






什么是es中的scroll?
scroll即滚动查询,我们知道,es中在进行普通的查询时,默认只会查询出来10条数据。我们通过设置es中的size可以将最终的查询结果从10增加到10000,那么问题来了,当我们需要查询的数据大于10000条怎么办?这时有两种方式解决:深度分页和滚动查询。优先使用滚动查询,因为深度分页越往后查性能越低,极其耗费内存和CPU。
深度分页
分页即使用from和size,如下:
{
"query": {
"match_all": {}
},
"from": 9990,
"size": 20
}像这样就能够获取到9990-10010的20条数据了,但是这样每次都需要将前面的9990条数据查询出来,然后再向下继续寻找后面的20条,最终就会导致搜索很深,即深度分页,性能就会受到极大影响,因此这种方式不推荐使用。
滚动查询
滚动查询,和关系型数据库中的游标有点类似,因此也叫游标查询。也相当于一个快照,它是es中提供的一种查询大数据量的方式。
在dsl语句中,完成一个scroll查询分为两步:
第一步:带有查询条件,根据条件查询。
GET search_account/_search?scroll=1m
{
"size":1000,
"query": {
"term": {
"type": {
"value": "生活"
}
}
}
}这是一个简单的term查询哈,这个查询条件比较简单,相当于一个示意,关键点两个:
① scroll表示这是一个scroll滚动查询;
② scroll=1m表示查询的结果数据在es服务器中过期时间为1min。
该查询返回的结果如下:
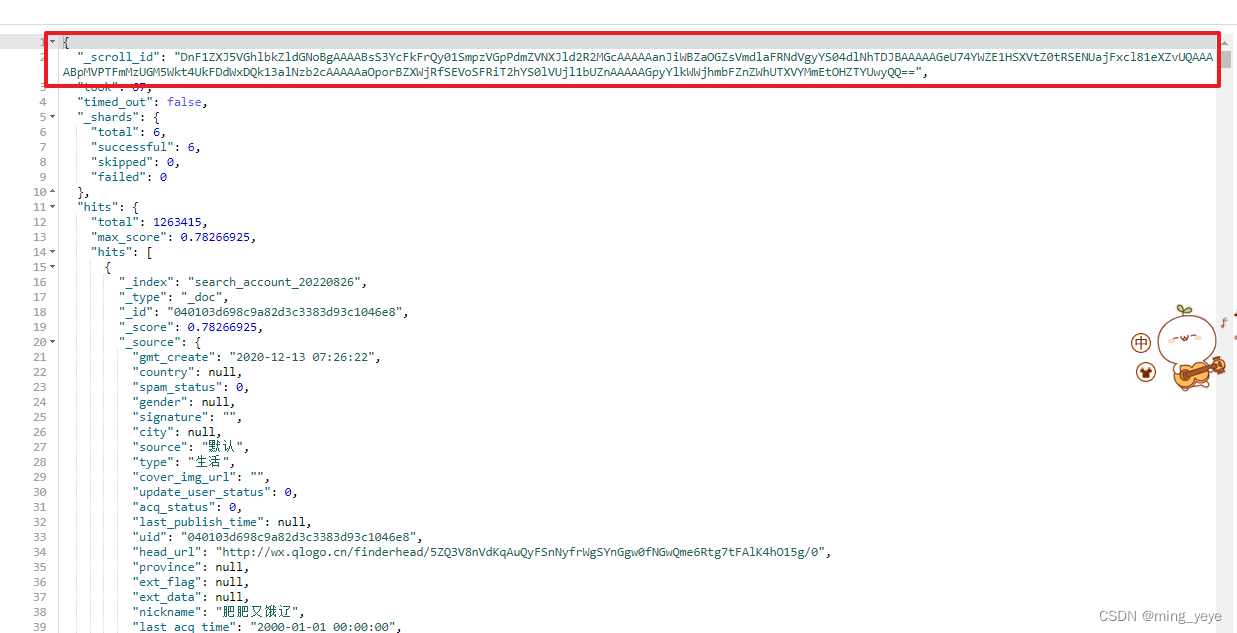
可以看到,返回结果中有一个_scroll_id字段,该字段其实就相当于一个书签,在我们之后的查询中需要带着这个书签,就可以一直往后根据设置的size大小获取数据(前提是在设置的过期时间之内)。
第二步:获取的scroll_id作为查询条件往后查询数据。
GET /_search/scroll/
{
"scroll":"1m",
"scroll_id":"DnF1ZXJ5VGhlbkZldGNoBgAAAABtmn3QFnJNSEk2S2FBVENTQ21JR0dtVXZEbFEAAAAAaePcNhZaOGZsVmdlaFRNdVgyYS04dlNhTDJBAAAAAG2afdEWck1ISTZLYUFUQ1NDbUlHR21VdkRsUQAAAABplHFdFkpvME9pZEd1U0pXdVlSc29CYXFkZHcAAAAAamCmqhZVNXRmNFhlNFN5NjZwMHZraE5ndEV3AAAAAGnj3DcWWjhmbFZnZWhUTXVYMmEtOHZTYUwyQQ=="
}将获取的scroll_id作为条件继续查询即可,不需要再指定索引和类型。因为scroll_id具有唯一性,在过期时间内,之后查询的scroll_id是不变的。
滚动查询在Springboot中的使用
以上说明的是在dsl语句中如何使用scroll,但是既然涉及到大数据量,在dsl中完成就不太可能了,一般都是通过代码的方式进行滚动查询。这里说明一下es中的scroll查询在Springboot中的使用:
环境准备:springboot项目,es依赖,restHighLevelClient客户端配置。(具体配置这里就不赘述了,咱们直接上手)
需求描述:现已经获取了大批账号的uid(20万以上的数据),需要根据这些账号的uid去es中查询账号所属的分类信息。
代码:
public String redoAccountTypeByScroll(List<String> uidList) {
List<List<RedoAccountTypeVO>> resultList=new ArrayList<>();
//构造es查询条件。
SearchRequest searchRequest = new SearchRequest("search_account");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termsQuery("uid",uidList))
//设置最多一次能够取出10000条数据,从第10001条数据开始,将开启滚动查询。
.size(10000)
.fetchSource(new String[]{"uid","type"},null);
searchRequest.source(sourceBuilder);
//设置scroll超时时间(10min)。
Scroll scroll=new Scroll(TimeValue.timeValueMinutes(10L));
//放入滚动查询对象。
searchRequest.scroll(scroll);
SearchResponse response = restHighLevelClient.search(searchRequest);
//TODO:这里可以解析response对象,获取前10000条数据,封装实体类对象(属性为uid和type),并构成集合accountTypeVOList。我这里假设已经解析response对象完成,得到了accountTypeVOList集合。
resultList.add(accountTypeVOList);
//记录滚动id。
String scrollId=response.getScrollId();
//滚动查询部分,将从第10001条数据开始取。
SearchHit[] scrollHits = response.getHits().getHits();
while (ObjectUtil.isNotNull(scrollHits) && scrollHits.length > 0 ) {
//构造滚动查询条件
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(scroll);
//响应必须是上面的响应对象,需要对上一层进行覆盖。
response = restHighLevelClient.scroll(searchScrollRequest);
scrollId = response.getScrollId();
scrollHits=response.getHits().getHits();
//TODO:同上面一样,在这个位置可以对滚动查询到的从10001条数据开始的数据进行处理(封装实体类),构成集合accountTypeVOList(假设我已经构成了集合)。
resultList.add(accountTypeVOList);
}
//TODO:在循环结束后可以遍历resultList这个大集合,来实现我们自己的需求,我这里是获取账号分类(由于我这里需要调用其它项目完成账号分类的获取,代码就不再贴了,感觉冗余。读者需要明白这里是实现自己的业务需求)。
//数据获取完毕后需要清楚滚动,否则影响下次查询。
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
ClearScrollResponse clearScrollResponse = restHighLevelClient.clearScroll(clearScrollRequest);
//清除滚动是否成功
boolean isSuccess = clearScrollResponse.isSucceeded();
log.info("=====================>清楚滚动scroll是否成功:{}",isSuccess);
return "==================>账号分类获取完毕~";
}总结:
① 滚动查询是建立在普通查询基础上的。
② 需要注意的是:滚动查询相当于快照,如果在使用scroll进行滚动查询期间有增删改的操作,那么查询结果是获取不到最新的数据的。
③ 深度分页和滚动查询优先使用滚动查询,性能更优,CPU资源耗费更少。
希望对你有所帮助!

















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









