







原文:Associative Embedding: End-to-End Learning for Joint Detection and Grouping
代码:princeton-vl/pose-ae-train
Abstract
文章提出了一种全新的用于detection和grouping的监督方法,Associate Embedding。意外的多人姿态估计、实例分割、多目标跟踪问题都采用了two-stages,先detect后group的方式。文章提出的associate embedding 同时输出detection 和 grouping的结果,并在多人姿态估计任务中的MPII和COCO数据集上达到了SOTA。
Introduction
Associate embedding的基本思想是为每一个detection都分配一个vector作为tag来指示聚类的分配。所以拥有同一个tag的detections聚类成一个集合,构建出一个人体实例。对于每个实例有m个关键点的多人姿态估计任务,网络共输出m张关键点检测的heatmap,和m个tag图,每个tag图分别来指示对于某一关节来说,每个像素分别应该属于哪个人体实例。
具体的解码方式是:先从heatmap上提取出关键点所在的位置,去对于的tag图中找到tag值,把tag值相近的关键点聚类成一个人体实例。
网络训练时,Loss函数只需要鼓励同一个人体实例的不同关节点的对应的tag值相近,而不同的人体实例的关节点tag值相异即可。只需要学习tag应该相同或不同,网络可以自由学习具体的绝对的标签是什么。(用0和1可以区别出来,2和3也可以区别出来,效果都是一样的,网络自己决定用哪组数字来区别,所以对于tag也没有具体的GT。)
Related Work
略
Approach
Network Architecture
用了Hourglass的网络结构做了一个改进,为了多人姿态,提高了hourglass各层的分辨率,每个网络中的residual modules换成了 3 × 3 3\times 3 3×3 卷积。
Detection and Grouping
Detection的部分和单人姿态类似,为m类关键点分别生成m张heatmap,为不同人的同类关节点在用一张heatmap上无差别的表示,所以一张理想的heatmap是为每个人的这类关节点都有一个不同的peak。训练时GT用2D高斯来构建peak,loss函数用了MSE。
Grouping的部分,也是本文的关键创新点。假设已经从detection的部分获得了共m类关键点的位置,每类关键点都有好几个,需要把这些关键点进行grouping,构建出完整的人体实例。网络在detection的同时额外生成了一个embedding来指示每个像素应该属于哪个人体实例。(对于不同类的实例来说都有一个不同的embedding)。文章提出embedding的纬度并不重要,高维如果能实现,那低维一定也可以,比较只是用来区别人体实例,所以文章里用了1D的embedding。
tag指示了每个检测到的关节点属于哪一个人体实例。每个detection heatmap都各自对应的tag map。因此对于m各人体关节,用m 个 detection heatmap用来检测 和 m 个 tag map用来grouping。为了把每个检测到关节匹配到不同的人体实例,文章首先检索出每个检测出的关键点的峰值处像素所对应的tag map中的tag值,通过比较各个关节点的值来聚类 组合人体。
Grouping 的 loss 函数评估预测出的tag能是否个GT的聚类结果相同。具体地,我们检索每个人体节点的GT位置的对应的tag map中预测出的tag值(并不是预测出的关节点位置对应的tag值)
每个人体各关节点的GT位置的tag求均值作为改人体的reference embedding:
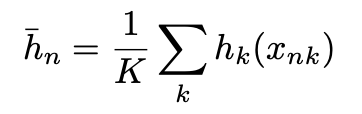
之后根据同意人体的tag相近,不同人体的reference embedding相异的原则,计算loss:
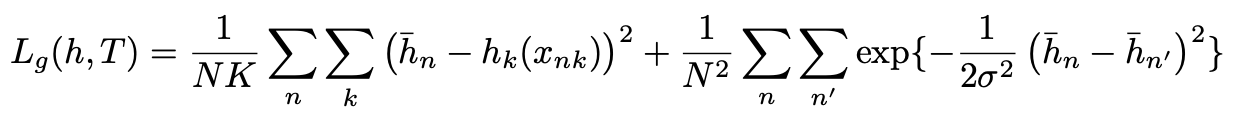
Parsing Network Output
为了生成最后的一系列检测结果,我们一个一个关节点遍历。顺序从头和躯干逐渐移动至关节。假设我们首先从脖子开始,组成我们的初始的人体实例pool。对于下一个关节点,
我们挑选出与人体pool最匹配的关节点。每个关节点由它的分数与tag组成,每个人体的reference embedding 由当前关节点的tag均值决定。
我们比较这些embedding之间的距离,我们贪婪的分配 在embedding距离之内的 响应最高的 关节点。如果新的joint没有任何匹配的人体(和任何tag都不相近),把这个joint作为一个新的人体实例。知道所有的joint都分配完成。
代码实现部分:
首先在k个heatmap上得到最多m个detection,在提取出对应的tag值,得到:
ans = {
tag_k:
loc_k:
val_k:
}
生成权重矩阵,使用KM算法找到二分图最佳匹配。(按关节点顺序遍历)
对于Missing Joints 我们在评估阶段需要确保每个人体实例都有完整的所有关节点,我们挑选出所有tag相近的位置,在其中挑选出响应最高的点作为其关节点。这个位置在之前的detection阶段可能并没有达到被detect出的阀值。
对于Multiscale Evaluation我们对多尺度的heatmaps在resize之后逐元素取均值,对于tag maps,我们resize之后对m个scale的tag maps进行逐元素的concat,tag作为m维的vector。
HigherHRNet 代码中的associate embedding部分。
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft
# Licensed under the MIT License.
# Written by Bin Xiao (leoxiaobin@gmail.com)
# Modified by Bowen Cheng (bcheng9@illinois.edu)
# ------------------------------------------------------------------------------
import torch
import torch.nn as nn
class AELoss(nn.Module):
def __init__(self, loss_type):
super().__init__()
self.loss_type = loss_type
def singleTagLoss(self, pred_tag, joints):
"""
associative embedding loss for one image
"""
tags = []
pull = 0
for joints_per_person in joints:
tmp = []
for joint in joints_per_person:
if joint[1] > 0:
tmp.append(pred_tag[joint[0]])
if len(tmp) == 0:
continue
tmp = torch.stack(tmp)
tags.append(torch.mean(tmp, dim=0))
pull = pull + torch.mean((tmp - tags[-1].expand_as(tmp))**2)
num_tags = len(tags)
if num_tags == 0:
return make_input(torch.zeros(1).float()), \
make_input(torch.zeros(1).float())
elif num_tags == 1:
return make_input(torch.zeros(1).float()), \
pull/(num_tags)
tags = torch.stack(tags)
size = (num_tags, num_tags)
A = tags.expand(*size)
B = A.permute(1, 0)
diff = A - B
if self.loss_type == 'exp':
diff = torch.pow(diff, 2)
push = torch.exp(-diff)
push = torch.sum(push) - num_tags
elif self.loss_type == 'max':
diff = 1 - torch.abs(diff)
push = torch.clamp(diff, min=0).sum() - num_tags
else:
raise ValueError('Unkown ae loss type')
return push/((num_tags - 1) * num_tags) * 0.5, \
pull/(num_tags)
def forward(self, tags, joints):
"""
accumulate the tag loss for each image in the batch
"""
pushes, pulls = [],  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









