







 本文介绍了如何使用Python编写爬虫,从长江雨课堂抓取选择题数据,并将其存储到MySQL数据库中。通过分析网页结构,提取JSON数据,处理cookie,最终实现题目和选项的入库操作。
本文介绍了如何使用Python编写爬虫,从长江雨课堂抓取选择题数据,并将其存储到MySQL数据库中。通过分析网页结构,提取JSON数据,处理cookie,最终实现题目和选项的入库操作。
**最近上网课,老师有些练习题在长江雨课堂布置,为了好复习我用了2小时写了个简单的爬虫,将习题爬取放到了mysql中下面开始讲讲我的思路。
首先这个需要账号登录 ,那就必须需要在爬取的时候带上cookie,
获取的方法很简单,直接登录常见雨课用f12打开开发者工具,随便点击一个数据,查看resquest headers ,并且复制cookie,后面写程序有用。

下面我们开始点开练习题界面,进入之后,打开开发者工具,全局搜素几个题目的字,找到了一个数据包

遮住的是课程id,以及试题的id。
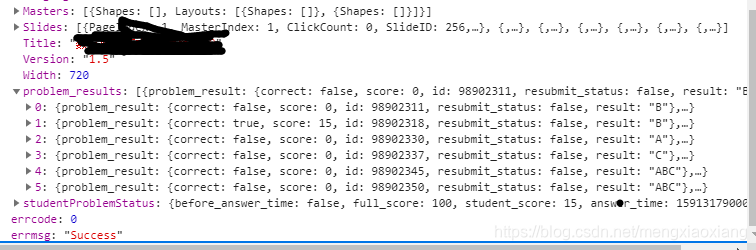
发现数据包是一个json数据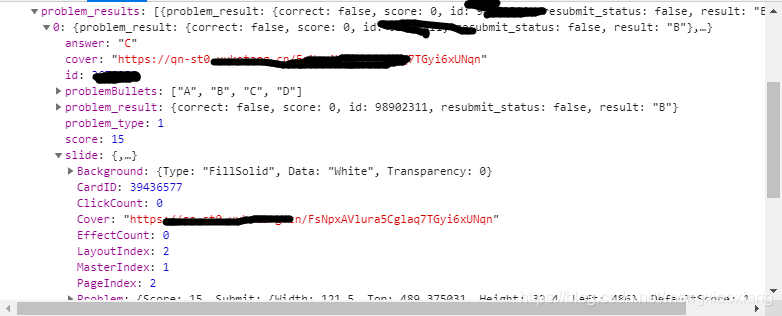
找到底下的problem_result值
然后查看slide的值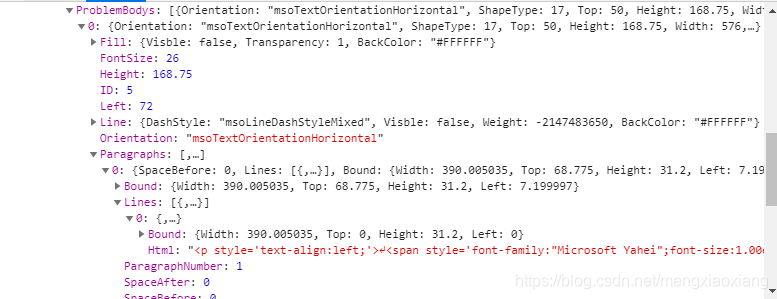
如图查看一直找到一个html标签的值,发现里面就有题目,由此判断这就是我们需要爬取的信息。写爬虫必须在请求头中加入cookie,我们刚才保存到cookie就可以使用(ps:时间长了cookie可能失效,可以按原来的方法获取新值)
这个爬虫的最麻烦的就是json数据吧里面的东西太多,需要一步一步解析然后取出自己想要的值。
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36', 'cookie': '' }
cookie自己写,这个是我们需要请求的url
https://changjiang.yuketang.cn/v2/api/web/cards/detlist/{}?classroom_id={}
括号内写自己的课程id以及练习题的号码
下来就是解析数据
response=requests.get(url,headers=headers).json()
for i in response['data']['problem_results']:#分每个题目解析
try:
bro=i['slide']['ProblemBodys'][0]['Paragraphs'][0]['Lines'][0]['Html']#题目在html里面需要用到xpath来提取文本
#前面需要写from lxml import etree 引入这个方法
question=str(etree.HTML(bro).xpath('//*//span/text()')[0])#提取到题目
# print(question)
# print(i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2064
2064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









