



MIT何恺明团队为ARC(抽象推理语料库)基准测试提出全新思路:ARC本质是视觉问题。他们设计VARC框架,将这一通用AI试金石级的抽象推理任务,转化为图像到图像翻译问题,斩获亮眼成果。
1. 【导读】

论文标题:ARC Is a Vision Problem!
作者:Keya Hu、Ali Cy、Linlu Qiu、Xiaoman Delores Ding、Runqian Wang、Yeyin Eva Zhu、Jacob Andreas、Kaiming He
作者机构:MIT
论文来源:MIT何恺明团队
论文链接:https://arxiv.org/abs/2511.14761
项目链接:https://github.com/lillian039/VARC
2. 【论文速读】
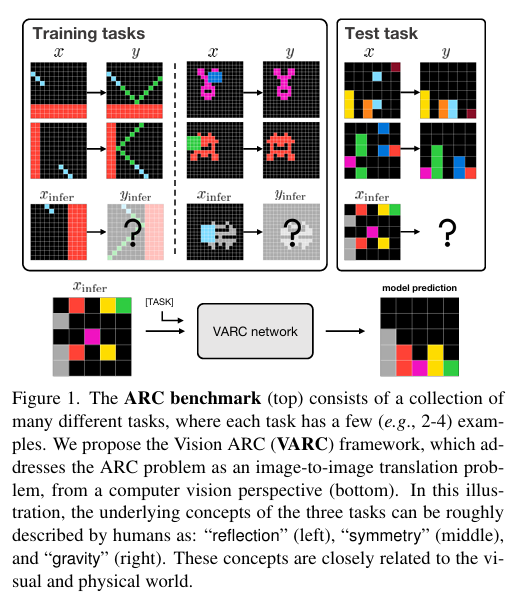
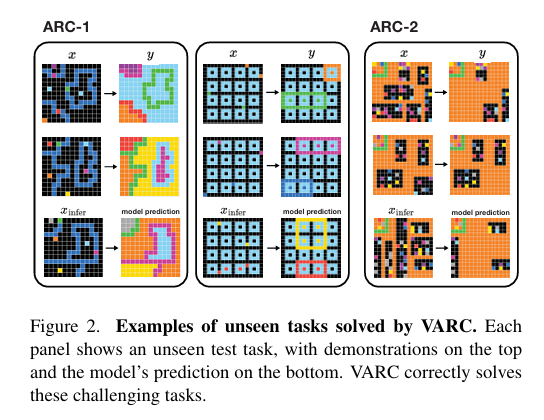
抽象推理语料库(ARC)旨在推动抽象推理这一人类智能基础领域的研究,现有方法多将其视为语言导向问题,采用大型语言模型(LLMs)或循环推理模型解决,却鲜少从视觉中心视角切入——而ARC中的谜题任务本质具有视觉属性。为此,研究团队将ARC构建为图像到图像翻译问题,引入“画布”表征输入以融入视觉先验,使其能像自然图像一样被处理,进而应用标准视觉架构(如普通视觉Transformer,ViT)实现图像到图像映射。该模型(命名为Vision ARC,VARC)仅基于ARC数据从头训练,并通过测试时训练实现对未见过任务的泛化。在ARC-1基准测试中,VARC准确率达60.4%,显著优于同样从头训练的现有方法,且结果与领先LLMs具有竞争力,同时缩小了与人类平均表现的差距。
3.【ARC难题:人类轻松搞定,AI却卡壳?视觉视角成破局新方向】
3.1 研究基石:ARC基准的核心定位与挑战
抽象推理语料库(ARC)是为推动抽象推理研究设计的基准,包含大量谜题式任务,每个任务仅含少量示例且遵循独特变换规则,需模型基于示例预测未见过任务的结果;人类能较好解决各类ARC任务,但当前主流机器学习系统仍难以应对这一挑战。
3.2 现有方案:两大主流思路的局限
- 语言模型(LLMs)主导:将ARC输入转为文本序列处理,依赖互联网规模预训练获取常识,虽表现有竞争力,但未契合ARC的视觉本质;
- 循环推理模型:仅基于ARC数据从头训练,通过迭代推理实现效果,虽摆脱大规模预训练依赖,却仍受语言建模思路启发,未突破非视觉框架。
3.3 关键缺口:视觉属性被忽视,新视角待挖掘
ARC谜题虽以视觉形式呈现,但现有研究极少将其视为视觉中心问题;实际上,ARC中的反射、对称、重力等核心概念,本质是视觉与物理属性,人类解决此类任务时,会结合从视觉世界获取的常识进行类比推理,这提示从视觉视角切入可能是突破ARC难题的重要方向。
点击阅读原文,获取更多论文信息
4.【ARC变“看图说话”:视觉视角下的任务定义与建模】
4.1 ARC问题定义:拆解“少样本、多任务”核心结构
ARC基准由数百个少样本(通常2-4个示例)推理任务构成,每个任务 T T T对应独特的变换规则,实现从输入 x x x到输出 y y y的映射( x x x和 y y y均为最大尺寸30×30的2D网格,每个位置含 C C C种颜色索引之一),具体拆解为以下核心组件:
- 任务基本单元:每个任务含演示集 D d e m o T = { ( x i , y i ) } i = 1 m D_{demo }^{T}=\{(x_{i}, y_{i})\}_{i=1}^{m} DdemoT={(xi,yi)}i=1m( m m m为2-4个演示对, x i x_i xi和 y i y_i yi均已知)与推理集 D i n f e r T = { ( x i , y i ) } i = 1 n D_{infer }^{T}=\{(x_{i}, y_{i})\}_{i=1}^{n} DinferT={(xi,yi)}i=1n( n n n为1-2个推理对);推理时仅提供 D d e m o T D_{demo }^{T} DdemoT和 x i n f e r ∈ D i n f e r T x_{infer }\in D_{infer }^{T} xinfer∈DinferT,需预测 y i n f e r y_{infer } yinfer。
- 训练集:记为 T t r a i n = { T i } i = 1 k T_{train }=\{T_{i}\}_{i=1}^{k} Ttrain={Ti}i=1k(ARC-1中 k = 400 k=400 k=400),仅用各任务 D d e m o T D_{demo }^{T} DdemoT训练模型, D i n f e r T D_{infer }^{T} DinferT仅用于验证。
- 测试集:记为
T
t
e
s
t
=
{
T
i
}
i
=
1
l
T_{test }=\{T_{i}\}_{i=1}^{l}
Ttest={Ti}i=1l,含训练时未见过的新任务;推理时提供新任务的
D
d
e
m
o
T
D_{demo }^{T}
DdemoT,需结合其预测
x
i
n
f
e
r
x_{infer }
xinfer的输出,支持通过测试时训练优化模型。

4.2 图像到图像翻译:将ARC转化为视觉经典任务
研究将每个ARC任务的推理过程构建为图像到图像翻译问题,采用逐像素分类思路(类似语义分割),具体形式化定义如下:
- 学习参数为 θ \theta θ的神经网络 f θ f_{\theta} fθ,输入为图像 x i x_{i} xi,并以任务 T T T的可学习嵌入(任务令牌)为条件。
- 网络输出为网格,每个位置代表一个类别分布,目标函数采用逐像素交叉熵损失:
L ( θ ) = E T , i [ D ( y i , f θ ( x i ∣ T ) ) ] \mathcal{L}(\theta)=\mathbb{E}_{T, i}\left[\mathcal{D}\left(y_{i}, f_{\theta}\left(x_{i} | T\right)\right)\right] L(θ)=ET,i[D(yi,fθ(xi∣T))]
其中 D \mathcal{D} D表示真实值 y i y_{i} yi与网络输出间的逐像素交叉熵损失。
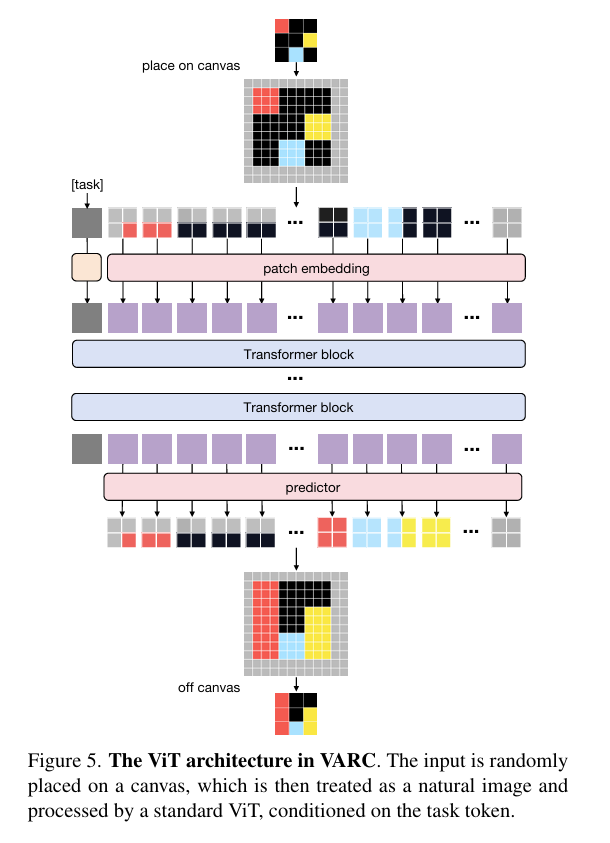
4.3 视觉建模:用“画布”与视觉先验解锁ARC
区别于传统ARC方法的离散令牌处理,研究基于视觉原生设计建模,核心包含以下关键策略:
-
画布(Canvas)设计:定义固定尺寸(如64×64)的画布,将原始输入变换后置于其上,画布背景设为第 C + 1 C+1 C+1种颜色;该设计支持灵活的几何变换,且当采用2×2补丁大小时,单个补丁可含多种颜色,理论上具有 O ( C 2 × 2 ) O(C^{2×2}) O(C2×2)的指数级基数,能减少过拟合并强化空间先验学习。
-
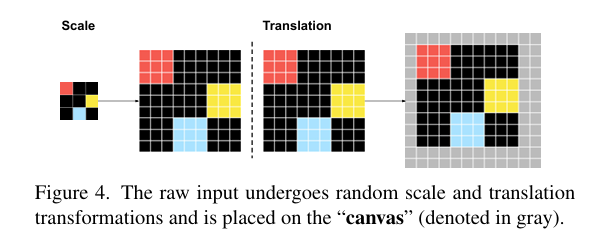
平移与尺度不变性增强:通过数据增广融入视觉先验:
- 尺度增广:随机将原始输入按整数比例 s s s缩放,每个像素复制为 s × s s×s s×s大小(类似最近邻插值);
- 平移增广:将缩放后的网格随机置于画布上,确保所有像素可见;增广能促使模型学习对视觉世界几何变换不变的底层映射。
-
视觉Transformer(ViT)应用:将画布分割为非重叠补丁(如2×2),经线性嵌入后添加位置嵌入,再通过Transformer块堆叠处理;输出层为线性投影层,实现逐像素分类;同时,先将离散像素索引映射为可学习的连续嵌入,且采用可分离2D位置嵌入(如RoPE),显式保留图像2D结构信息。
-
备选架构:卷积网络(U-Net):采用用于图像到图像翻译的U-Net分层卷积网络,作为ViT的补充视觉骨干网络,验证经典视觉架构解决ARC问题的有效性。
4.4 两阶段训练:离线预训练+测试时微调
为适配ARC“少样本、多任务”特性,研究采用两阶段训练范式优化模型参数:
- 离线训练:基于训练集 T t r a i n T_{train } Ttrain中所有任务的 D d e m o T D_{demo }^{T} DdemoT训练模型 f θ f_{\theta} fθ,所有任务共享网络参数,仅各任务拥有专属的任务条件令牌;不使用训练任务的 D i n f e r T D_{infer }^{T} DinferT进行训练,仅用于验证。
- 测试时训练(TTT):针对测试集单个新任务
T
∈
T
t
e
s
t
T\in T_{test }
T∈Ttest,独立进行微调:初始化新的任务令牌,对
D
d
e
m
o
T
D_{demo }^{T}
DdemoT(2-4个演示对)进行数据增广(翻转、旋转、颜色置换等),生成辅助任务;基于增广数据微调模型,适配新任务的变换规则,微调过程快速(单GPU单任务约70秒)。
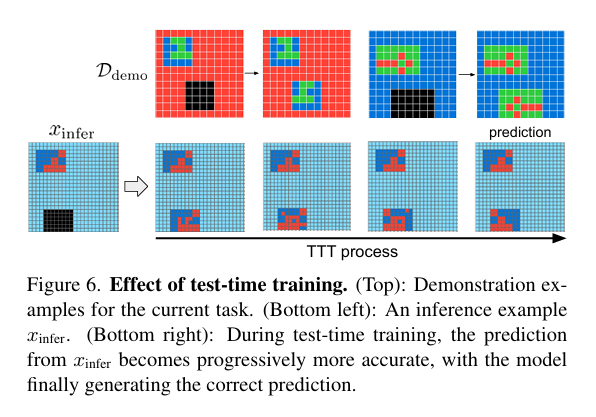
4.5 推理策略:多视角融合提升预测精度
训练完成后,通过以下策略优化推理效果:
- 单视角推理:将 x i n f e r x_{infer } xinfer按特定尺度和平移方式置于画布,经 f θ f_{\theta} fθ预测输出;对原始网格单个位置的多个画布像素预测结果,采用平均池化聚合。
- 多视角推理:采用510个随机增广视角(不同尺度、平移组合)进行预测,通过多数投票整合结果;因视角推理成本远低于测试时训练,几乎不增加额外开销。
- Pass@2准确率支持:保留多视角投票中排名前2的输出结果,契合ARC基准的Pass@2评估标准(两个结果中一个正确即判定任务解决)。
5.【数据说话!VARC模型的实验表现与可视化洞察】
5.1 视觉先验的核心贡献
以ViT-18M为基准,叠加关键视觉组件后,ARC-1准确率从26.8%提升至54.5%(累计+27.7个百分点):
- 2D位置嵌入(尤其RoPE)提升显著,显式建模2D结构必要;
- 64×64画布+2×2补丁丰富数据空间,强化空间先验;
- 尺度增广贡献最大(+6.2个百分点),弥补ViT尺度不变性不足。

5.2 消融实验关键结论
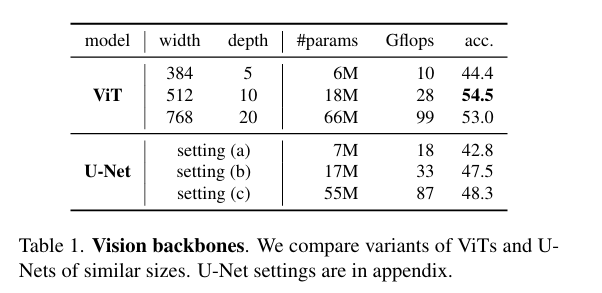
-
架构:ViT性能优于同规模U-Net,18M ViT达54.5%(17M U-Net为47.5%);
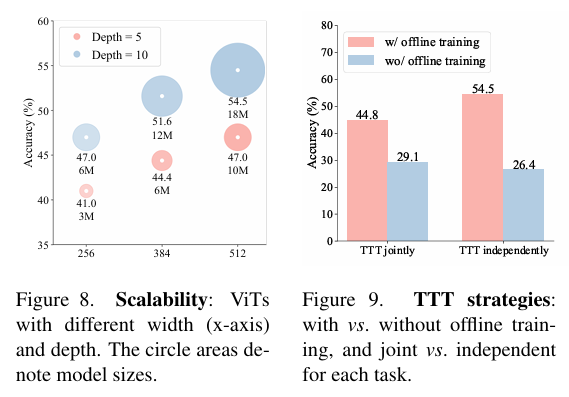
-
训练:离线训练+单任务独立TTT效果最优,避免遗忘视觉常识;
-
推理:多视角融合(510个视角)+Pass@2评估,大幅降低单像素错误影响,准确率从35.9%(单视角)升至54.5%。
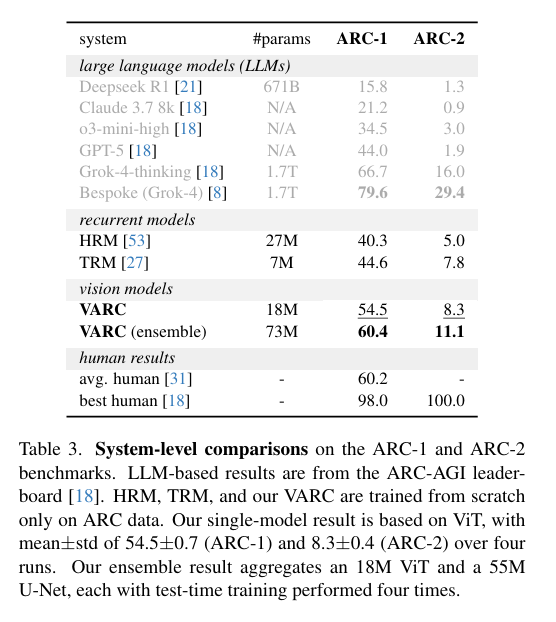
5.3 系统级对比亮点
- 超循环模型:18M VARC在ARC-1达54.5%,优于TRM(44.6%)、HRM(40.3%),相对提升超20%;
- 平LLM:无互联网预训练,却比肩GPT-5(44.0%)等大模型;
- 近人类水平:集成模型(ViT+U-Net)ARC-1准确率60.4%,与人类平均(60.2%)持平;ARC-2单模型8.3%、集成11.1%,表现稳健。
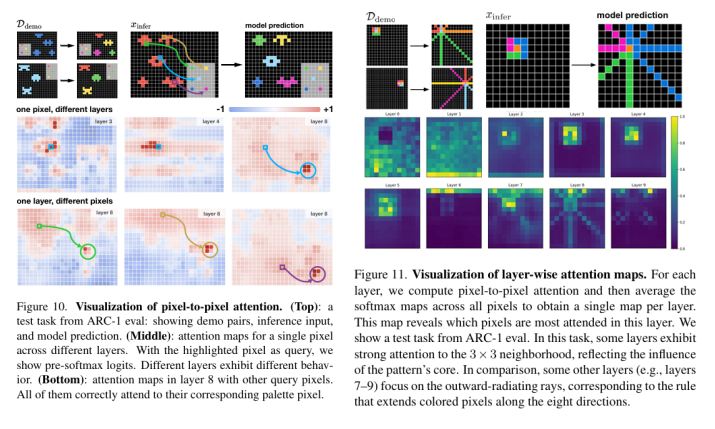
5.4 可视化核心洞察
-
注意力分工:像素级关注“源-目标”对应,层间各司其职(局部/方向/任务专属);
-
任务嵌入聚类:语义相似任务(着色/逻辑运算)在嵌入空间聚集,体现抽象关系学习;
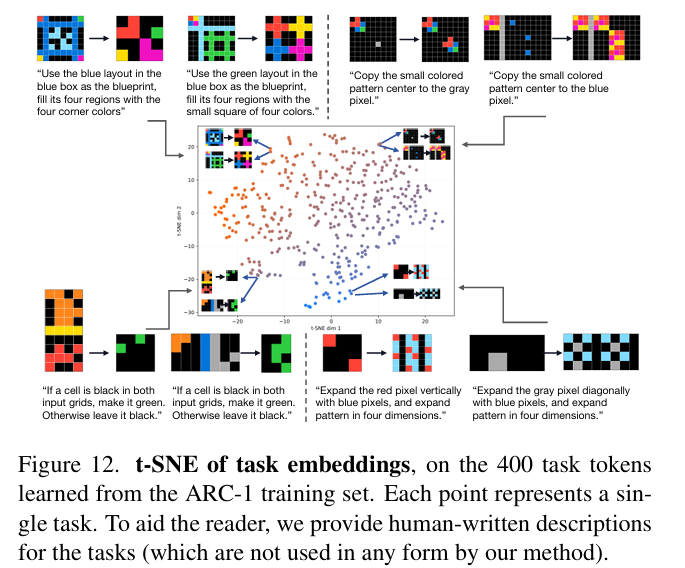
-
TTT过程:从粗糙预测逐步细化,展现快速适配新任务的能力。
6.【视觉破局ARC:总结与未来展望】
本研究打破现有ARC研究的语言导向思路,首次将其构建为图像到图像翻译问题,通过“画布”设计融入2D位置嵌入、平移/尺度增广等视觉先验,采用ViT或U-Net等视觉架构,结合“离线训练+测试时训练”范式,仅基于ARC数据从头训练的VARC模型,在ARC-1基准上单模型准确率54.5%、集成模型达60.4%(接近人类平均水平),显著优于同训练条件的循环模型且比肩部分LLM,证明视觉视角是解决ARC的有效路径;未来可通过更具表达力的视觉架构、更丰富的视觉先验设计或大规模图像预训练进一步拓展,推动视觉驱动的抽象推理研究,助力构建更接近人类学习抽象概念能力的AI系统。


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









