






一、基于所给数据运行storm程序
(1)打开eclipse,点击文件,选择新建项目:
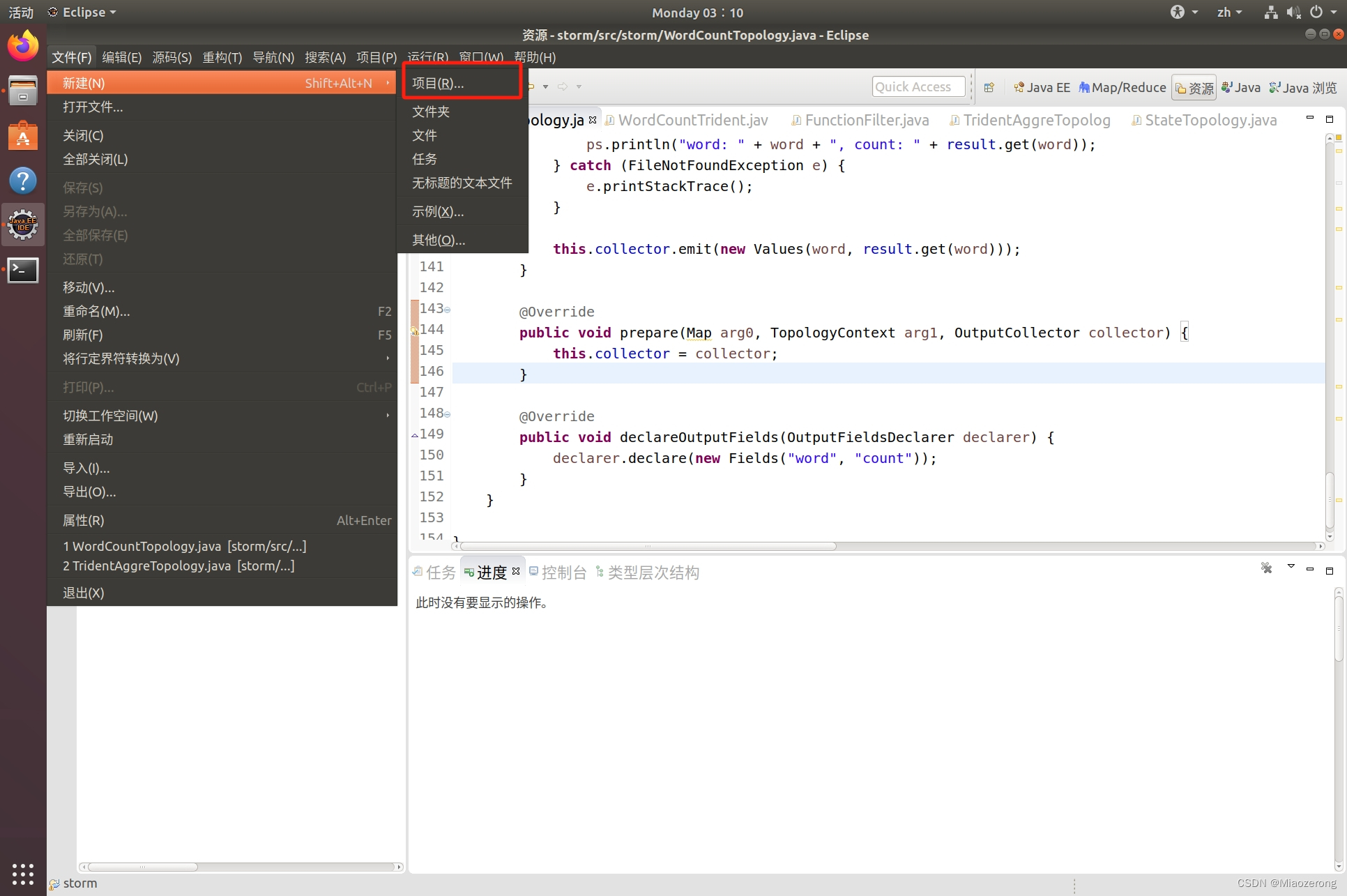
(2)在单出的栏目里面找到Java项目,选择,点击下一步:
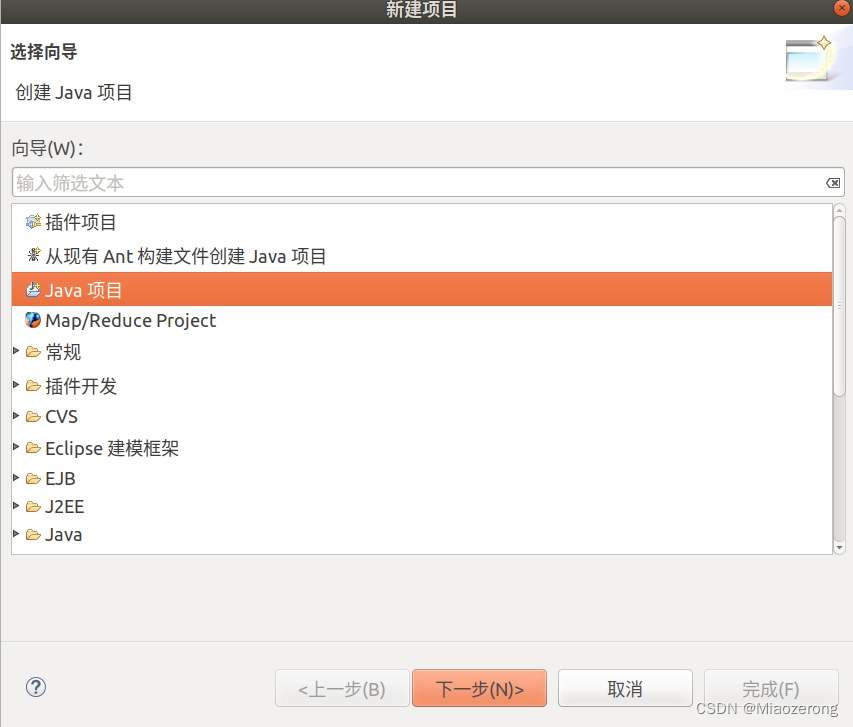
(3) 输入自定义项目名,点击完成:
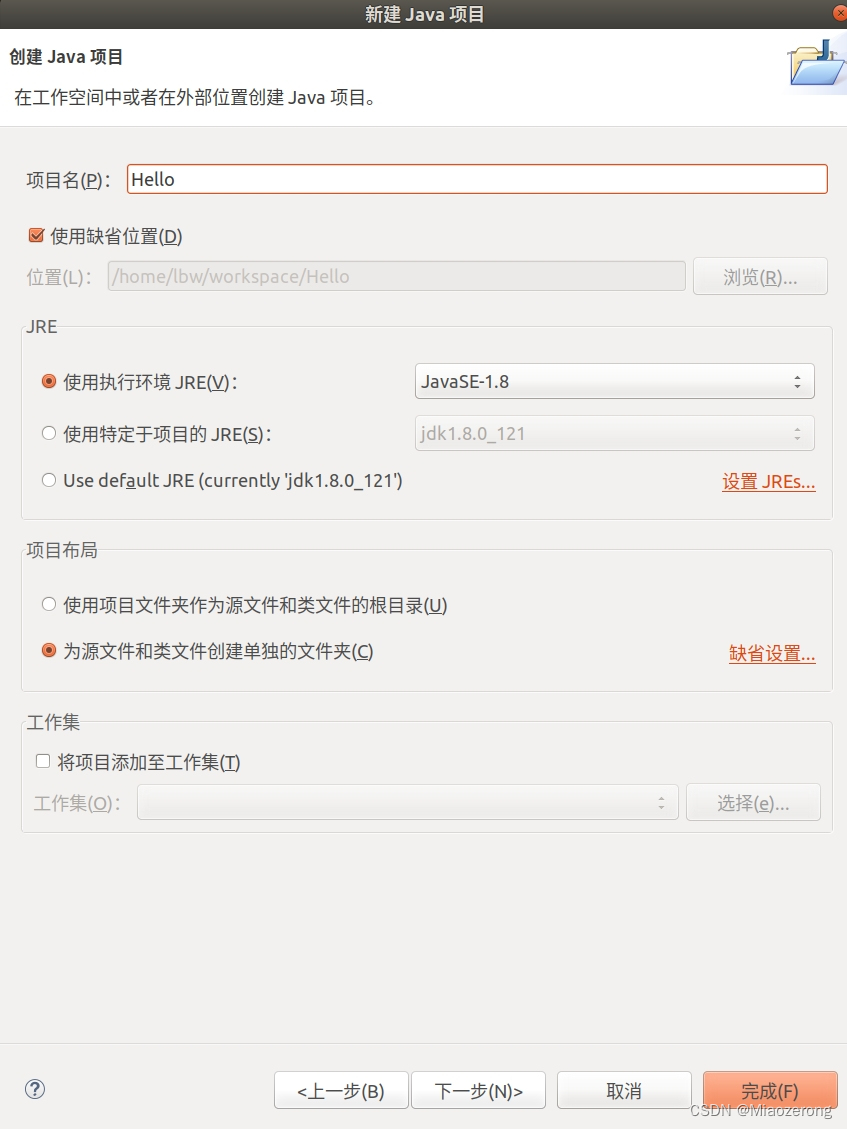
(4) 你会看到这样的结构:
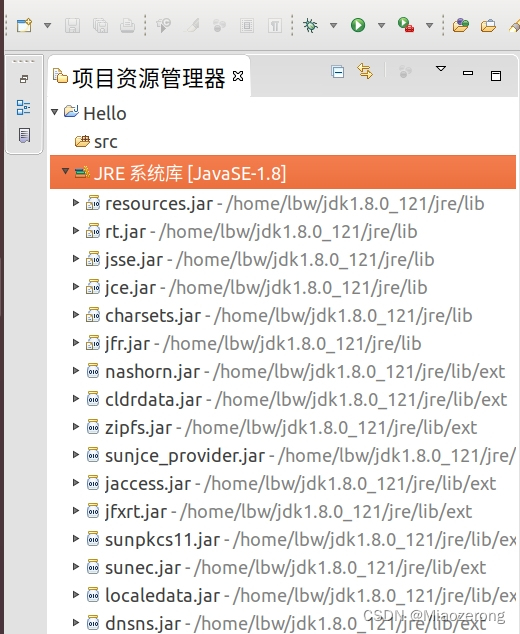
(5)点击src文件夹,右键新建一个包:
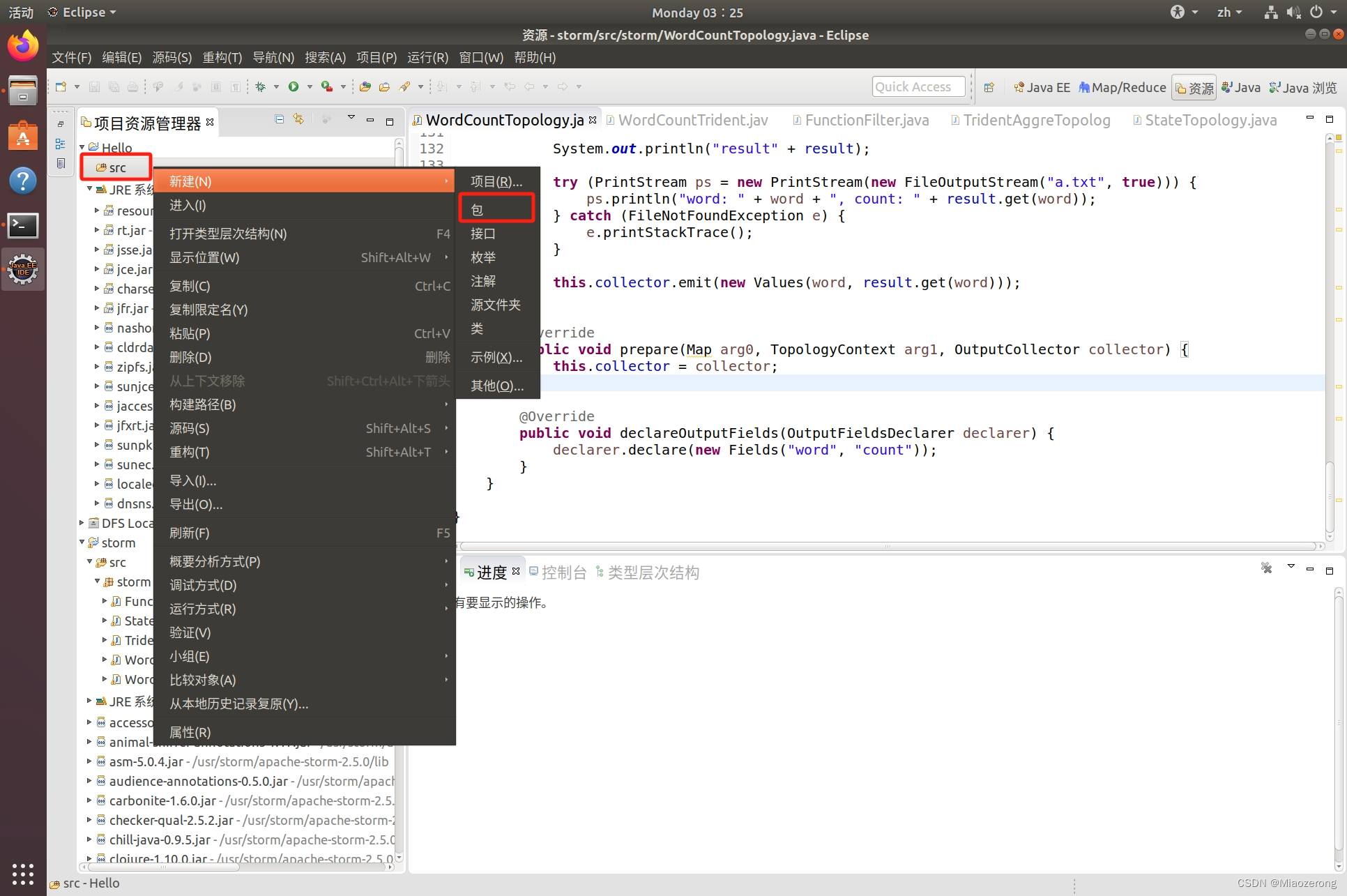
(6)输入包名storm,点击完成:

(7)点击新建的storm包,右键新建一个WordCountTopology类,代码如下:
package storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
import java.util.HashMap;
import java.util.Map;
public class WordCountTopology {
public static void main(String[] args) throws Exception {
//throws Exception捕获异常声明
//主程序:创建一个名为builder的Topology的任务
TopologyBuilder builder = new TopologyBuilder();
//指定Topology任务的spout组件(不设置并行度)
builder.setSpout("wordcount_spout", new WordCountSpout());
//指定Topology任务的第一个Bolt组件:分词(不设置并行度)
builder.setBolt("wordcount_split_bolt", new WordCountSplitBolt()).shuffleGrouping("wordcount_spout");
//指定Topology任务的第二个Bolt组件:计数(不设置并行度)
builder.setBolt("wordcount_count_bolt", new WordCountTotalBolt()).fieldsGrouping("wordcount_split_bolt",new Fields("word"));
//创建Topology任务
StormTopology wc = builder.createTopology();
//配置参数
Config conf = new Config();
//执行任务
//方式1:本地模式
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("MyStormWordCount", conf, wc);
//方式2:集群模式
//使用 StormSubmitter 将 topology 提交到集群. StormSubmitter 以 topology 的名称, topology 的配置和 topology 本身作为输入
// StormSubmitter.submitTopology(args[0], conf, wc);
}
//采集数据spout组件
public static class WordCountSpout extends BaseRichSpout {
// 模拟产生一些数据
private String[] data = {
"Apache Storm is a free and open source distributed realtime computation system.Apache Storm makes it easy to reliably process unbounded streams of data,doing for realtime processing what Hadoop did for batch processing."
};
// 定义spout的输出流
private SpoutOutputCollector collector;
@Override
public void nextTuple() {
// 由storm框架调用,每次调用进行数据采集
// 打印打印采集到的数据
System.out.println("采集的数据是:" + data[0]);
// 将采集到的数据发送给下一个组件进行处理
this.collector.emit(new Values(data[0]));
// 设置为隔很长时间才执行一次下采集操作
Utils.sleep(300000000);
}
@Override
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector) {
// 初始化spout组件时调用
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明输出的Tuple的格式
declarer.declare(new Fields("sentence"));
}
}
public static class WordCountSplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void execute(Tuple tuple) {
// 处理上一个组件发来的数据
String str = tuple.getStringByField("sentence");
//str.trim()用于去除字符串两端的空白字符
str = str.trim();
//replace(char oldChar,char newChar);
// oldChar:要替换的子字符串或者字符。
// newChar:新的字符串或字符,用于替换原有字符串的内容。
str = str.replace(",", " ");
str = str.replace(".", " ");
str = str.trim();
// 分词操作
String[] words = str.split(" ");
// 将处理好的(word,1)形式的数据发送给下一个组件
for (String w : words) {
this.collector.emit(new Values(w, 1));
}
}
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
// 初始化时调用
// OutputCollector代表的就是这个bolt组件的输出流
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明这个Bolt组件输出Tuple的格式
declarer.declare(new Fields("word", "count"));
}
}
public static class WordCountTotalBolt extends BaseRichBolt {
private OutputCollector collector;
private Map<String, Integer> result = new HashMap<>();
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
int count = tuple.getIntegerByField("count");
if (result.containsKey(word)) {
int total = result.get(word);
result.put(word, total + count);
} else {
result.put(word, count);
}
System.out.println("result" + result);
try (PrintStream ps = new PrintStream(new FileOutputStream("a.txt", true))) {
ps.println("word: " + word + ", count: " + result.get(word));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
this.collector.emit(new Values(word, result.get(word)));
}
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
}
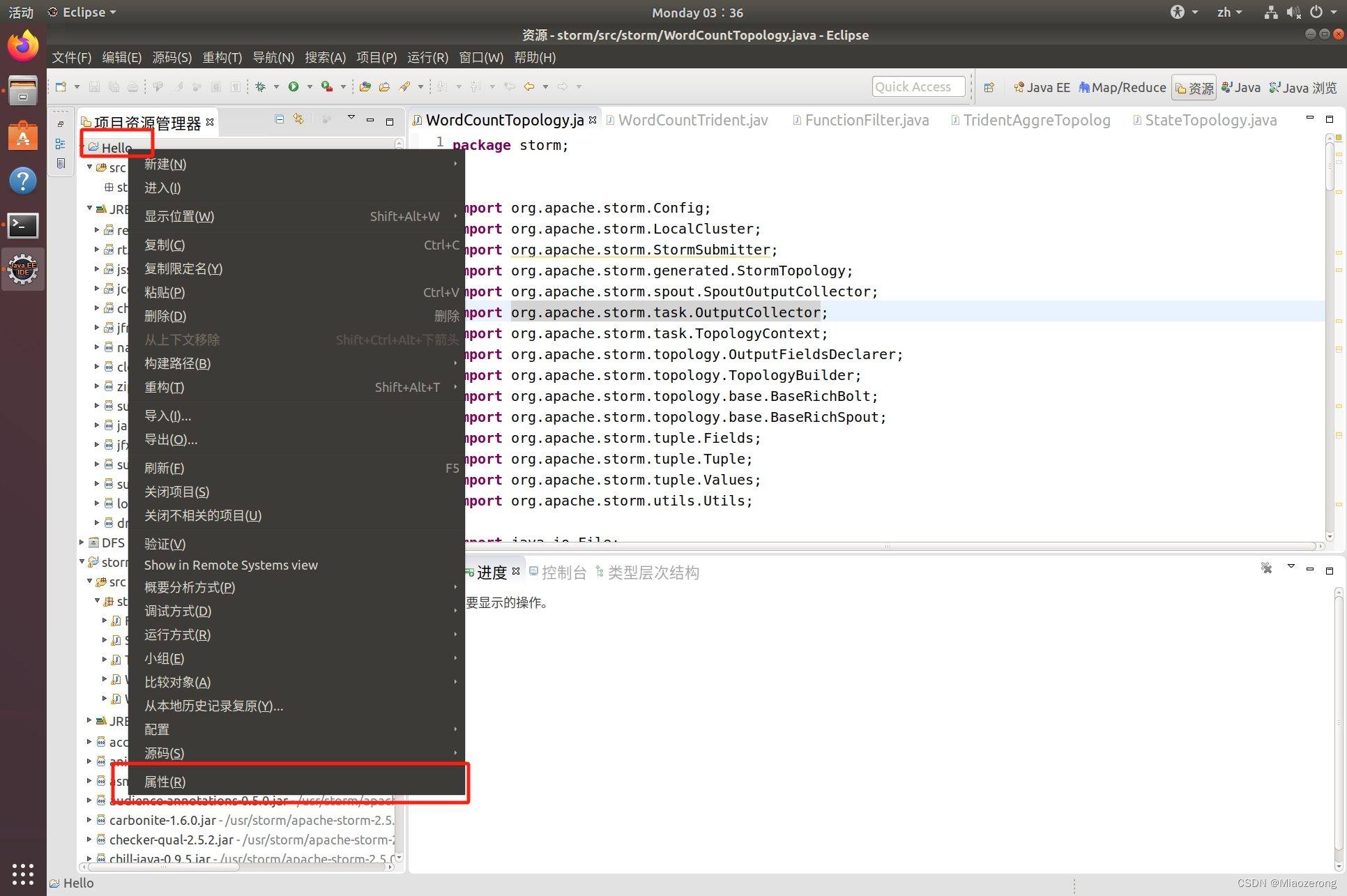
(8)点击自己的Hello项目,右键属性:
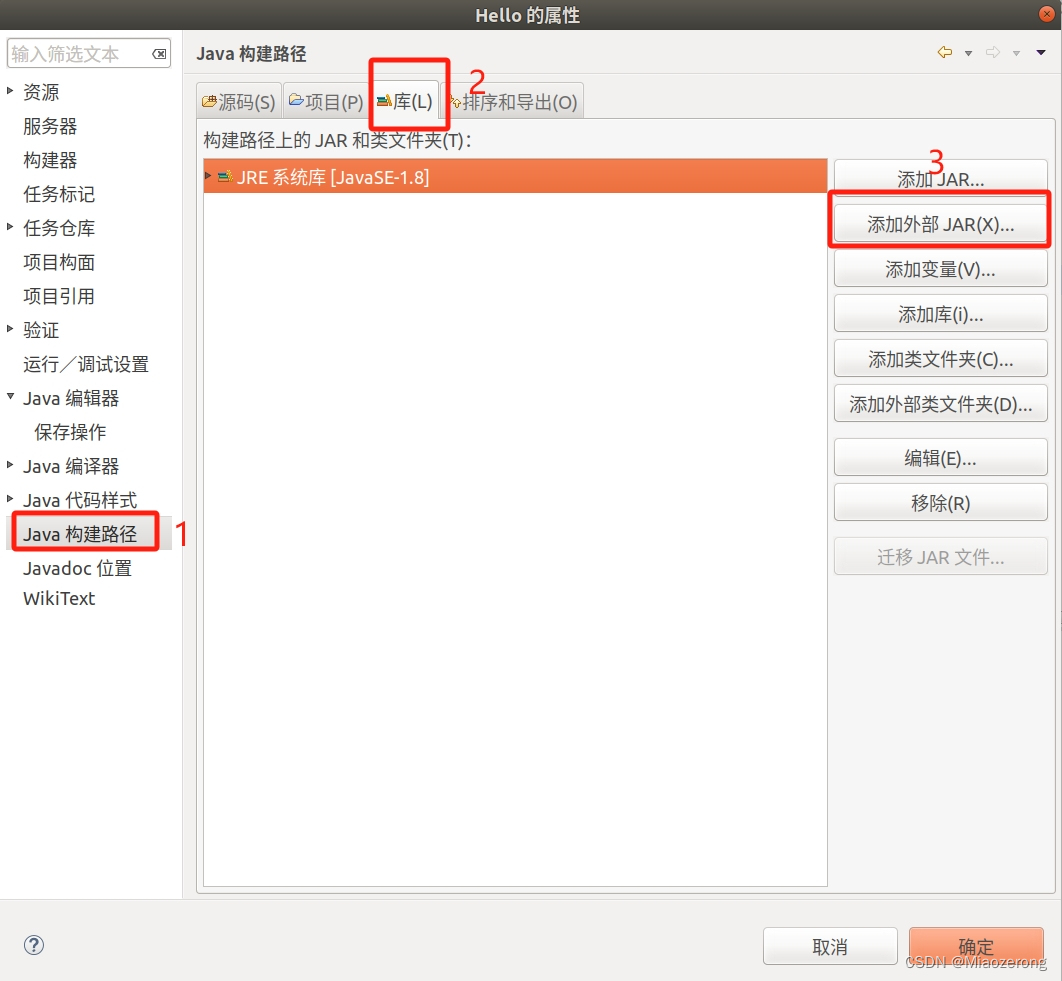
(9)选择 java构建路径,点击libraries(库),点击添加外部JAR:
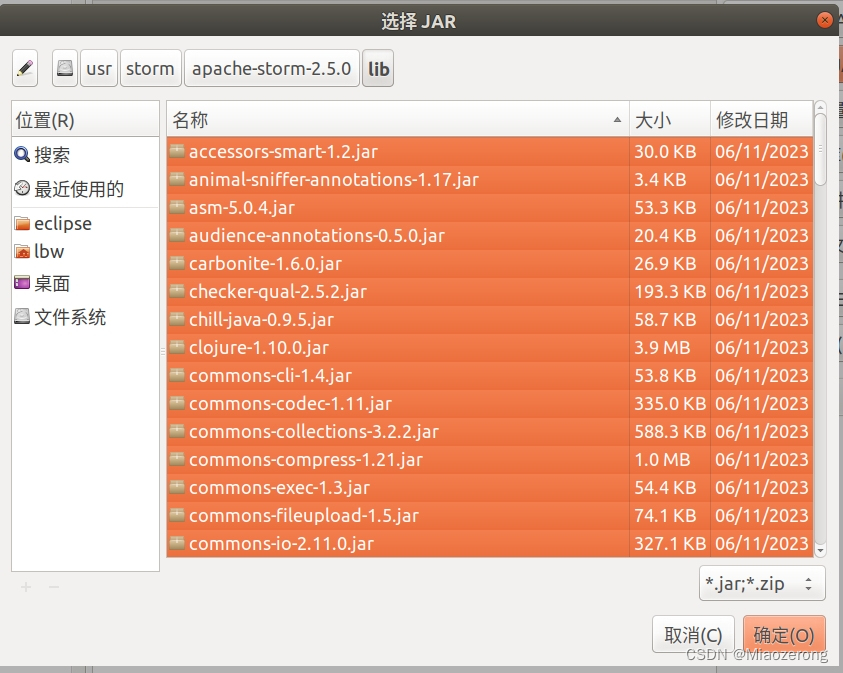
(10)找到你已经解压后的storm文件夹,找到该文件夹下的lib目录,Ctrl+A全选所有jar文件,点击确定,之后继续点击确定:
(11)文件结构如下:

(12)到现在,就已经全部配置完了,下面开始运行。点击代码,右键run as,选择java应用程序:
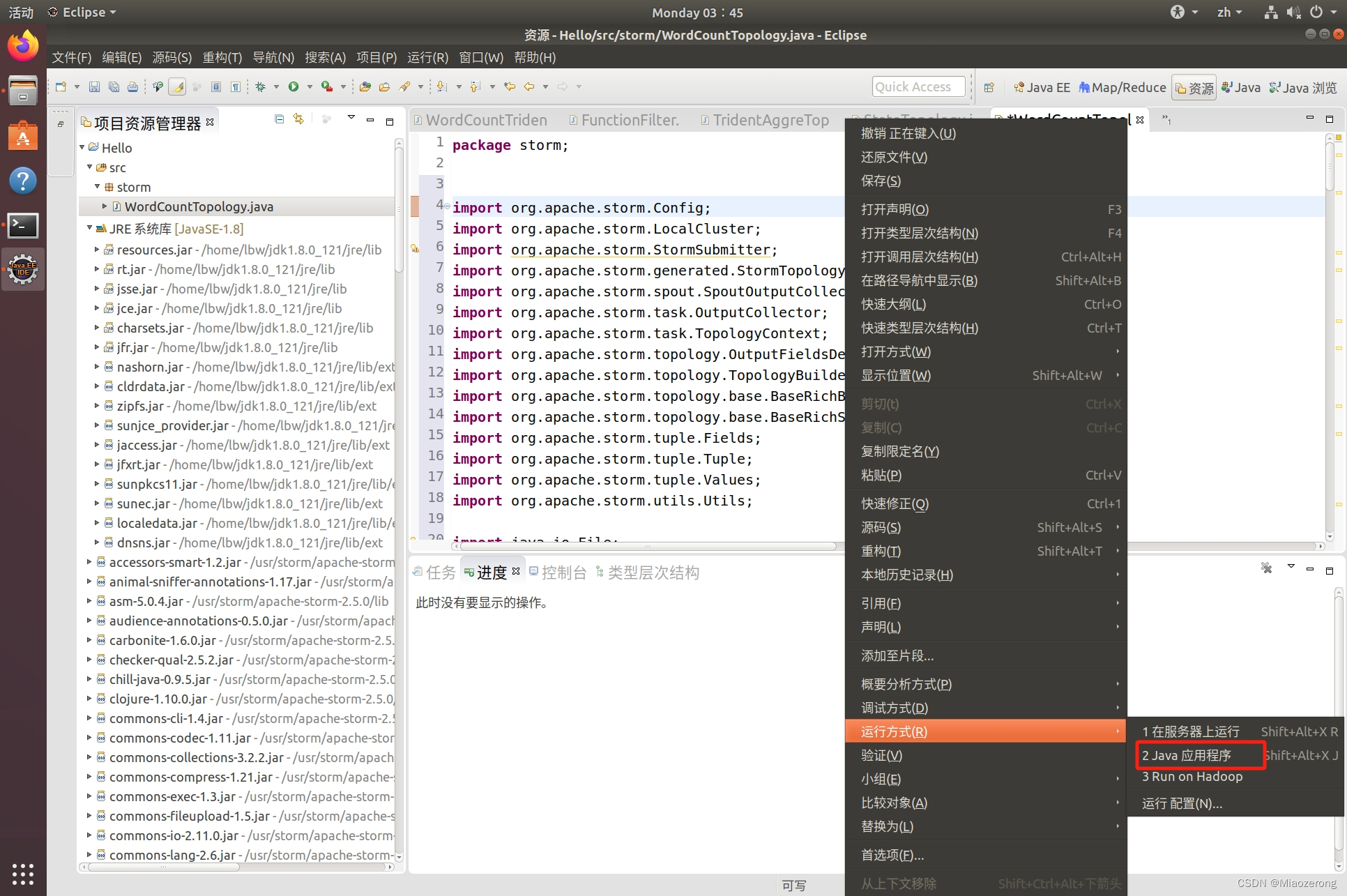
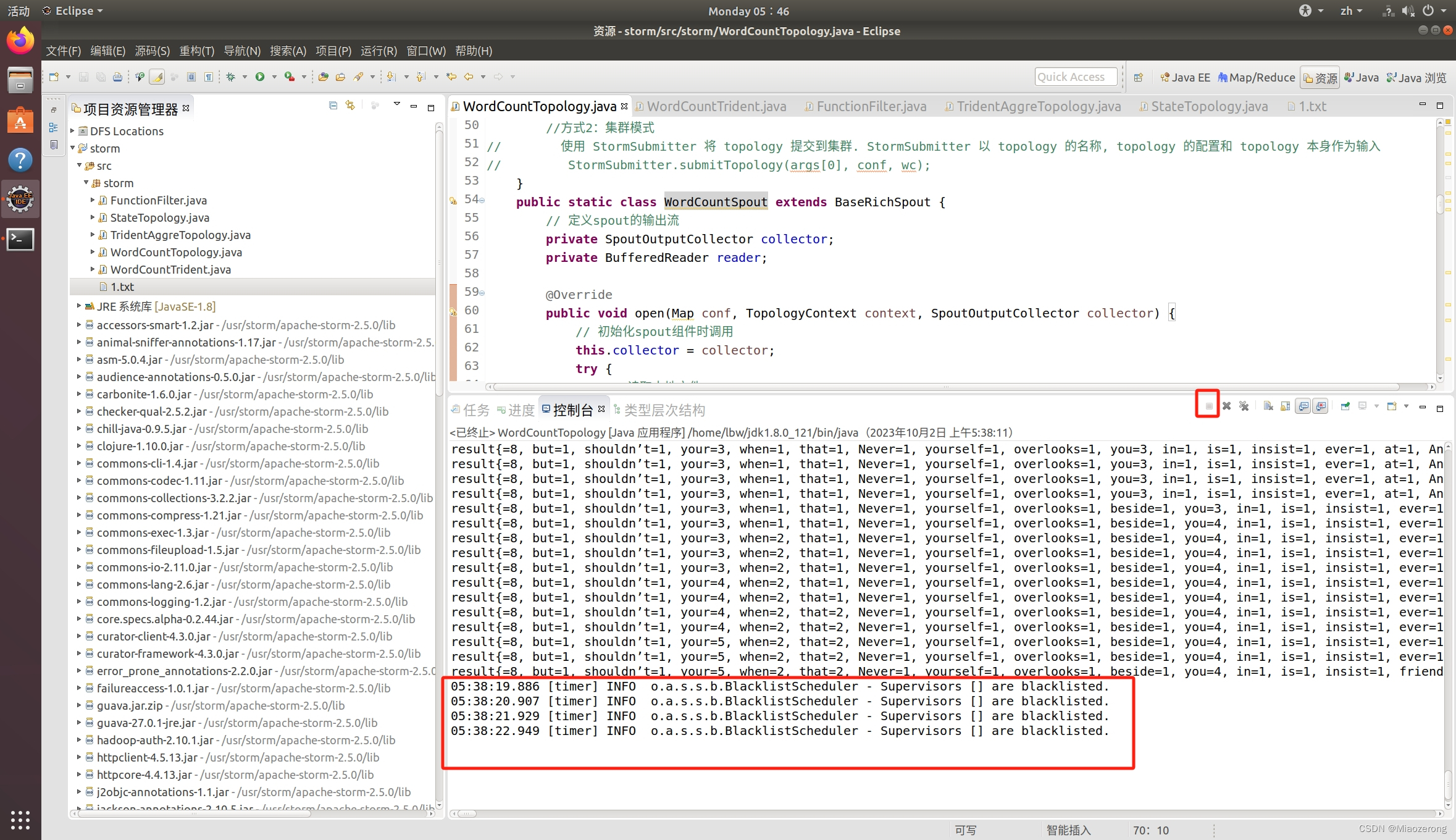
(13)运行到这种状态就可以停止了,因为这是流处理,结果已经出来了,后面没有继续输入数据,也不会有结果:

这就是得到的结果:
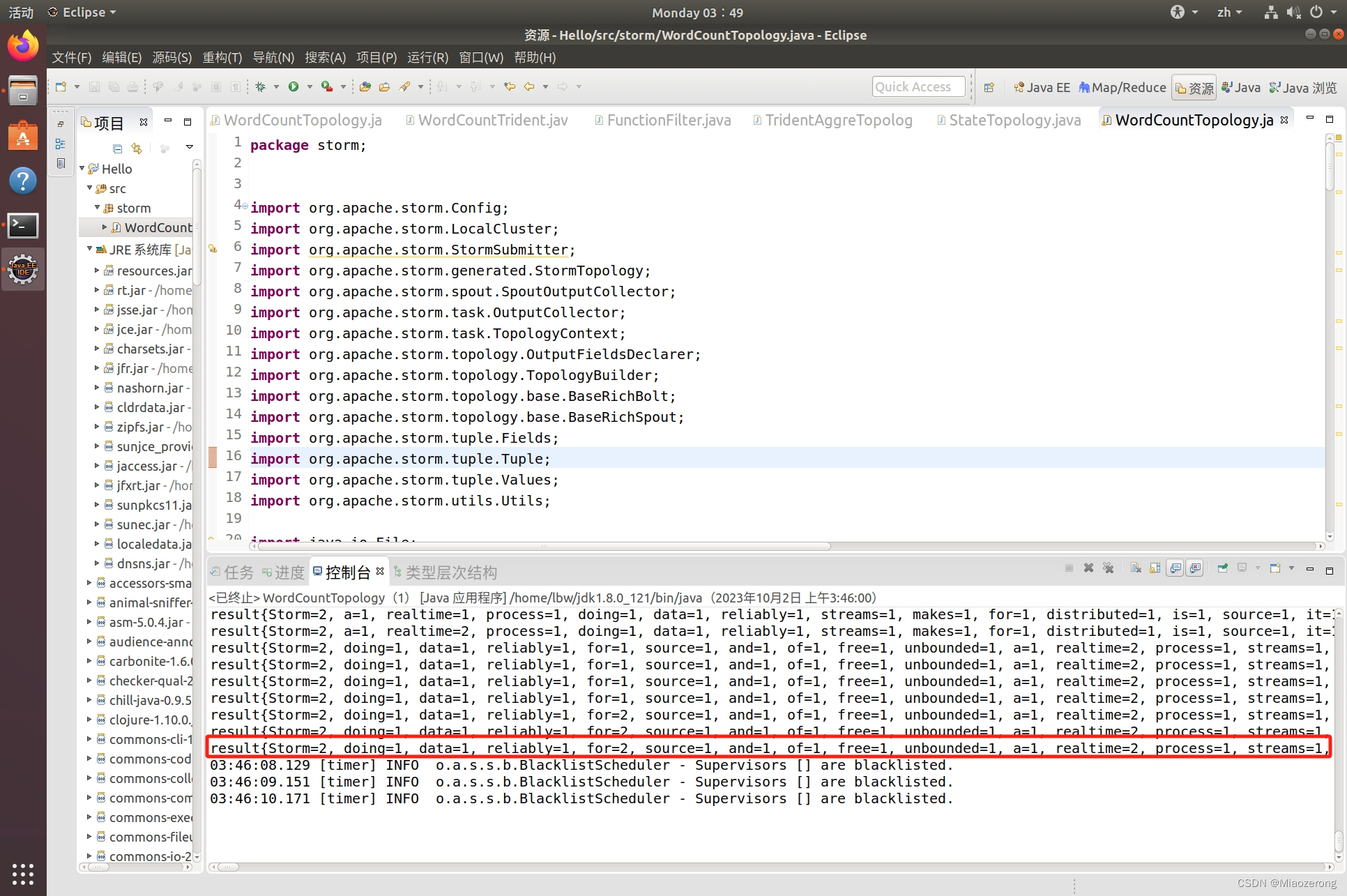
ps:还有其他的代码大家也可以参考,已经测试都可以运行:
package storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.thrift.TException;
import org.apache.storm.trident.TridentTopology;
import org.apache.storm.trident.operation.BaseFilter;
import org.apache.storm.trident.operation.BaseFunction;
import org.apache.storm.trident.operation.TridentCollector;
import org.apache.storm.trident.testing.FixedBatchSpout;
import org.apache.storm.trident.tuple.TridentTuple;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
/* 部分输出
emit word is :the
Filter word is:the and return type is:true
emit word is :cow
emit word is :jumped
emit word is :over
emit word is :the
Filter word is:the and return type is:true
emit word is :moon
* */
public class FunctionFilter {
public static void main(String[] args) throws TException{
TridentTopology topology = new TridentTopology();
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 1,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
//不循环发送数据
spout.setCycle(false);
//****请根据提示补全Topology程序****//
/*********begin*********/
//newStream 方法从输入源中读取数据, 并在 topology 中创建一个新的数据流 batch-spout
topology.newStream("batch-spout",spout)
//使用.each()方法,sentence tuple经过split()方法后输出word tuple
.each(new Fields("sentence"), new Split(), new Fields("word"))
//使用.each()方法,new Fields()保留setence tuple和word tuple ,经过WordFilter() 过滤 单词 the
.each(new Fields("sentence","word"), new WordFilter("the"));
/*********end*********/
StormTopology stormTopology = topology.build();
LocalCluster cluster = null;
try {
cluster = new LocalCluster();
} catch (Exception e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
Config conf = new Config();
cluster.submitTopology("soc", conf,stormTopology);
}
//Filter过滤器
public static class WordFilter extends BaseFilter {
String actor;
public WordFilter(String actor) {
this.actor = actor;
}
@Override
public boolean isKeep(TridentTuple tuple) {
//如果元组的值和 actor 相等(这里的actor是“the”)
if(tuple.getString(1).equals(actor)){
//输出 Filter word is:the and return type is:true
System.out.println("Filter word is:"+tuple.getString(1) + " and return type is:"+tuple.getString(1).equals(actor));
}
return tuple.getString(1).equals(actor);
}
}
// Function函数
public static class Split extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
//把句子以空格切分为单词
//每一个 sentence tuple 可能会被转换成多个 word tuple,
//比如说 "the cow jumped over the moon" 这个句子会被转换成 6 个 "word" tuples
for(String word: sentence.split(" ")) {
System.out.println("emit word is :"+word);
collector.emit(new Values(word));
}
}
}
}package storm;
import java.util.ArrayList;
import java.util.List;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.trident.TridentTopology;
import org.apache.storm.trident.operation.BaseFunction;
import org.apache.storm.trident.operation.TridentCollector;
import org.apache.storm.trident.testing.FixedBatchSpout;
import org.apache.storm.trident.tuple.TridentTuple;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.trident.state.BaseQueryFunction;
import org.apache.storm.trident.state.State;
import java.util.Map;
import org.apache.storm.task.IMetricsContext;
import org.apache.storm.trident.state.StateFactory;
public class StateTopology {
public static void main(String[] agrs) throws Exception{
FixedBatchSpout spout = new FixedBatchSpout(
new Fields("sentence"), 2,
new Values("the cow"),
new Values("the man"),
new Values("four score"),
new Values("many apples"));
spout.setCycle(false);
TridentTopology topology = new TridentTopology();
//****请根据提示补全Topology程序****//
/*********begin*********/
//newStream 方法从输入源中读取数据, 并在 topology 中创建一个新的数据流 spout
topology.newStream("spout",spout)
//使用.each()方法,sentence tuple经过split()方法后输出word tuple
.each(new Fields("sentence"), new Split(), new Fields("word"))
//使用 .newStaticState()方法创建了一个外部数据库,
//.stateQuery()将topology.newStaticState(new TestStateFactory())映射到new Fields("word") word字段
//将new TestQueryLocation()映射到 new Fields("test") test字段 上
.stateQuery(topology.newStaticState(new TestStateFactory()),new Fields("word"), new TestQueryLocation(), new Fields("test"));
/*********end*********/
StormTopology stormTopology = topology.build();
LocalCluster cluster = new LocalCluster();
Config conf = new Config();
conf.setDebug(false);
cluster.submitTopology("test", conf,stormTopology);
}
public static class Split extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
}
public static class TestState implements State{
@Override
public void beginCommit(Long arg0) {
// TODO Auto-generated method stub
}
@Override
public void commit(Long arg0) {
// TODO Auto-generated method stub
}
public String getDBOption(int i){
return "success"+i;
}
}
public static class TestStateFactory implements StateFactory{
@Override
public State makeState(Map arg0, IMetricsContext arg1, int arg2, int arg3) {
// TODO Auto-generated method stub
return new TestState();
}
}
public static class TestQueryLocation extends BaseQueryFunction<TestState, String>{
@Override
public List<String> batchRetrieve(TestState state, List<TridentTuple> arg1) {
List<String> list = new ArrayList<String>();
for(int i = 0 ; i< arg1.size() ; i++){
list.add(state.getDBOption(i));
}
return list;
}
@Override
public void execute(TridentTuple arg0, String arg1, TridentCollector arg2) {
System.out.println(arg0.getString(0));
System.out.println(arg1);
}
}
}package storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.trident.TridentTopology;
import org.apache.storm.trident.operation.BaseAggregator;
import org.apache.storm.trident.operation.TridentCollector;
import org.apache.storm.trident.testing.FixedBatchSpout;
import org.apache.storm.trident.testing.Split;
import org.apache.storm.trident.tuple.TridentTuple;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.HashMap;
import java.util.Map;
public class TridentAggreTopology {
public static class WordAggregat extends BaseAggregator<Map<String, Integer>> {
public static Map<String, Integer> map = new HashMap<String, Integer>();
@Override
public Map<String, Integer> init(Object batchId, TridentCollector collector) {
return new HashMap<String, Integer>();
}
@Override
public void aggregate(Map<String, Integer> val, TridentTuple tuple,
TridentCollector collector) {
String location = tuple.getString(0);
Integer i = map.get(location);
if(null == i){
i = 1;
}else{
i = i+1;
}
map.put(location, i);
}
@Override
public void complete(Map<String, Integer> val, TridentCollector collector) {
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
collector.emit(new Values(map));
Utils.sleep(300000000);
}
}
public static void main(String[] args) throws Exception{
TridentTopology topology = new TridentTopology();
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 1,
new Values("the cow jumped cow jumped jumped"));
spout.setCycle(true);
//****请根据提示补全Topology程序****//
/*********begin*********/
//newStream 方法从输入源中读取数据, 并在 topology 中创建一个新的数据流 batch-spout
topology.newStream("batch-spout",spout)
//使用.each()方法,sentence tuple经过split()方法后输出word tuple
.each(new Fields("sentence"), new Split(), new Fields("word"))
//使用partitionBy()对word tuple进行分区
.partitionBy(new Fields("word"))
//使用partitionAggregate(),对word tuple聚合每个分区,经过WordAggregat(),输出agg字段元组
.partitionAggregate(new Fields("word"),new WordAggregat(), new Fields("agg"));
/*********end*********/
StormTopology stormTopology = topology.build();
LocalCluster cluster = new LocalCluster();
Config conf = new Config();
cluster.submitTopology("soc", conf,stormTopology);
}
}package storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.trident.Stream;
import org.apache.storm.trident.TridentState;
import org.apache.storm.trident.TridentTopology;
import org.apache.storm.trident.operation.BaseFunction;
import org.apache.storm.trident.operation.Consumer;
import org.apache.storm.trident.operation.TridentCollector;
import org.apache.storm.trident.operation.builtin.Count;
import org.apache.storm.trident.testing.FixedBatchSpout;
import org.apache.storm.trident.testing.MemoryMapState;
import org.apache.storm.trident.tuple.TridentTuple;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
public class WordCountTrident {
//构建topology
private static StormTopology buildTopology() {
//spout源
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"),1,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
//不循环发射数据
spout.setCycle(false);
//****请根据提示补全StormTopology程序的创建过程****//
/*********begin*********/
//首先创建了一个 名为 topology 的TridentTopology 对象
TridentTopology topology = new TridentTopology();
//使用.newStream() 方法从上面定义的输入源中读取数据,并在 topology 中创建一个新的数据流 名为spout1
//使用.each()方法遍历每一个文本行 sentence ,指定使用split()处理,输出字段名为word的tuple元组
//使用.groupby()方法对字段名为word的tuple元组进行分组
//使用.persistentAggregate()方法,指定使用count()方法对word进行统计并保存结果到内存中。
// 不使用.parallelismHint()方法设置并行度
TridentState wordCounts =
topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));
/*********end**********/
//打印count后结果
wordCounts.newValuesStream()
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input);
}
});
return topology.build();
}
public static class Split extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
//根据空格拆分 sentence
for(String word: sentence.split(" ")) {
//将拆分出的每个单词作为一个 tuple 输出
collector.emit(new Values(word));
}
}
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
//本地模式
//创建一个进程内的集群,只需要使用 LocalCluster 类
//使用 LocalCluster 对象的 submitTopology 方法提交topologies(拓扑)
//以 topology 的名称, topology 的配置和 topology 本身作为参数输入
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("app0", conf, buildTopology());
}
}二、基于本地文件运行storm程序
(1)直接在java文件本地新建一个文件,例如1.txt,如下图所示:
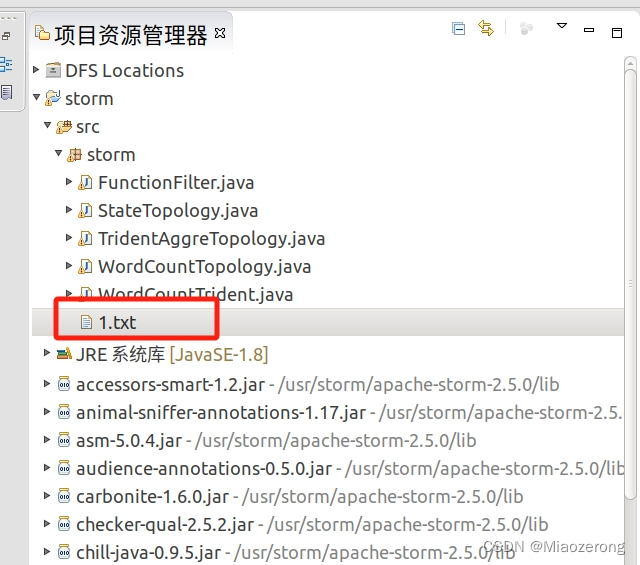
(2)相应的词频统计代码如下:
package storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
import java.util.HashMap;
import java.util.Map;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class WordCountTopology {
public static void main(String[] args) throws Exception {
//throws Exception捕获异常声明
//主程序:创建一个名为builder的Topology的任务
TopologyBuilder builder = new TopologyBuilder();
//指定Topology任务的spout组件(不设置并行度)
builder.setSpout("wordcount_spout", new WordCountSpout());
//指定Topology任务的第一个Bolt组件:分词(不设置并行度)
builder.setBolt("wordcount_split_bolt", new WordCountSplitBolt()).shuffleGrouping("wordcount_spout");
//指定Topology任务的第二个Bolt组件:计数(不设置并行度)
builder.setBolt("wordcount_count_bolt", new WordCountTotalBolt()).fieldsGrouping("wordcount_split_bolt",new Fields("word"));
//创建Topology任务
StormTopology wc = builder.createTopology();
//配置参数
Config conf = new Config();
//执行任务
//方式1:本地模式
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("MyStormWordCount", conf, wc);
//方式2:集群模式
// 使用 StormSubmitter 将 topology 提交到集群. StormSubmitter 以 topology 的名称, topology 的配置和 topology 本身作为输入
// StormSubmitter.submitTopology(args[0], conf, wc);
}
public static class WordCountSpout extends BaseRichSpout {
// 定义spout的输出流
private SpoutOutputCollector collector;
private BufferedReader reader;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
// 初始化spout组件时调用
this.collector = collector;
try {
// 读取本地文件
FileReader fileReader = new FileReader("/home/lbw/workspace/storm/src/storm/1.txt");
this.reader = new BufferedReader(fileReader);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
@Override
public void nextTuple() {
try {
// 读取文件中的一行数据
String line = reader.readLine();
if (line != null) {
// 将读取到的行数据发送给下一个组件进行处理
this.collector.emit(new Values(line));
} else {
// 文件已读取完毕,等待一段时间后重复读取
Utils.sleep(3000);
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明输出的Tuple的格式
declarer.declare(new Fields("sentence"));
}
@Override
public void close() {
// 在spout组件关闭时关闭文件读取器
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static class WordCountSplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void execute(Tuple tuple) {
// 处理上一个组件发来的数据
String str = tuple.getStringByField("sentence");
//str.trim()用于去除字符串两端的空白字符
str = str.trim();
//replace(char oldChar,char newChar);
// oldChar:要替换的子字符串或者字符。
// newChar:新的字符串或字符,用于替换原有字符串的内容。
str = str.replace(",", " ");
str = str.replace(".", " ");
str = str.trim();
// 分词操作
String[] words = str.split(" ");
// 将处理好的(word,1)形式的数据发送给下一个组件
for (String w : words) {
this.collector.emit(new Values(w, 1));
}
}
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
// 初始化时调用
// OutputCollector代表的就是这个bolt组件的输出流
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明这个Bolt组件输出Tuple的格式
declarer.declare(new Fields("word", "count"));
}
}
public static class WordCountTotalBolt extends BaseRichBolt {
private OutputCollector collector;
private Map<String, Integer> result = new HashMap<>();
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
int count = tuple.getIntegerByField("count");
if (result.containsKey(word)) {
int total = result.get(word);
result.put(word, total + count);
} else {
result.put(word, count);
}
System.out.println("result" + result);
try (PrintStream ps = new PrintStream(new FileOutputStream("a.txt", true))) {
ps.println("word: " + word + ", count: " + result.get(word));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
this.collector.emit(new Values(word, result.get(word)));
}
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
}
主要修改WordCountSpout部分:
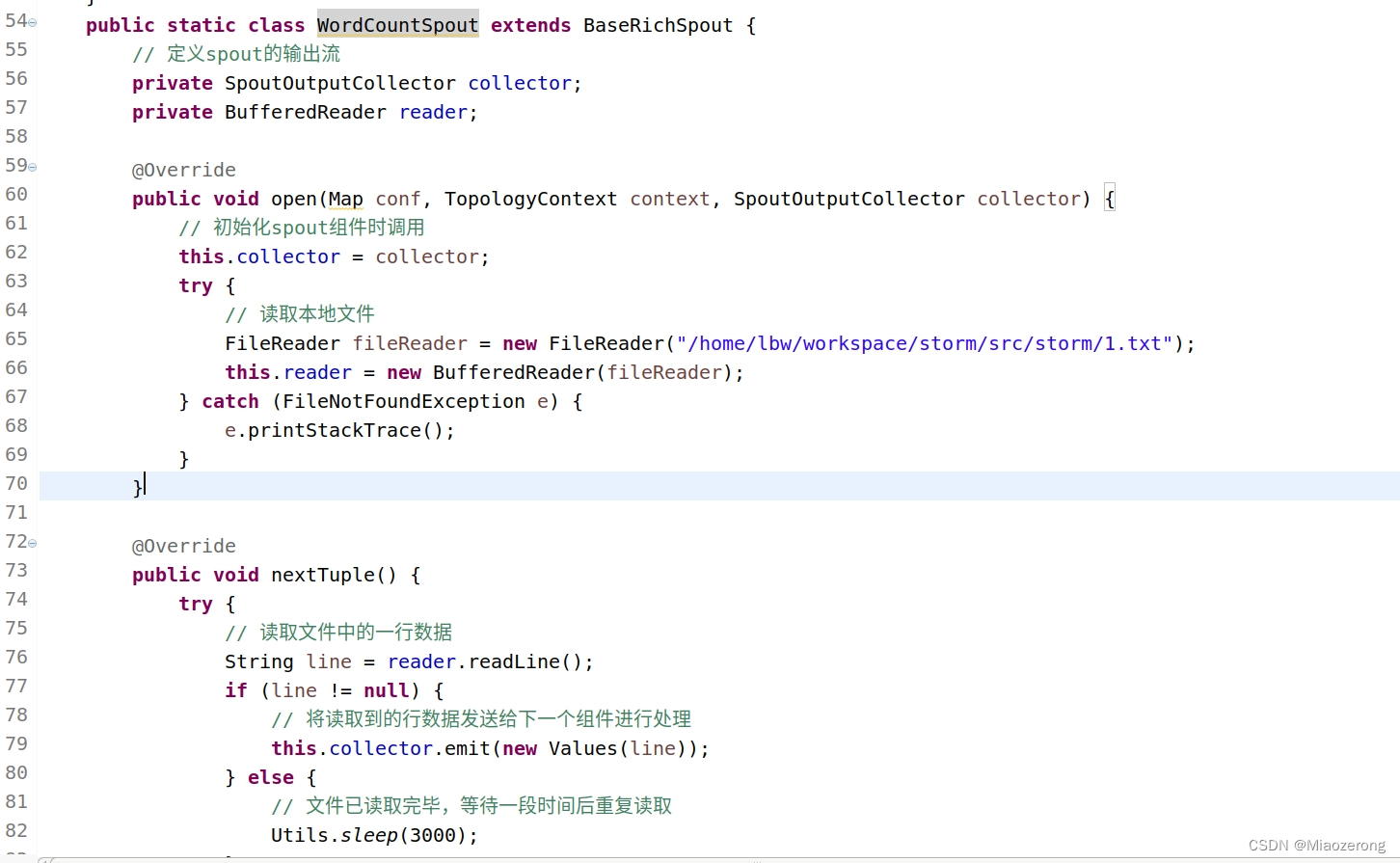
和上面一样,运行到这样就点击停止,不需要运行下去了:














 3478
3478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









