







1. 什么叫stack overflow?
答:
- 栈溢出 Stack Overflow
- 全球最大的程序员问答网站
Stack Overflow
2. 什么是程序栈?
从一个简单的C语言程序开始。
// function_example.c
#include <stdio.h>
int static add(int a, int b)
{
return a+b;
}
int main()
{
int x = 5;
int y = 10;
int u = add(x, y);
}
在名字叫add的子函数中,接受a 和 b两个参数 ,返回值就是 a+b。在main函数中定义了x、y和u三个变量。
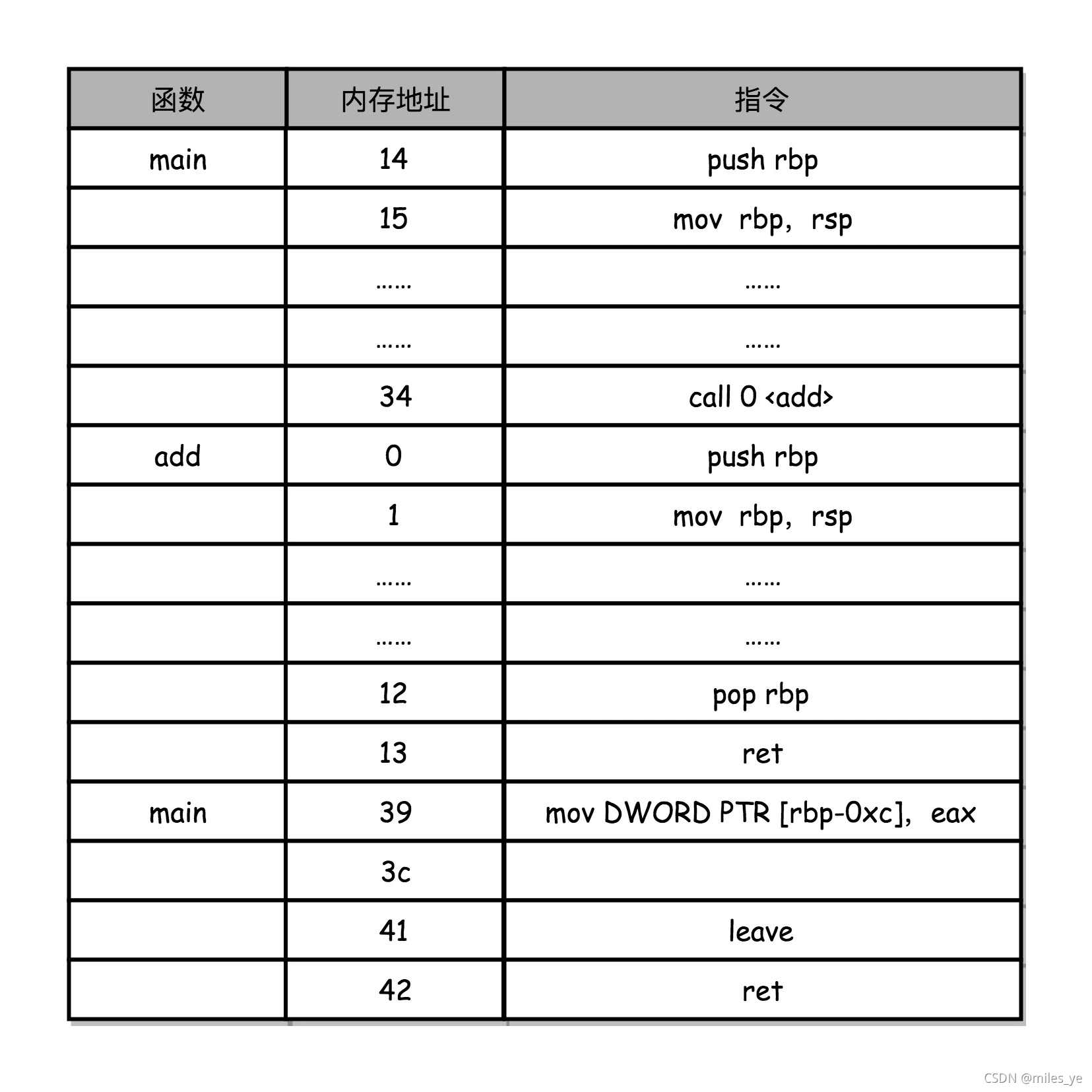
上述这段程序编译后的汇编程序如下。
int static add(int a, int b)
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 89 7d fc mov DWORD PTR [rbp-0x4],edi
7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
return a+b;
a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
d: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
10: 01 d0 add eax,edx
}
12: 5d pop rbp
13: c3 ret
0000000000000014 <main>:
int main()
{
14: 55 push rbp
15: 48 89 e5 mov rbp,rsp
18: 48 83 ec 10 sub rsp,0x10
int x = 5;
1c: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5
int y = 10;
23: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xa
int u = add(x, y);
2a: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
2d: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
30: 89 d6 mov esi,edx
32: 89 c7 mov edi,eax
34: e8 c7 ff ff ff call 0 <add>
39: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
3c: b8 00 00 00 00 mov eax,0x0
}
41: c9 leave
42: c3 ret
发现:
- add函数中先执行了一条push指令和一条mov指令。
- add函数执行结束后,又执行了一条pop指令和一条ret指令。
分析:
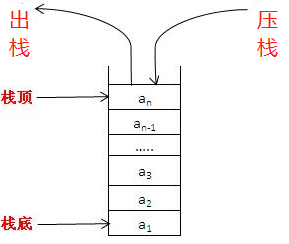
- push就是压栈
- pop就是出栈
- 函数调用的跳转,在对应函数的指令执行完之后,还需要再回到函数调用的地方,继续执行call之后的指令。
问题来了: 这种情况下,有没有办法可以不跳转回原来的地方,实现函数的调用呢?(例如:Java的方法内联优化方法)
**答:**似乎可以。
- 就是把调用的函数指令,直接插入在调用函数的地方,替换对应的 call 指令。然后在编译器编译代码的时候,直接就把函数调用变成对应的指令替换掉。
但是,这会产生:如果函数A调用B,B再调用A,那么程序会导致无限镜面效应(Infinite Mirror Effect)。这种方法行不通(例如:内联优化方法中调用树不能递归)。over

2. 用一个类似PC寄存器那样的“程序调用寄存器”,来存储接下来要跳转回来执行的指令地址。等到函数调用结束,从这个寄存器里取出地址,再跳转到这个记录的地址,继续执行。
但是,随着多层函数调用的调用数量的增加,每一次调用的返回地址都需要记录下来,所需要的“程序调用寄存器”的数量也一定会增加。而CPU中的寄存器数量并不多,例如Intel i7 CPU中只有16个64-bit的寄存器。这种方法不现实。over
所以,在内存中开一个“后进先出(LIFO,Last In First Out)”数据结构的的存储空间,这就是“栈”。
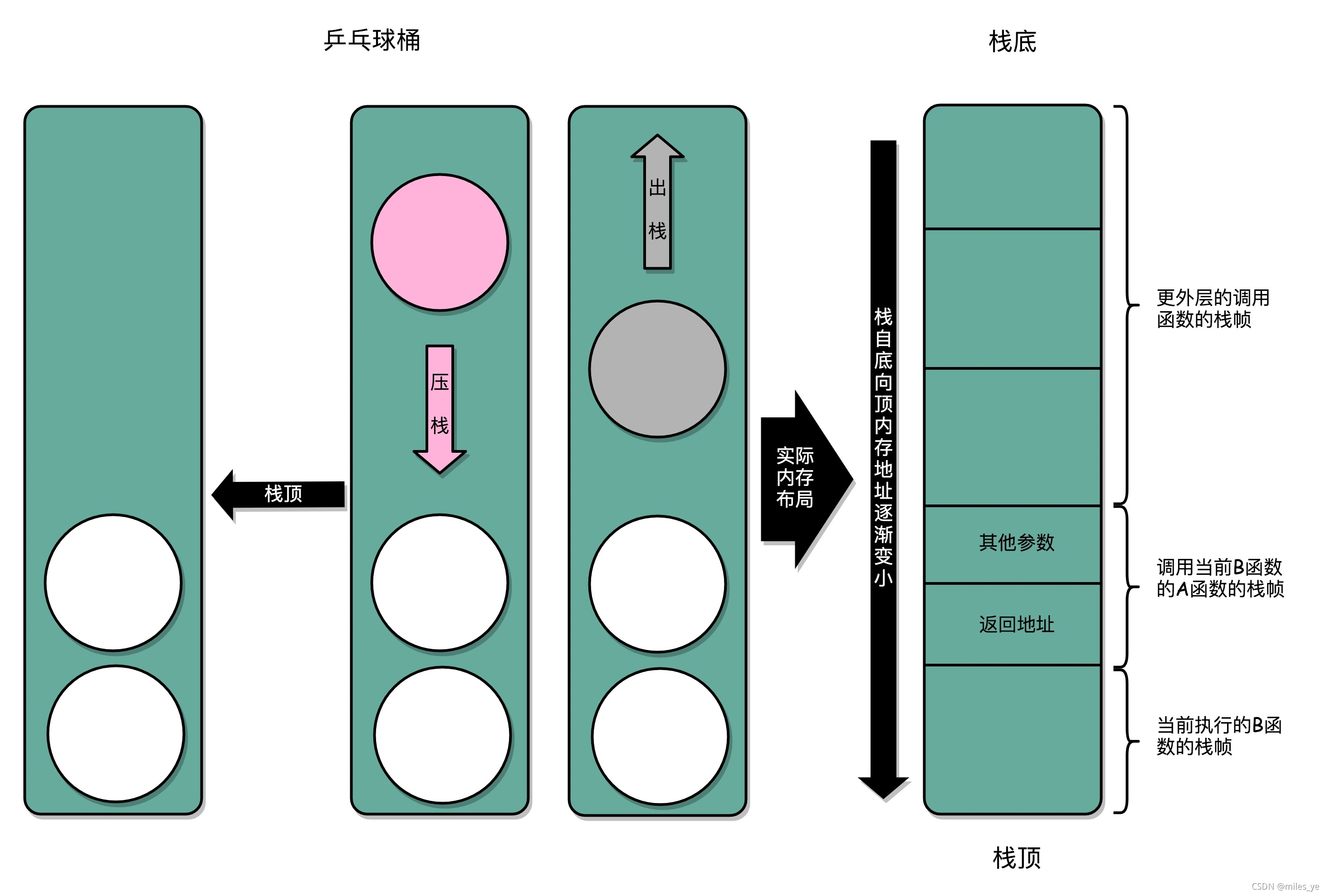
不只有上述函数调用的情况会用堆栈,如下情况也都会会用到堆栈:
- a+b*c
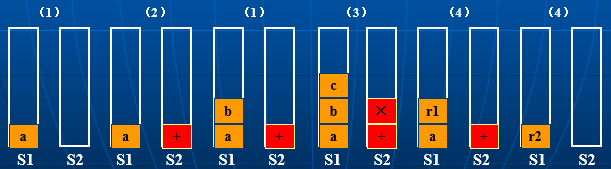
- 函数A在调用函数B时,在跳转之前需要把A的状态(包括函数A的参数、变量、返回地址等)保留下来。这里函数A的状态被称为栈帧(Stack Frame)。
在实际内存中,栈底的内存地址一开始就是固定的,在最上面。栈顶的内存地址是逐渐变小,而不是变大,在最下面。这是因为栈底决定了这个栈的最大存储空间。栈底是最大值,然后随着数据不断压栈存储,栈顶不断靠近最上层即接近最小值。如果是逐渐变大的话会造成超出内存地址的最大限制。
其中,rbp代表register base pointer栈基址寄存器(栈帧指针Frame Pointer),指向栈底的地址(start of stack)。rsp代表register stack pointer栈顶寄存器(栈指针Stack Pointer),指向栈顶的地址(current location in stack)。
3. 如何构造一个stack overflow?
栈的大小是有限制的。如果函数调用层数太多,往堆栈中压入太多的内容,就会发生栈的溢出错误(Stack Overflow)。用上面的Infinite Mirror Effect,让函数A不限递归,就可以实现一个Stack Overflow。
int a()
{
return a();
}
int main()
{
a();
return 0;
}
除了无限递归,如果在堆栈空间里创建非常占内存的变量(例如:巨大的数组),也可能会stack overflow。
4. 如何利用函数内联进行性能优化?
函数内联(Inline):如果被调用的函数里没有调用其他函数(这种被调用的函数称为叶子函数),则可以把调用函数中的指令替换对应的函数调用指令。优点是CPU需要执行的指令变少,不需要根据地址进行跳转,不需要压栈和出栈。例如下列程序:
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
int static add(int a, int b)
{
return a+b;
}
int main()
{
srand(time(NULL));
int x = rand() % 5;
int y = rand() % 10;
int u = add(x, y);
printf("u = %d\n", u);
}
用下列命令执行:
$ gcc -g -c -O function_example_inline.c
$ objdump -d -M intel -S function_example_inline.o
编译出来的汇编程序,没有把add子函数单独编译成一段指令,而直接替换成了一个add命令。
return a+b;
4c: 01 de add esi,ebx
除了像上面那样,在 GCC 编译的时候用参数 -O,进行函数内联外,还可以在定义函数时使用inline关键字,来进行函数内联。例如:
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
inline int add(int a, int b)
{
return a+b;
}
int main()
{
srand(time(NULL));
int x = rand() % 5;
int y = rand() % 10;
int u = add(x, y);
printf("u = %d\n", u);
}
内联的代价:内联意味着把可以复用的程序指令在调用它的地方完全展开了。如果一个函数在很多地方都被调用了,那么就会展开很多次,整个程序占用的空间就会变大了。
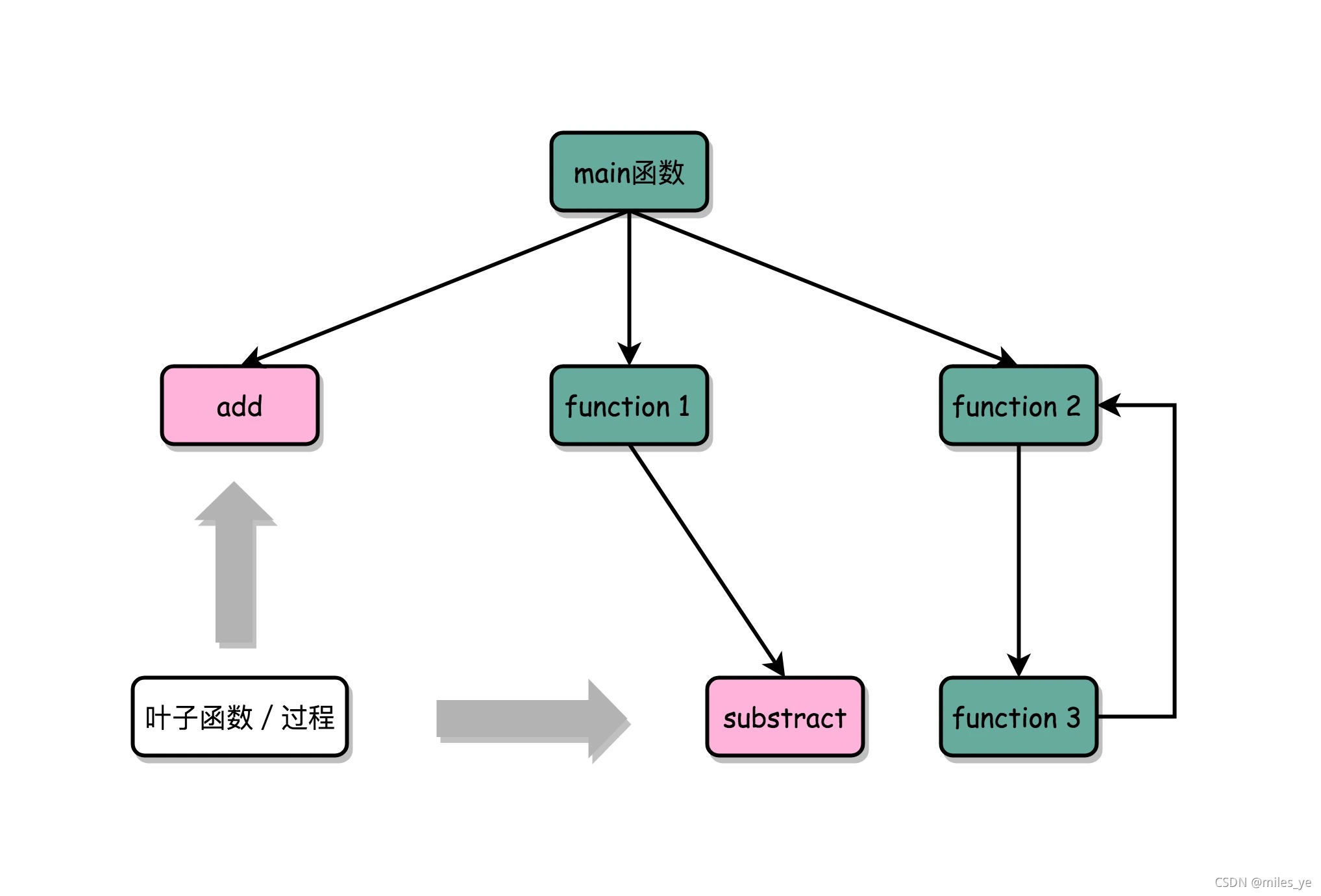
5. 小结
通过程序栈,能在跳转去运行新的指令之后,再回到跳出去的位置,能够实现更加丰富和灵活的指令执行流程。程序栈也提供了“函数”这样一个抽象,使得在软件开发的过程中,可以复用代码和指令,而不是只能简单粗暴地复制、粘贴代码和指令。
















 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











