







问题的提出
泰坦尼克号Titanic的故事众人皆知。我们拿到了泰坦尼克号上的乘客数据的一部分——训练集train.csv,数据集在这里。
数据描述
这个数据集包含以下特征(Feature):
- PassengerId => 乘客编号;
- Survived => 获救情况(1为获救,0为未获救);
- Pclass => 乘客等级(1等舱位,2等舱位,3等舱位);
- Name => 姓名,字符串型(String);
- Sex => 性别(male,female),字符串型(String);
- Age => 年龄,浮点数型(Double);
- SibSp => 兄弟姐妹及配偶在船数,整数型(Integer);
- Parch => 父母及子女在船数,整数型(Integer);
- Ticket => 船票编号,字符串型(String);
- Fare => 船票价格,浮点数型(Double);
- Cabin => 乘客船舱,字符串型(String);
- Embarked => 出发港口(C = Cherbourg;Q = Queenstown;S = Southampton),字符串型(String)。
可以 把特征分为两类:目标变量和特征项。因为这个数据集的分析目标是预测乘客的获救与否,所以目标变量(也称因变量)为“Survived”,其余变量都为特征项(也称自变量)。目标变量的取值只有两个:“0”和“1”。其中,“0”表示死亡,“1”表示获救,所以这是一个二分类问题。对于分类问题,在KNIME中要求特征项都为字符型。所以要对特征项进行数据预处理,整理为模型需要的数据类型。
数据预处理
- 创建工作流,添加文件读取节点
(1)添加CSV Reader文件读取节点。因为数据原文件为csv文件,所以选择CSV Reader节点。在“Node Repository”的搜索框中输入“CSV Reader”,选择“IO”=>“Reader”下的“CSV Reader”,然后将其拖入工作流编辑器窗口。
(2)配置CSV Reader节点。在工作流编辑器窗口中双击CSV Reader节点,打开“Configure”,点击Browse,在工作区中选择要输入的泰坦尼克号“train.csv”数据文件,勾选“Has Row Header”,其他的默认配置。然后,点击“OK”。
(3)执行CSV Reader节点并查看执行结果。
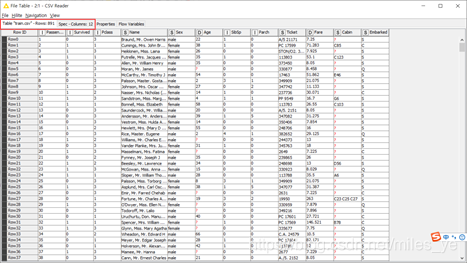
可以清晰地看到“Age”和“Cabin”两个特征项有缺失值,其他的特征项没有缺失值。此外,“PassengerID”、“Survived”、“Pclass”、“SibSp”、“Parch”特征项都为整数型(Integer),需要把他们变成字符串型(String)。“Age”和“Fare”为浮点数型(Double),需要进行数据离散化。 - 数据类型转换
(1)添加Number to String节点。开始数据清洗,首先把“PassengerID”、“Survived”、“Pclass”、“SibSp”、“Parch”的整数型(Integer)特征项都转换成字符串型(String)。在“Node Repository” 的搜索框中输入“Number to String”,选择“Manipulation”=>“Column”=>“Convert & Replace”下的“Number to String”,然后将其拖入工作流编辑器窗口。
(2)连接CSV Reader和Number to String节点。
(3)配置Number to String节点。
在工作流编辑器窗口中双击Number to String节点,打开“Configure”,在“Exclude”中选择“Age”和“Fare”,排除这两项特征。然后,点击“OK”。
(4)执行Number to String节点。
(5)查看Number to String节点的执行结果。右键单击Number to String节点,选择 “Transformed input”,可以看到“PassengerID”、“Survived”、Pclass”、“SibSp”、“Parch”特征项都转换成字符串型(String),特征名之前都有代表String的“S”符号。 - 数据初步统计
(1)添加Statistics节点,对数据进行初步了解。在“Node Repository”中的搜索框中输入“Statistics”,选择“Analytics”=>“Statistics”下的“Statistics”,然后将其拖入工作流编辑器窗口。
(2)连接Number to String节点和Statistics节点。
(3)配置Statistics节点。在工作流编辑器窗口中双击Statistics节点,打开“Configure”。在“Include”中选择所有的特征字段,其他的默认配置。然后,点击“OK”。
(4)执行Statistics节点。
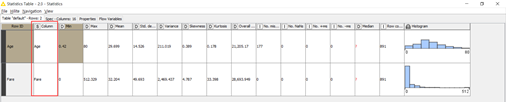
(5)查看Statistics节点的执行结果。右键单击Statistics节点,选择“Statistics Table”,可以看到在浮点数型数据“Age”和“Fare”的统计结果。
右键单击Statistics节点,选择“Nominal Histogram Table”,可以看到在字符串型变量的统计结果。
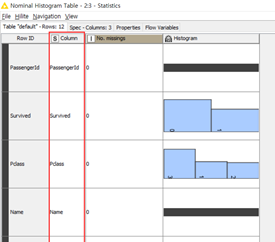
还可以通过在“Nominal Histogram Table”中的“No.Missings”按降序排列 “Sort Descending”,查看各特征项中缺失值的个数。
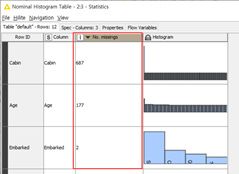
可以看到,“Cabin”、Age”、“Embarked”三列分别存在687、177、2个缺失值。
4. 字符串型变量与目标变量的关系
(1)添加Crosstab节点。开始探索每个特征项与目标变量的关系,把特征项分为数值型特征项和字符串型特征项两类。其中,字符串型特征项需要用到Crosstab节点。数值型特征项需要用到数据可视化方法,使用Conditional Box Plot节点绘制分组箱型图。
首先,探索字符串型变量与目标变量的关系。在“Node Repository”中的搜索框中输入“Crosstab”,选择“Analytics”=>“Statistics”下的“Crosstab(local)”,然后将其拖入工作流编辑器窗口。
(2)连接Number To String和Crosstab(local)节点。
(3)配置Crosstab(local)节点。
探索每个字符串型数据的特征项与目标变量“Survived”的关系。通过分析可以知道,乘客编码“PassengerID”、乘客姓名“Name”及乘客船票号码“Ticket”不会影响乘客的获救率。因此这三个字符串型变量与目标变量关系不用分析。
乘客等级“Pclass”包含1/2/3三个特征值,分别代表1等舱,2等舱,3等舱;乘客等级“Pclass”应该会影响目标变量“Survived”,影响乘客的获救率。
在工作流编辑器窗口中双击“Crosstab(local)”节点,打开“Configure”,“Row variable”设置为乘客等级“Pclass”,“Column variable”设置为“Survived”,“Weight column”设置为“None”。然后,点击“OK”。
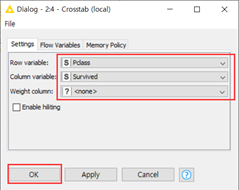
(4)执行并查看Crosstab(local)节点的结果。右键单击Crosstab(local)节点,选择“Execute and OpenViews”,会自动弹出结果。
5. 数值型变量与目标变量的关系
(1)添加Conditional Box Plot节点。数值型变量与目标变量的关系可以通过分组箱型图来分析。在“Node Repository”中的搜索框中输入“Conditional Box Plot”,选择“Views”=>“JavaScript”下的“Conditional Box Plot”,然后将其拖入工作流编辑器窗口。
(2)连接Number To String节点和Conditional Box Plot节点。
(3)配置Conditional Box Plot节点。
探索“Age”和“Fare”两个数值型变量与目标变量“Survived”的关系。在工作流编辑器窗口中双击Conditional Box Plot节点,打开“Configure”,把“Category Column”设置为“Survived”,在右边绿色框中选择“Age”和“Fare”两列。在“Selected Column”中设置为“Age”,其他的默认设置。然后,点击“OK”,可以查看到“Age”特征项与目标变量“Survived”的关系。
“Fare”数值型数据的特征项与目标变量“Survived”的关系,则把“Selected Column”设置为“Fare”即可,其他参数不变。
(4)执行并查看Conditional Box Plot节点。
6. 乘客船舱信息提取
(1)添加String Manipulation节点。
Carbin为乘客船舱信息,跟熟知的火车票类似,首个字母决定了船舱的位置,也很大程度上可以反映船票价格和乘客的身份、等级。因此,需要把乘客船舱的首个字母提取出来。在“Node Repository”的搜索框中输入“String Manipulation”,选择“Manipulation”=>“Column”=>“Convert & Replace”=>“String Manipulation”,然后将其拖入工作流编辑器窗口。
(2)连接Number To String节点和String Manipulation节点。
(3)配置String Manipulation节点。
在工作流编辑器窗口中双击String Manipulation节点,打开“Configure”,在“Function”中找到substr函数,在“Expression”中生成“substr(
C
a
r
b
i
n
Carbin
Carbin, 0,1)”的表达式。在“Append Column”中输入提取乘客船舱信息后保存的列名“New_Cabin”。然后,点击“OK”。
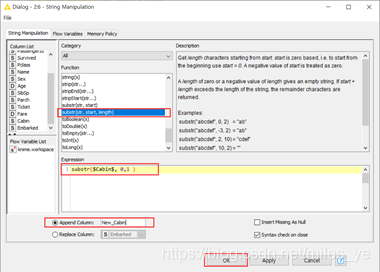
(4)执行String Manipulation节点。
(5)查看String Manipulation节点的执行结果。右键单击String Manipulation节点,选择“Appended table”,可以看到在原数据集上新增一列“New_Cabin”。
7. 缺失值处理
(1)添加Missing Value节点。
现在开始处理“Cabin”、“Age”、“Embarked”特征项中的缺失值。在本例中,“Age”为连续型数据,可以用中位数或平均值填充;“Embarked”为离散型、字符串型数据,且缺失值只有2个,可用众数填充;“Cabin”也为离散型、字符串型数据,但缺失值687个,可以考虑把缺失值作为特征中的取值,另成一类。
在“Node Repository”中的搜索框中输入“Missing Value”,选择“Manipulation”=>“Column”=>“Transform”=>“Missing Value”,然后将其拖入工作流编辑器窗口。
(2)连接String Manipulation节点和Missing Value节点。
(3)配置Missing Value节点。
在工作流编辑器窗口中双击Missing Value节点,打开“Configure”,在“Column Settings”把“Age”中的缺失值用中位数(Median)来填充,把“Embarked”中的缺失值用众数(Most Frequent Value)来填充,把“New_Cabin”中的缺失值用“NAN”来填充,也就是把缺失值作为特征中的一个取值,另成一类。然后,点击“OK”。
(4)执行Missing Value节点。
(5)查看Missing Value节点的执行结果。右键单击Missing Value节点,选择“Output table”,可以看到“New_Cabin”中的缺失值被“NAN”填充了。
8. 缺失值处理后对数据统计
(1)如前所述,添加、连接、配置、执行数据初步统计Statistics节点。可以看到“Age”、“Cabin”、“Embarked”三个特征项中无缺失值,数据完整。
9. 对船票价格数据离散化
(1) 添加Rule Engine节点。
在前面的数值型数据与获救率的关系分析中,发现获救乘客的船票价格比死亡乘客的船票价格高。因此,船票价格和获救率之间存在关系。船票价格是浮点数型的,将船票价格数据离散化,把连续型数据转换为离散型数据;再根据前面的箱型图,把船票价格划分为[0,10)、[10,50)、[50,100)、[100,+∞)四个区间,用这四个区间代替落入该区间的特征值,增强模型的鲁棒性。这时,需要用到“Rule Engine”节点。
在“Node Repository” 的搜索框中输入“Rule Engine”,选择“Manipulation”=>“Row”=>“Other”下的“Rule Engine”,然后将其拖入工作流编辑器窗口。
(2)连接Missing Value节点和Rule Engine节点。
(3)配置Rule Engine节点。
在工作流编辑器窗口中Rule Engine节点,打开“Configure”,在“Expression”中生成如下的表达式(注意表达式中所有的符号均为英文符号)。
F
a
r
e
Fare
Fare < 10 => “very_low”
F
a
r
e
Fare
Fare < 50 => “low”
F
a
r
e
Fare
Fare < 100 => “middle”
TRUE => “high”
在“Append Column”中数据离散后的特征名称“New_Fare”。然后,点击“OK”。
(4)执行Rule Engine节点。
(5)查看Rule Engine节点的执行结果。右键单击Rule Engine节点,选择“Classified values”,可以看到在原数据集上新增一列“New_Fare”。
10. 对年龄特征数据离散化
(1)添加Rule Engine节点。
泰坦尼克号沉没时秉承“妇女和小孩先走”的原则,所以获救与否与年龄段有关系。因此,将年龄特征数据离散化,即连续型变量转换为离散型变量,把年龄划分为[0,18)、[18,65)、[65,+∞)三个区间,用这三个区间代替落入该区间的特征值,增强模型的鲁棒性。这时,需要用到“Rule Engine”节点。
在“Node Repository”的搜索框中输入“Rule Engine”,选择“Manipulation”=>“Row”=>“Other”=>“Rule Engine”,然后将其拖入工作流编辑器窗口。
(2)连接前后两个Rule Engine节点。
(3)配置Rule Engine节点。
在工作流编辑器窗口中双击Rule Engine节点,打开“Configure”,在“Expression”中生成如下的表达式(注意表达式中所有的符号均为英文符号)。
A
g
e
Age
Age < 18 => “child”
A
g
e
Age
Age < 65 => “adult”
TRUE => “senior”
在“Append Column”中输入新增列的列名,“New_Age”。然后,点击“OK”。
(4)执行Rule Engine节点。
(5)查看Rule Engine节点的执行结果。右键单击Rule Engine节点,选择“Classified values”,可以看到新增的列“New_Age”。
11. 导出工作流
选中“File”“Export KNIME Workflow…”,选择一个导出路径,将工作流命名为clearData.knwf。


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











