






引言:
深度学习为什么火?
深度学习在处理复杂的感知和模式识别任务方面展现出了前所未有的能力。以图像识别为例,深度学习模型(如卷积神经网络 CNN)能够识别图像中的各种物体、场景和特征,准确率远超传统的计算机视觉方法。
当然这之中也还因为
- 大数据时代的推动(随着互联网的发展,数据量呈爆炸式增长。社交媒体、电子商务、物联网等领域产生了海量的数据,这些数据包含了丰富的信息。)
- 计算能力的提升:例如GPU的发展,硬件加速支持,高性能计算硬件的发展为深度学习提供了强大的计算支持。
- 算法和模型的创新:从早期的多层感知机(MLP)到现在广泛应用的卷积神经网络(CNN)、循环神经网络(RNN)及其变种(如长短期记忆网络 LSTM、门控循环单元 GRU),再到 Transformer 架构,每一种新架构都为特定类型的任务带来了性能的飞跃。
深度学习应用领域:
目前应用较好的有计算机视觉领域、自然语言处理领域和语音识别和音频处理领域,当然还有很多其他领域相结合。
基础知识:
以我的理解,深度学习其实就是多隐藏层神经网络,一些架构模型的变形都是基于神经网络的变化,那么学习深度学习需要学习什么知识呢?
- 神经网络基础概念
- 激活函数
- 损失函数与优化算法
- 数据预处理与模型评估
- 过拟合与欠拟合处理
- 神经网络基础概念:
神经元与感知机:
神经元是神经网络的基本单元,它模拟了生物神经元的工作方式。一个神经元接收多个输入,对这些输入进行加权求和,再通过一个激活函数产生输出。感知机是最简单的神经网络形式,它由一个神经元组成,主要用于二分类任务。例如,在一个简单的逻辑与(AND)感知机中,它有两个输入(表示两个逻辑变量),通过调整权重和偏置,当两个输入都为 1 时,输出为 1,否则输出为 0。
神经网络结构:
神经网络由多个神经元按一定的层次结构组成,包括输入层、隐藏层和输出层。输入层接收原始数据,如在图像识别中,输入层的神经元数量可能等于图像像素的数量。隐藏层用于提取数据中的特征,其神经元数量和层数可以根据任务的复杂程度调整。输出层则根据任务产生最终的输出,如在分类任务中输出各类别的概率。以一个简单的手写数字识别多层感知机(MLP)为例,输入层有 784 个神经元(对应 28x28 像素的手写数字图像),一个隐藏层有 128 个神经元,输出层有 10 个神经元(对应 0 - 9 十个数字类别)。
2. 激活函数
作用与意义:
激活函数用于给神经元引入非线性因素。如果没有激活函数,多层神经网络就相当于一个线性回归模型,无法处理复杂的非线性关系。例如,在处理图像数据时,图像中的物体形状、纹理等复杂特征都是非线性的,激活函数可以帮助神经网络更好地拟合这些非线性特征。
常见激活函数:
Sigmoid 函数:公式为![]() ,它的输出范围在 0 到 1 之间,常用于将神经元的输出映射为概率值,在二分类问题的输出层比较常见。但是它存在梯度消失问题,当输入值过大或过小时,梯度趋近于 0,导致网络难以训练。
,它的输出范围在 0 到 1 之间,常用于将神经元的输出映射为概率值,在二分类问题的输出层比较常见。但是它存在梯度消失问题,当输入值过大或过小时,梯度趋近于 0,导致网络难以训练。
ReLU(Rectified Linear Unit)函数:公式为![]() ,它在x>0时是线性的,计算简单且能够有效缓解梯度消失问题。在现代神经网络中被广泛应用于隐藏层。
,它在x>0时是线性的,计算简单且能够有效缓解梯度消失问题。在现代神经网络中被广泛应用于隐藏层。
Tanh 函数:公式为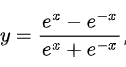 ,输出范围在 - 1 到 1 之间,它的非线性特性比 Sigmoid 函数更好一些,也存在梯度消失问题,但在某些特定的网络架构和任务中仍有应用。
,输出范围在 - 1 到 1 之间,它的非线性特性比 Sigmoid 函数更好一些,也存在梯度消失问题,但在某些特定的网络架构和任务中仍有应用。
3. 损失函数与优化算法
损失函数:
损失函数用于衡量模型预测结果与真实结果之间的差异。在回归任务中,常用的损失函数是均方误差(MSE):![]() 。在分类任务中,交叉熵损失函数比较常用,如在二分类任务中,交叉熵损失函数为
。在分类任务中,交叉熵损失函数比较常用,如在二分类任务中,交叉熵损失函数为![]() 。
。
优化算法
梯度下降算法:这是最基本的优化算法,其原理是沿着损失函数的梯度方向(即函数下降最快的方向)更新模型参数。在每次迭代中,参数更新公式为![]() ,其中θ是模型参数,α是学习率,
,其中θ是模型参数,α是学习率,![]() 是损失函数关于参数的梯度。学习率的大小很关键,如果学习率过大,可能会导致模型无法收敛,而过小则会使训练速度过慢。
是损失函数关于参数的梯度。学习率的大小很关键,如果学习率过大,可能会导致模型无法收敛,而过小则会使训练速度过慢。
随机梯度下降(SGD)及其变种:SGD每次随机选取一个样本计算梯度并更新参数,它的优点是计算速度快,但由于样本的随机性,可能导致收敛过程不稳定。为了改进这一问题,出现了Adagrad、Adadelta、Adam等优化算法。例如,Adam优化算法结合了动量法和自适应学习率的思想,能够根据不同参数的梯度情况动态调整学习率,在实际应用中被广泛使用。
4. 过拟合与欠拟合
过拟合:
过拟合是指模型在训练数据上表现很好,但在新的数据(测试数据)上表现不佳的现象。这是因为模型过于复杂,学习到了训练数据中的噪声和细节,而没有真正掌握数据的一般规律。例如,在一个多项式拟合任务中,如果使用一个很高次的多项式来拟合数据,它可能会完美地穿过训练数据中的每一个点,但对于新的数据点却无法很好地预测。在神经网络中,过拟合可能是因为网络层数过多、神经元数量过多或者训练时间过长等原因导致的。
欠拟合:
欠拟合与过拟合相反,是指模型过于简单,无法很好地拟合训练数据,在训练数据和测试数据上的表现都不好。例如,在图像识别中,如果使用一个只有一层的神经网络来识别复杂的物体,可能会因为模型无法提取足够的特征而导致欠拟合。
应对策略:
为了防止过拟合,可以采用正则化方法,如L1和L2正则化,它们会在损失函数中加入对模型参数大小的惩罚项,使模型参数尽量小,从而避免模型过于复杂。另外,Dropout是一种常用的技术,在训练过程中随机丢弃一些神经元,让网络在不同的子结构中学习,增加模型的泛化能力。对于欠拟合,则需要增加模型的复杂度,如增加网络层数、神经元数量或者延长训练时间等。
5. 数据预处理与模型评估
数据预处理:
数据预处理是为了让数据更适合模型训练。常见的操作包括数据归一化和标准化。数据归一化是将数据映射到一个特定的区间,数据标准化是将数据转换为均值为0,标准差为1的分布。
模型评估:
在分类任务中,常用的评估指标有准确率、精确率、召回率和F1 - score。准确率是指模型正确预测的样本数占总样本数的比例;精确率是指在预测为正类的样本中真正为正类的比例;召回率是指在真实为正类的样本中被正确预测为正类的比例;F1 - score是精确率和召回率的调和平均数。在回归任务中,常用的评估指标有均方误差(MSE)、平均绝对误差(MAE)等,这些指标可以帮助我们了解模型的性能,选择合适的模型和参数。
之后使用python进行模型的搭建,见文章:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











