






如何获取特定 HIVE 库的元数据信息如其所有分区表和所有分区
1. 问题背景
有时我们需要获取特定 HIVE 库下所有分区表,或者所有分区表的所有分区,以便执行进一步的操作,比如通过 使用 HIVE 命令 MSCK REPAIR TABLE table_name sync partitions 修复 HIVE 元数据与 HDFS 数据在分区上的不一致性。
怎么获取这些 hms 元数据呢?
2. 获取 HMS 元数据的方案概述
获取 HMS 元数据,大体有以下几种方案:
2.1 执行 hive sql 命令,并基于 hive sql 的返回结果,解析获取 hms元数据
相关的 hive sql 命令有:
show databases;
show tables;
show tables like table_name_regexp;
show create table xxx;
DESCRIBE DATABASE EXTENDED db_name;
DESCRIBE EXTENDED|FORMATTED db_name.table_name;
DESCRIBE EXTENDED|FORMATTED db_name.table_name PARTITION partition_spec;
2.2 查询 hive 库对应的 hdfs 目录的结构信息,并基于这些结构信息,解析获取 hms 元数据
- hdfs 目录的结构信息,包括子目录和文件名等信息,解析这些信息可以获取 HIVE 库名,表名,分区名,分区值等 hms 元数据信息。
- 比如如果某个库中,所有分区表的分区字段名都是 part_date 且分区值都是8位数字如20230101,则可以通过如下 hdfs 命令结合 awk 命令,解析获取该hive库下所有分区表的表名:
hdfs dfs -ls -R hdfs:///user/hundsun/dap/hive | egrep part_date=[0-9]{8}$ |awk -F '/' 'BEGIN { OFS="." ;}{print $8,$9}' | uniq
2.3 直接访问 hms 底层的 rdbms 数据库,并执行sql查询获取 hms 元数据
- hms 底层的元数据信息,都是保存在 rdbms s数据库如mysql中的,所以我们也可以直接访问 hms 底层的 rdbms 数据库,并执行sql查询获取 hms 元数据;
- 访问 hms 数据库并执行sql,以获取指定 HIVE 库下所有分区表,或指定HIVE库下所有分区表的所有分区,其示例命令如下:
# 获取指定HIVE库下所有分区表-访问 hms 数据库并执行sql:
select distinct d.NAME,t.TBL_NAME
from tbls t join dbs d join partitions p
on t.DB_ID=d.DB_ID and t.TBL_ID=p.TBL_ID
where d.name in ("hs_sr","hs_ods","hs_mid");
# 获取指定HIVE库下所有分区表的所有分区-访问 hms 数据库并执行sql:
select d.NAME,t.TBL_NAME,p.PART_NAME
from tbls t join dbs d join partitions p
on t.DB_ID=d.DB_ID and t.TBL_ID=p.TBL_ID
where d.name in ("hs_sr","hs_ods","hs_mid");
3 hms 元数据库的相关信息
- 在 hms 元数据服务底层的 hms 元数据库中,保存了 hive 库/表/分区等相关元数据信息;
- hms 元数据库的 url/数据库名/用户名/密码等信息,可以咨询集群管理员获取,其中数据库名一般默认是hive,用户名一般默认也是hive;在 cdh/cdp大数据平台中,也可以使用如下 curl 命令访问 CM API 获取: curl -u admin_uname:admin_pass “http://cm_server_host:7180/api/v19/cm/deployment”,该命令中的 admin_uname:admin_pass 是 cm 管理员的用户名和密码,其默认值可以在 CM server 节点的配置文件 /etc/cloudera-scm-server/db.properties 中获取(当 cm 和 hms 使用同一个 rdbms 数据库实例时,有时 cm 管理员也可以直接查询 hms 的元数据库 hive);
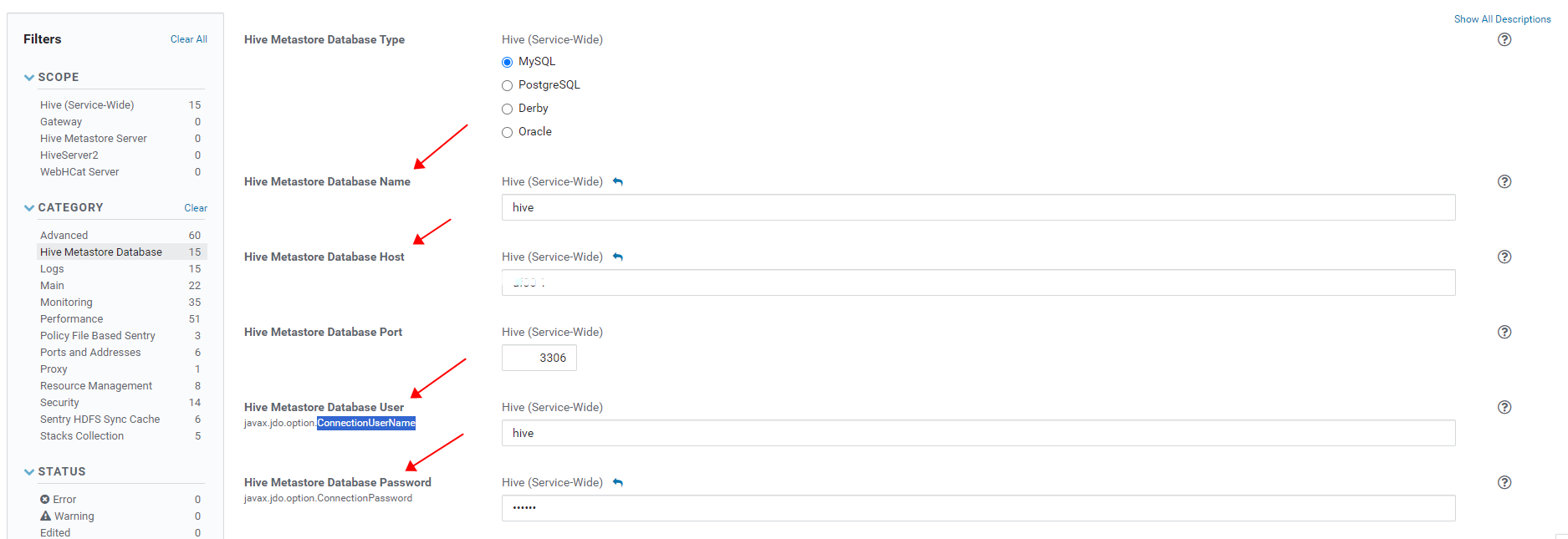
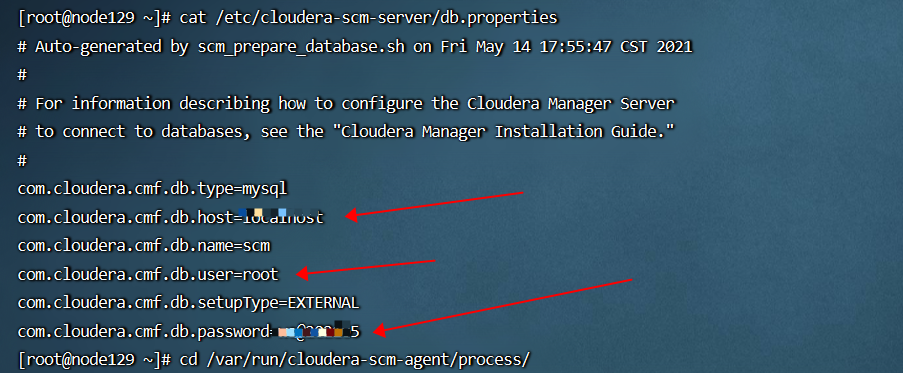

- hms 元数据库 rdmbs中,一些核心关键的表有 dbs,tbls,PARTITIONS,SDS 等,其相关信息如下:
- table "dbs" stores the information of hive databases;
- table "TBLS" stores the information of Hive tables;
- table "PARTITIONS" stores the information of Hive table partitions;
- table "SDS" stores the information of storage location, input and output formats, SERDE etc;
- table hive.dbs has below important columns:DB_ID,NAME,DB_LOCATION_URI;
- tablet hive.bls has below important column:TBL_ID,DB_ID,SD_ID,TBL_NAME;
- table hive.partitions has below important column:PART_ID,PART_NAME,SD_ID,TBL_ID;
- table hive.sds has below important column:SD_ID,LOCATION;
- Both table "TBLS" and "PARTITIONS" have a foreign key referencing to SDS(SD_ID);
















 1187
1187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











