






 本文档详细介绍了如何获取和处理LipReadingSentences2(LRS2)数据集,包括从官网申请数据、文件整合与解压,以及使用Python脚本进行视频和音频的预处理步骤。预处理过程涉及面部检测和音频转换,为后续的唇语识别模型训练做好准备。
本文档详细介绍了如何获取和处理LipReadingSentences2(LRS2)数据集,包括从官网申请数据、文件整合与解压,以及使用Python脚本进行视频和音频的预处理步骤。预处理过程涉及面部检测和音频转换,为后续的唇语识别模型训练做好准备。

一、数据集获取
LRS2数据集官网:Lip Reading Sentences 2 (LRS2) dataset
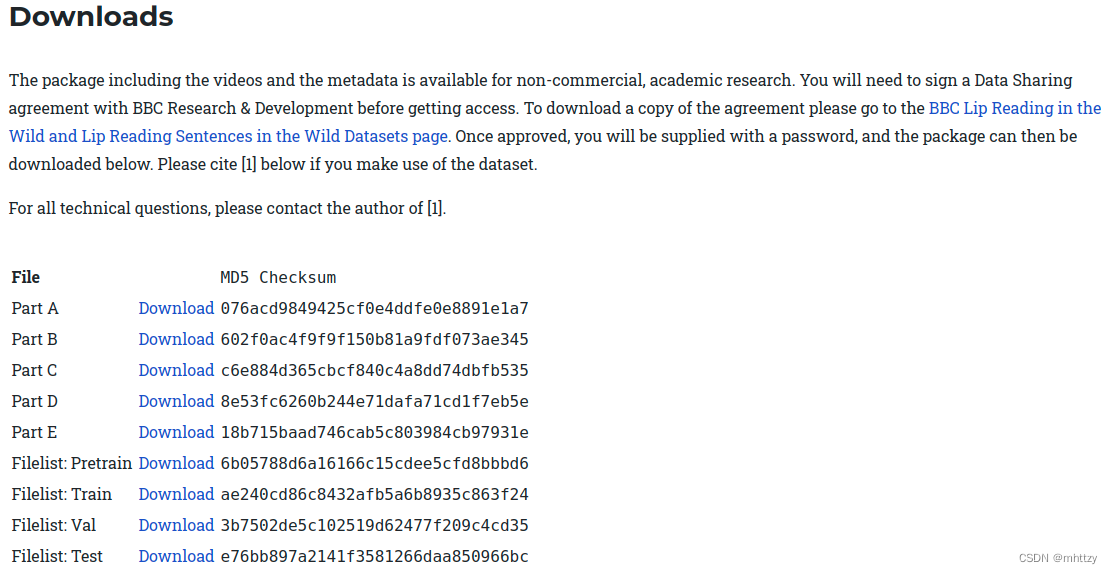
获取方式:
- 根据网站https://www.bbc.co.uk/rd/projects/lip-reading-datasets提示,获取word版数据集申请文件,在文件最后签署使用协议,使用邮箱发送到该网站指定邮箱,等待一两天即可收到带有用户名和密码的邮件。
- 点击上图中“Download”链接,使用用户名密码登陆,即可下载数据集。共计50GB左右,下载所需时间较长。
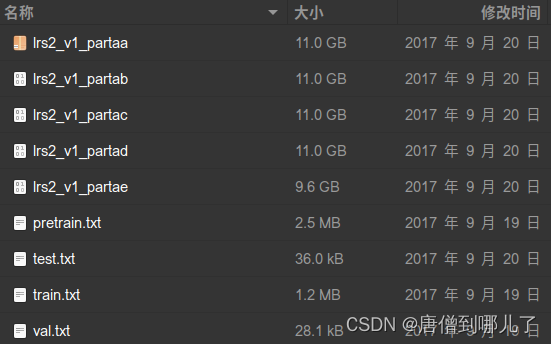
- 下载后的文件名称及大小如下图所示:
二、数据集处理
1、文件处理
(1)将分段的压缩包整合成一个tar文件,bash命令如下
cat lrs2_v1_parta* > lrs2_v1.tar(2)解压tar文件
tar -xvf lrs2_v1.tar2、解析数据集
代码来源:https://github.com/Rudrabha/Wav2Lip/blob/master/preprocess.py
import sys
if sys.version_info[0] < 3 and sys.version_info[1] < 2:
raise Exception("Must be using >= Python 3.2")
from os import listdir, path
if not path.isfile('face_detection/detection/sfd/s3fd.pth'):
raise FileNotFoundError('Save the s3fd model to face_detection/detection/sfd/s3fd.pth \
before running this script!')
import multiprocessing as mp
from concurrent.futures import ThreadPoolExecutor, as_completed
import numpy as np
import argparse, os, cv2, traceback, subprocess
from tqdm import tqdm
from glob import glob
import audio
from hparams import hparams as hp
import face_detection
parser = argparse.ArgumentParser()
parser.add_argument('--ngpu', help='Number of GPUs across which to run in parallel', default=1, type=int)
parser.add_argument('--batch_size', help='Single GPU Face detection batch size', default=32, type=int)
parser.add_argument("--data_root", help="Root folder of the LRS2 dataset", required=True)
parser.add_argument("--preprocessed_root", help="Root folder of the preprocessed dataset", required=True)
args = parser.parse_args()
fa = [face_detection.FaceAlignment(face_detection.LandmarksType._2D, flip_input=False,
device='cuda:{}'.format(id)) for id in range(args.ngpu)]
template = 'ffmpeg -loglevel panic -y -i {} -strict -2 {}'
# template2 = 'ffmpeg -hide_banner -loglevel panic -threads 1 -y -i {} -async 1 -ac 1 -vn -acodec pcm_s16le -ar 16000 {}'
def process_video_file(vfile, args, gpu_id):
video_stream = cv2.VideoCapture(vfile)
frames = []
while 1:
still_reading, frame = video_stream.read()
if not still_reading:
video_stream.release()
break
frames.append(frame)
vidname = os.path.basename(vfile).split('.')[0]
dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, dirname, vidname)
os.makedirs(fulldir, exist_ok=True)
batches = [frames[i:i + args.batch_size] for i in range(0, len(frames), args.batch_size)]
i = -1
for fb in batches:
preds = fa[gpu_id].get_detections_for_batch(np.asarray(fb))
for j, f in enumerate(preds):
i += 1
if f is None:
continue
x1, y1, x2, y2 = f
cv2.imwrite(path.join(fulldir, '{}.jpg'.format(i)), fb[j][y1:y2, x1:x2])
def process_audio_file(vfile, args):
vidname = os.path.basename(vfile).split('.')[0]
dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, dirname, vidname)
os.makedirs(fulldir, exist_ok=True)
wavpath = path.join(fulldir, 'audio.wav')
command = template.format(vfile, wavpath)
subprocess.call(command, shell=True)
def mp_handler(job):
vfile, args, gpu_id = job
try:
process_video_file(vfile, args, gpu_id)
except KeyboardInterrupt:
exit(0)
except:
traceback.print_exc()
def main(args):
print('Started processing for {} with {} GPUs'.format(args.data_root, args.ngpu))
filelist = glob(path.join(args.data_root, '*/*.mp4'))
jobs = [(vfile, args, i%args.ngpu) for i, vfile in enumerate(filelist)]
p = ThreadPoolExecutor(args.ngpu)
futures = [p.submit(mp_handler, j) for j in jobs]
_ = [r.result() for r in tqdm(as_completed(futures), total=len(futures))]
print('Dumping audios...')
for vfile in tqdm(filelist):
try:
process_audio_file(vfile, args)
except KeyboardInterrupt:
exit(0)
except:
traceback.print_exc()
continue
if __name__ == '__main__':
main(args)
















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









