







数据结构学习笔记
c++语言基本语法
模板
1.模板函数
template <typename T>
T Max(T x,T y){
return x>=y?x:y;
}
2.模板类
template <typename T>
class compare{
public:
Compare(T x, T y){item1=x;item2=y;}
T Max();
private:
T item1,item2;
};
template <typename T>
T compare<T>::Max(){
return item1>=item2?item1:item2;
}
使用模板类来定义对象变量:
模板类名<模板参数> 对象名;
异常处理
1.抛出异常
void FuncExcep(int i){
if(异常) throw"this is a exception";
}
2.捕获异常
try{
FuncExcep(0);
}
catch(string *str){
cout<<str<<ensl;//输出异常
}
一、基本概念
1.1数据结构的基本概念
1.1.1数据结构
数据:能输入到计算机中并能被计算机程序识别和处理的符号
数据元素:数据的基本单位,在计算机中通常作为一个整体进行考虑和处理
数据项:构成数据元素的最小单位
数据结构:相互之间存在一定关系的数据元素的集合。分为逻辑结构和存储结构。
-
逻辑结构:数据元素以及数据元素之间的逻辑关系
- 集合
- 线性结构
- 树结构
- 图结构
-
存储结构:数据及其逻辑结构在计算机中的表示。通常有两种存储结构:顺序存储结构和链式存储结构
- 顺序存储结构:用一组连续的存储单元以此存储数据元素,数据元素之间的逻辑关系由元素的存储位置来表示
- 链式存储结构:用一组任意的存储单元来存储元素,数据元素之技安的逻辑关系用指针来表示
1.1.2抽象数据类型ADT
ADT 抽象数据类型名
DataModel
数据元素之间逻辑关系的定义
Operation
操作1
前置条件:
输入:
功能:
输出:
后置条件:
操作2
.
.
.
操作n
.
.
.
endADT
1.2.算法的基本概念
算法:对特定问题求解步骤的一种描述,是指令的有限序列
算法特性:
- 有穷性
- 确定性
- 可行性
好算法特性:
- 正确性
- 健壮性
- 可理解性
- 抽象分级
- 高效性
算法的描述方法:
- 自然语言
- 流程图
- 程序设计语言
- 伪代码
1.3.算法分析
1.3.1算法的时间复杂度
常见时间复杂度:
O(
l
o
g
2
n
{log_2{n}}
log2n)<O(n)<O(n
l
o
g
2
n
{log_2{n}}
log2n)<O(n2)<O(n3)<…<O(2n)<O(n!)
算法运行时间计算:
-
for循环
假设循环体的时间复杂度为O(n)循环m次,则这个循环的时间复杂度为O(nm);
-
嵌套的for循环
由内向外各个循环的复杂度为O(a)、O(b)、O©…则这个嵌套循环时间复杂度为O(abc…)
-
顺序语句
各个语句运行时间求和(或取较大值)
int a=0,b=0;
for(int i=0;i<100;i++)
a++;
for(int i=0;i<50;i++){
for(int j=0;j<100;j++){
b++;
}
}
-
if/else语句
假设时间复杂度最大的路径的时间复杂度为O(n),则if/else语句的时间复杂度为O(n)
1.3.2算法的空间复杂度
练习:设计算法将数组a[n]循环左移k位,并要求时间复杂度O(n),只能用一个元素的辅助空间,输出的参考样例如下所示。
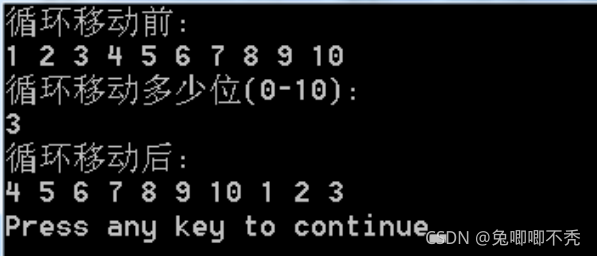
答案:
#include<iostream>
using namespace std;
void reverse(int a[],int start,int end)
{
int i,temp;
for(i=0;i<=(end-start)/2;i++)
{
temp=a[start+i];
a[start+i]=a[end-i];
a[end-i]=temp;
}
}
void RRotate(int a[],int k)
{
int n=10;
reverse(a,0,k-1);
reverse(a,k,n-1);
reverse(a,0,n-1);
}
void main()
{
int i,k,a[10]={1,2,3,4,5,6,7,8,9,10};
cout<<"循环移动前:"<<endl;
for(i=0;i<10;i++)
cout<<a[i]<<" ";
cout<<endl;
cout<<"循环移动多少位(0-10):"<<endl;
cin>>k;
RRotate(a,k);
cout<<"循环移动后:"<<endl;
for(i=0;i<10;i++)
cout<<a[i]<<" ";
cout<<endl;
}
二、线性表
2.1顺序表
线性表的顺序存储结构称为顺序表(sequential list),其基本思想是用一段连续的存储单元依次存储线性表的数据元素
特点:
- 随机存取
2.2链表
2.2.1单链表
双链表
2.2.2循环链表
2.3顺序表与链表的比较
| 顺序表 | 链表 |
|---|---|
| 随机存取 | 顺序读取 |
| 长度固定,难以扩容 | 任意长度 |
| 连续存储 | 不一定连续存储 |
| 删除插入操作需移动大量数据 | 删除插入较方便 |
因此,当需要多次读取某一位置的数据时,用顺序表较高效;当需要进行多次插入、删除操作时,用链表更为高效。当知道数据长度时,用顺序表的空间效率更高;当未知数据长度或数据长度经常发生变化时,用链表的空间效率更高。
线性表练习
2.4块状链表
三、栈和队列
3.1栈
栈是限定仅在表的一端进行插入和删除操作的线性表。
特点:后进先出
用途:
(1)深度优先搜索
(2)表达式求值
3.1.1顺序栈
3.1.2链栈
3.2队列
队列是只允许在一端进行插入操作,在另一端进行删除操作的线性表。
特点:先进先出
用途:宽度优先搜索
3.2.1顺序队列
缺点:随着队列的插入和删除操作,整个队列向数组的高端移,而低端还有空闲空间,形成“假溢出”。
3.2.2循环队列
将存储队列的数组看成是头尾相接的循环结构,即允许队列直接 从数组中下标最大的位置延续到下标最小的位置,可以通过取模操作实现:rear=(rear+1)%QueueSize;
队空条件:rear=front;
队满条件:(rear+1)%QueueSize=front;
3.2.3链队列
3.2.4双端队列
允许在队列的两端进行插入和删除操作,则称为两端队列。














 7130
7130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









