






全球气象站点年平均降水数据(1929-2024)
1853
数据简介
全球气象站点年平均降水数据,该数据为整理NCDC(美国国家气候数据中心,National Climatic Data Center)公布的气象站点数据得出,计算为从1929到最新2024年12月31号的站点降水平均值数据,并合并整理成年度表,其中每日的降水量数据单位为英寸,为便于使用,我们将年度表的单位整理为毫米,方便大家研究使用。
该数据是来源于NCDC(美国国家气候数据中心,National Climatic Data Center)提供的自1929-2024年气象数据,其中包含气象站点温度、湿度、光照等等,感兴趣的朋友也可以去官网上自行了解。该数据中无效值用9999.99表示,如果需要中国范围的站点可以在站点名称里进行筛选,中国的缩写为CH。
数据来源
数据来源于NCDC(美国国家气候数据中心,National Climatic Data Center),由数据皮皮侠团队人工整理,全部内容真实有效。
时间跨度
1929-2024
数据范围
全球两万多气象站点
数据形式
数据格式为Excel形式
数据指标
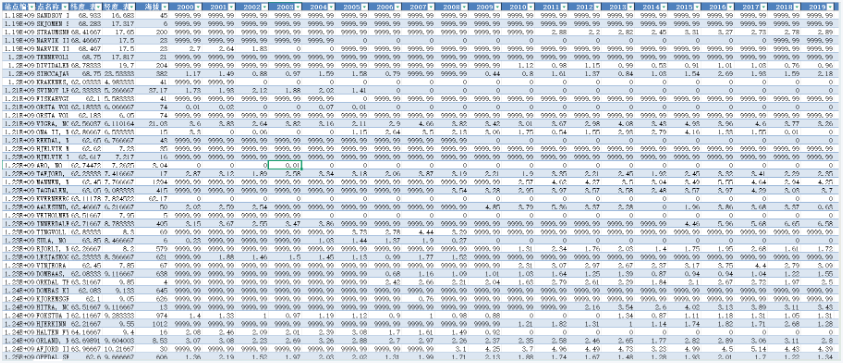
数据展示
声明:本数据由数据皮皮侠团队整理,仅用于学术研究

















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









