







前言
上一篇文章已经讲述了RocksDB的基础概念,本文趁热打铁,将上文留下的作业以及RocksDB的基本操作集中说明一下,既帮助大家巩固下上文的概念,又为后文的高级操作以及特性打下基础。
总体来说,RocksDB的基础操作和LSM tree的基础操作基本相同,但是RocksDB在标准的LSM tree方案的基础上进行了定制化的优化,以支持自身的各种功能,下面就一起来看一下RocksDB的各种基本操作。
正文
写流程:
rocksdb写入时,直接以append方式写到WAL文件以及memtable,随即返回,因此非常快速。memtable达到一定阈值后切换为Immutable Memtable,只能读不能写。
Immutable memtable触发阈值后,后台Flush线程负责按照时间顺序将Immutable Memtable刷盘 生成Level 0 SST,Level 0 SST触发阈值后,经合并操作(compaction)生成level 1 SST,level 1 SST 合并操作生成level 2 SST,以此类推,生成level n SST。流程如下:
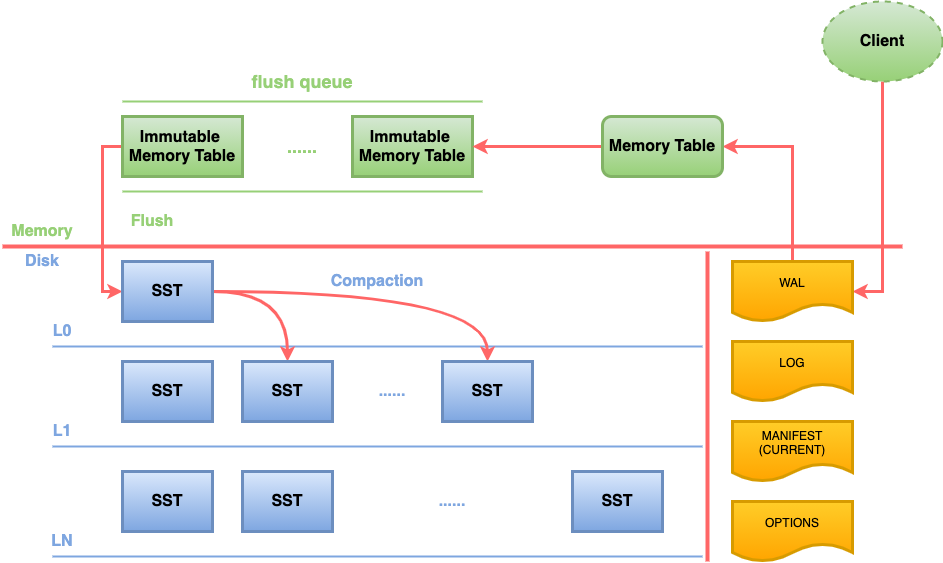
读流程:
按照 memtable --> Level 0 SST–> Level 1 SST --> … -> Level n SST的顺序读取数据。这和记录的新旧顺序是一的。因此只要在当前级别找到记录,就可以返回。流程如下:

Flush流程
上一章节讲述了Flush的定义,下面来讲一下Flush的具体流程:
简单来说在RocksDB中,每一个ColumnFamily都有自己的Memtable,当Memtable超过固定大小之后(或者WAL文件超过限制),它将会被设置为Immutable Memtable,然后会有后台的线程启动来刷新这个Immutable Memtable到磁盘(SST)。
在下面这几种条件下RocksDB会flush Memtable到磁盘:
-
当某一个Memtable的大小超过write_buffer_size
-
当所有的Memtable的大小超过db_write_buffer_size
-
当WAL文件的大小超过max_total_wal_size,我们需要清理WAL,因此此时我们需要将此WAL对应的数据都刷新到磁盘,也是刷新Memtable
Compaction操作
上一章节讲述了Compaction操作的定义,下面来讲一下Compaction操作的具体作用:
-
数据合并迁移:首先当上层level的sst文件数量或者大小达到阈值时,就会触发指定的sst文件的合并并迁移到下一层。每一层都会检查是否需要进行compaction,直到数据迁移到最下层
-
数据真删:LSM树的特点决定数据的修改和删除都不是即时的真删,而是写入一条新的数据进行冲抵。这些数据只会在compaction时才会真正删除(HBase是在major compaction中才会删除,minor compaction不会进行真删),所以compaction能释放空间,减少LSM树的空间放大,但是代价就是写放大,需要根据业务场景要求通过参数来调整两者之间的关系,平衡业务与性能。
-
冷热数据管理:RocksDB的数据流向是从Memtable到level 0 最后到 level N,所以数据查询时也是通过这个路径进行的。由于业务上查询大多是热数据的查询,所以数据的冷热管理就显得很必要,能很大程度上提高查询效率;而且由于各个level的sst文件可以使用不同的压缩算法,所以可以根据自己的业务需求进行压缩算法的配置,达到最佳性能。
LSM tree相关的经典压缩算法有下面几种:经典Leveled,Tiered,Tiered+Leveled,Leveled-N,FIFO。除了这些,RocksDB还额外实现了Tiered+Leveled和termed Level,Tiered termed Universal,FIFO。这些算法各有各的特点,适用于不同的场景,不同的 compaction 算法,可以在空间放大、读放大和写放大之间这三个LSM tree的"副作用"中进行取舍,以适应特定的业务场景。大家可以按需选择,如果没有特殊需求,开箱即用即可。至于每一种压缩算法的具体方式以及实现将会在高级特性篇进行讲解。
Compression操作
上一章节讲述了Compression操作的定义,下面来讲一下Compression的具体操作:
使用options.compression来指定使用的压缩方法。默认是Snappy。但是大多数情况下LZ4总是比Snappy好。之所以把Snappy作为默认的压缩方法,是为了与旧版本保持兼容。LZ4/Snappy是轻量压缩,所以在CPU使用率和存储空间之间能取得一个较好的平衡。
如果你想要进一步减少存储的使用并且你有一些空闲的CPU,你可以尝试设置options.bottommost_compression来使用一个更加重量级的压缩。最底层会使用这个方式进行压缩。通常最底层会保存大部分的数据,所以用户通常会选择偏向空间的设定,而不是花费cpu在各个层压缩所有数据。我们推荐使用ZSTD。如果没有,Zlib是第二选择。
如果你有大量空闲CPU并且希望同时减少空间和写放大,把options.compression设置为重量级的压缩方法,所有层级都生效。推荐使用ZSTD,如果没有就用Zlib
当然也可以通过一个已经过期的遗留选项options.compression_per_level,你可以有更好的控制每一层的压缩方式。当这个选项被使用的时候,options.compression不会再生效,但是正常情况下这个是不必要的,除非你有极特殊的需求或者性能优化要求。
最后可以通过把BlockBasedTableOptions.enable_index_compression设置为false来关闭索引的压缩。
Ingest操作
上一章节讲述了Ingest操作的定义,下面来讲一下Ingest的具体操作。Ingest实现上主要是两部分:创建SST文件和导入SST文件:
创建SST文件
创建SST文件的过程比较简单,创建了一个SstFileWriter对象之后,就可以打开一个文件,插入对应的数据,然后关闭文件即可。 写文件的过程比较简单,但是要注意下面三点:
-
传给SstFileWriter的Options会被用于指定表类型,压缩选项等,用于创建sst文件。
-
传入SstFileWriter的Comparator必须与之后导入这个SST文件的DB的Comparator绝对一致。
-
行必须严格按照增序插入
导入SST文件
导入SST文件也非常简单,需要做的只是调用IngestExternalFile()然后把文件地址封装成vector以及相关的options传入参数即可。下面是IngestExternalFile()的实现逻辑:
-
把文件拷贝,或者链接到DB的目录。
-
阻塞DB的写入(而不是跳过),因为我们必须保证db状态的一致性,所以我们必须确保,我们能给即将导入的文件里的所有key都安全地分配正确的序列号。
-
如果文件的key覆盖了memtable的键范围,把memtable进行flush操作。
-
把文件安排到LSM树的最合适的层级。
-
给文件赋值一个全局序列号。
-
重新启动DB的写操作。
为了减少compaction的压力,我们总是想将目标的sst文件写入最合适的层级,即合适写入的最低层级,下面三个条件作为约束可以选出合适的层级:
-
文件可以安排在这个层
-
这个文件的key的范围不会覆盖上面任何一层的数据
-
这个文件的key的范围不会覆盖当前层正在进行压缩
另外,5.5以后的新版本的RocksDB的IngestExternalFile加载一个外部SST文件列表的时候,支持下层导入,意思是如果ingest_behind为true,那么重复的key会被跳过。在这种模式下,我们总是导入到最底层。文件中重复的key会被跳过,而不是覆盖已经存在的key。
总结
上面的基础操作中可以看出来,RocksDB的各种操作是围绕着LSM tree的特性展开的,各种优化点也是为了平衡LSM tree的读放大,写放大以及空间放大三个副作用而设计的。
现在看来这三个放大更像数据库的CAP,不能同时解决,只能根据业务场景来解决主要矛盾,尽量减少次要矛盾,至于具体的方法,会在后续的高级特性中详细讲述。














 2478
2478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









