







一、Shuffle机制
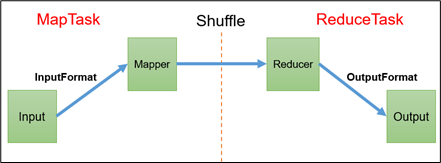
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。

二、Partition分区
1、问题引出
要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
2、默认Partitioner分区

默认分区是根据
key的hashCode对Reduce Tasks个数取模得到的。用户没法控制哪个key存储到哪个分区。
3、自定义Partitioner步骤
(1) 自定义类继承Partitioner, 重写getPartition()方法

(2) 在Job驱动中,设置自定义Paritioner
job.setPartitionerClass(CustomPartitioner.class);
(3)自定义Partition后, 要根据自定义Partitioner的逻辑设置相应数量的ReduceTask
job.setNumReduceTasks(5);
4、分区总结
(1) 如果Reduce Task的数量 > getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
(2) 如果1 < ReduceTask的数量 < getPartition的结果数, 则有一部分分区数据无处安放, 会Exception;
(3) 如果ReduceTask的数量 = 1, 则不管MapTask端输出多少个分区文件,最终结果都交给这一个Reduce Task,最终也就只会产生一个结果文件 par-00000;
(4) 分区号必须从零开始,逐一累加。















 2972
2972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









