







-
SELECT
在写sql语句时,可以任意换行,但在语句间不能有空行
sql的注释有两种:--(单行注释) 与 /* */(多行注释)
在SELECT子句中可以进行简单的运算并设为新列,如:
SELECT price * 2 AS "pricex2";
或者SELECT 28 AS "price"; (将price列所有值都设为28)
任何运算中含有NULL,结果都是NULL,且不会报错,即使是NULL/0
sql的比较运算符可以用于字符、日期等几乎所有数据类型。对字符串进行比较时,是按照字典顺序进行排序的。比较运算符的结果中不会出现NULL的行。
要想判断是不是NULL,使用WHERE col = NULL是没有结果的,应该写成WHERE col IS NULL
AND运算符的优先级高于OR
SQL中除了真值(非0即1)外还有不确定值NULL,但是尽量少用,为字段添加not null约束。
count(*)统计包括null值的行一共多少行
count(col_name)统计不包括null值的行一共多少行
sum函数其实并没有把null看做0,而是会先删去null行,再计算。
所以avg函数计算平均值是的除数也不包含null行。
min 与max函数与比较运算符一样可以运用于几乎所有数据类型。
字句的书写顺序是固定的:SELECT-FROM-WHERE-GROUP BY-HAVING-ORDER BY。但是系统的执行顺序是:FROM-WHERE-GROUP BY-HAVING-SELECT-ORDER BY。因此,group by中不能使用select中定义的列的别名,但是order by中可以用。
当有group by时,select与having子句中可以使用的元素只能是:常数、GROUP BY指定的列、聚合函数(如count等,一般写count(*),就是统计每个类中的个数)
有group by的结果是随机排列的。
count等聚合函数只能在select、having、order by子句中使用,所以当想在group by的结果中筛选聚合函数的结果的话,不能在where中写筛选条件,要在having中写书写条件。
where用来指定数据行的条件,having用来指定分组的条件。
select的结果也是随机排序的(但是每次都一样,其实是按照数据存储的物理地址排序的,物理地址通过hash算法计算得到)。把postgresql.conf的ENABLE_HASHJOIN设为OFF.则查询的结果就是插入的顺序。
-
INSERT/DELETE/UPDATE
一条insert语句只能插入一条数据,但是update可以一次更新多条数据
在插入数据时,如果省略了没有默认值的列,该列的值就会被设为NULL
使用INSERT INTO ... SELECT... FROM...来从一个表中筛选数据到另一张表
删除所有数据:DELETE FROM 表名 (注意,没有 *)
DDL指令不能rollback,DML指令可以rollback
-
事务
SQL, Server, Pgsql的开始事务语句:BEGIN TRANSACTION
MySQL的开始事务语句:START TRANSACTION
Oracle,DB2没有开始事务语句
大家的结束语句都是:COMMIT或者ROLLBACK,事务一旦提交,就回不去了。
不同的数据库对于事务什么时候开始,什么时候结束不一样,大部分都是自动提交模式,每一条成功运行的语句都在事务中被处理。所以一旦执行,不能回滚,除非显式地指明开始结束。Oracle则虽然没有开始语句,却是一定要求用户显式地写结束语句才会提交事务。
即使写了开始事务,没有写结束事务,操作也能执行并查询到结果,但是该操作可以被回滚。
ACID:参考另一篇博文
-
视图
一个视图就是一个select语句,所以它不存储实际的数据,只存储SELECT语句。所以原表更新的话,视图也会及时更新。对于一些频繁需要select的语句,可以建立视图。
由于视图与表一样,数据是无须的,所以不能使用order by子句(postgresql可以用)
可以在视图上再建视图,就是多重视图,但是不推荐
要使用Insert语句时,视图要满足:没有使用group by, having, distinct, from一张表等条件。在pgsql中视图默认为只读,需要进行设置可更新:
AS NO INSERT TO 视图名 DO INSERTED INSERT INTO 表名 VALUES().
UPDATE与DELETE语句可以像表一样正常执行,而且会影响到原表。对于一些敏感字段不想让用户更改的,可以不提取到视图中,而只给视图的权限,不给原表的权限。
在pgsql中,如果删除多重视图中有关联的视图会报错,需要在删除的时候解除关联:
DROP VIEW 视图名 CASCADE;
子查询必须使用AS关键字设定名称,该名称在运行完语句后就失效清除了。
标量子查询一定且只能返回一个数据,所以可以使用<> =等操作符,如查询平均值。由于WHERE子句中不能使用聚合函数,所以这里的平均值要写在一个SELECT子句中。
-
函数
MOD(被除数,除数) :求余 【SQL Server使用特殊的运算符(函数)“%”来计算余数】
EXTRACT(日期元素 FROM 日期):截取日期元素
-
谓词
谓词会返回真值(TRUE/ FALSE/UNKNOWN),如=、<、>、<> 等比较运算符,以及:
-
CASE表达式
CASE WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
.
.
.
ELSE <表达式>
END搜索CASE表达式,与switch-case-default用法类似,只针对一个变量进行条件判断
由于是表达式,所以可以书写在任意位置。
-
集合运算
UNION(相同行不重复)、UNION ALL(相同行重复):求并集, UNION的两个select子句的记录列个数与类型要相同
INTERSECT(相同行不重复)、INTERSECT ALL(相同行重复):求交集
EXCEPT:求差集
INNER JOIN:内联结,通过一列字段,将多张表相连,只保留联结部分
OUTER JOIN:外联结,保留未联结的多余行,分为RIGHT OUTER JOIN与LEFT OUTER JOIN
ON子句与联结一同使用,相当于WHERE子句
CROSS JOIN:交叉联结(笛卡尔积)
-
窗口函数(OLAP 实时分析处理)
这里的窗口表示 范围 的意思(与窗口算法里的含义类似,重点在边框范围),其实用组更准确写,但是组一般用来指GROUP BY之后的组。
PARTITION BY与ORDER BY为分组之后排序,PARTITION BY的功能与GROUP BY非常相似,但其没有汇总功能。
RANK函数就是可以将相同的数值都标记为同一等级,类似于成绩排名。如标记为:1 1 3 3 5 6
DENSE_RANK函数即使存在相同位次的记录,也不会跳过之后的位次。如 1 1 2 2 3 4
ROW_NUMBER函数,赋予唯一的连续位次:1 2 3 4,
使用方法:RANK() OVER (ORDER BY sale_price) AS newcolumn
使用限制:只能写在select子句中,因为它是在where子句与group by子句处理之后进行的
所有聚合函数都能用作窗口函数
使用示例:SELECT SUM (sale_price) OVER (ORDER BY product_id) AS current_sum
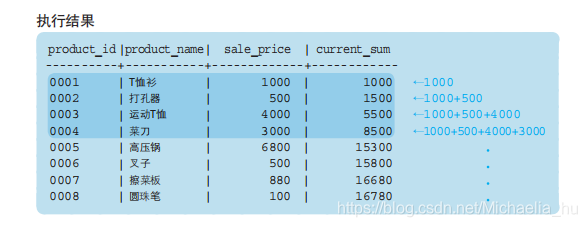
在ORDER子句后使用ROWS 2 PRECEDING将汇总对象限定为 最靠近的前3行(包括自己)。
PRECEDING替换为FOLLOWING表示 最靠近的后三行(包括自己)
-
GROUPING
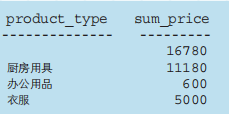
与CASE子句一起使用:
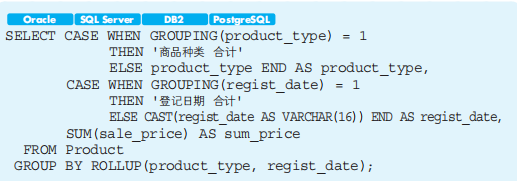
结果:
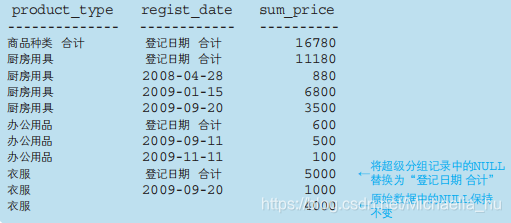
CUBE:同时得出合计与小计,会针对GROUP BY的每一个字段以及它们的排列组合得出小计。
如下为GROUP BY CUBE(product_type, regist_date);的结果,其实所有行一共分为四种情况。
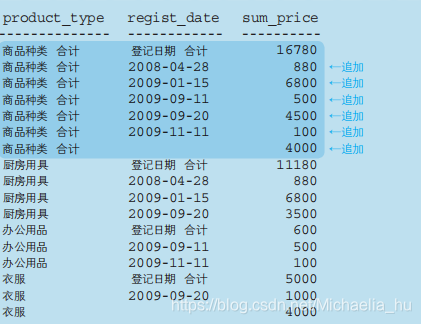
GROUPING SETS:从 ROLLUP 或者 CUBE 的结果中取出部分记录
如下图为GROUP BY GROUPING SETS (product_type, regist_date);的结果,其中没有GROUP BY(product_type, regist_date)行也没有总计行。














 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









