







机器学习笔记三(5课)
一.生成式学习算法与判别式学习算法
1.判别式学习算法
直接对P(y|x)建模,得到参数模型,然后用最大似然法求解得到具体的参数。
2.生成式学习算法
对p(x|y),p(y)进行建模,得到参数模型,然后利用p(x,y)写出似然表达式,再用最大似然求得参数。最后利用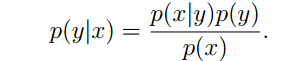
这两种学习算法的最终目的都是求解出p(y|x)的合理表达。
二.高斯判别分析算法
1.数学模型
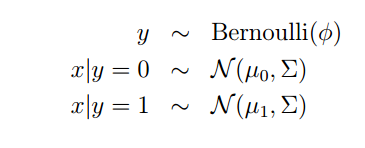
x是连续的随机变量,y取值0或者1,要解决的问题是二元分类问题。
对p(y)建模为贝努利分布,合情合理;对p(x|y=0),p(x|y=1)建模为均值不同而方差相同的高斯分布,这个的合理性取决于实际情况。
建立好参数模型之后,接下来就是列出最大似然表达式,然后求解各个参数的似然解。
最后的结果是:
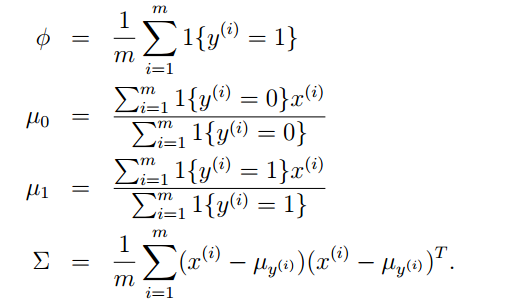
注:此处是根据p(x,y)来列似然表达式,在求解过程中需要利用实数a=a的转置这样的数学技巧来化简表达式,最后求出结果。
2.GDA与logistic回归
GDA是对p(x|y),p(y)建模然后求得p(y|x),而logistic回归是直接对p(y|x)进行建模。
GDA最后推导出的p(y|x)也是符合sigmoid函数的形式,相比于logistic回归,GDA更加充分利用了特征的分布属性,当p(x|y)近似服从高斯分布的时候会有很好的性能。但是当p(x|y)不服从高斯分布的时候,GDA的性能就比不上logistic回归了。
三.朴素贝叶斯法
1.数学模型
相比于GDA,朴素贝叶斯法不同的地方在于对p(x|y)的建模。
GDA中,x是连续变量,直接对其建模为多维高斯分布。
朴素贝叶斯中,x是多维离散变量,假定其各个元素之间在给定y时候相互独立,然后用一个参量表示概率。
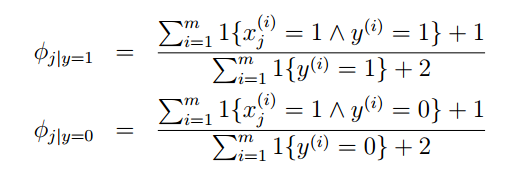
之后的求解参数的方法跟GDA基本上是一样的。
注:对于xi是连续的情况,也可以进行离散化处理。
2.laplace平滑
1)朴素贝叶斯模型不合理的地方:
P(x|y)是根据最大似然求解得到的,可能会出现为0的情况。
2)解决措施
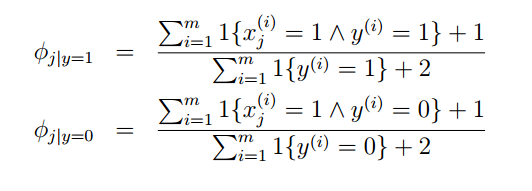
3)分析
采用极大似然法求得的概率估计的直观解释就是正(负)样本中某个元素为1的总数目除以正(负)样本的数目。如果我有5个负样本,在这5个负样本中xj有三个出现了1,那么对p(xj|y=0)的估计就是3/5。极大似然法是用频率估计概率,如果样本数目不够大,那么就会出现较大的误差。比方说即使如果5个负样本中没有出现xj,那么我们也不能估计p(xj|y=0)为0,这显然是不合理的。在这种情况下,我们对其的估计是1/l。这里的l是xj可能的取值的数目,这个概率估计的直观解释是认为xj是均匀取值的,xj有l种取值可能,所以每种取值的概率就是1/l。















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









