






本文精选了美团技术团队被CVPR 2024收录的7篇论文进行解读,这些论文既包括OCR预训练、长尾半监督学习等基础学习范式升级,也包括图生视频、数字人驱动、视听分割(AVS)等视觉AIGC技术创新。这些论文有美团视觉智能部的独立产出,也有跟高校、科研机构合作的成果。希望能给从事相关研究工作的同学带来一些帮助或启发。
CVPR 全称为 IEEE Conference on Computer Vision and Pattern Recognition,国际计算机视觉与模式识别会议。该会议始于1983年,与ICCV和ECCV并称计算机视觉方向的三大顶级会议。根据谷歌学术公布的2022年最新学术期刊和会议影响力排名,CVPR在所有学术刊物中位居第4,仅次于Nature、NEJM和Science。

6月27日(周四),我们将邀请4位论文作者进行线上分享,文末有详细介绍(以及CVPR展会信息),欢迎点击这里报名~
01
ODM: A Text-Image Further Alignment Pre-training Approach for Scene Text Detection and Spotting
展示位置:6月20日 17:15-18:45(美西时间) Poster Session 4 No.95 & Exhibit Hall (Arch 4A-E)
论文作者:Chen Duan(Meituan),Pei Fu(Meituan),Shan Guo(Meituan),Qianyi Jiang(Meituan),Xiaoming Wei(Meituan)
论文下载:PDF
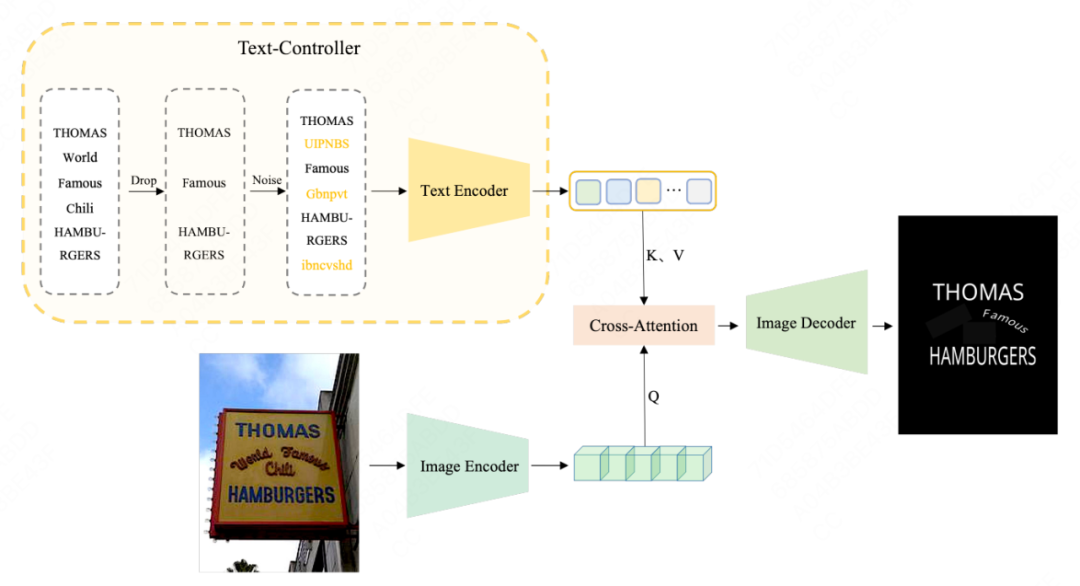
论文简介:近年来,文本-图像联合预训练技术在多个领域展现出了卓越的性能。然而,在光学字符识别(OCR)任务中,将文本提示与图像中相应的文本区域对齐是一个挑战,现有的基于MIM(Masked Image Modeling)或者基于MLM(Masked Language Modeling)的方法存在一定的局限性。
本文提出了一种创新的预训练方法,称为OCR-Text Destylization Modeling(ODM),它可以将图像中不同风格的文本转换为基于文本提示的统一风格文本。通过ODM,我们可以更好地对齐文本提示和图像中OCR文本,并使预训练模型适应场景文本检测和端到端任务中复杂多样的字体风格。此外,我们还设计了一种新颖的标签生成方法,并将其与我们提出的文本控制器模块相结合,有效降低了OCR任务中的标注成本,使得更多未经人工标注的数据能够被用于预训练。在多个公共数据集上的实验表明,我们的方法在场景文本检测和端到端识别任务中显著提高了性能,并超过了现有的预训练方法。
02
BEM: Balanced and Entropy-based Mix for Long-Tailed Semi-Supervised Learning
展示位置:6月21日 10:30-12:00(美西时间) Poster Session 5 No.327 & Exhibit Hall (Arch 4A-E)
论文作者:Hongwei Zheng(Meituan),Linyuan Zhou(Meituan), Han Li(SJTU), Jinming Su(Meituan), Xiaoming Wei(Meituan),Xiaoming Xu(Meituan)
备注:SJTU(Shanghai Jiao Tong University)
论文下载:PDF
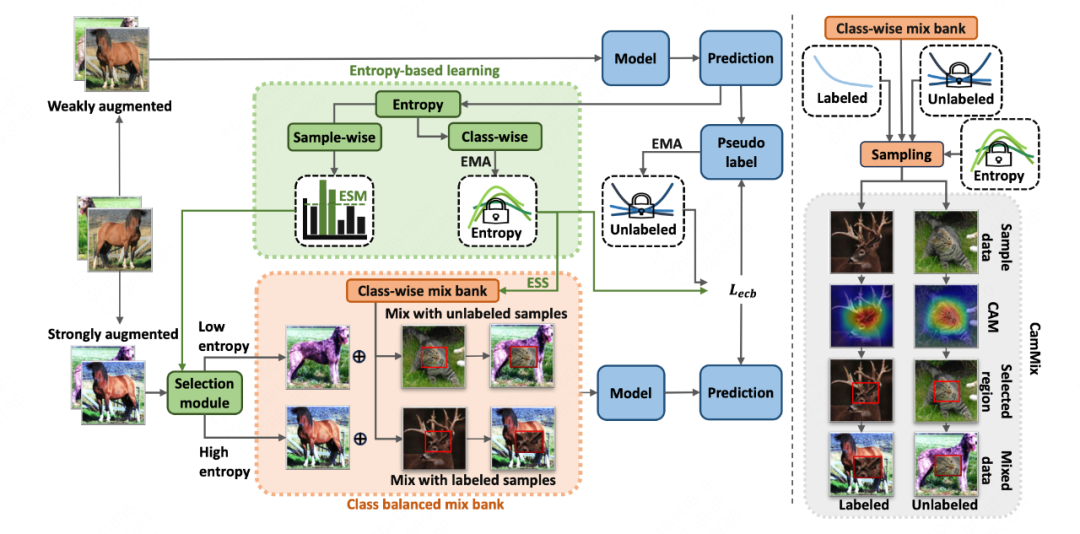
论文简介:长尾半监督学习(LTSSL)最近受到了广泛关注。本文探讨了数据混合在 LTSSL中的应用。传统的数据混合方法通常采用批量混合,无法解决类不平衡的问题。此外,类的平衡不仅与数据量有关,还与类的不确定性有关,而类的不确定性与数据量的分布存在差距。例如,一些有足够样本的类可能拥有无法区分的特征,从而导致高不确定性。
为此,本论文介绍了基于平衡和熵的混合(BEM),这是一种开创性的混合方法,可重新平衡数据量和不确定性的类别分布。具体来说,利用类平衡混合库来存储类数据,并根据对数据分布的估计对其进行采样混合,从而重新平衡类数据量。此外,我们还引入了一种基于熵的学习方法来重新平衡类的不确定性,包括基于熵的采样策略、基于熵的选择模块和基于熵的类平衡损失。实证结果表明,在多个基准测试中,BEM 与重新平衡方法相辅相成,显著提高了重新平衡方法的性能。作为首个利用数据混合来改进 LTSSL 的策略,BEM 证明了其在补充再平衡方法方面的多功能性。在不同的数据分布、数据集和 SSL 学习者之间,证明了 BEM 在补充再平衡方法方面的通用性。
03
Animating General Image with Large Visual Motion Model
展示位置:6月19日 17:15-18:45(美西时间) Poster Session 2 No.227 & Exhibit Hall (Arch 4A-E)
论文作者:Dengsheng Chen(Meituan),Xiaoming Wei(Meituan),Xiaolin Wei
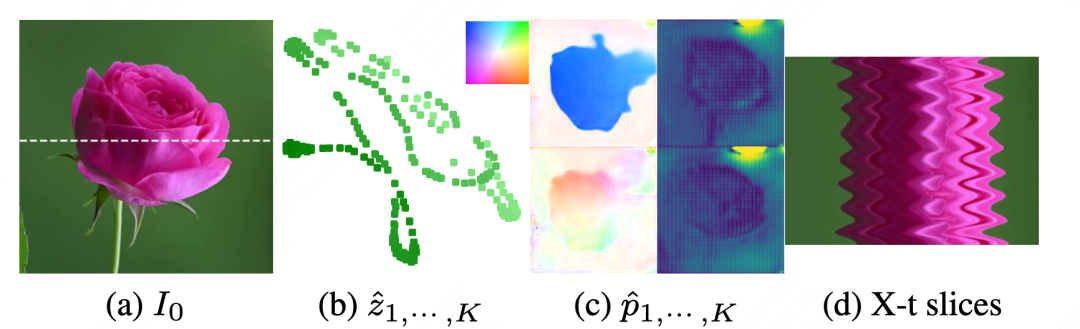
论文简介:传统基于光流构建的图像驱动算法往往受限于一些特定的使用场景,例如人脸表情驱动、手势驱动等,而无法广泛用于预测任意场景的动态特征。我们认为这主要是由于相关领域缺乏大规模高质量的训练数据和学习能力足够强的模型结构导致。
鉴于近期扩散模型在文生图上表现出令人惊艳的效果,我们首次尝试构建一个大规模的网络结构用于预测复杂场景的光流,并称之为大型视觉运动模型(LVMM)。LVMM主要由神经渲染网络(R),光流预测网络(P),压缩和重建网络(E和D)以及一个潜在空间的扩散模型e构成。整个模型需要经过三个阶段的独立训练。
首先,LVMM通过光流预测网络P生成给定两张图像之间存在的光流信息,然后通过神经渲染网络R用于将光流信息渲染成逼真的图像运动效果。在这个阶段,我们发现可以使用两个不同的网络分支分别预测光流中的高频和低频信息(如上图c所示)。其中高频信息则善于捕捉物体边缘的一些细微的运动特征,而低频信息则用于描述物体整体的运动趋势。两种特征相互补充,从而有效的估计出各种复杂场景下细微的运动差异。在完成R和P的联合训练以后,我们固定光流预测网络P的参数,将它作为一个数据预处理的操作,用于训练压缩和重建网络(E和D)。在实验过程中发现,直接使用扩散模型e去预测光流训练得到的模型无法取得很好的泛化性能,这是因为光流特征的推断往往严重依赖物体的视觉特征。如果想要得到足够好的泛化性,我们需要设计算法更好的将物体的视觉和运动特征解耦。我们发现通过压缩网络E可以将光流信息中的视觉和运动特征分别映射到两个不同的空间,从而保证扩散模型e的有效训练。最后,扩散模型e通过在高维特征空间解构物体的视觉特征和运动特征来准确预测图像中蕴含的动态特征,从而驱动静态图像表现出符合自然规律的动态效果,大大增加了图像的视觉吸引力。
04
CustomListener: Text-guided Responsive Interaction for User-friendly Listening Head Generation
展示位置:6月19日 10:30-12:00(美西时间) Poster Session 1 No.216 & Exhibit Hall (Arch 4A-E)
论文作者:Xi Liu* (Meituan), Ying Guo*(Meituan),Cheng Zhen(Meituan),Tong Li(Meituan), Yingying Ao(Meituan),Pengfei Yan(Meituan)
论文下载:PDF
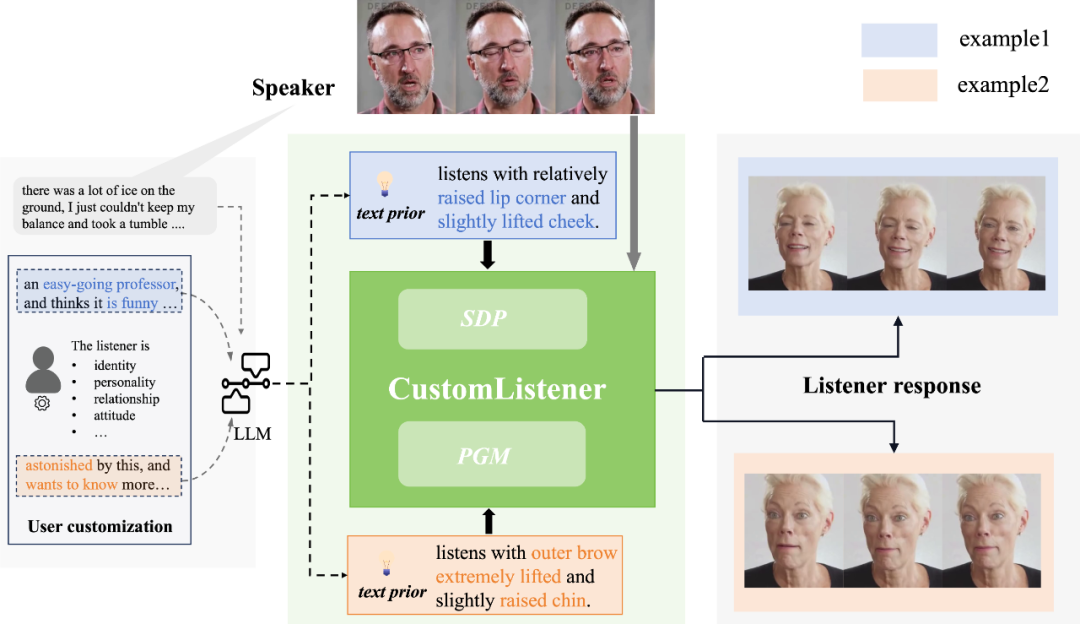
论文简介:近年来,数字人生成技术逐渐发展并应用于虚拟对话交互场景中,通过模拟真实Speaker和Listener的表情和肢体语言,来创造生动和更具沉浸感的交流场景。然而,现有Listener生成中,用户只能通过简单情绪标签去控制Listener属性,可控力有限。本文中,我们提出CustomListener,用户可以使用任意自由文本自定义想要的Listener属性(身份、性格、行为习惯、社会关系等),模型结合自定义的文本属性以及交流场景中Speaker的讲话内容/语音/动作,实时生成合理且逼真的Listener反应。
具体而言,我们首先基于ChatGPT,依据用户定义文本和Speaker讲话内容,得到指导Listener动作的静态文本先验,从语义层面分析刻画来得到Listener的行为基调。该静态先验只提供了窗口时间内Listener的静态基调动作,然而对话中,Listener的行为需要配合Speaker的实时状态,来确定静态基调动作的完成节奏和幅度信息。为实现这种Speaker-Listener行为的协调性,SDP模块根据Speaker语音-静态文本先验的响应式交互来获得基调动作的完成节奏引导,根据Speaker动作对交互结果进行精炼来获得基调动作的幅度引导,由此将静态文本先验转换为包含Listener动作完成节奏和幅度信息的动态肖像Token。为实现长视频生成的片段间连贯性,PGG模块基于片段间动态肖像tocken的相似性生成运动先验,以此保持片段间Listener行为的连贯性和属性的一致性,并基于以运动先验和动态肖像Token为条件的diffusion结构,最终实现听者的可控生成。
05
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation
展示位置:6月21日 17:15-18:45(美西时间) Poster Session 6 No.287 & Exhibit Hall (Arch 4A-E)
论文作者:Qi Yang(UCAS,CASIA),Xing Nie(UCAS,CASIA),Tong Li(Meituan),Pengfei Gao(Meituan),Ying Guo(Meituan),Cheng Zhen(Meituan),Pengfei Yan(Meituan),Shiming Xiang(UCAS,CASIA)
备注:UCAS(School of Artificial Intelligence, University of Chinese Academy of Sciences);CASIA(Institute of Automation, Chinese Academy of Sciences)
论文下载:PDF
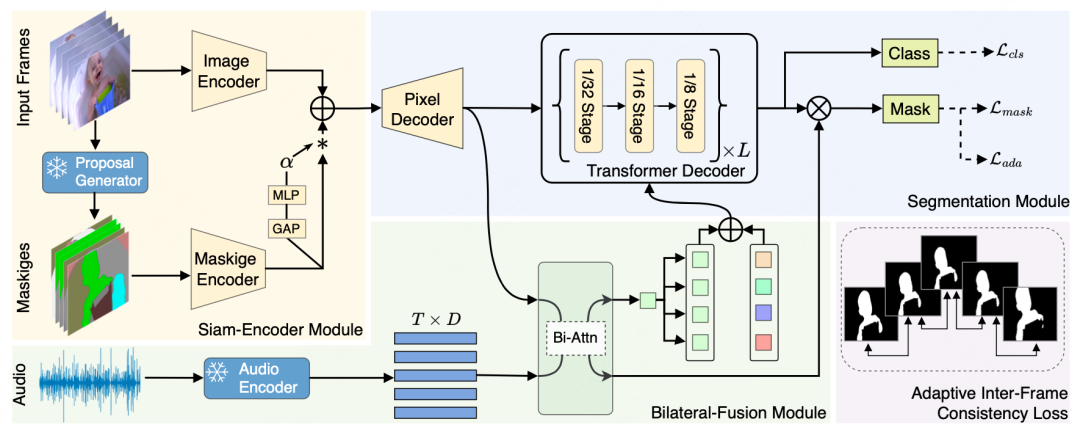
论文简介:人类的视觉注意力常受听觉引导,即我们倾向于专注发声目标。基于此,我们引入了视听分割(AVS)任务,旨在像素级分割视频中的发声目标。该任务需对场景进行音频驱动的像素级理解,极具挑战性。
本论文提出了一种创新的视听Transformer框架,名为COMBO,即COoperation of Multi-order Bilateral relatiOns。该框架首次探讨了视听分割中三种双边纠缠关系:像素纠缠、模态纠缠和时间纠缠。针对像素纠缠,图像和发声目标掩码之间存在像素级关系,图像中的无关背景往往会影响掩码预测的精度,目前大部分方法所依赖的基础分割模型如SAM(Segment Anything Model)系列,在通用分割任务中展示出了很好的鲁棒性和泛化性,但迁移到AVS任务中后,无法达到很好的性能,因为AVS目的是得到所有发声目标的像素级分割,而SAM是在无语音引导条件下的类别级分割,无法直接进行适配。因此我们采用了孪生编码模块,利用先验知识生成更精确的视觉特征。针对模态纠缠,两种模态之间存在内在联系,如图像可以用文字描述,声音可以对应图像中的目标物,已有的方法往往聚焦在音频模态对视觉模态的影响,而忽略了视觉对音频的影响,相较于以上单边融合方法,我们认为两种模态的相互融合能带来更优的效果,因此设计了双边融合模块,来实现视觉特征和听觉信号的双向对齐,该模块使视觉特征更聚焦在发声目标,同时使语音信号更关注视觉目标。针对时间纠缠,在视频序列中,能够根据过去的帧序列结果来估计当前帧,同时也可以根据当前帧结果预测未来帧,基于以上时序间内在关系,我们引入了一种自适应帧间一致性损失算法。综合实验和消融研究表明,COMBO在AVSBench-Object和AVSBench-Semantic数据集上均优于现有的最先进方法。
06
Intelligent Grimm - Open-ended Visual Storytelling via Latent Diffusion Models
展示位置:6月19日 17:15-18:45(美西时间) Poster Session 2 No.135 & Exhibit Hall (Arch 4A-E)
论文作者:Chang Liu* (SJTU,Shanghai Al Laboratory),Haoning Wu*(SJTU),Yujie Zhong(Meituan),Xiaoyun Zhang(SJTU),Yanfeng Wang(SJTU,Shanghai Al Laboratory),Weidi Xie(SJTU,Shanghai Al Laboratory)
备注:SJTU(Shanghai Jiao Tong University)
论文下载:PDF
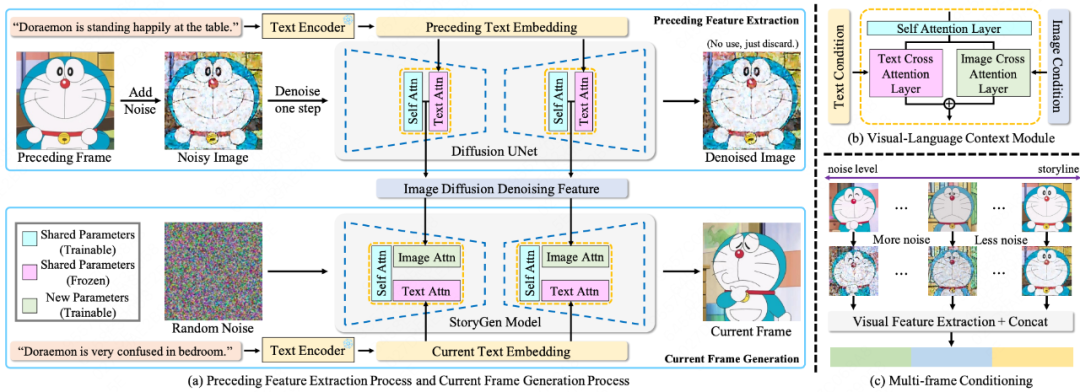
论文简介:生成模型最近在文本到图像生成方面展示了出色的能力,但在生成连贯的图像序列方面仍然存在困难。在本研究中,我们专注于根据给定的故事情节生成连贯图像序列的新颖而具有挑战性的任务,称为开放式视觉叙事。我们的工作有以下三个贡献:
-
为了完成视觉叙事的任务,我们提出了一种基于学习的自回归图像生成模型,称为StoryGen,它具有一个新颖的视觉-语言上下文模块,可以在依据相应的文本提示和之前的图像-字幕对的条件下生成当前帧;
-
为了解决视觉叙事数据的不足,我们通过从在线视频和开源电子书中收集配对的图像-文本序列,建立了处理流水线,构建了一个具有多样化人物、情节和艺术风格的大规模数据集,命名为StorySalon;
-
定量实验证明了我们的StoryGen的优越性,我们展示了StoryGen可以推广到未见过的角色而无需任何优化,并生成具有连贯内容和一致人物的图像序列。
07
InstaGen: Enhancing Object Detection by Training on Synthetic Dataset
展示位置:6月20日 10:30-12:00(美西时间)Poster Session 3 No.432 & Exhibit Hall (Arch 4A-E)
论文作者:Chengjian Feng(Meituan),Yujie Zhong(Meituan),Zequn Jie(Meituan),Weidi Xie(SJTU), Lin Ma(Meituan)
备注:SJTU(Shanghai Jiao Tong University)
论文下载:PDF
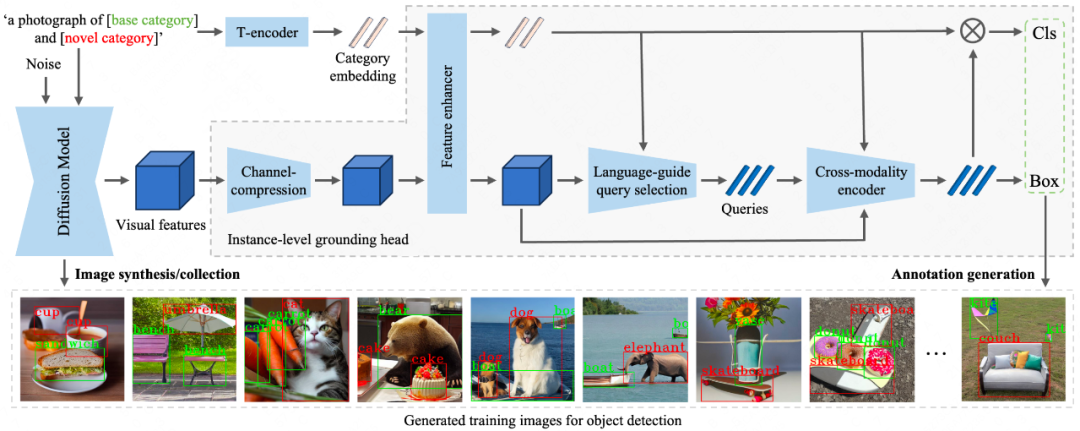
论文简介:近年来,文本到图像的生成模型在生成高质量图像方面取得了显著的成功,这为使用合成图像训练视觉系统提供了可能。现有的文本到图像生成模型通常可以根据某些自由形式的文本提示来生成图像。尽管这些生成的图像看起来很逼真,但无法满足训练复杂系统的需求,因为这些系统通常需要有实例级的注释,例如目标检测需要物体边界框。
在本文中,我们探索了一种创新的数据集合成范式,用于训练目标检测器以提高其性能,例如扩展类别或改进检测能力。具体而言,我们成功地将一个实例级的检测头(Grounding head)集成到一个预训练的生成模型中,以增强其在生成图像中定位物体实例的能力。检测头通过使用来自现成目标检测器的监督,以及一种针对目标检测器未覆盖的类别的新颖自训练方案,将类别名称的文本嵌入与扩散模型的区域视觉特征进行对齐。我们进行了详细的实验,结果表明这个增强版的生成模型,即InstaGen,可以作为一个数据合成器,通过使用其生成的样本来增强目标检测器的性能,无论是在开放词汇(+4.5 AP)还是数据稀缺的情况下(+1.2 ∼ 5.2 AP),都比现有最先进的方法表现出更好的性能。
活动一:论文分享-线上直播
识别图片上的二维码(或点击图片)跳转报名,一起来交流吧~

活动二:CVPR 2024 与美团相约西雅图
美团在CVPR 2024西雅图会场也有丰富的线下活动,欢迎参加CVPR的同行们到大会现场交流。
Booth
展台号:1417
展出时间:6月19日~6月21日(美西时间)
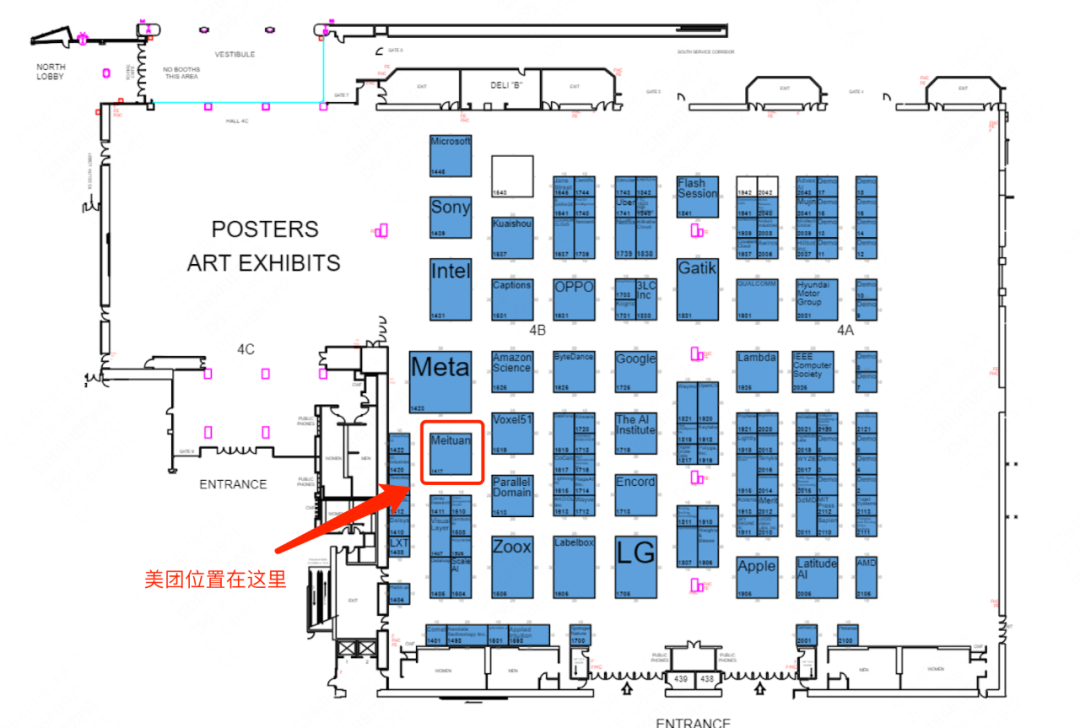
BoothTalk(Booth: 1417)
-
6月19日 15:00-15:30(美西时间)美团自动配送车团队
-
6月20日 15:00-15:30(美西时间)美团视觉智能部团队
Workshop
-
时间地点:6月17日 9:00 –18:00 Summit 442(美西时间)
-
Workshop主题:Foundation Models for Autonomous Systems
美团作为联合发起方和组织方,深度参与本场Workshop的挑战赛Autonomous Grand Challenge。
Workshop
-
时间地点:6月17日 9:00 –12:00 Arch 201(美西时间)
-
Workshop主题:5th Chalearn Face Anti-spoofing Workshop and Challenge
美团荣获Track 1-Unified Physical-Digital Face Attack Detection挑战赛第一名,并受邀发表演讲。
---------- END ----------
美团科研合作
美团科研合作致力于搭建美团技术团队与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕机器人、人工智能、大数据、物联网、无人驾驶、运筹优化等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作。欢迎老师和同学们发送邮件至:meituan.oi@meituan.com。
推荐阅读
















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









