







安装sbt
本文方法有些繁琐,可以查看github最新更新:用sbt编译spark源码
linux版本:CentOS6.7
sbt: 0.13.9
Spark中没有自带sbt,需要手动安装sbt,我的方法是下载sbt-launch.jar,然后将源改为国内源(aliyun),我选择将sbt安装在/usr/local/sbt中。
$sudo mkdir /usr/local/sbt
$sudo chown -R hadoop /usr/local/sbt #username is hadoop.
$cd /usr/local/sbt
$mkdir sbtlaunch #store sbt-launch.jar1.下载sbt-launch.jar,并存放至/usr/local/sbt/sbtlaunch
$cd /usr/local/sbt/sbtlaunch
$wget https://repo.typesafe.com/typesafe/ivy-releases/org.scala-sbt/sbt-launch/0.13.9/sbt-launch.jar -O ./sbt-launch.jar #download sbt-launch.jar
$unzip -q ./sbt-launch.jar #解压
$ 2.需要修改其中的./sbt/sbt.boot.properties文件,将[repositories]处修改为如下内容:
即增加一条aliyun-nexus的镜像。
$cd /usr/local/sbt/sbtlaunch
$vim ./sbt/sbt.boot.properties修改为如下
[repositories]
local
aliyun-nexus: http://maven.aliyun.com/nexus/content/groups/public/
jcenter: https://jcenter.bintray.com/
typesafe-ivy-releases: https://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
maven-central
3.删除原来的sbt-launch.文件,然后重新打包
$rm ./sbt-launch.jar #delete the old jar
$jar -cfM ./sbt-launch.jar . #create new jar 4.在/usr/local/sbt目录下创建sbt脚本文件并赋予可执行权限,来执行sbt-launch.jar
$cd /usr/lcoal/sbt
$vim ./sbt #create sbt script添加如下内容:
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname`/sbt-launch.jar "$@" #dirname为路径名 my dirname : /usr/local/sbt/sbtlaunch
5.保存后,为./sbt增加可执行权限:
$chmod u+x ./sbt6.最后检验sbt是否可用
$./sbt sbt-version这一步请耐心等待,不要怀疑我天朝的网速,笔者出现第一条信息时等待了约10分钟,只要得到如下版本信息就没有问题:

7.创建hello world项目,并编译,打包,运行。
7.1 hello world的目录结构是:
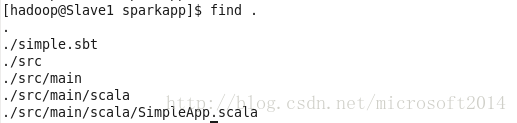
代码如下:
$mkdir ~/simpleapp
$mkdir ~/simpleapp/src
$mkdir ~/simpleapp/src/main
$mkdir ~/simpleapp/src/main/scala
$vim SimpleApp.scala #内容如下SimpleApp.scala
object SimpleApp{
def main(args: Array[String]){
println("Hello World!")
}
}7.2 创建simple.sbt
$cd ~/simpleapp
$vim ./simple.sbt #内容如下simple.sbt内容如下:每一行之间空一行。scala version 和 spark版本信息根据所安装的spark所写。笔者安装的是spark2.1.0和scala 2.11.8。
name :="Simple Project"
version :="1.0"
scalaVersion := "2.11.8"
libraryDependencies +="org.apache.spark" %% "spark-core" % "2.1.0"
7.3配置环境变量,编译和运行。
$vim ~/.bashrc #在开头添加如下内容:export PATH=/usr/local/sbt:$PATH
$source ~/.bashrc #使之生效
$cd ~/simpleapp
$sbt compile #编译,等待很久,天朝龟速
$sbt package #打包
$/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar #将生成的jar包通过spark-summit提交到spark中执行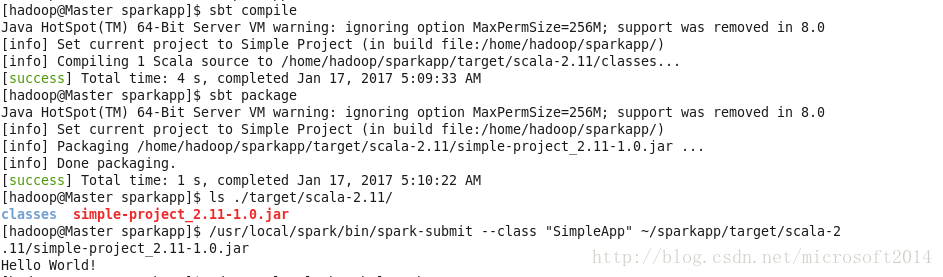

















 2067
2067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









