且要求对期望值进行验证,那么它将执行验证操作。
操作步骤
1.添加线程组
2.添加HTTP请求
3.添加JSON断言
4.添加断言结果
5.添加查看结果树
案例
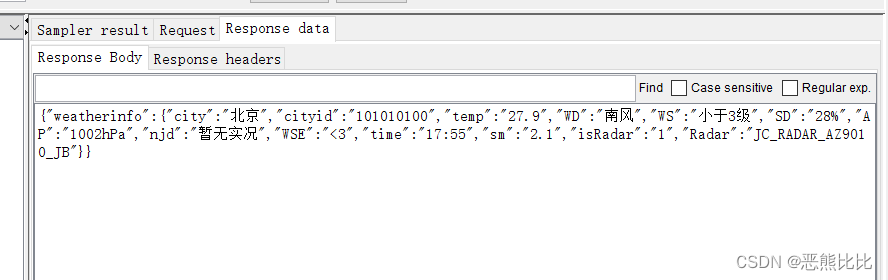
- 请求:http://www.weather.com.cn/data/sk/101010100.html
- 检查:让程序检查响应的JSON数据中,city对应的内容是否为“北京
6.3 持续时间断言
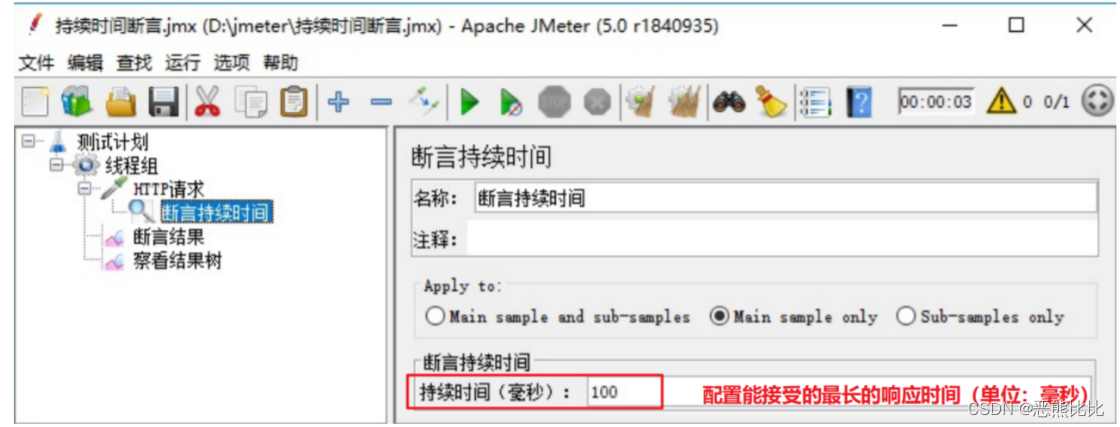
概念:
对响应时间进行断言
客户端发送请求,到收到服务器的响应的时间,要求不超过指定的时间。
添加方式
测试计划 --> 线程组–> HTTP请求 --> (右键添加) 断言 --> 断言持续时间
操作步骤
1.添加线程组
2.添加HTTP请求
3.添加断言持续时间
4.添加断言结果
5.添加查看结果树
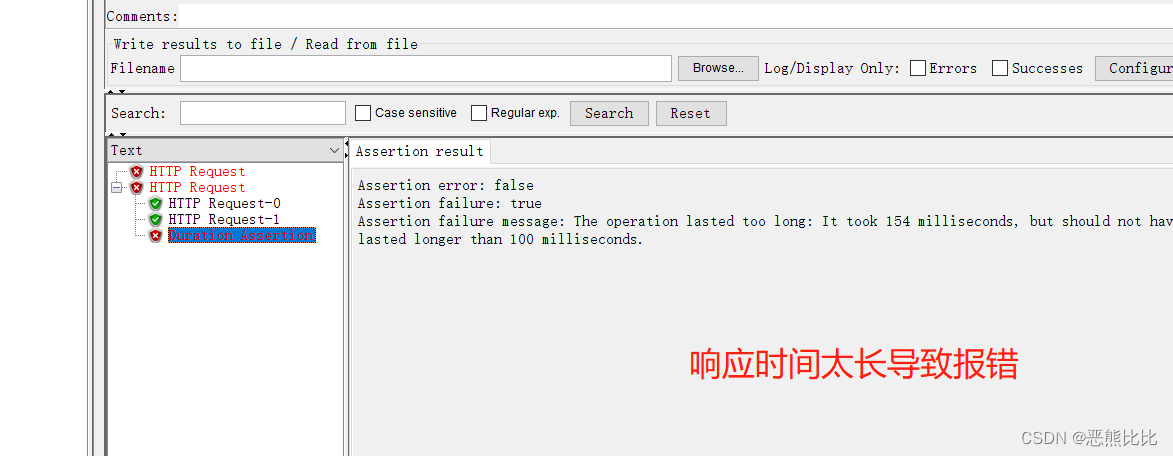
案例
- 请求:https://www.jd.com
- 检查:让程序检查响应时间是否大于500毫秒
7.JMeter 关联
关联
- 当请求之间有依赖关系,比如一个请求的入参是另一个请求返回的数据,这时候就需要用到关联处理;
- JMeter可以通过后置处理器中的一些组件来处理关联。
关联方法
- 正则表达式提取器
- XPath提取器
- JSON提取器
7.1 正则表达式提取器
正则表达式介绍

添加方式
测试计划 --> 线程组–> HTTP请求 --> (右键添加) 后置处理器 --> 正则表达式提取器
场景
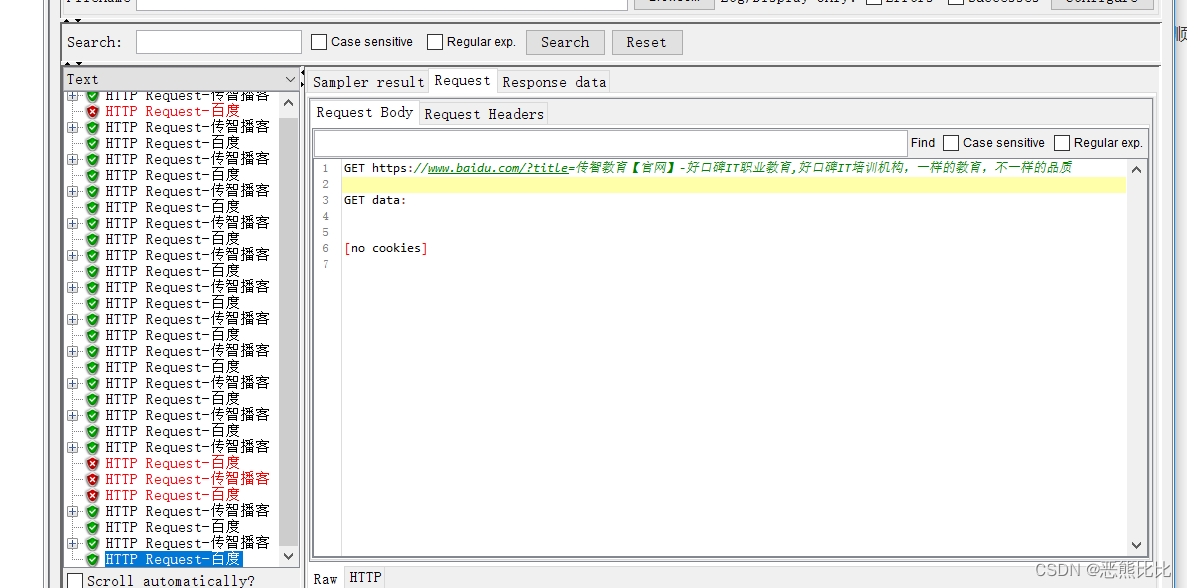
请求:http://www.itcast.cn/ ,获取网页的title值
请求:https://www.baidu.com/
,把获取到的title作为请求参数
操作步骤
1.添加线程组
2.添加HTTP请求-传智播客
3.添加正则表达式提取器
4.添加HTTP请求-百度
5.添加查看结果树
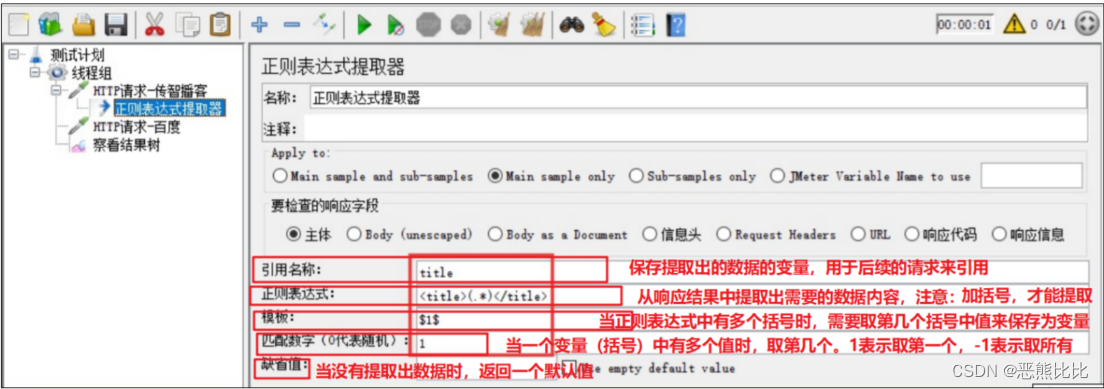
正则表达式提取器
应用场景:正则表达式提取器可以提取任意格式的响应数据
参数介绍
7.2 XPath提取器
XPath
页面元素都是有标签的,标签会形成一组完整的路径可以定位到元素上去。
//Xpath是web页面的特色
应用场景
只能适用于响应消息为HTML格式的情况
添加方式:
测试计划 --> 线程组–> HTTP请求 --> (右键添加) 后置处理器 --> XPath提取器
场景
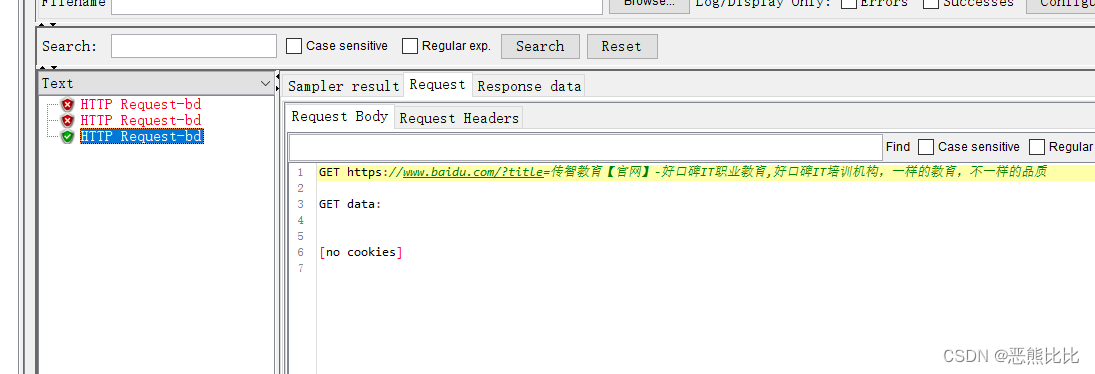
请求:http://www.itcast.cn/ ,获取网页的title值
请求:https://www.baidu.com/,把获取到的title作为请求参数
操作步骤
- 添加线程组
- 添加HTTP请求-传智播客
- 添加XPath提取器
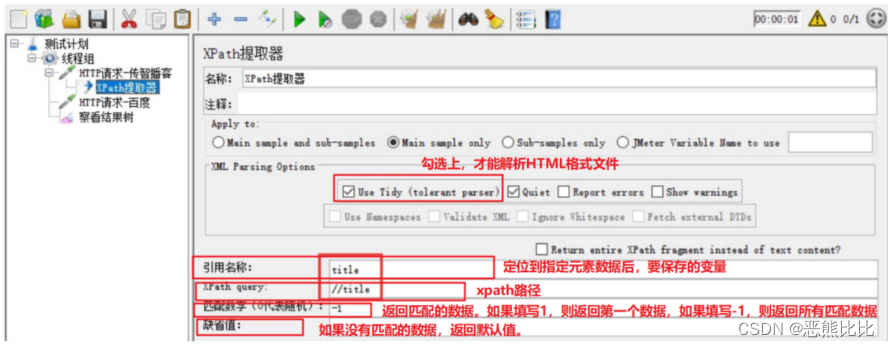
勾选Use Tidy
填写引用名称:参数名
Xpath路径- 添加HTTP请求-百度
引用xpath提取器中定义的参数名:${参数名}- 添加查看结果树
参数介绍
7.3 JSON提取器
应用场景
:适用于返回的数据类型为JSON格式的情况
添加方式
测试计划 --> 线程组–> HTTP请求 --> (右键添加) 后置处理器 --> JSON提取器
场景
- 请求获取天气的接口,http://www.weather.com.cn/data/sk/101010100.html
- 获取返回结果中的城市名称
- 请求:https://www.baidu.com/s?wd=北京 ,把获取到的城市名称作为请求参数
操作步骤
- 添加线程组
- 添加HTTP请求——传智播客首页
- 添加xpath提取器
勾选Use Tidy
填写引用名称:参数名
Xpath路径- 添加HTTP请求——百度首页
引用xpath提取器中定义的参数名:${参数名}- 添加查看结果树
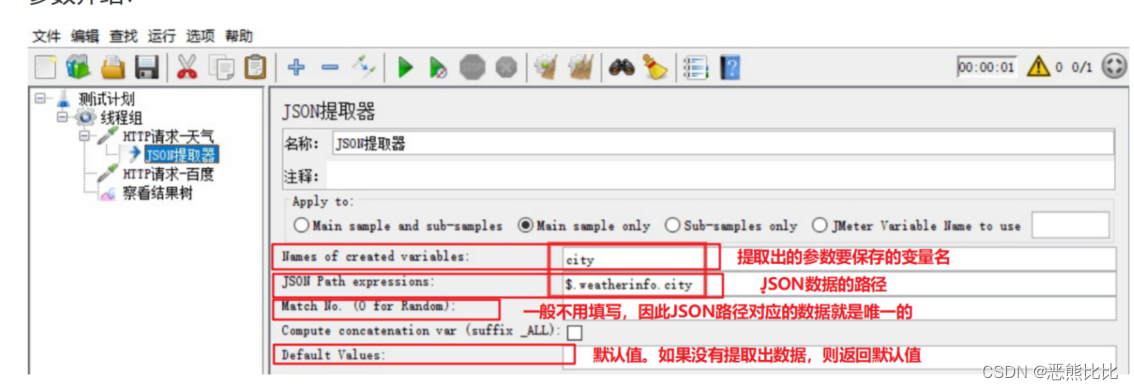
7.4 跨线程组的关联(不同用户执行)
应用条件
当有依赖关系的两个请求(一个请求的入参是另一个请求返回的数据),放入到不同的线程组中时,就不能使用提取器保存的变量来传递参数值,而是要使用Jmeter属性来传递
- 属性:类似于全局变量
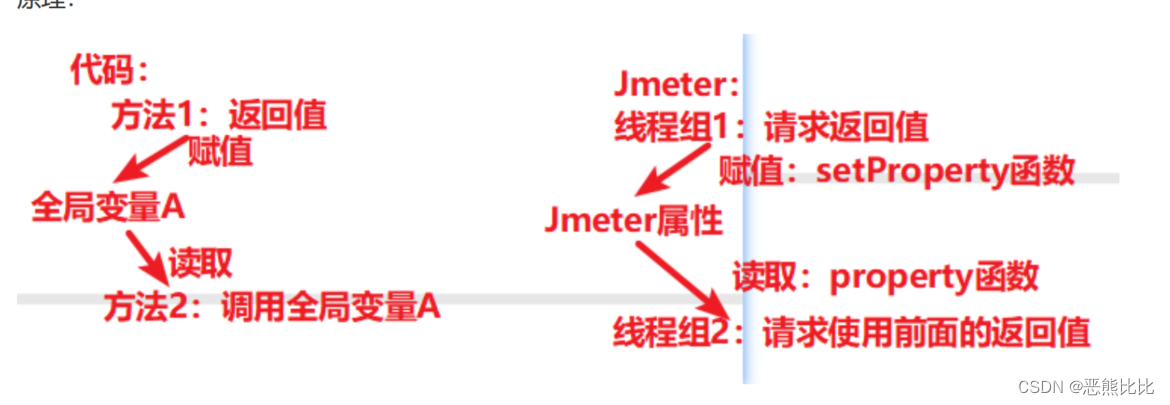
Jmeter属性的配置方法

场景
- 线程组1:请求获取天气的接口,http://www.weather.com.cn/data/sk/101010100.html
- 获取返回结果中的城市名称
- 线程组2:请求:https://www.baidu.com/s?wd=北京 ,把获取到的城市名称作为请求参数
操作步骤
1.添加线程组1
2.添加HTTP请求-天气
3.添加JSON提取器
4.添加BeanShell取样器(将JSON提取器提取的值保存为Jmeter属性)
5.添加HTTP请求-百度(读取Jmeter属性)
6.添加查看结果树

8.JMeter录制脚本
应用场景
在没有接口文档的旧项目当中,快速录制web页面产生的http接口请求,帮助编写接口测试脚本。
- 作用:将操作过程直接转化成脚本;
JMeter脚本录制
Jmeter在客户端和服务器之间做代理。
- 代理服务器的原理主要拦截和转发请求与响应数据。
- 收到所有的请求和响应数据后,Jmeter再进行逆向解析的动作,将数据报文转化为脚本。
web脚本录制步骤
- 添加http代理服务器(测试计划下边)
- 配置http代理服务器(配置代理服务器端口、脚本存放位置)
- 启动http代理服务器
- 配置浏览器/PC机的代理
- 执行操作并生成脚本
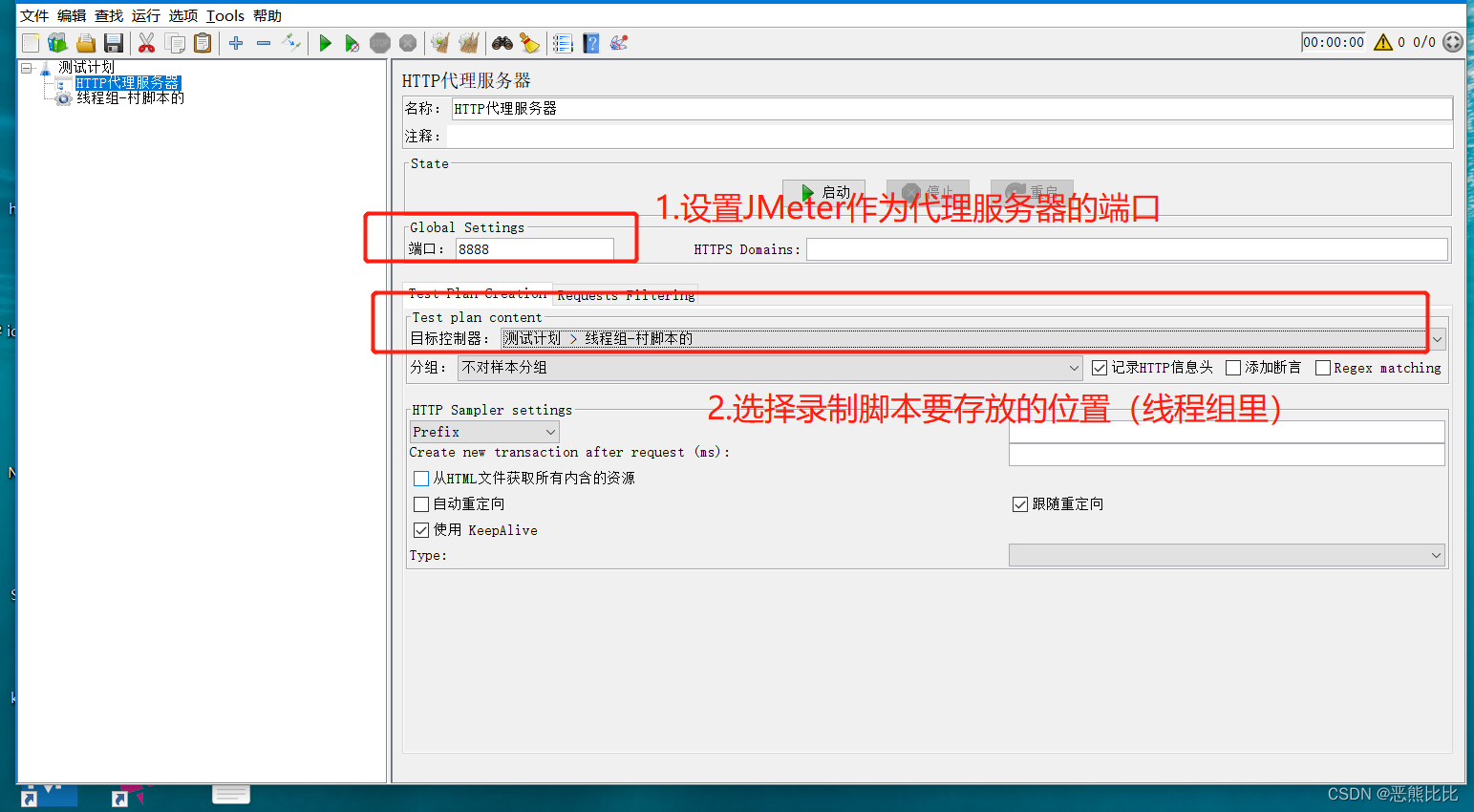
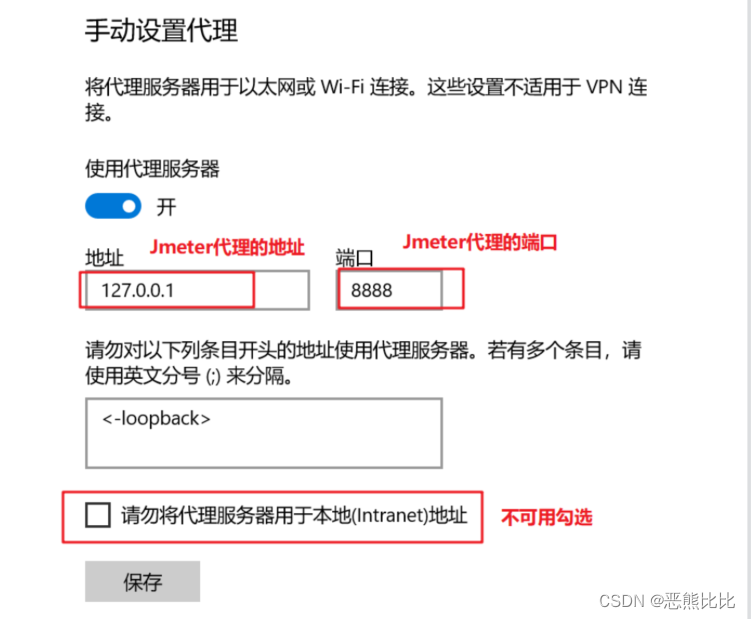
过滤规则配置
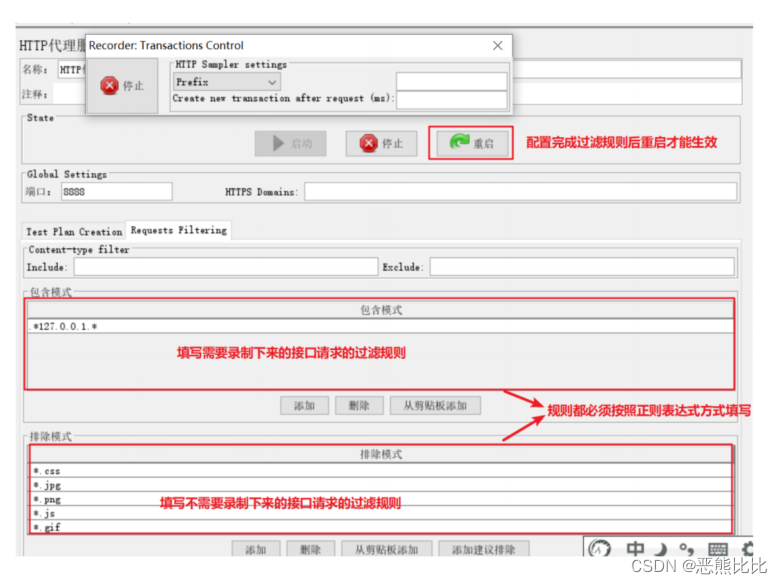
Cookie管理器
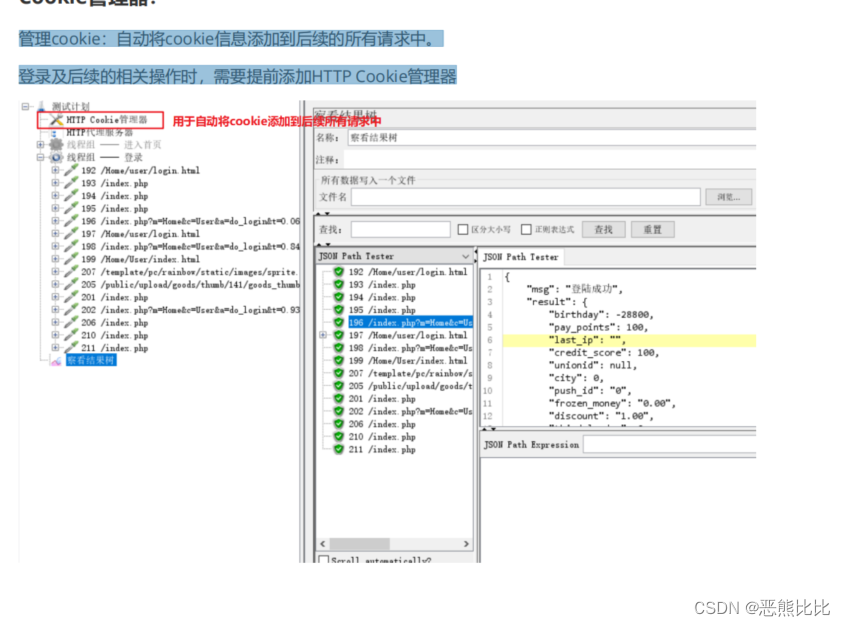
管理cookie:自动将cookie信息添加到后续的所有请求中。 登录及后续的相关操作时,需要提前添加HTTP Cookie管理器
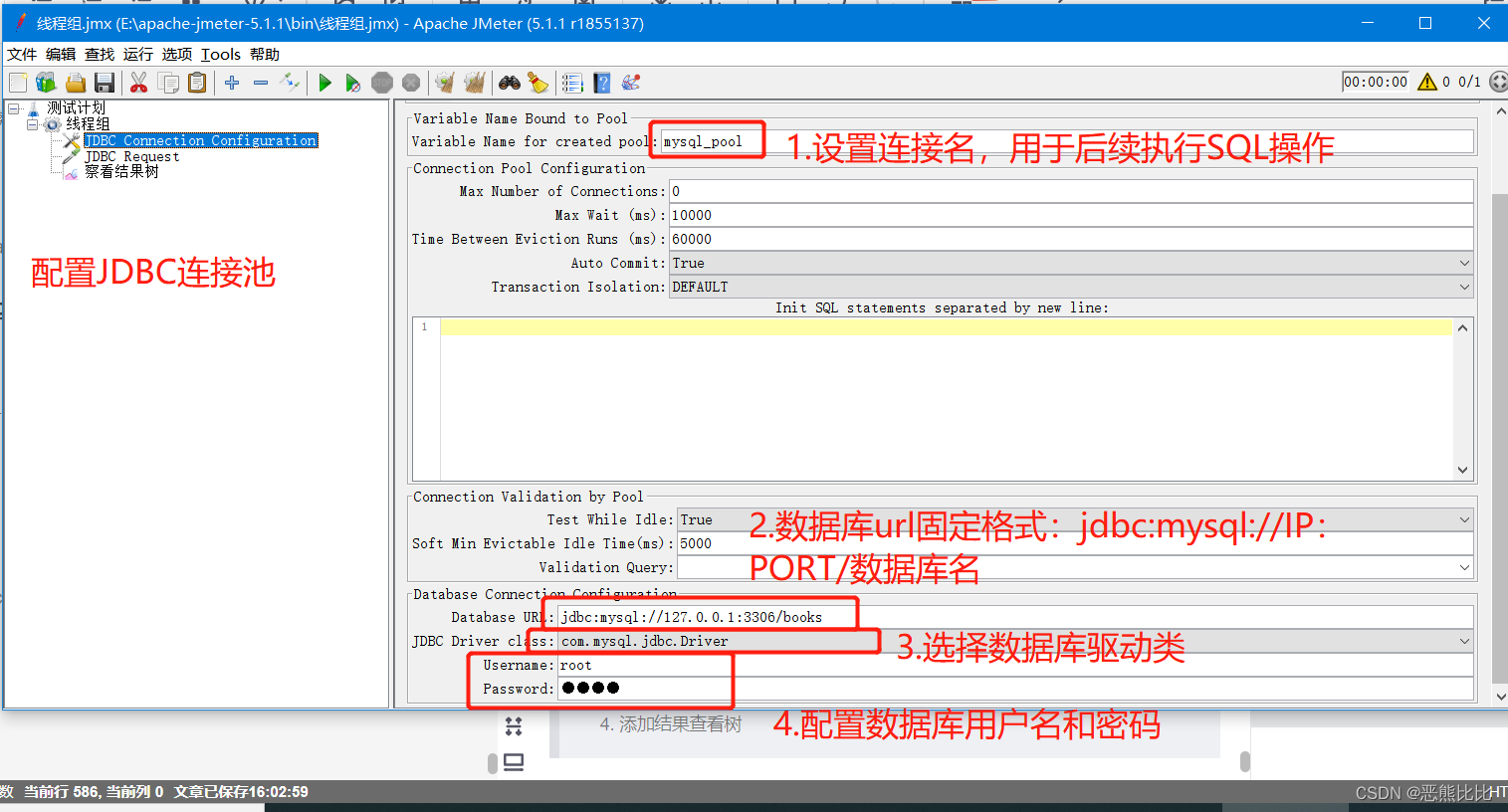
9.JMeter直连数据库
添加MYSQL驱动jar包
添加方式:
- 测试计划 --> 线程组–> (右键添加) 配置元件 --> JDBC Connection Configuration
操作步骤
- 创建新的线程组
- 添加JDBC Connection Configuration
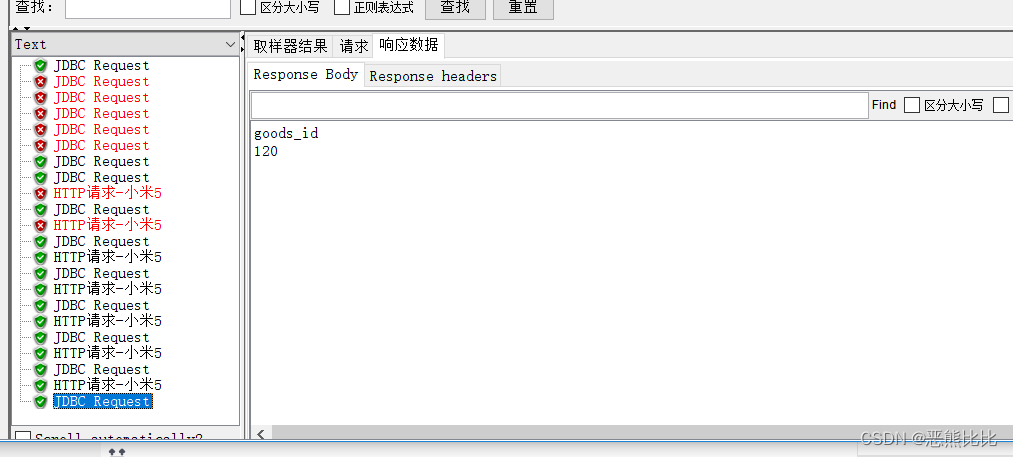
- JDBC request
- 添加结果查看树
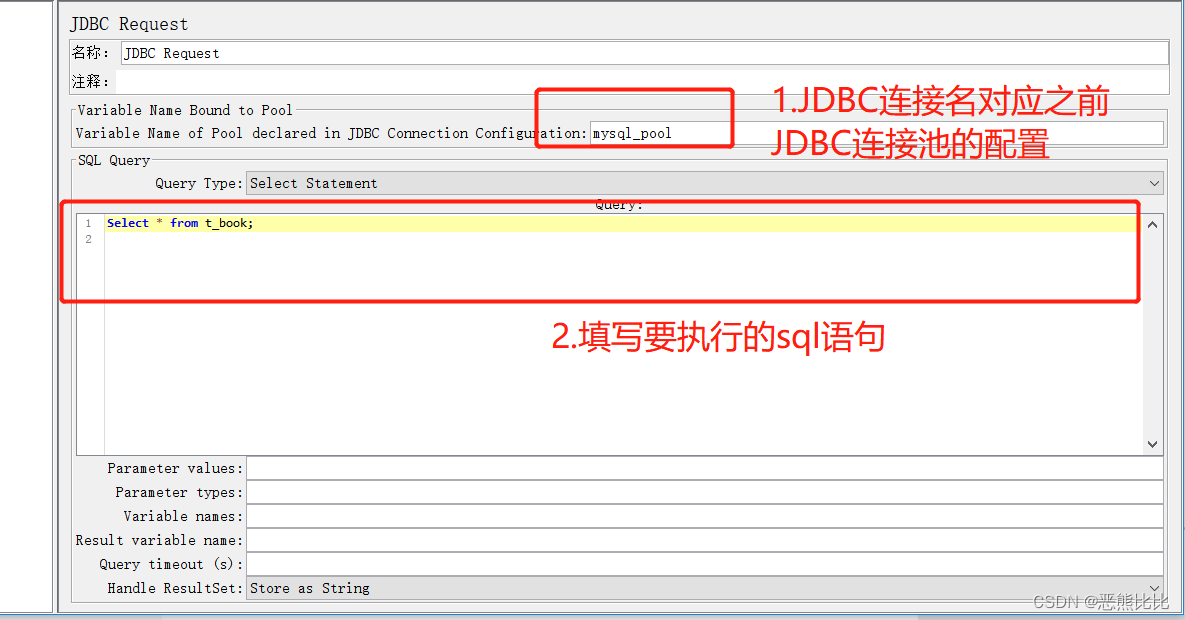
配置JDBC Request请求
案例
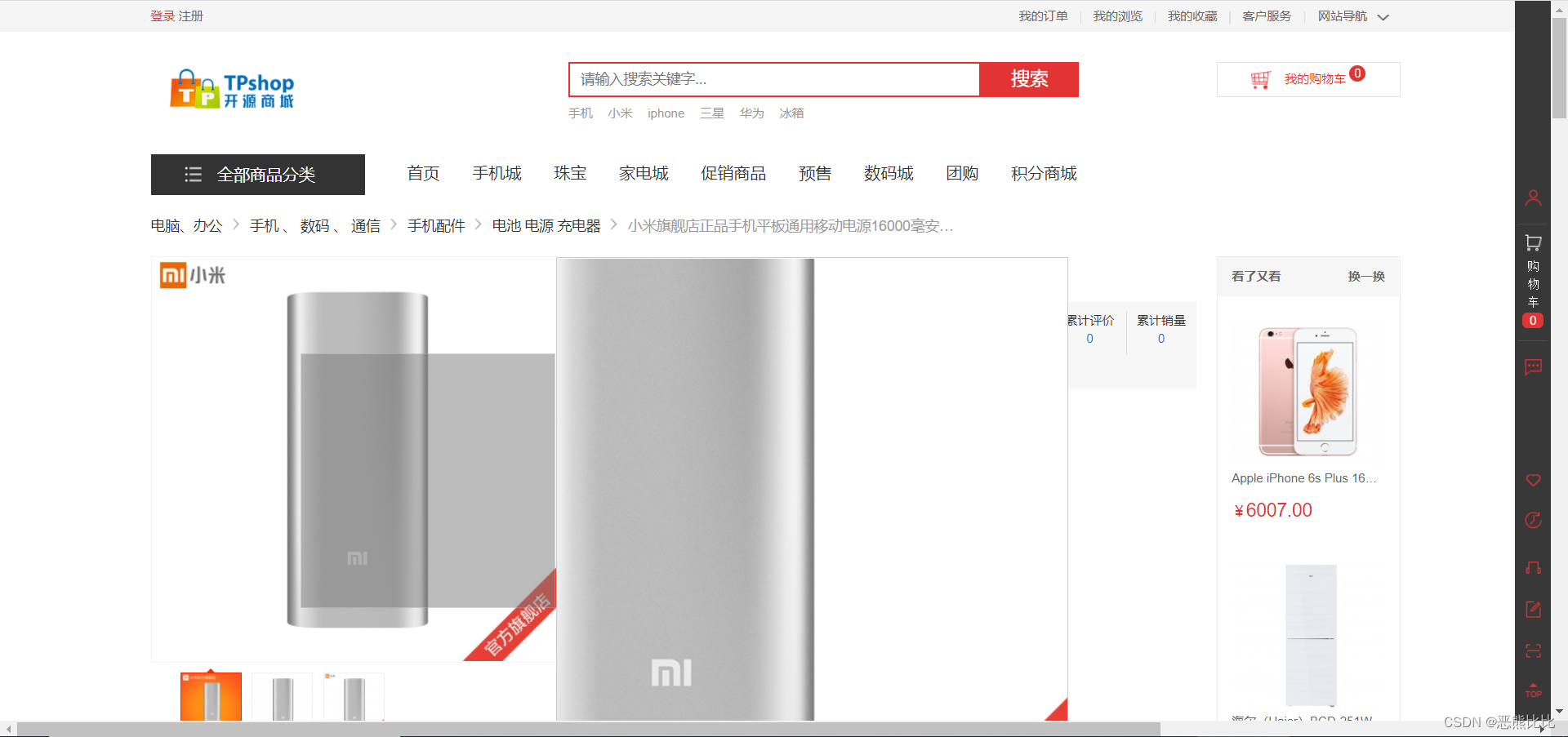
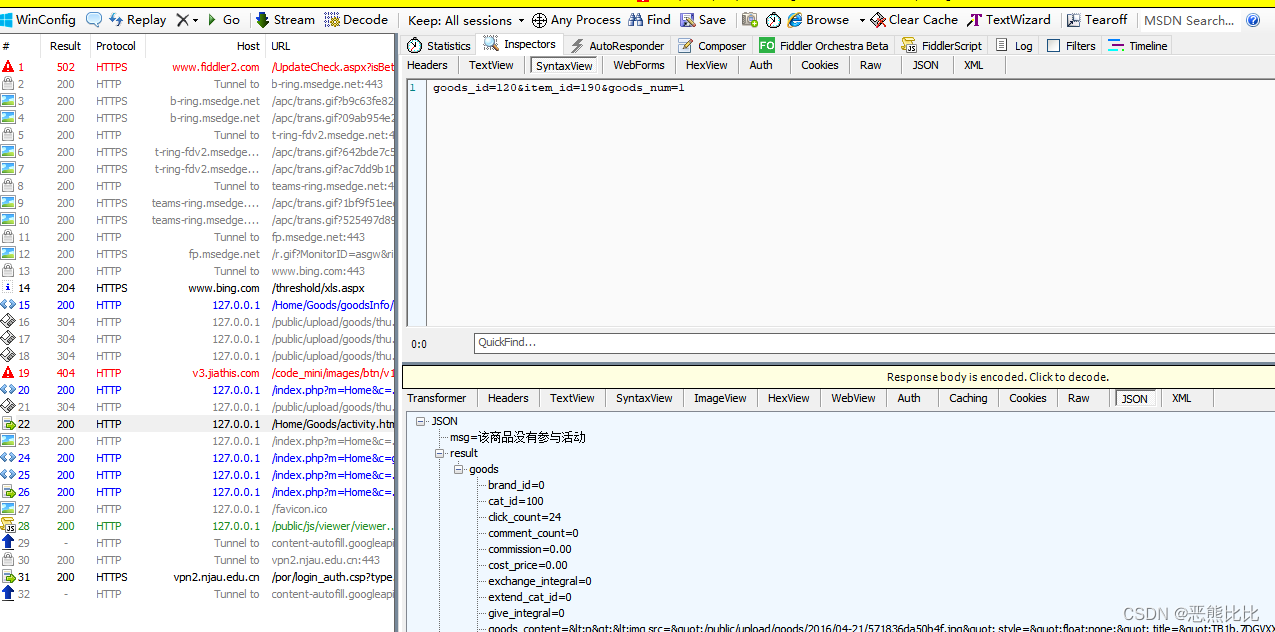
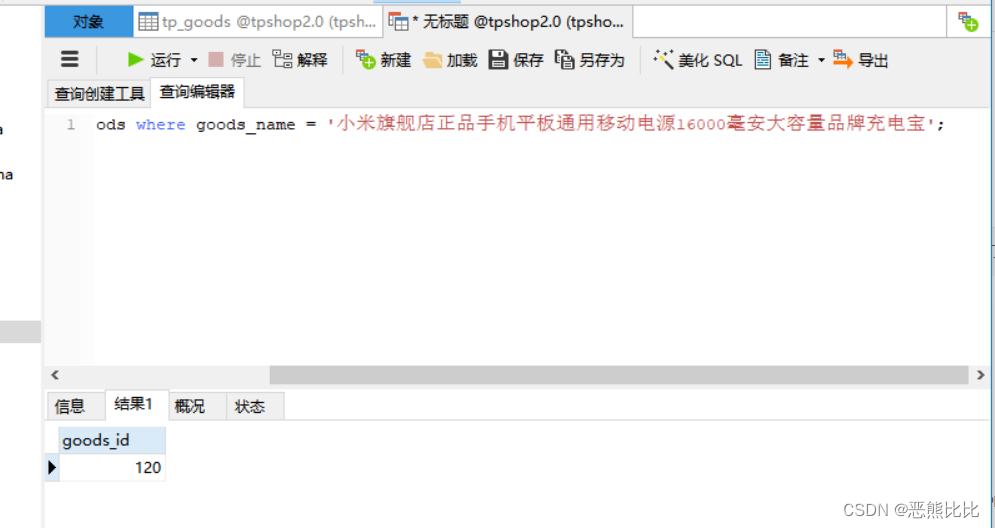
连接tpshop商城数据库获取商品名包含:小米手机5 的商品id
准备工作
启动tpshop数据库服务器
- 库名:tpshop2.0
表名:tp_goods
商品id字段:goods_id
商品名字段:goods_name
10. JMeter逻辑控制器
逻辑控制器可以按照设定的逻辑控制取样器的执行顺序
常用的逻辑控制器
- if控制器
- 循环控制器
- foreach控制器
10.1 if控制器
If控制器用来控制它下面的测试元素是否运行
添加方式
测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> 如果(If)控制器
两张配置方法
- 配置多个if控制器
- 勾选上Interpret Condition as Variable Expression,判断条件需用使用jexl3函数
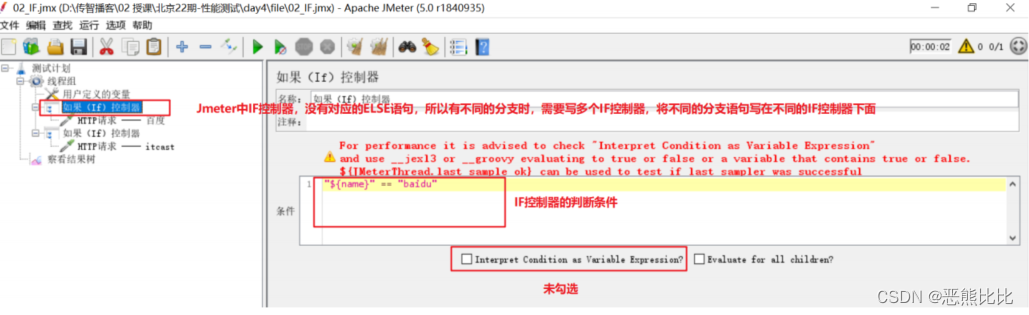
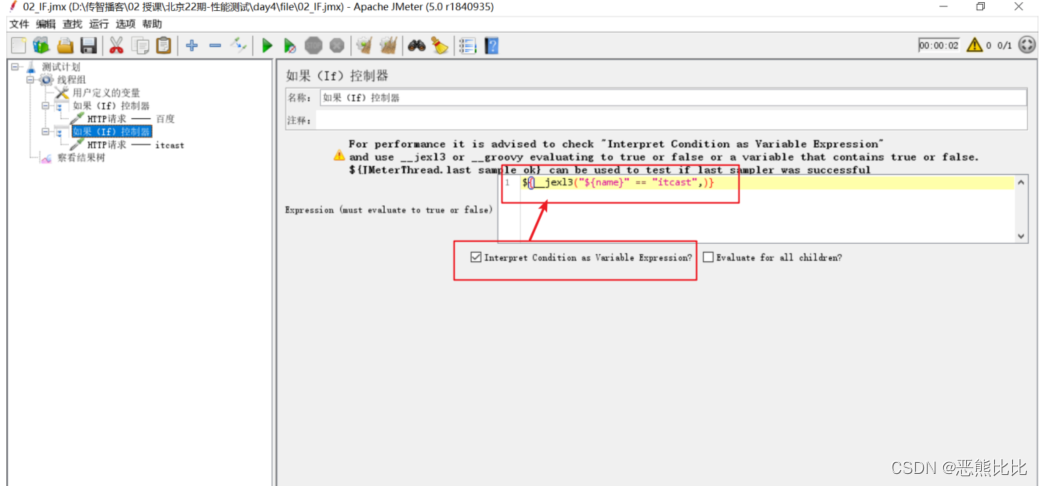
案例需求
- 使用‘用户定义的变量’定义一个变量name,name的值可以是‘baidu’或‘itcast’
- 根据name的变量值实现对应网站的访问
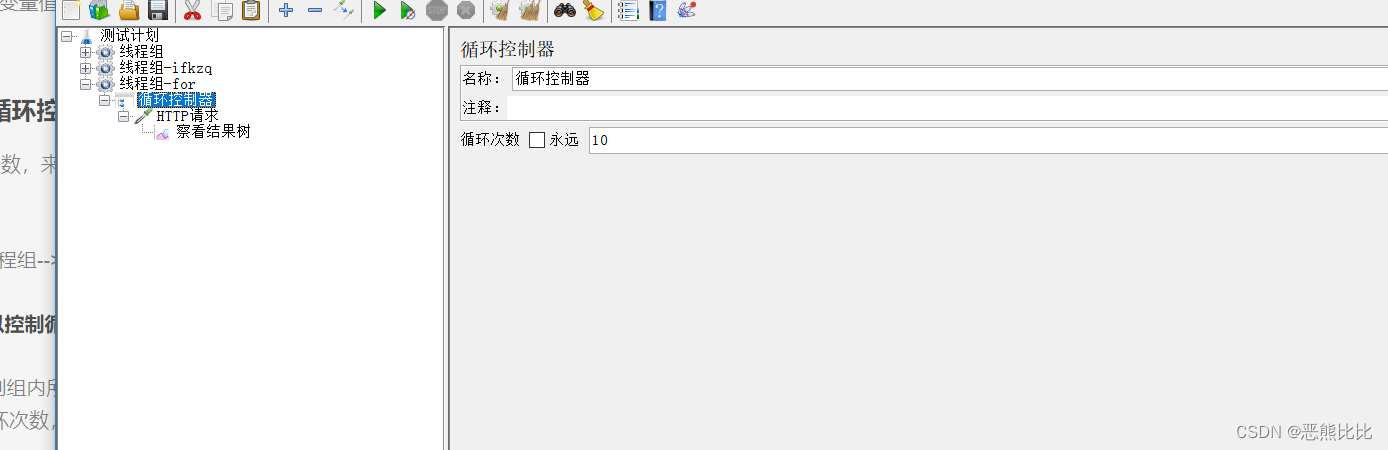
10.2 for循环控制器
通过设置循环次数,来实现循环发送请求
添加方式
测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> 循环控制器
线程组属性可以控制循环次数,那么循环控制器有什么用?
线程组属性控制组内所有取样器的执行次数,而循环控制器可以控制组内部分取样器的循环次数,后者控制精度更高
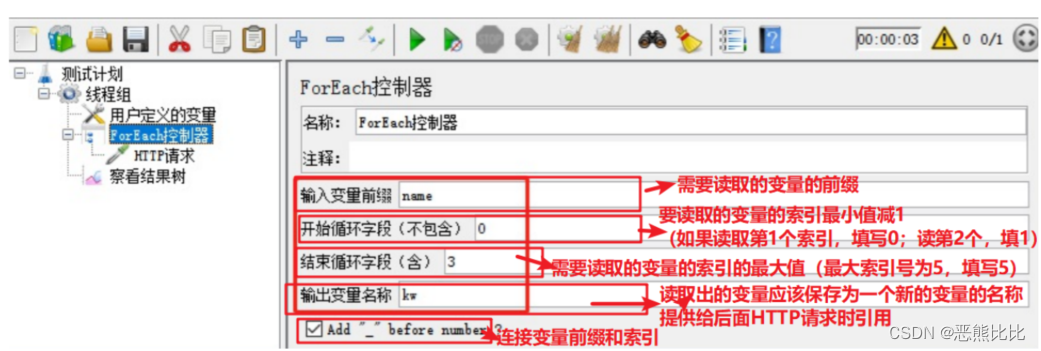
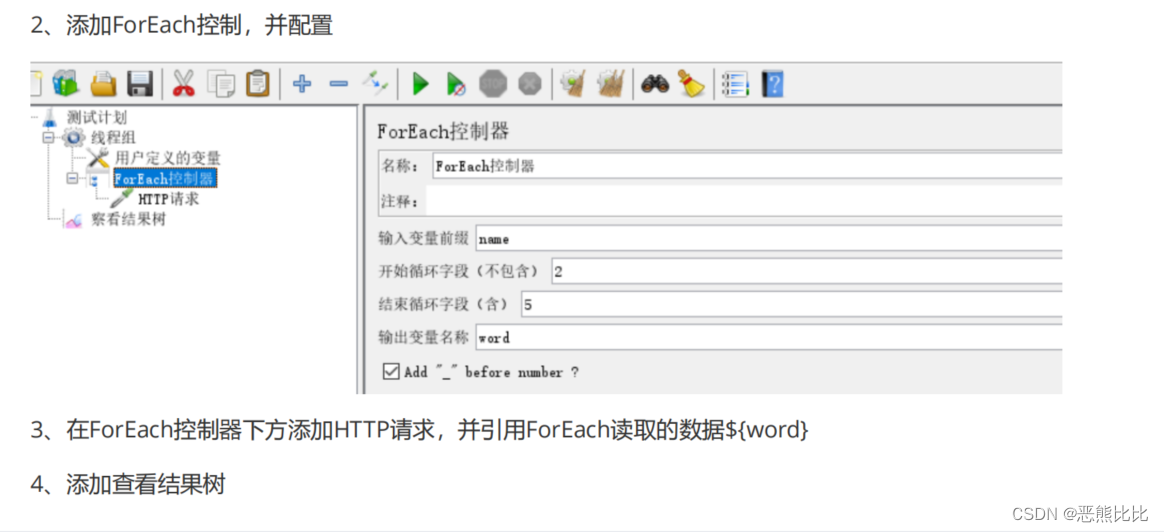
10.3 ForEach控制器
ForEach控制器一般和用户自定义变量或者正则表达式提取器一起使用,其在用户自定义变量或者从正则表达式提取器的返回结果中读取一系列相关的变量。
- 该控制器下的取样器都会被执行一次或多次,每次读取不同的变量值。
添加方式:
测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> ForEach控制器
配置参数
11.JMeter定时器
11.1 同步定时器(Synchronizing Timer)
.同步定时器(Synchronizing Timer)
提示:在Jmeter中叫做同步定时器,在其他软件中又叫集合点。
实现原因:设置同步定时器,有请求要发出时,同步定时器会暂缓请求发送,一直到积攒的请求数达到要的数量时
SyncTimer的目的
阻塞线程,直到阻塞了n个线程,然后立即释放它们
- 同步定时器相当于一个储蓄池,累积一定的请求,当在规定的时间内达到一定的线程数量,这些线程会在同一个时间点一起并发,所以可以用来做大数据量的并发请求。
- 保证大量的请求在同一时间进行发送,形成绝对的并发
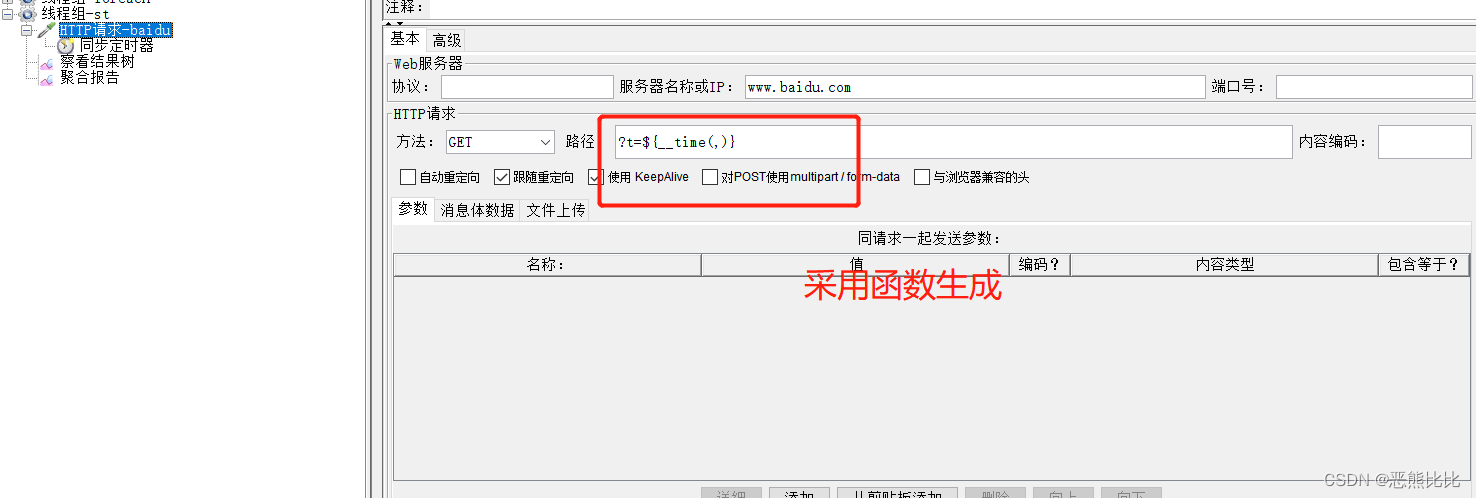
添加方式
测试计划 --> 线程组–> HTTP请求 --> (右键添加) 定时器 --> Synchronizing Timer
案例
模拟100个用户同时访问百度首页,统计高并发情况下运行情况
操作步骤
- 添加线程组,设置线程数=100
- 添加HTTP请求
- 添加同步定时器
- 添加查看结果树
- 添加监听器-聚合报告
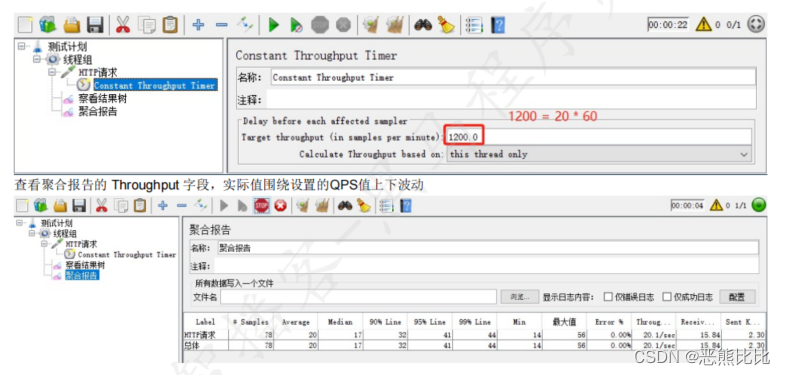
11.2 常数吞吐定时器(Constant Throughput Timer)
概念
常数吞吐量定时器可以让JMeter以指定数字的吞吐量(以每分钟的样本数为单位,而不是每秒)执行。
吞吐量计算的范围可以为指定为当前线程、当前线程组、所有线程组。
添加方式
测试计划 --> 线程组–> HTTP请求 --> (右键添加) 定时器 --> Constant Throughput Timer
场景
一个用户以 20QPS (20 次/s) 的频率访问百度首页,持续一段时间,统计运行情况
操作步骤
- 添加线程组,循环次数设置成永远
- 添加HTTP请求
- 添加常数吞吐定时器
- 添加查看结果树
- 添加监听器-聚合报告
12. JMeter分布式
使用背景
在使用JMeter进行性能测试时,如果并发数比较大(比如项目需要支持10000并发),单台电脑的(CPU和内存)可能无法支持,这时可以使用JMeter提供的分布式测试的功能。
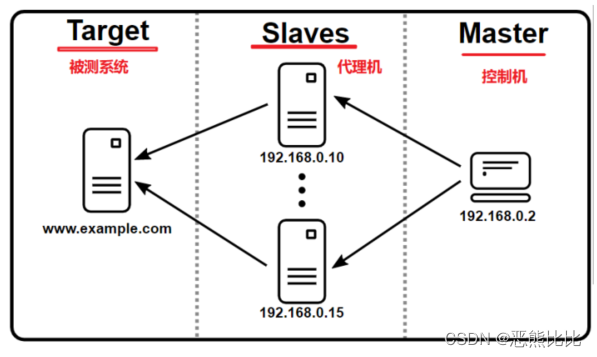
JMeter分布式执行原理
- 分布式测试时通常由1台控制机和N台代理机
- 控制机:给代理发送任务,接收代理机返回的数据统计,做汇总展示
- 代理机:往服务器发送HTTP请求,并接收服务器的响应,并对响应进行处理
注意事项
- 测试机上所有的防火墙关闭
- 所有的控制机、代理机、被测系统都在同一个子网中
- 所有的控制机和代理机上安装的Jmeter和JDK的版本必须完全一样。
- 要关闭Jmeter中的RMI SSL开关
13.JMeter测试报告
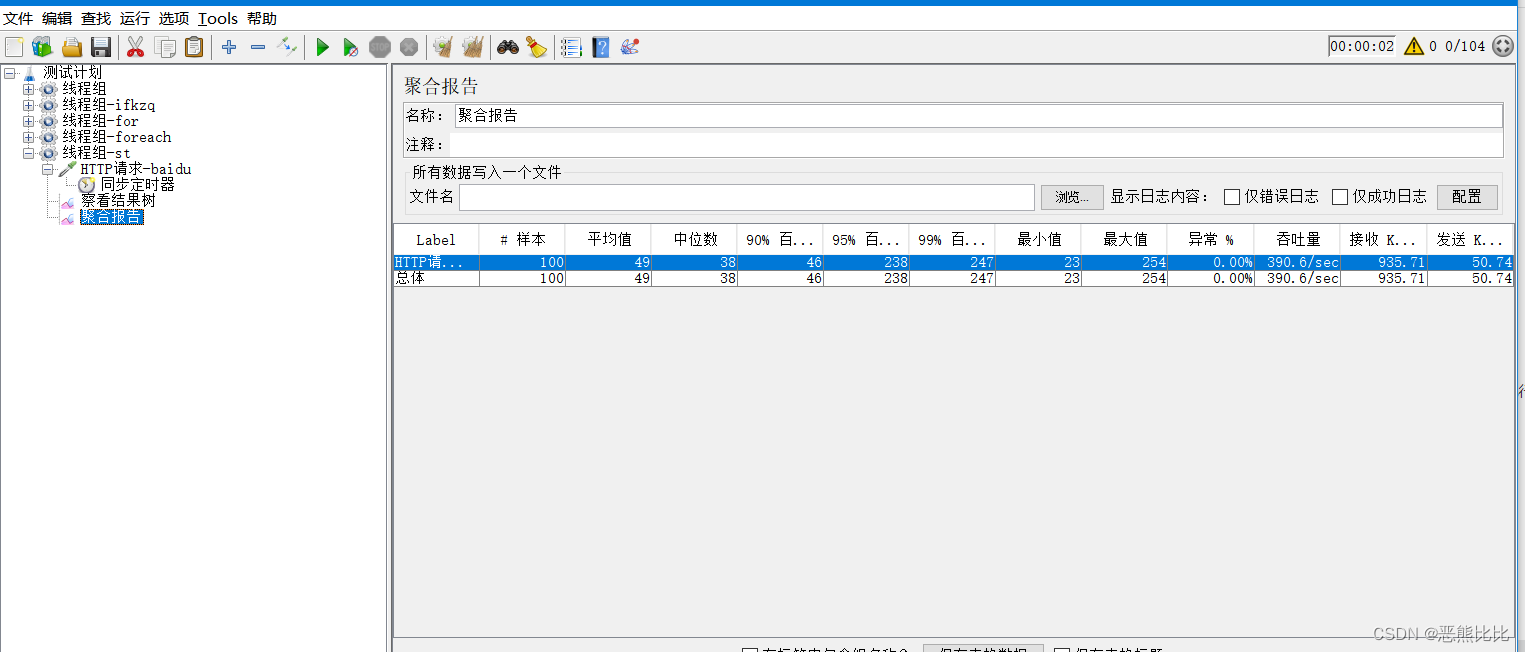
测试计划->右键->监听器->聚合报告
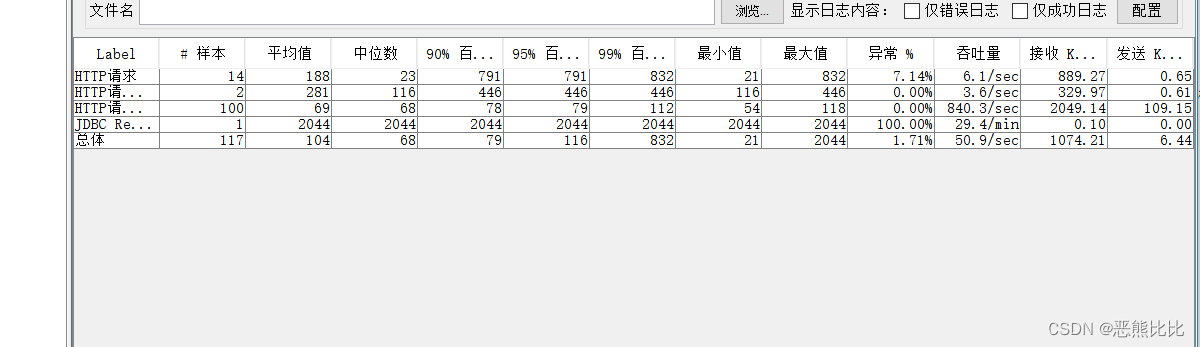
- Label:每个请求的名称(勾选:在标签中包含组名称,显示线程组名-取样器名)
- #样本:各请求发出的数量
- 平均值:平均响应时间(单位:毫秒)。默认是单个Request的平均响应时间
- 中位数:中位数,50% <= 时间
- 90%百分比:90% <= 时间
- 95%百分比:95% <= 时间
- 99%百分比:99% <= 时间
- 最小值:最小响应时间
- 最大值:最大响应时间
- 异常%:请求的错误率 = 错误请求的数量/请求的总数
- 吞吐量:吞吐量。默认情况下表示每秒完成的请求数,一般认为它为TPS。
- 接收 KB/sec:每秒从服务器端接收到的千字节数
- 发送 KB/sec:每秒向服务器发送的千字节数
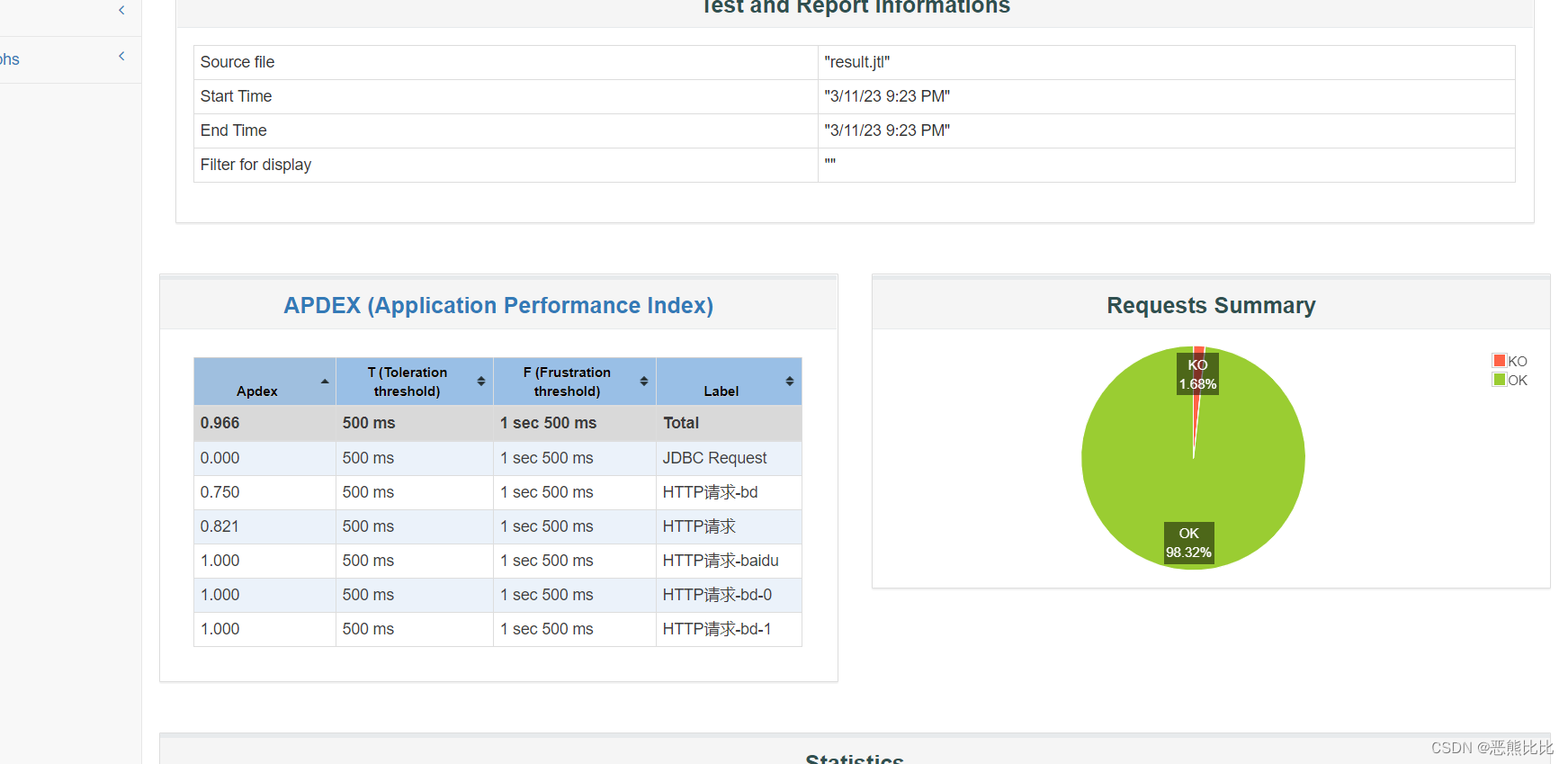
13.1 生成html测试报告
JMeter支持生成HTML测试报告,以便从测试计划中获得图表和统计信息。
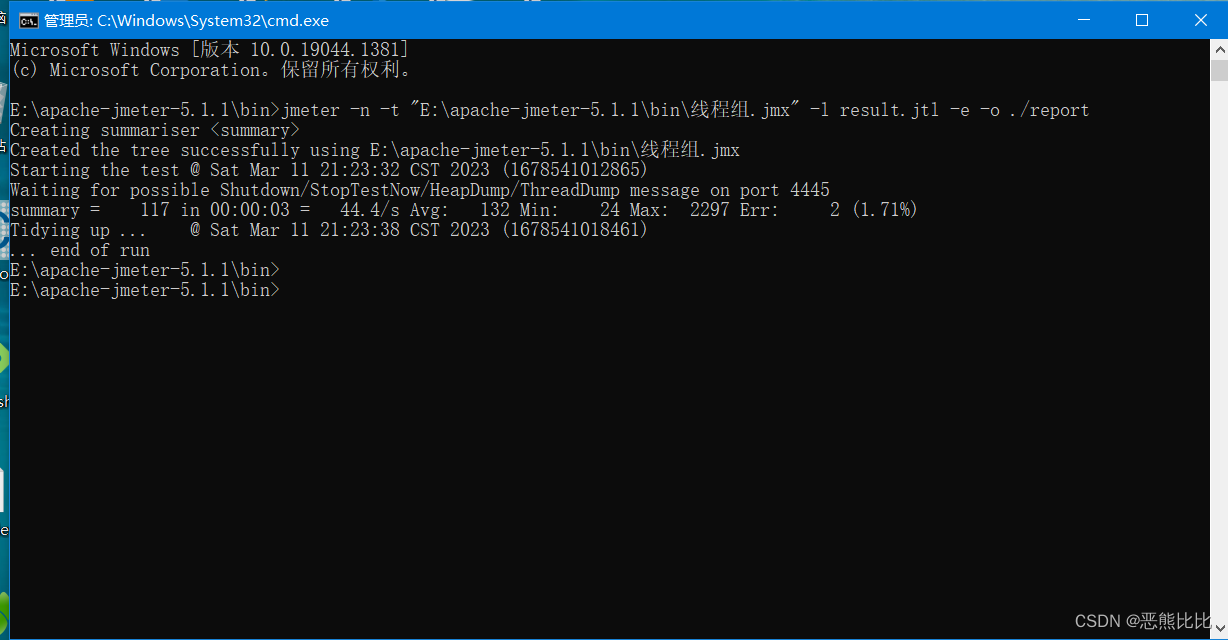
命令
jmeter -n -t [jmx file] -l [result file] -e -o [html report folder]
eg: jmeter -n -t hello.jmx -l result.jtl -e -o ./report
-n:非GUI模式执行JMeter
-t [jmx file]:测试计划保存的路径及.jmx文件名,路径可以是相对路径也可以是绝对路径
-l [result file]:保存生成测试结果的文件,jtl文件格式
-e:测试结束后,生成测试报告
-o [html report folder]:存放生成测试报告的路径,路径可以是相对路径也可以是绝对路径

14.Locust
Locust简介
Locust是一个开源的性能测试工具,主要思想就是模拟一群用户访问你的系统。
特点
- 在代码中定义用户行为 不需要安装笨重的软件,只是简单的Python代码
- 分布式和可扩展 Locust支持在多台机器上的运行负载测试,因此可用于模拟数百万用户的请求
- 经过验证和战斗测试 Locust被用于许多真实的项目中
- Locust有一个整洁的HTML+JS的用户界面,实时显示相关测试细节 由于用户界面是基于网络的,它是跨平台的和容易扩展















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









