







19.1 C++STL标准模板库大局观-STL总述、发展史、组成与数据结构谈
19.2 C++STL标准模板库大局观-容器分类与array、vector容器精解
19.3 C++STL标准模板库大局观-容器的说明和简单应用例续
19.4 C++STL标准模板库大局观-分配器简介、使用与工作原理说
19.5 C++STL标准模板库大局观-迭代器的概念和分类
19.6 C++STL标准模板库大局观-算法简介、内部处理与使用范例
19.7 C++STL标准模板库大局观-函数对象回顾、系统函数对象与范例
19.8 C++STL标准模板库大局观-适配器概念、分类、范例与总结
2.容器分类与array、vector容器精解
上一节把STL的组成部分做了一个划分:容器、迭代器、算法(函数)、分配器(用于分配内存)、其他(包括适配器、仿函数/函数对象等)。本节先从容器谈起。
2.1 容器的分类
STL中有许多容器,如最常用的vector、list、map等,如果常读别人的代码,也能够发现,在别人的代码中也会经常用到这些容器。
容器是做什么的?当然是保存数据的,用于管理一大群元素,少则几十个,多则几百万个甚至更多元素都是可能的。
STL中的容器可以分成三类。
(1)顺序容器
顺序容器(Sequence Containers)的意思就是放进去的时候把这个元素(放进容器中的数据称为容器中的元素)排在哪里,它就在哪,顺序容器(Sequence Containers)的意思就是放进去的时候把这个元素(放进容器中的数据称为容器中的元素)排在哪里,它就在哪里,例如把它排在最前面,那它就会一直在最前面待着,这就是顺序容器。如array、vector、deque、list、forward_list等容器都是顺序容器。
(2)关联容器
这种容器,它的每一个元素都是一个键值(key/value)对
上面提到的键值对中的“值”是一个字符串(姓名)。试想,如果键值对中的“值”是一个结构(不仅仅是一个字符串),比如说结构里面有姓名、身高、年龄、体重等,那么就可以通过学号这个“键(key)”,把该学生的完整信息“值(value)”获取到,非常方便。
这种容器的内部一般是使用一种称为“树”的数据结构实现数据的存储。刚刚谈到顺序容器时笔者说过,顺序容器是那种放进去的时候把这个元素排在哪里,它就在哪里。而关联容器则不同,把一个元素放到关联容器里去的时候,该关联容器会根据一些规则,如根据key,把这个元素自动放到某个位置。容易想象,这种自动放到某个位置的做法,肯定是为了方便将来快速进行数据查询所采用的技术手段。换句话说,程序员不能控制元素插入的位置,只能控制插入的内容。set、map、multiset、multimap等都属于关联容器(Associative Containers)。
(3)无序容器
这种容器是C++11里推出的容器,按照官方的说法,这种容器里面的元素位置不重要,唯一重要的是这个元素是否在这个集合内。一般插入这种元素的时候也不需要给要插入的元素安排位置,这种容器也是会自动给元素安排位置。所以,根据这种容器的特点,无序容器(Unordered Containers)应该属于一种关联容器,只不过权威的资料上把它单独分出来。
“无序”这个词有什么说法呢?可以这样理解,随着往这个容器中增加的元素数量的增多,很可能某个元素在容器中的位置会发生改变,这是由该容器内部的算法决定的。因此“无序容器”这种名字还是挺贴切的。无序容器内部一般是用哈希表这种数据结构来实现的。
例如,unordered_set、unordered_multiset、unordered_map、unordered_multimap等都是无序容器。
下图所示代表一个无序容器。该图体现了无序容器内部采用哈希表这种数据结构来实现数据的存储。
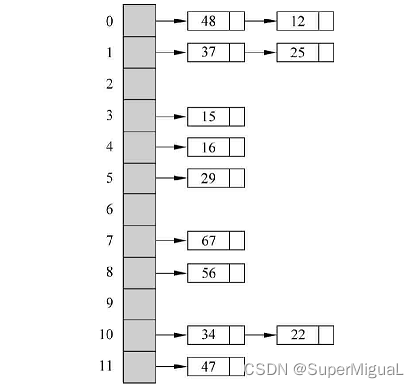
上图左侧的深色方块一般称为篮子(或者叫桶),想象成装水果的篮子。其中的48、12,这些就是属于篮子上挂的元素(或者篮子中装的元素)。有的篮子是空的,有的篮子上挂一个元素,有的篮子上挂两个元素。这种容器内部有一个算法,把程序员插入的元素通过一定的计算得到一个数字,通过容器内部算法找到一个该数字对应的篮子,例如找到了编号为0的篮子,就把这个元素挂到这个篮子上。如果有第二个元素,通过一定的计算得到另外一个数字,通过容器内部算法,找到的该数字对应的篮子编号也为0,那么因为编号为0的篮子上已经有一个元素了,这个新元素就挂在老元素的后面。显然,相同的篮子上挂的元素越多,查找的时候效率越低。
所以,当这种容器中元素的个数大于或等于篮子个数的时候,这个容器会扩充篮子的数量,例如扩充为原来篮子个数的2倍(从12个扩充到24个),然后,根据这24个篮子重新计算容器中的元素适合哪个篮子并重新挂到对应的篮子上。
另外,刚才笔者说过:“无序容器也应该属于一种关联容器”,所以也可以认为,关联容器内部的实现不但可以用树,也可以用哈希表实现,如hash_set、hash_map、hash_multiset、hash_multimap等关联容器,都是采用哈希表技术来实现的。
官方有一句话:C++标准并没有规定任何容器必须使用任何特定的实现手段。但一般来讲,都有规律可循,例如map用的是树这种数据结构存储数据,hash_开头的容器一般用的是哈希表这种数据结构存储数据。
2.2 容器的说明和简单应用
(1)array
array是一个顺序容器,其实是一个数组,所以它的空间是连续的,大小是固定的,刚开始时申请多大,就是多大,不能增加它的大小。
array这种容器数据存储结构的感觉如图所示。
写一个针对array容器的范例

#include <array>
#include <iostream>
#include <string>
using namespace std;
int main()
{
array<string, 5> mystring = { "I", "Love1Love2Love3Love4Love5Love6Love7", "China" };//定义包
cout << "mystring.size() = " << mystring.size() << endl;
mystring[0] = "It it very long~~~~~~~~~~~~~~~~long~~~~~~~~~~~~~~~~long";
mystring[4] = "It it very long~~~~~~~~~~~~~~~~long~~~~~~~~~~~~~~~~long";
cout << "sizeof(string) = " << sizeof(string) << endl;
for (size_t i = 0; i < mystring.size(); ++i)
{
const char * p = mystring[i].c_str();
cout << "---------------------begin---------------------" << endl;
cout << "数组元素值 = " << p << endl; //用下标访问,从0开始
printf("对象地址 = %p\n", &mystring[i]);
printf("指向的字符串地址 = % p\n", p);
cout << "---------------------end-----------------------" << endl;
}
const char * p1 = "Love1Love2Love3Love4Love5Love6Love7";
const char * p2 = "Love1Love2Love3Love4Love5Love6Love7";
printf("指向字符串的p1地址 = % p1\n", p1);
printf("指向字符串的p1地址 = % p2\n", p1);
return 0;
}
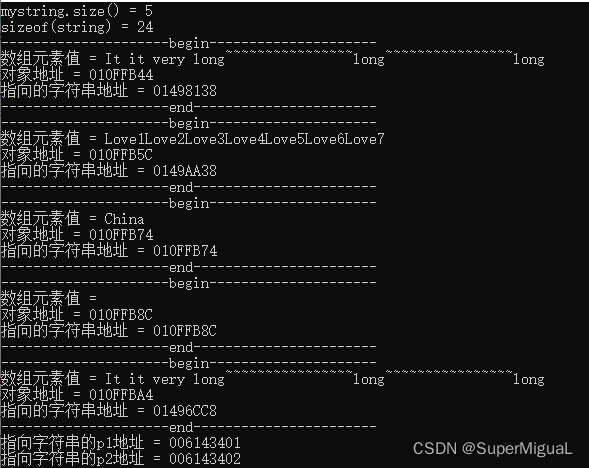
注意观察结果,得到一些结论:
(2)p1和p2指向的地址相同,也就是说都指向相同的常量字符串,而常量字符串在内存中是有一个特定地址的。
通过上面的结果可以绘制出一张程序运行后的结果示意图,如图所示。
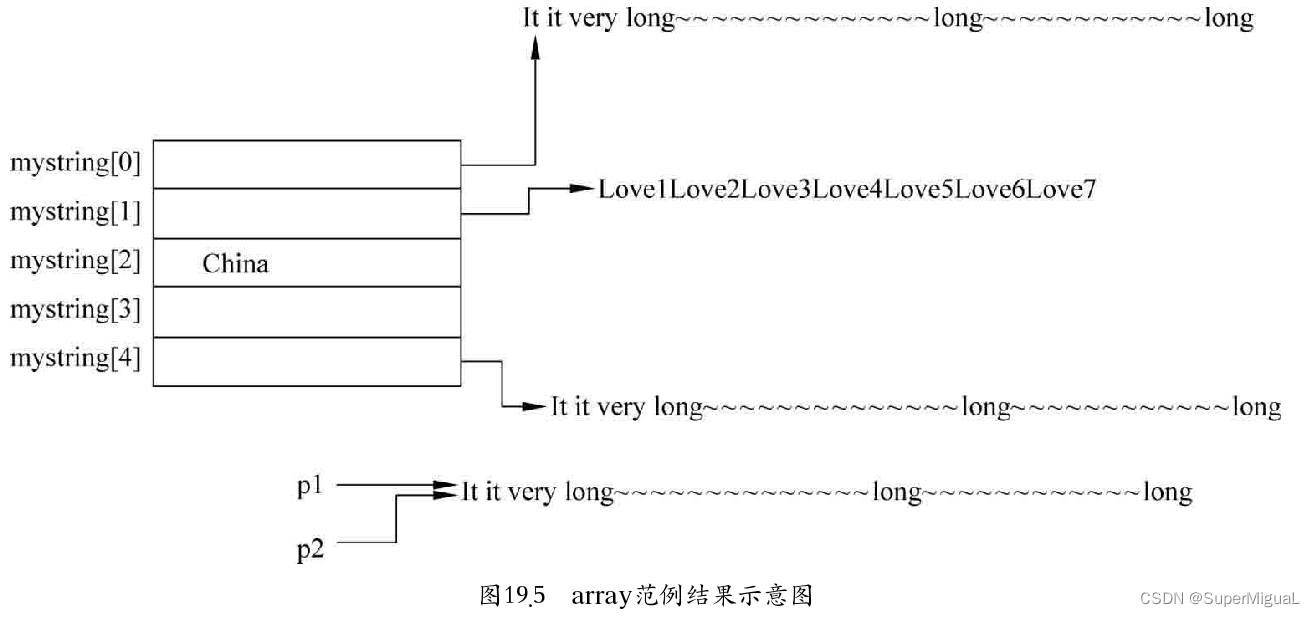
从上图中可以看到,p1和p2指向同一个字符串常量。虽然mystring[0]和mystring[3]指向的内容与p1、p2所指向的字符串内容相同,但是,mystring[0]和mystring[3]分别指向了不同位置的该字符串(这表示在内存中有该字符串的多份复制)。而mystring[2]中指向的是China字符串,但因为China字符串的内容比较短,所以China字符串的首地址就在mystring[2]这个对象地址的后面第4个位置开始处。
(2)vector
vector也是一个顺序容器,这种容器数据存储结构的感觉如图19.6所示。
从下图可以看到,vector是一端(尾端)开口的,通过这个开口,可以进行元素(数据)的插入和删除。最左端的起始端是封死不能动的。通过这个图有几点感受:

(1)这个容器往尾端加入元素和从尾端删除元素都应该比较快速。
(2)但是要往起始端或者往中间插入元素,那么不难想象,所有塞进来这个元素所在位置以及该位置后面位置的元素都得往后移动来保持这个相对顺序。这可能会涉及元素的析构和重新构造,所以这种插入操作对效率上会产生不小的影响。
(3)感觉查找速度不会太快,似乎要沿着元素存储时的顺序一直往下查找。
所以这个容器专门有一个接口(成员函数)push_back,用于往容器尾端插入元素。看看如下范例:
class A
{
public:
int m_i;
A(int tmpv) :m_i(tmpv) //构造函数
{
cout << "A::A()构造函数执行" << endl;
}
A(const A& tmpA)
{
m_i = tmpA.m_i;
cout << "A::A()拷贝构造函数执行" << endl;
}
~A()
{
cout << "A::~A()析构函数执行" << endl;
}
};
int main ()
{
vector<A> myveca;
for (int i = 0; i < 5; ++i)
{
cout << "-------------begin--------------" << endl;
myveca.push_back(A(i));//往容器末尾增加元素
cout << "-------------end--------------" << endl;
}
}
在push_back行设置断点并进行跟踪调试。在前三次执行for循环后,结果如下:

从上面的结果可以看到,每次for循环多执行了一次拷贝构造函数和一次析构函数,这就比较坑人了。为什么会是这种结果呢?
因为从图可以看到,vector容器的内存元素是挨在一起的,vector容器有个“空间”的概念,每一个空间可以装一个元素,这个空间就好像一个抽屉,抽屉中有多个格子,每个格子都能装一个物品,每个格子就是一个空间。
当装第一个元素的时候,这个容器分配出一个空间,正好把这个元素装进去了。
当装第二个元素的时候,就没有多余的空间了,这时这个容器就会把空间增长以便容纳更多元素。有的资料说这个空间是按2倍增长,这不一定,不同的厂商有不同的实现。假设空间增长后变成了2,那么可以插入第二个元素了,但vector的空间是连续的,这个空间一增长,就要找一块新的足以容纳下当前所有元素的内存,把所有元素搬到新内存去,这一搬就很容易想到,老的容器中元素要析构,这些搬来的元素都要重新执行构造函数来构造。这显然非常影响程序执行效率。
容器里面有多少个元素可以用size来查看,而容器的空间可以用capacity来查看。根据上面的描述,可以得到一个结论:capacity的结果一定不会小于size,也就是说容器中空间的数量一定不会比元素数量少。
在main主函数的for循环中增加一些输出信息用的代码,现在完整的main主函数中的代码如下:
for (int i = 0; i < 5; ++i)
{
cout << "-------------begin--------------" << endl;
cout << "容器插入元素之前size = " << myveca.size() << endl;
cout << "容器插入元素之前capacity = " << myveca.capacity() << endl;
myveca.push_back(A(i));//往容器末尾增加元素
cout << "容器插入元素之后size = " << myveca.size() << endl;
cout << "容器插入元素之后capacity = " << myveca.capacity() << endl;
cout << "-------------end--------------" << endl;
}
执行起来,观察结果,可以看到,5次for循环,容器插入元素后capacity的值分别是1、2、3、4、6(注意没有5)。
可以看到,vector的capacity值每次的增长非常谨慎,它增长太多会耗费大量连续内存(因为vector内存空间是连续的),但增长太少也麻烦,因为要大量地搬移元素,构造、析构元素变得非常频繁。
怎么验证vector容器的空间是连续的呢?很简单,用下标来访问数组元素即可验证。vector容器支持下标,在main主函数中原有代码的后面继续增加如下代码:
cout << "打印一下每个元素的地址看看--------------" << endl;
for (int i = 0; i < 5; ++i)
{
printf("下标为%d的元素的地址是%p,m_i=%d\n", i, &myveca[i], myveca[i].m_i);
}
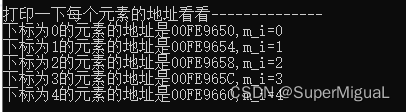
从输出结果中不难看到,每个元素的地址都间隔4字节,而容器中的类A对象的大小正好是4字节,这充分证明了容器中的元素是紧挨在一起的。
如果从vector容器的中间删除一个元素会怎样?在main主函数中原有代码的后面继续增加如下代码:
cout << "删除一个元素看看--------------" << endl;
int icount = 0;
for (auto pos = myveca.begin(); pos != myveca.end(); ++pos)
{
icount++;
if (icount == 2) //把m_i == 1的对象删除
{
myveca.erase(pos);
break;
}
}
for (int i = 0; i < 4; ++i)
{
printf("下标为%d的元素的地址是%p,m_i=%d\n", i, &myveca[i], myveca[i].m_i);
}
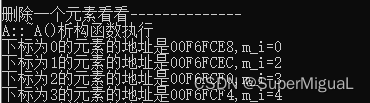
通过结果可以看到,删除了一个元素,导致执行了一次析构函数,m_i为1的元素确实已经被删除,然后所有后续元素的内存往前动了(至少从表面上看元素对象是往前移动了),但并没有执行这些移动了的对象的任何构造和析构函数,这说明编译器内部有自己的处理,这个处理就很好。
继续,再插入一个元素看看。在main主函数中原有代码的后面继续增加如下代码:
cout << "再次插入一个元素看看--------------" << endl;
icount = 0;
for (auto pos = myveca.begin(); pos != myveca.end(); ++pos)
{
icount++;
if (icount == 2)
{
myveca.insert(pos, A(10));
break;
}
}
for (int i = 0; i < 5; ++i)
{
printf("下标为%d的元素的地址是%p,m_i=%d\n", i, &myveca[i], myveca[i].m_i);
}
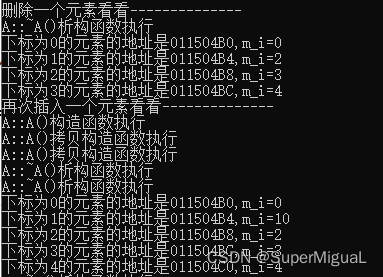
通过结果可以看到,向vector容器中间插入元素会导致后续的一些元素都被析构和重新构造,但是按道理来讲后面三个元素应该被析构三次,估计同样是系统内部有处理,节省了一次构造。但不管怎么说,从中间插入元素代价都很大。
通过这些演示可以看到,如果事先不知道有多少个元素要往vector里插入,需要的时候就往里插入一个,那么显然vector容器的运行效率应该不会高——频繁大量地构造、析构、寻找新的整块内存,这都是很让开发者忌讳的。
但是,如果事先知道整个程序运行中这个vector容器里最多也不会超过多少个元素,例如程序员知道最多也不会超过10个元素,那就让capacity事先等于10(在容器中预留10个空间),这样往容器中插入元素时,只要不超过10个,那么就不需要频繁地构造和析构元素对象。换句话说,就不需要寻找新的整块内存进行元素搬迁了。
在main主函数的前面,语句行vector<A>myveca;的后面,插入下面几行代码:
cout << "myveca.capacity()=" << myveca.capacity() << endl;
cout << "myveca.size()=" << myveca.size() << endl;
myveca.reserve(10);//为容器预留空间,前提是知道该容器最多会容纳多少元素
cout << "myveca.capacity()=" << myveca.capacity() << endl;
cout << "myveca.size()=" << myveca.size() << endl;
通过结果可以看到,刚开始的时候,容器的capacity(空间)为0,而后通过reserve把容器的capacity设置为10。这就相当于容器预留了10个空间,可以预计,只要后续插入的元素数量不超过10个,那么就不会因为vector所需要的连续内存空间不足而导致整个容器元素的搬迁。既然容器中元素不会发生搬迁(迁移),所以根据结果也不难看到,例如开始的时候第二对begin和end之间是要执行一次构造函数、二次拷贝构造函数以及二次析构函数,而在这里改进之后,只需要执行一次构造函数、一次拷贝构造函数以及一次析构函数。所以,利用好capacity也能够提升vector容器的效率。















 859
859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









