






Python语言是由Guido van Rossum大牛在1989年发明,它是当今世界最受欢迎的计算机编程语言之一,也是一门“学了有用、学了能用、学会能久用”的计算生态语言。
为此,CSDN作为国内最大的IT中文社区,特向广大Python爱好者开设了Python学习班,帮助大家在学习的道路上少走弯路,事半功倍。在昨天的女神节,我们继续邀请知名的CSDN博客专家杨秀璋老师,在班级里举行博客专家会客厅活动。
杨秀璋:Web数据挖掘/软件工程。研究生阶段从事Web数据挖掘和知识图谱相关的研究,结合Python写了一些Selenium爬虫和数据挖掘的算法。从2013年开始在CSDN写博客,每个月都坚持分享些技术,已完成8个专栏。博客地址:http://blog.csdn.net/Eastmount
下面是杨老师在Python学习班的分享:
非常开心能够认识大家,和大家简单交流些Python相关的基础知识。群里面也有很多大神,我主要结合自己做过的东西,讲解一些Python知识,这节课主要是Python爬虫相关的知识,通过一些实际的简单应用,提升同学们学习Python的兴趣。
因为是微信授课,讲得不好的地方,还请大家海涵~
前面我讲过:学习Python最重要的地方是通过Python做一些自己喜欢的事情,来提升自己的兴趣,从而学好它,包括Python爬虫、数据分析、自动化测试、网站、GUI游戏等。
网络爬虫
网络爬虫(Web Spider),又被称为网页蜘蛛、网络机器人,它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。

常见的Python爬虫工具包括:正则表达式、XPath技术、Selenium、BeautifulSoup、Scrapy等。这节课讲课内容主要是Python安装Selenium并自动爬取相关信息。
Selenium
Selenium也是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。通常用于自动化测试,这里我们是用来作为简单的爬虫。
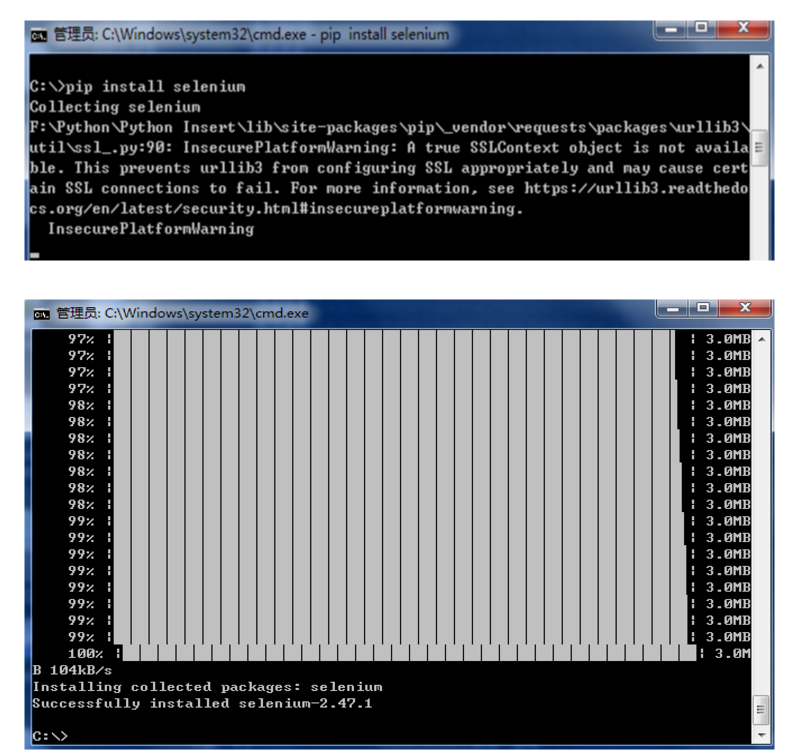
第一步:安装selenium
通过cd去到Scripts路径下,调用pip install selenium进行安装
注意:调用pip或easy_install安装第三方库函数,是常见的Python安装用法。
第二步:安装Firefox浏览器
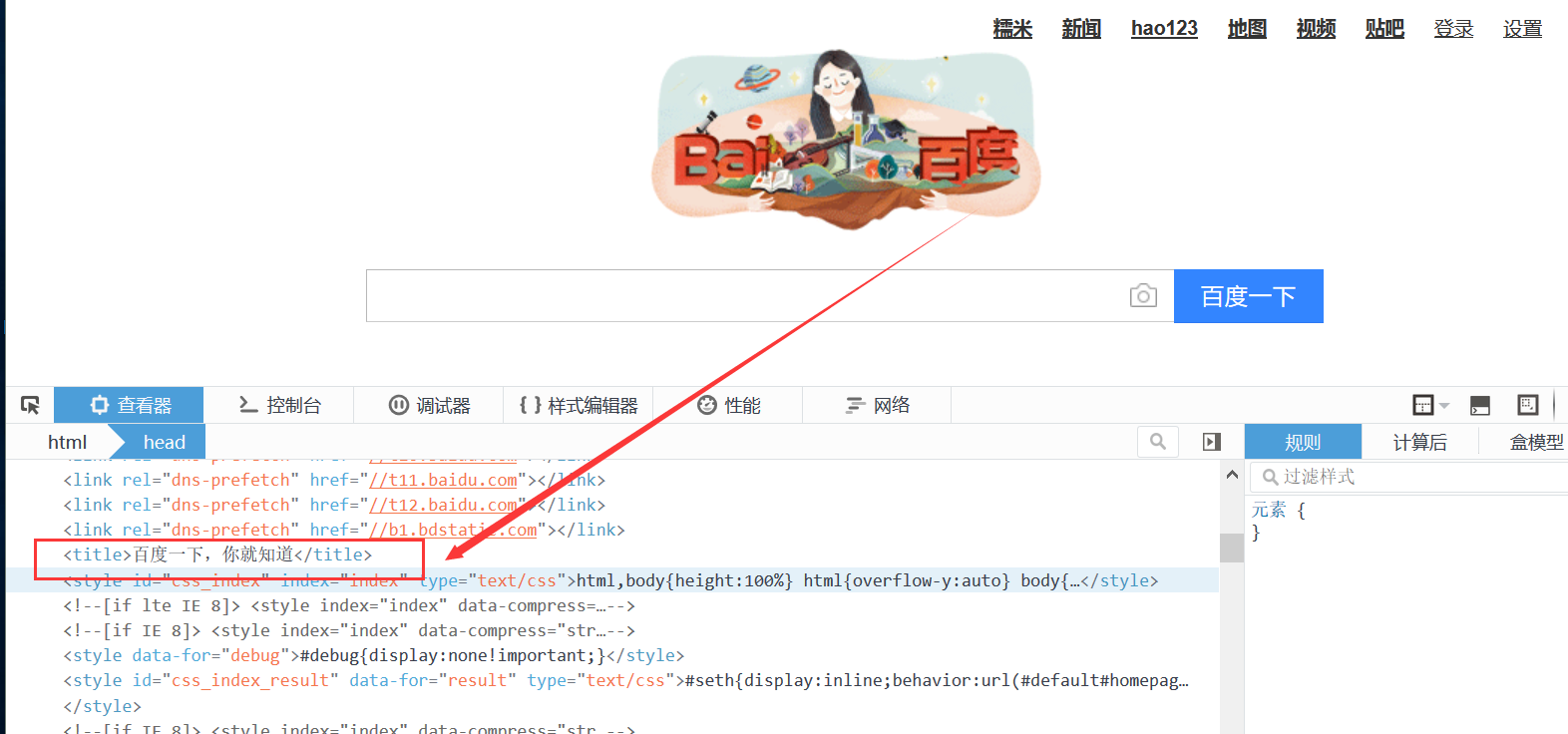
第三步:简单访问百度页面
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
data = driver.title
print data
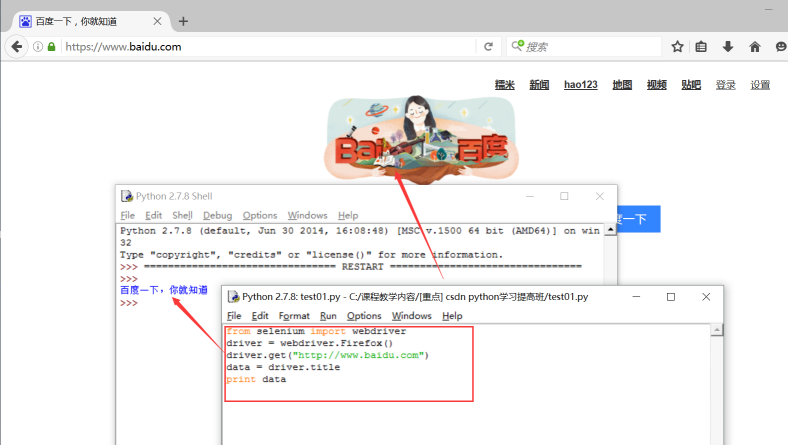
其中:webdriver.Firefox()是调用Firefox浏览器,这句话会自动弹出火狐浏览器
driver.get(url)是调用浏览器后访问某个url页面
driver中包含一些属性和方法,这里只是输出标题“百度一下,你就知道”
注意:Python导入包的常见语法就是 from xxxx import xxxx
例如:from sklearn.cluster import Kmeans
从机器学习sklearn包的聚类cluster中导入Kmeans聚类的方法
其中Kmeans在cluster中,当然还有其他聚类的方法
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
data = driver.title
print data
driver.save_screenshot('baidu.png')
添加一句代码,复制下载整个页面到本地。
Selenium常见元素定位方法和操作
注意driver下包括很多方法和属性,常见的包括:
这里有各种策略用于定位网页中的元素(locate elements),你可以选择最适合的方案,Selenium提供了一下方法来定义一个页面中的元素:
•find_element_by_id
•find_element_by_name
•find_element_by_xpath
•find_element_by_link_text
•find_element_by_partial_link_text
•find_element_by_tag_name
•find_element_by_class_name
•find_element_by_css_selector
下面是查找多个元素(这些方法将返回一个列表):
•find_elements_by_name
•find_elements_by_xpath
•find_elements_by_link_text
•find_elements_by_partial_link_text
•find_elements_by_tag_name
•find_elements_by_class_name
•find_elements_by_css_selector
除了上面给出的公共方法,这里也有两个在页面对象定位器有用的私有方法。这两个私有方法是find_element和find_elements。
例如:

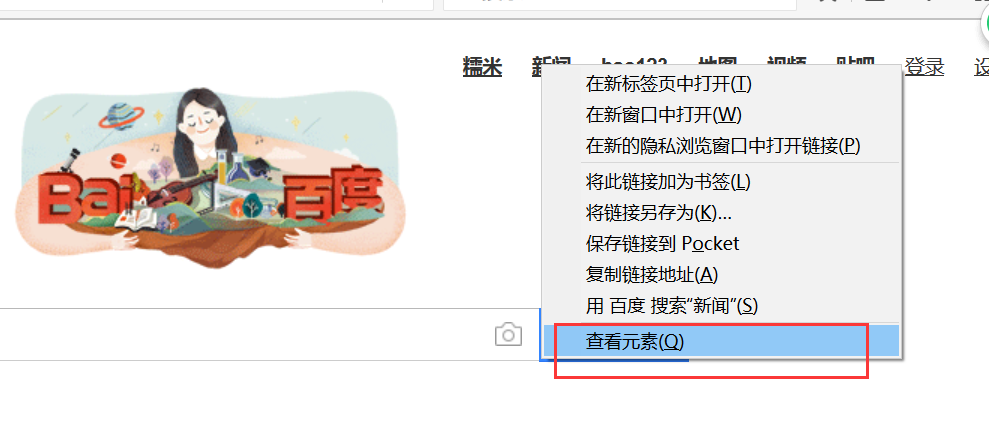
对应的文字:
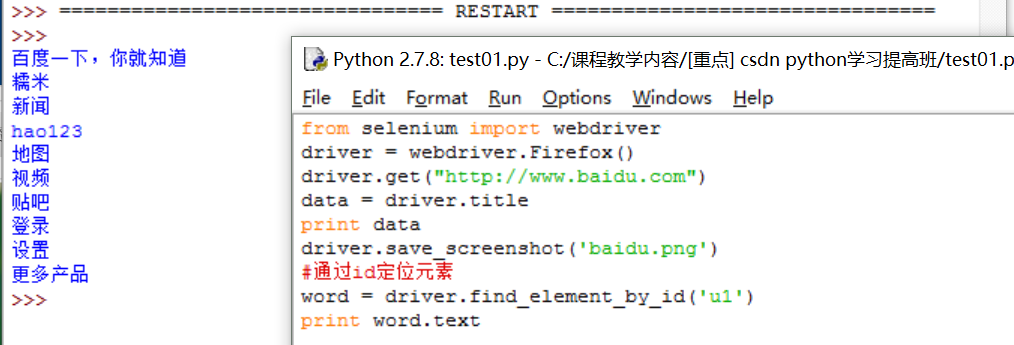
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
data = driver.title
print data
driver.save_screenshot('baidu.png')
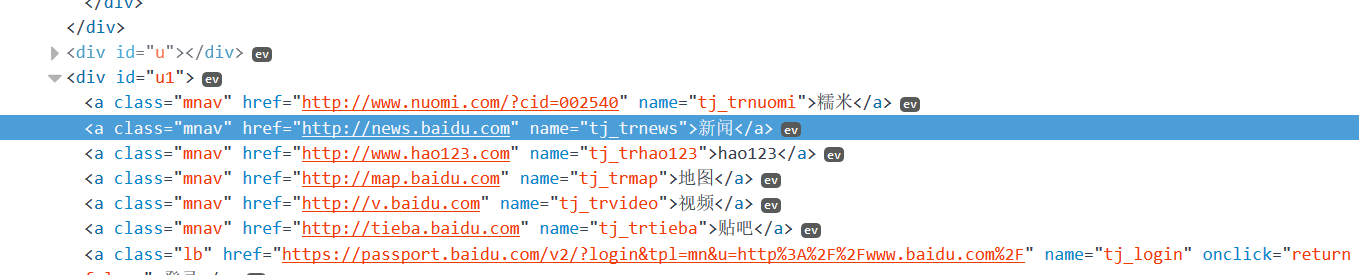
通过id定位元素
word = driver.find_element_by_id('u1')
print word.text
重点方法是分析网站DOM树结构:
这里需要注意,网页通常都是采用树形的形式进行存储的,比如:
我们需要学会右键审查元素,分析对应的界面:
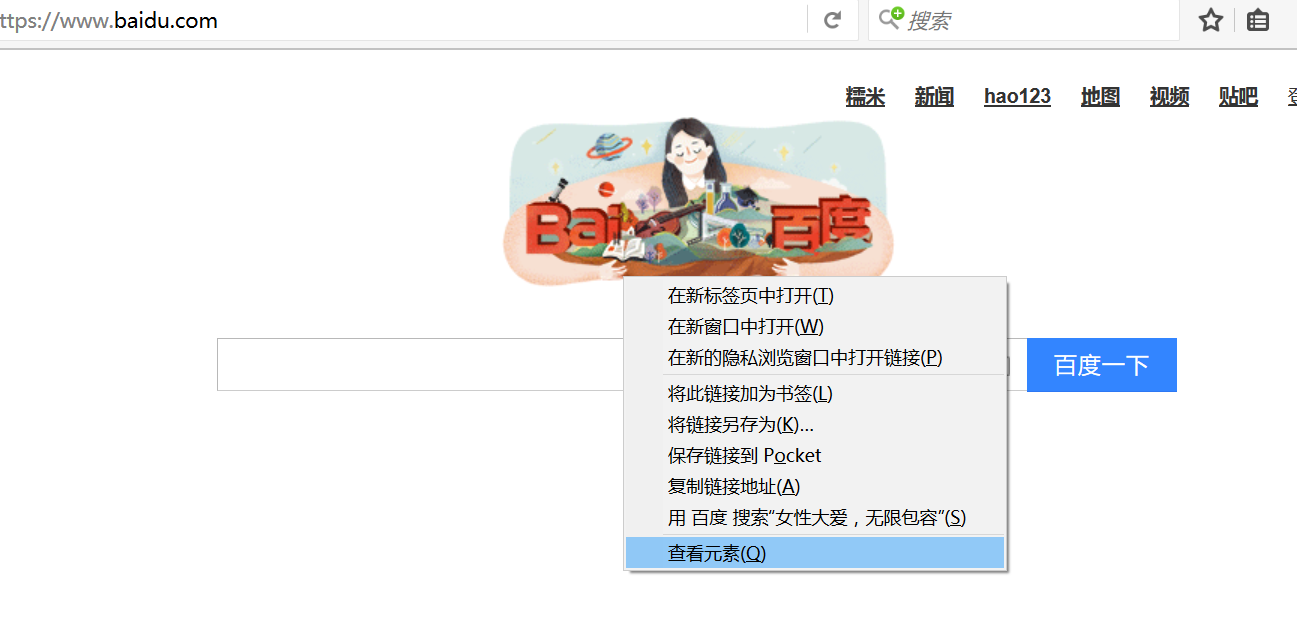
这个比较基础的知识,给大家普及下
题目:
- 学会pip方法安装各种库函数,Anaconda调用pip操作。
- 学会Python调用Selenium方法简单爬取百度首页。
- 学会Python调用Selenium定位元素,尝试写个需要翻页的爬虫。
- 学会Python调用Selenium自动登录操作。
- (难) 如果实现防止403 Forbidden错误,ip地址转换,模拟登陆等操作。
同时,对讲课内容存在什么意见,也欢迎大家反馈给我,相互学习,相互提高。
希望这门课程对你们有所帮助,感觉讲得不是很好,希望给多知识来和我交流,谢谢~
感谢CSDN这个平台。
Python爬虫
-
- urllib等包简单下载数据
-
- Selenium爬虫=》自动化工具
-
- Beautifulsoup爬虫
-
- Dom树分析
-
- 分布式爬虫,线程
Python数据分析
- 常见Python数据分析包
- Sklearn、numpy、scipy、Matplotlib
- 数据挖掘基础知识
基本流程
- Python网站设计
- Odoo ERP框架
课堂花絮
欢迎希望学习Python语言,热爱交流技术的同学加入我们的CSDN Python学习班。入群请扫下方群二维码。
目前群已满,请扫描下面的小助手账号,申请入群
















 3142
3142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









