









前言:去年曾经参加过天猫移动推荐比赛。但是当时报名之后实验室安排了其他的新任务,导致这个比赛只是在最后几天粗略的做了一下,然后也只提交了一次结果。没能好好地做这个比赛也是我的一个遗憾。现在回过头来再尝试去做这个比赛,就当练练手了。
一.基本思路
题目的训练数据包含了抽样出来的一定量用户在一个月时间(11.18~12.18)之内的移动端行为数据(D),评分数据是这些用户在这个一个月之后的一天(12.19)对商品子集(P)的购买数据。参赛者要使用训练数据建立推荐模型,并输出用户在接下来一天对商品子集购买行为的预测结果。
拿到题目,首先是读取数据和初步观察数据是否有缺失值等等。我还是使用Pandas库来读取数据,但是在读取数据的时候遇到了memory error的错误。

上网查了一些资料,出现这个错误的原因是我的python是32位的,能访问的内存有限,而训练数据又比较大。所以不得已重装了64位python,然后又装了一片那一大堆的库
先读取部分数据,把重心放在后续的数据处理上。
首先是做数据预处理,观察数据的缺失值情况:
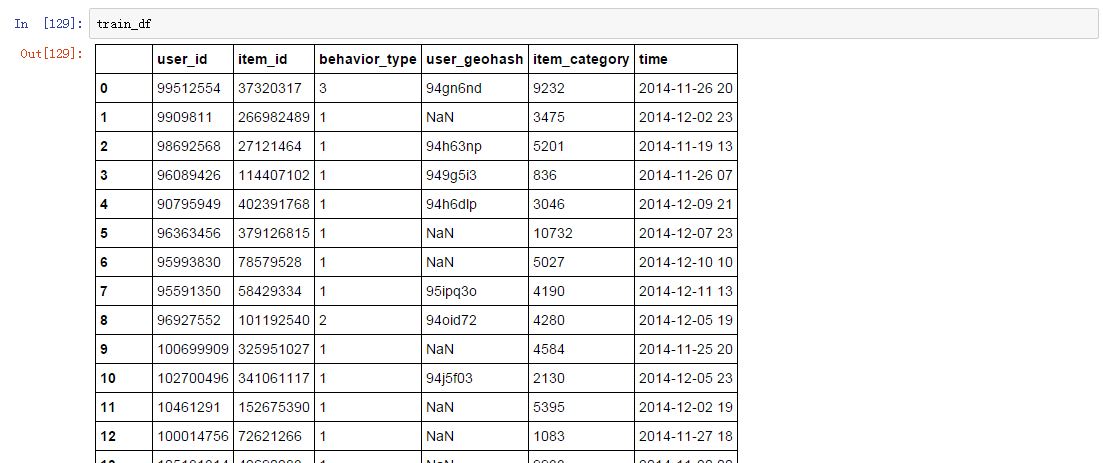
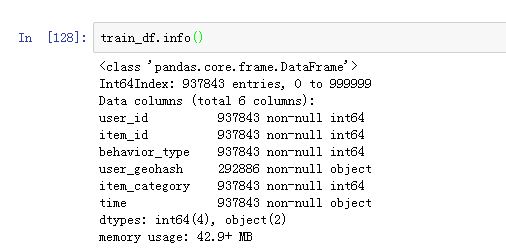
可知公布的数据应该是经过阿里官方清洗的,除了地理位置那一栏之外并不存在缺失数据的情况。而且主要的数据也不需要再转换成数值型数据的。这样一来,接下来就可以进入特征工程阶段。
训练集是11.18-12.16 用户与商品的交互记录,训练集的标签是12.17用户有木有购买相应的商品。我的方案是先针对有交互记录的数据进行处理。
正样本:12.17当天有购买,而且17号之前有互动记录的用户-商品对
负样本:12.17当天没有购买,而且17号之前有互动记录的用户-商品对
我习惯于先制作几个基本的特征,预留好接口。先把整个特征提取和模型训练的过程给跑通了,之后再去往里面加新的特征。所以初步设计了一些很简单的特征:
用户特征:点击(收藏或者加入购物车)转换成购买的比例
商品特征:点击(收藏或者加入购物车)转换成购买的比例
用户-商品对特征:测试日期前几天点击,收藏,加入购物车,购买的次数
由于对pandas的使用还不怎么熟练,花了一些时间才完成这些特征提取工作,当前的程序如下:
import numpy as np
import pandas as pd
import random as rd
import re
from sklearn import tree
from sklearn import preprocessing
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
def sp_count(df,num):
return sum(df['behavior_type']==num)
def load_off_data():
global train_df,label_df,item_df,user_feature_dic,item_feature_dic,ui_feature_dic,label_dic
df = pd.read_csv('tianchi_mobile_recommend_train_user.csv')
user_feature_dic={};item_feature_dic={};ui_feature_dic={};label_dic={}
train_df = df[(df['time'].values>='2014-11-18 00') & (df['time'].values<'2014-12-17 00')]
label_df = df[(df['time'].values>='2014-12-17 00') & (df['time'].values<'2014-12-18 00')]
item_df = pd.read_csv('tianchi_mobile_recommend_train_item.csv')
def load_on_data():
global train_df,label_df,item_df,user_feature_dic,item_feature_dic,ui_feature_dic,label_dic
df = pd.read_csv('tianchi_mobile_recommend_train_user.csv')
user_feature_dic={};item_feature_dic={};ui_feature_dic={};label_dic={}
train_df = df[(df['time'].values>='2014-11-18 00') & (df['time'].values<'2014-12-18 00')]
label_df = df[(df['time'].values>='2014-12-18 00') & (df['time'].values<'2014-12-19 00')]
item_df = pd.read_csv('tianchi_mobile_recommend_train_item.csv')
def gen_user_item_fea():
global train_df,user_feature_dic,item_feature_dic,ui_feature_dic
dataMat = train_df.values
for data in dataMat:
user_id=data[0]
item_id=data[1]
behavior=data[2]
date=data[5]
tmp_list=[0,0,0,0]
tmp_list[behavior-1]+=1
item_feature_dic[item_id]=np.array(item_feature_dic.get(item_id,[0,0,0,0]))+np.array(tmp_list)
user_feature_dic[user_id]=np.array(user_feature_dic.get(user_id,[0,0,0,0]))+np.array(tmp_list)
key=tuple([user_id,item_id])
if(date>"2014-12-13 00"):
ui_feature_dic[key]=np.array(ui_feature_dic.get(key,[0,0,0,0]))+np.array(tmp_list)
for item in item_feature_dic.keys():
tmp_value = item_feature_dic[item]
for k in range(3):
if(tmp_value[k]==0):
tmp_value[k]=10000
item_feature_dic[item]=[float(tmp_value[3])/(tmp_value[0]),float(tmp_value[3])/(tmp_value[1]),float(tmp_value[3])/(tmp_value[2]),tmp_value[3]]
for user in user_feature_dic.keys():
tmp_value = user_feature_dic[user]
for k in range(3):
if(tmp_value[k]==0):
tmp_value[k]=10000
user_feature_dic[user]=[float(tmp_value[3])/(tmp_value[0]),float(tmp_value[3])/(tmp_value[1]),float(tmp_value[3])/(tmp_value[2]),tmp_value[3]]
def gen_train_label():
global train_df,label_df,label_dic
tmp_df=train_df[['user_id','item_id']]
label_df=pd.merge(label_df,tmp_df,on=['user_id','item_id'])
label_array=label_df[label_df['behavior_type']==4][['user_id','item_id']].values
for key in label_array:
tmp_list=[key[0],key[1]]
label_dic[tuple(tmp_list)]=1
neg_array=tmp_df.values
pos_len=len(label_dic);i=0;k=0
while i<len(neg_array):
key=neg_array[i]
tmp_list=[key[0],key[1]]
if(label_dic.get(tuple(tmp_list),0)!=1):
label_dic[tuple(tmp_list)]=0+label_dic.get(tuple(tmp_list),0)
k=k+1
i=i+1
if(k>pos_len*50):
break
def feature_extraction():
global train_df,user_feature_dic,item_feature_dic,ui_feature_dic
feature=[];label=[]
for key in label_dic.keys():
user = key[0];item=key[1]
curr_fea=[]
user_fea = user_feature_dic.get(user,[0,0,0,0])
#curr_fea.extend(user_fea)
item_fea=item_feature_dic.get(item,[0,0,0,0])
#curr_fea.extend(item_fea)
curr_fea.extend(ui_feature_dic.get(key,[0,0,0,0]))
feature.append(curr_fea)
label.append(label_dic[key])
return feature,label
def off_model_building(feature,label):
train_feature,test_feature,train_label,test_label= cross_validation.train_test_split(feature, label, test_size=0.3, random_state=0)
clf = RandomForestClassifier(random_state=1,n_estimators=150,min_samples_split=4,min_samples_leaf=2)
clf = clf.fit(train_feature, train_label)
predict_label=clf.predict(test_feature)
res=predict_label ^ test_label
accuracy = 1-float(sum(res))/len(test_label)
print "accuracy rate is: %f" % accuracy
return clf
def my_test(clf):
global train_df,label_df,item_df,user_feature_dic,item_feature_dic,ui_feature_dic,label_dic
test_label_dic={}
label_df = pd.merge(label_df,item_df,on='item_id')
label_array=label_df[label_df['behavior_type']==4][['user_id','item_id']].values
for key in label_array:
tmp_list=[key[0],key[1]]
test_label_dic[tuple(tmp_list)]=1
test_df = pd.merge(train_df,item_df,on='item_id')
tmp_df = test_df.groupby(['user_id','item_id']).apply(sp_count,4)
candidate_data = test_df[['user_id','item_id']].values
pre=0;ref=len(test_label_dic);pri_and_ref =0
feature=[]
for array in tmp_df.index:
user = array[0];item=array[1]
key=tuple([user,item])
curr_fea=[]
user_fea = user_feature_dic.get(user,[0,0,0,0])
#curr_fea.extend(user_fea)
item_fea=item_feature_dic.get(item,[0,0,0,0])
#curr_fea.extend(item_fea)
curr_fea.extend(ui_feature_dic.get(key,[0,0,0,0]))
feature.append(curr_fea)
predict_mat = clf.predict(feature)
print len(predict_mat)
for i in range(len(predict_mat)):
array = tmp_df.index[i]
user = array[0];item=array[1]
key=tuple([user,item])
predict_label=predict_mat[i]
test_label = test_label_dic.get(key,0)
if(predict_label==1):
pre+=1
if(test_label==1):
pri_and_ref +=1
acc = float(pri_and_ref)/pre
recall = float(pri_and_ref)/ref
F = 2*acc*recall/(acc+recall)
print acc,recall,F
def model_build():
load_off_data()
gen_user_item_fea()
gen_train_label()
feature,label=feature_extraction()
model = off_model_building(feature,label)
return model
def model_test(model):
load_on_data()
gen_user_item_fea()
my_test(model)
我的做法是利用pandas处理数据,生成特征,然后将特征存在user/item/ui字典中。最后根据字典生成特征向量和label,再训练模型。采用这种方式对12.18号的购买记录进行预测,最后得到的结果F1值只有0.7% 。而如果只用ui的特征,那么F1值可以达到2.2%。初步的框架算是搭建起来 了,后续会进行完善。















 3779
3779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









