







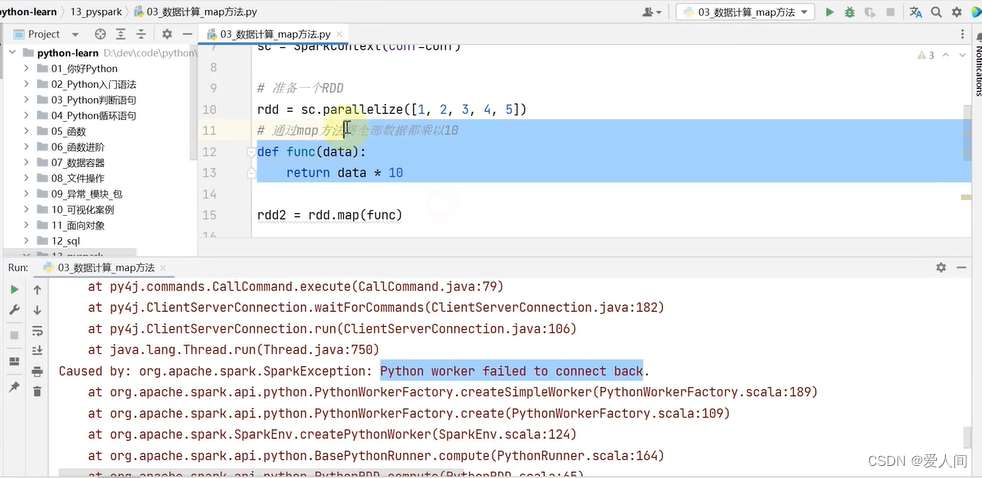
直接运行会报错,需要配置下python环境变量
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="D:/Program Files/Python/Python3.13/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd=sc.parallelize([1,2,3,4,5])
def func(data):
return data*10
rdd2=rdd.map(func)
print(rdd2.collect())
sc.stop()
使用匿名函数:
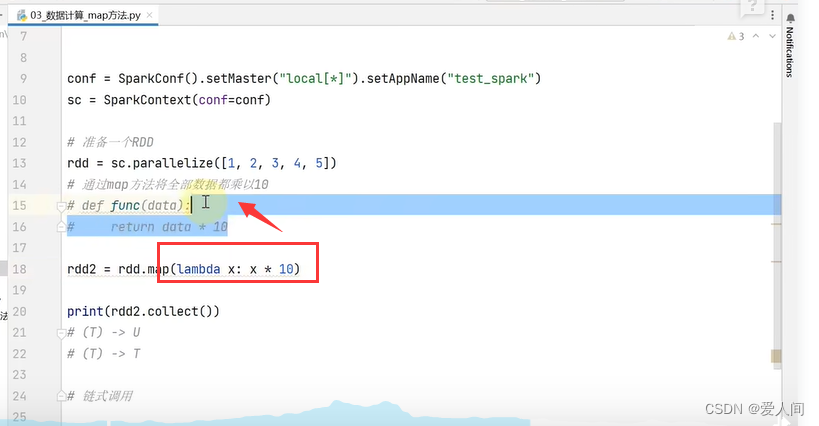
逻辑简单用lamda比较方便


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











