






深度学习聚类技术在处理高维和非线性数据方面展现出了卓越的能力,它不仅继承了传统聚类算法的优势,还在自适应性和抗干扰性上有着显著的提升。这种技术通过深度神经网络的先进特征提取功能,能够自动识别和学习数据中的复杂结构,从而在无需人为干预的情况下,实现更精准的聚类效果。
例如,集成时空深度聚类(ISTDC)模型就是一个很好的例子,它结合了四种不同的算法和变分贝叶斯高斯混合模型(VBGMM)进行聚类,其在0-back和2-back任务中达到了98.0%的平均聚类准确率,这一成绩比现有技术提升了11.0%。
除了ISTDC模型之外,还有许多其他值得关注的深度学习聚类算法的新进展。我精选了近两年11篇相关顶会顶刊论文,并从中提取了一些创新点,希望能够激发大家的学术灵感。
关注公众号:AI前沿速递,获取跟多优质资源!
三篇论文详述
1、Clustering Propagation for Universal Medical Image Segmentation
方法
-
S2VNet框架:提出了一个名为S2VNet的通用框架,利用Slice-to-Volume传播统一自动和交互式医学图像分割。
-
基于聚类的分割技术:通过从之前切片的聚类结果初始化簇中心,充分利用体积数据的切片结构。
-
交互式分割:无需架构更改,通过从用户输入初始化质心,轻松适应交互式分割。
-
快速推理速度和降低内存消耗:与主流3D解决方案相比,S2VNet在推理速度和内存消耗方面有显著优势。
-
多类别交互:能够处理多类别交互,每种类别都用于初始化不同的质心。
-
实验验证:在三个基准测试(WORD、BTCV和AMOS)上进行实验,证明S2VNet在自动和交互式设置上都超越了特定任务的解决方案。
创新点
-
统一的模型和训练会话:S2VNet能够在单一模型和单一训练会话中处理自动医学图像分割(AMIS)和交互式医学图像分割(IMIS)。
-
基于2D网络的Slice-to-Volume传播:通过在不同切片之间传播更新后的簇中心,利用2D网络实现高效的知识传递。
-
交互式分割的适应性:S2VNet可以通过用户输入初始化簇中心,无需对架构进行修改,即可适应交互式分割。
-
多类别用户输入:S2VNet能够同时接受多类别的用户输入,每种类别初始化一个簇中心,实现多实例的并行细化。
-
诊断系统的潜力:S2VNet能够为多个病变/器官类别提供粗糙的分割结果,并通过精确的反馈进行细化,节省了在初始搜索病变/器官区域时的时间。
-
高效的计算资源利用:S2VNet通过重用质心,显著减轻了计算资源的负担,实现了更快的推理速度和更低的内存消耗。
-
鲁棒的网络推理:通过递归质心聚合策略,S2VNet能够收集历史质心并将其融合为单一向量,以提供更鲁棒的网络推理。
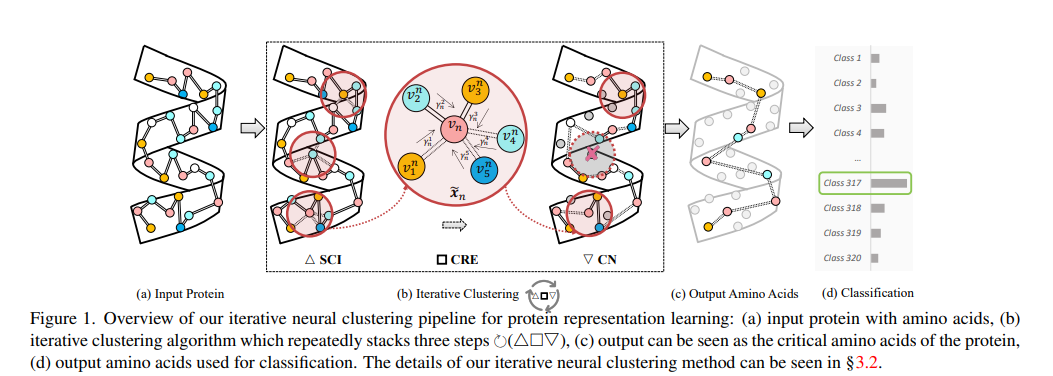
2、Clustering for Protein Representation Learning
方法
-
本文提出了一种神经聚类框架,用于蛋白质表示学习,旨在自动发现蛋白质的关键组成部分,同时考虑其一级和三级结构信息。
-
将蛋白质视为图,其中每个节点代表一个氨基酸,每条边代表氨基酸之间的空间或序列连接。
-
应用迭代聚类策略,根据节点的一维和三维位置将节点分组到不同的簇中,并为每个簇分配分数。
-
选择得分最高的簇,并使用它们的中心节点(medoid nodes)作为下一轮聚类的输入,通过迭代这一过程,获得蛋白质的层次化和信息丰富的表示。
-
在蛋白质相关的四个任务上进行评估:蛋白质折叠分类、酶反应分类、基因本体(Gene Ontology, GO)术语预测和酶委员会(Enzyme Commission, EC)编号预测。
创新点
-
关键氨基酸的识别:与以往方法不同,本文的方法强调并非所有氨基酸对蛋白质的折叠和活性都同等重要,而是通过聚类过程识别出对蛋白质形状和功能起决定性作用的关键氨基酸。
-
迭代聚类策略:通过迭代的聚类过程,逐步细化对蛋白质结构和功能有代表性氨基酸的搜索,每次迭代都包括球状聚类初始化(SCI)、聚类表示提取(CRE)和聚类提名(CN)三个步骤。
-
层次化表示学习:通过迭代过程,模型能够学习到从粗到细的蛋白质层次化表示,有助于更深入地理解蛋白质的复杂结构和功能。
-
多任务学习:所提出的方法在多个与蛋白质相关的任务上进行了评估,显示出其在不同领域的适用性和有效性。
-
结合1D和3D信息:在聚类过程中同时考虑了氨基酸的一级序列信息和三维空间结构信息,这有助于更全面地捕捉蛋白质的特征。
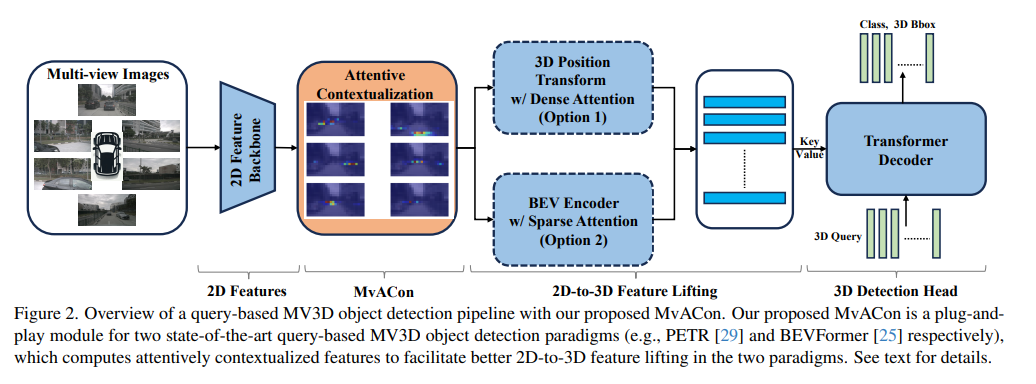
3、Multi-View Attentive Contextualization for Multi-View 3D Object Detection
方法
-
论文提出了一种名为Multi-View Attentive Contextualization (MvACon)的方法,用于改进基于查询的多视图3D (MV3D) 目标检测中的2D到3D特征提升。
-
MvACon通过一种表示密集但计算稀疏的注意力特征上下文化方案,解决了现有方法在高分辨率2D特征的密集注意力提升中的计算成本问题,以及在稀疏注意力提升中3D查询与多尺度2D特征的不足接地问题。
-
MvACon通过聚类注意力操作来上下文化原始特征图,该操作建立在最近提出的Patch-to-Cluster Attention (PaCa)方法之上。
-
在实验中,MvACon在nuScenes基准测试中使用BEVFormer及其3D可变形注意力(DFA3D)变体和PETR进行了彻底测试,显示出在位置、方向和速度预测方面的性能提升。
-
MvACon模块设计为与特定的2D到3D特征提升策略无关,易于集成到现有的MV3D目标检测框架中。
创新点
-
表示密集与计算稀疏的平衡:MvACon在保持表示密集的同时,通过计算稀疏的方式,有效地降低了计算成本。
-
聚类注意力机制:通过聚类注意力操作,MvACon能够捕捉到全局的场景级上下文,从而为MV3D目标检测提供了丰富的上下文信息。
-
跨方法的通用性:MvACon不仅适用于基于视角的解码器仅包含密集注意力的方法(如PETR),也适用于基于编码器-解码器的稀疏2D/3D可变形注意力方法(如BEVFormer和DFA3D),显示出良好的通用性。
-
性能提升:在nuScenes和Waymo-mini基准测试中,MvACon在多个查询基础上的MV3D目标检测器上显示出一致的性能提升,特别是在位置、方向和速度预测方面。
-
模块化设计:MvACon的模块化设计使其可以作为一个即插即用模块轻松集成到现有的MV3D目标检测框架中,提高了方法的灵活性和实用性。
-
细节分析:论文通过详细的可视化和定量分析,展示了MvACon如何在不同层次上改善特征提升过程,以及如何通过学习到的聚类上下文来提高检测结果的质量。
关注公众号:AI前沿速递,获取跟多优质资源!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









