







Manacher算法是专门用来处理回文的一种算法,其主要的作用是找出一个字符串里面最长的一个回文。
要用到这个算法,首先要做的就是改变原来的字符串,就是在原有的字符串中,每两个字母之间都插入一个字符串里面没有的符号。比如:如果这个字符串是由26位字母组成的,那么就在第一个字母前和最后一个字母的后面以及每两个中间都插入一个#。
举个栗子:s[]=”aaaaa”,那么这个字符串就改成:s[]=”#a#a#a#a#a#”
这种做法有个什么作用呢?可以这样想,我们平时判断这个字符串是不是回文的时候,我们首先要判断这个字符串的长度到底是奇数还是偶数,但是,如果你将字符串整理成这样,那么,这个字符串里面的每个回文的长度就都是奇数了。这种做法是不是很神奇?嗯,至少我是觉得很神奇的,所以我觉得这种算法好好玩啊。
在把原来的字符串变化之后,我们就要求一个辅助数组了,让我们命名为f[],这个数组表示的意思是:f[i]表示的是,以第 i 个字符为中心的回文串向左或向右延伸的长度,所以 f[i]-1 就是原字符串的,以第 i 个字符为中心的回文串的长度。因为改变之后的字符串的长度是原字符串的两倍。
举个栗子:
s[]="abbabcba"
p[]="# a # b # b # a # b # c # b # a #"
f[]="1 2 1 2 5 2 1 4 1 2 1 6 1 2 1 2 1"
//可以看出,f[i]-1就是以s[i]为中心的回文串的长度好了,那么重点来了,这个 f[] 是怎么求的呢?其实就几行代码:
void mana()
{
int id=0;
int mx=0;
for(int i=1;i<l;i++) //以$开头,所以是从1开始扫
{
if(mx>i) f[i]=min(f[id*2-i],mx-i);
else f[i]=1;
while(p[i-f[i]]==p[i+f[i]]) f[i]++; //两边有相同的就加一
if(i+f[i]>mx)
{
id=i;
mx=i+f[i];
}
}
}
//P.S. 这个里面,为了不会出现数组溢出,这里面的p[]是以$开头的
//即:p[]="$ # a # b # b # a # b # c # b # a #"以上代码中,mx表示到 i 之前,最长的回文串所到达的最右边的地方,而 id 的意思是,到 i 之前的最长的回文的中心点,最核心的代码其实是这个:
if(mx>i) f[i]=min(f[id*2-i],mx-i);
else f[i]=1;关于这个代码的解释,我也是看了好多个博客才懂得,光看代码肯定一头雾水,果然还是要上图:
记 j = id * 2 - i,意思是 i 关于 id 对称的点
当mx > i 时:
有两种情况,一种是以p[i]为中点的回文串的最右边比mx小:
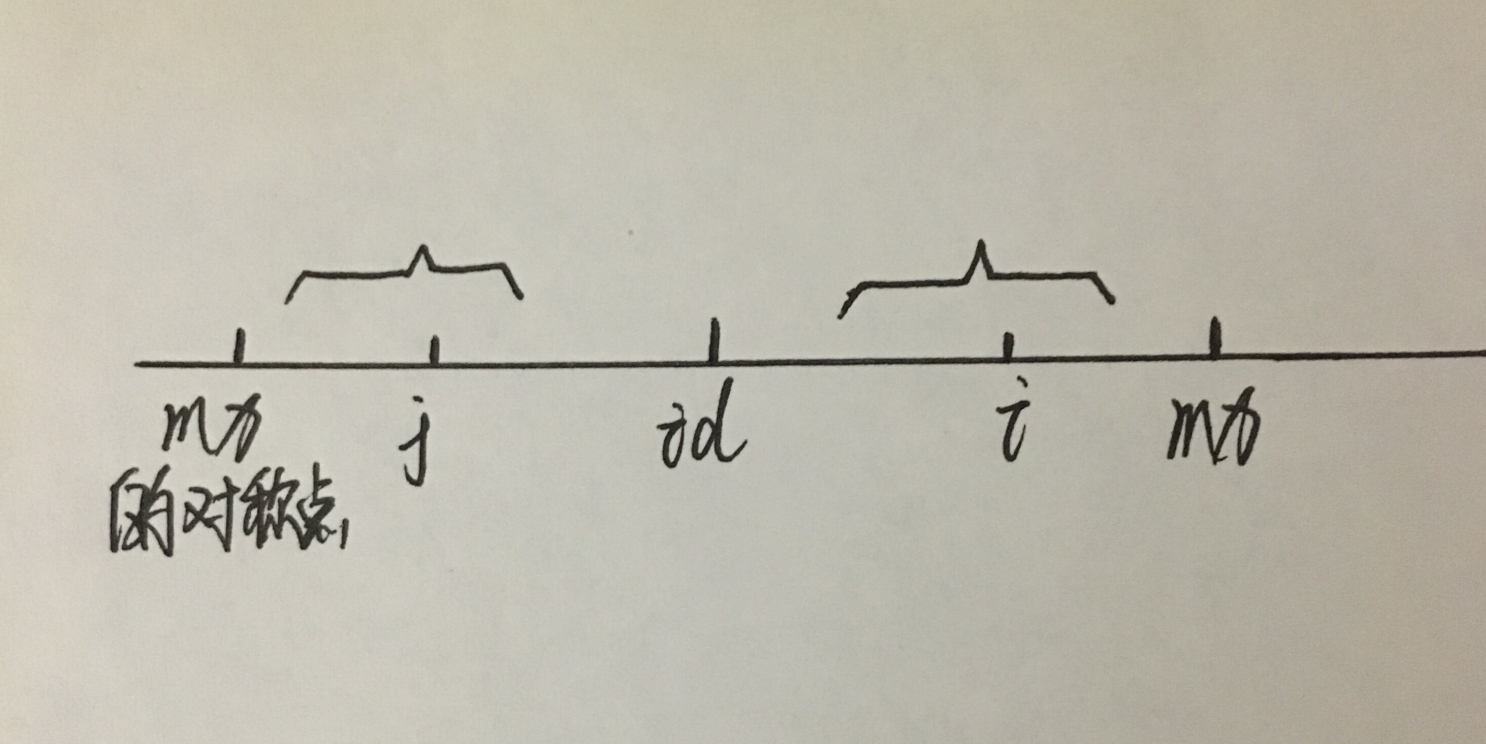
因为以p[i]为中点的回文串和以p[j]为中点的回文串是对称的,所以f[i]=f[j]。
还有一种情况是以p[i]为中点的回文串的最右边比mx大:
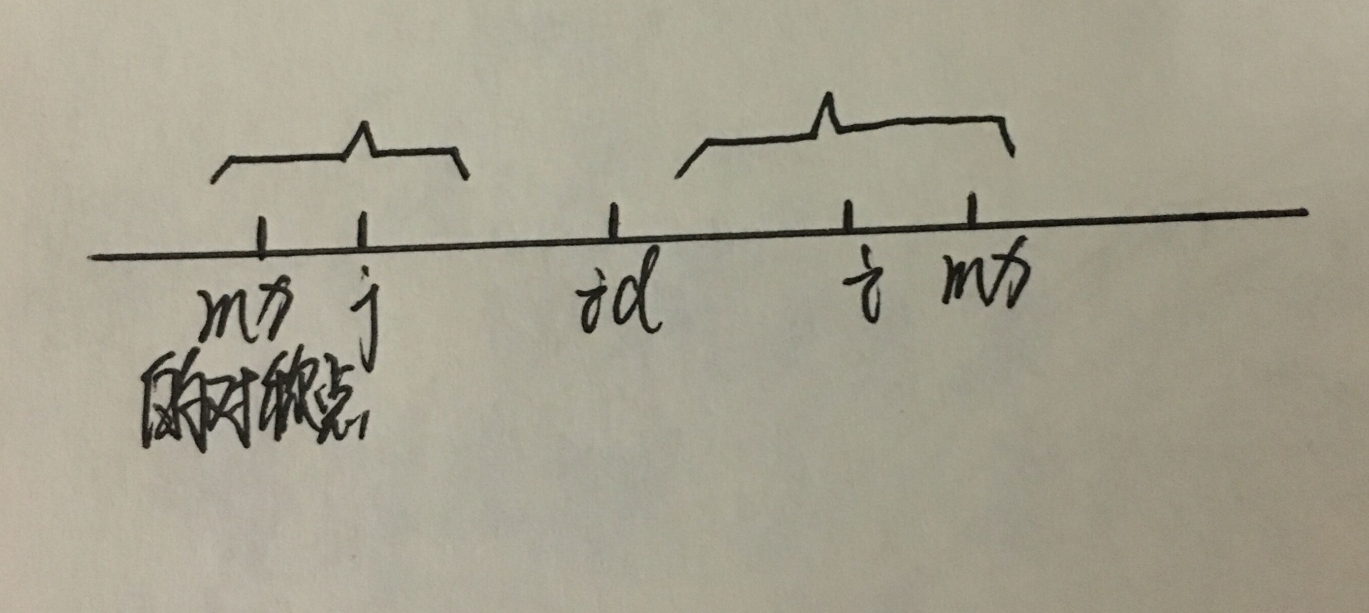
由于以p[i]为中点的回文串的右边超过了mx,所以我们能确定的只是从 i 到mx的长度,所以这种时候f[i]=mx-i。
总的来说就是当 mx>i 的时候,取 mx-i 和 f[j] 的最小值,然后再进行配对。
而当mx小于 i 的时候,以 p[j] 为中心的回文串并不在以 p[id] 为中心的回文串内,因此 p[i] 和 p[j] 并不关于点 id 对称,所以初始化为1。
THE END.















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









