






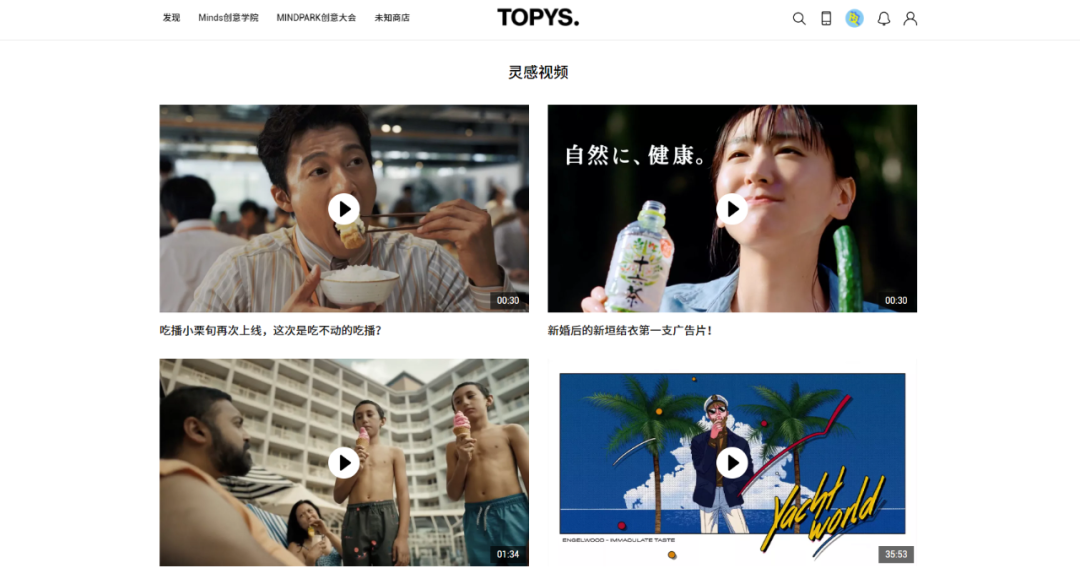
一个创意灵感网站,某个频道都是灵感创意视频,其数据是异步加载方式,特别适合python新人json数据解析获取练习实践,基本上没有什么限制,不妨跟随本渣渣的脚步一起来撸一发!
关键要点:
requests.post() 获取数据
response.json() 数据解析
mp4视频格式文件下载方法
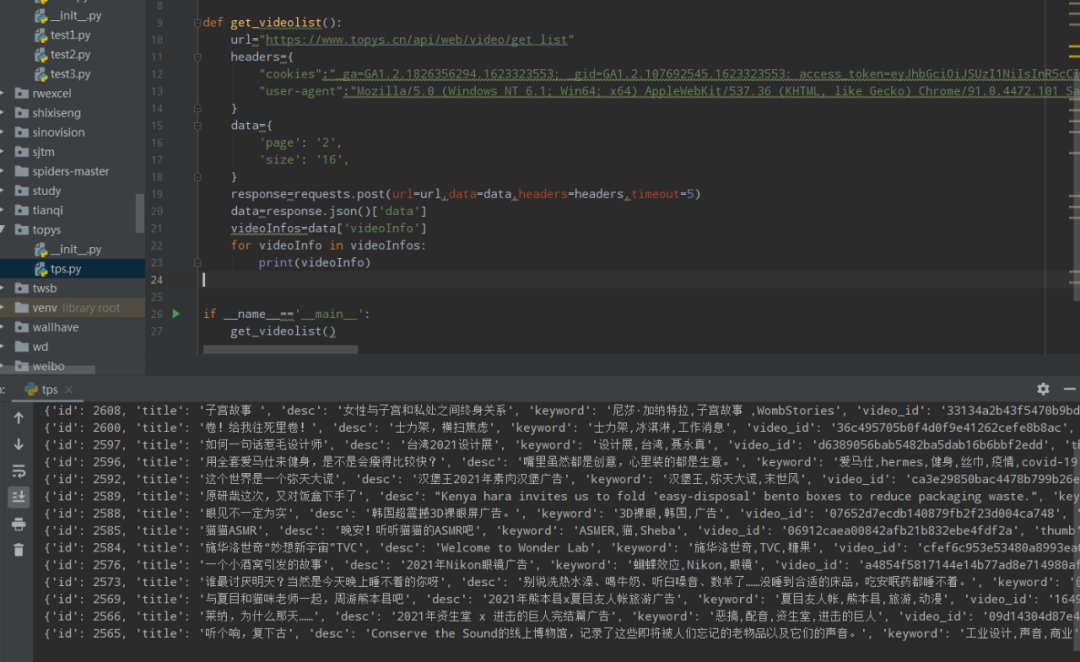
获取视频列表内容信息
通过灵感视频栏目可以知晓,加载更多数据的方式是异步加载,进一步通过抓包可以获悉,该网站视频数据是通过post方式以json格式交互数据给前台用户,这里我们就可以应用requests.post来构造,当然你需要知晓api接口地址,以及提交的数据,尤其是页码数据,好在网页没有什么加密以及限制。

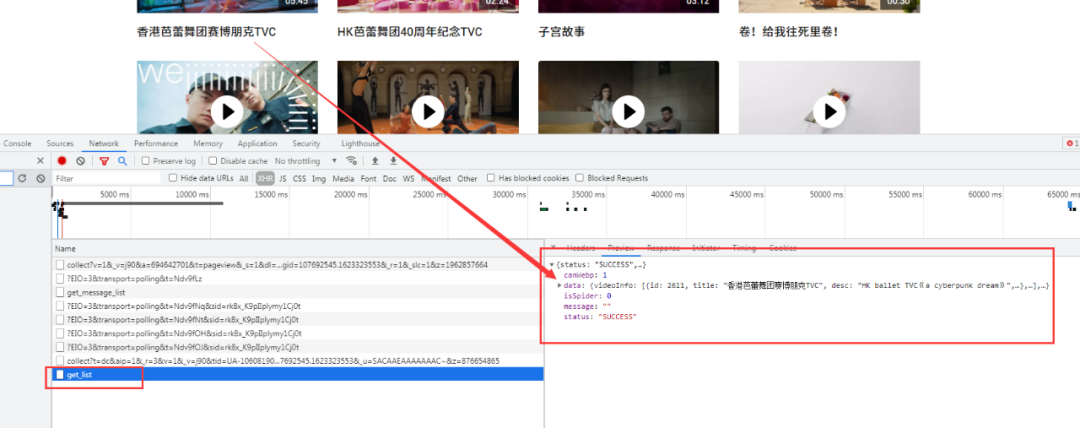
获取视频列表源码参考:
#获取视频列表
def get_videolist(page):
print(f'>> 正在获取第 {page} 页视频数据..')
url="https://www.topys.cn/api/web/video/get_list"
headers={
"cookies":cookise,
"user-agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36",
}
data={
'page': page,
'size': '16',
}
response=requests.post(url=url,data=data,headers=headers,timeout=5)
data=response.json()['data']
videoInfos=data['videoInfo']
if videoInfos:
print(">> 存在视频数据,开始解析视频数据..")
for videoInfo in videoInfos:
title=videoInfo['title']
video_id=videoInfo['video_id']
PS:这里需要提醒的是,网站视频观看及获取都是需要在登陆的操作前提下,你只需要在headers协议头里提交上自己的cookise信息即可!
获取真实视频播放地址及相关信息
同样的,通过进一步视频播放的观察和抓包,我们可以很容易得知单个视频的信息及播放地址也是通过post方式以json格式交互数据给前台用户,以同样的方式获取到我们想要的真实视频地址。
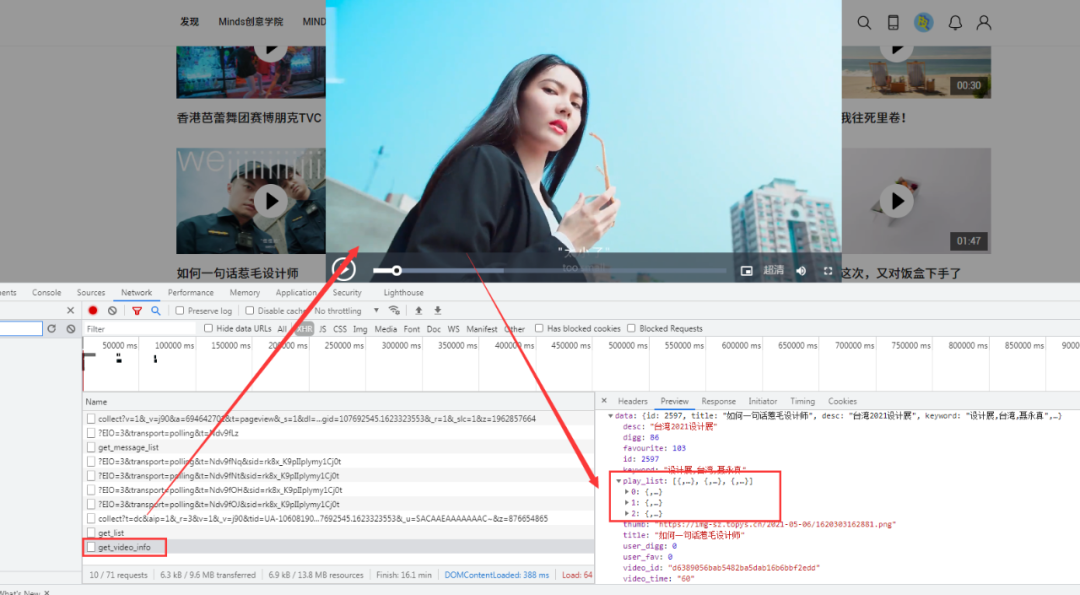
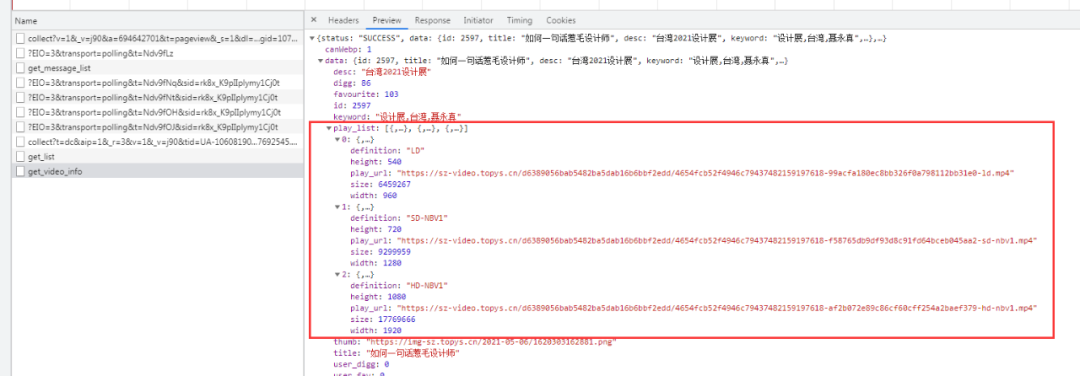
获取视频地址源码参考:
#获取真实视频地址信息
def get_video_info(video_id):
url = "https://www.topys.cn/api/web/video/get_video_info"
headers = {
"cookies": cookise,
"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36",
}
data = {
"video_id":video_id,
}
response = requests.post(url=url, data=data, headers=headers, timeout=5)
data=response.json()['data']
play_list=data['play_list']
play_url=play_list[-1]['play_url']
print(f'>> 已经获取1920真实播放地址:{play_url}')
return play_url
response.json()解析json格式数据,可能不少json格式数据比较多,这里建议大家多尝试调试和测试来获取到自己想要获取的信息数据。
下载mp4格式视频文件
如果你有应用过python下载过图片文件,尤其是requests的方式,那么对于下载视频文件的话,其实还是比较简单的,方法类似,不过该视频网站下载的话存在一个比较明显的反爬,那就是在下载的headers协议头上你需要加上referer地址,不然会下载不到正确的视频文件内容。
下载视频文件源码参考:
#下载视频
def down_video(title,play_url):
pattern = r"[\/\\\:\*\?\"\<\>\|]"
title = re.sub(pattern, "_", title) # 替换为下划线
play_title=f'{title}.{play_url.split(".")[-1]}'
headers={
'referer': 'https://www.topys.cn/video',
'user-agent':UserAgent().random,
}
r=requests.get(url=play_url,headers=headers,timeout=6)
with open(play_title,'wb') as f:
f.write(r.content)
print(f'>> 下载 {play_title} 视频完成!')
以上,就是全篇内容,仅供参考学习交流使用,请忽略本渣渣的胡言乱语,整体上比较简单,适合新人学习和参考,实践,注意爬取有度!
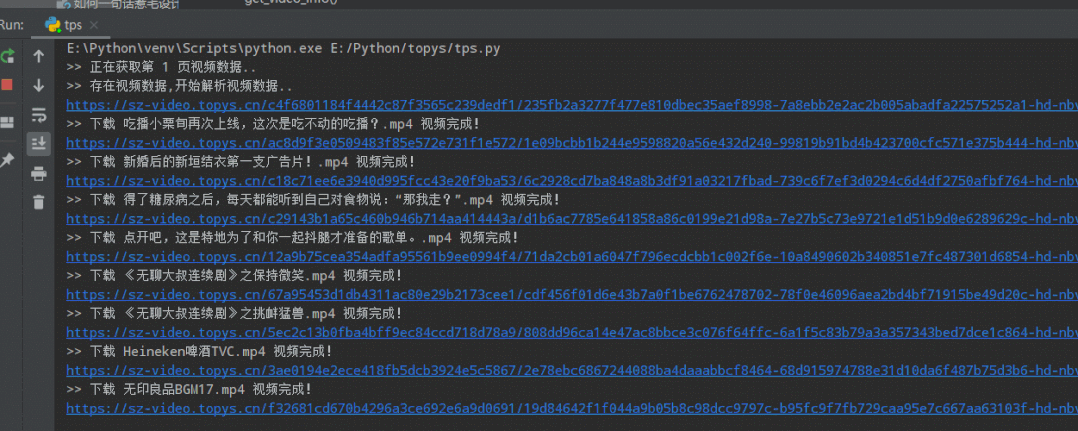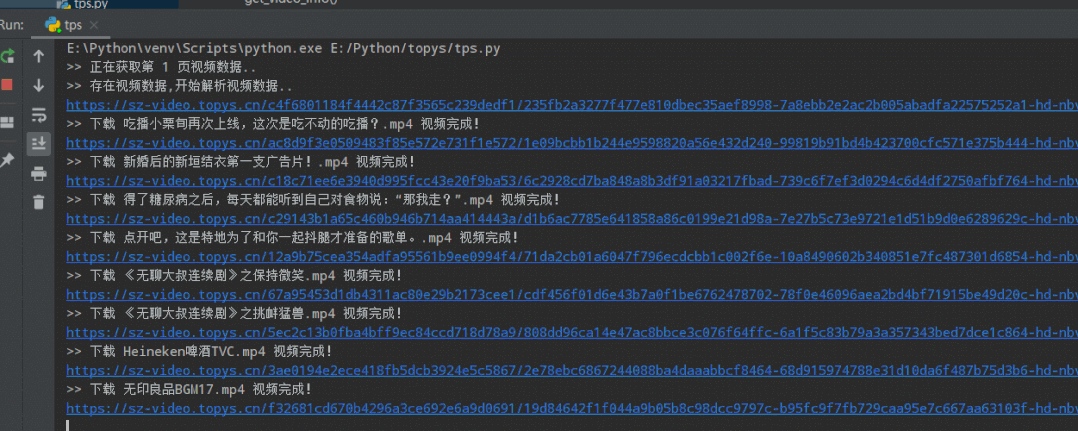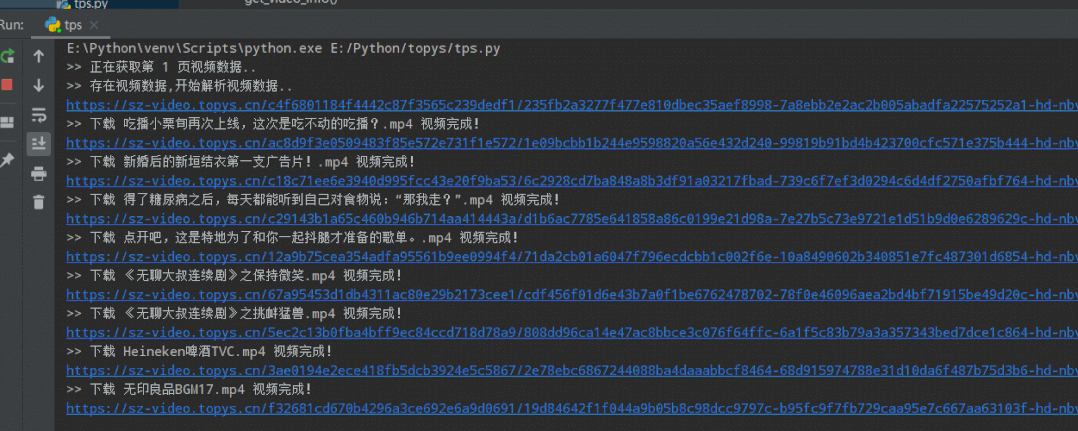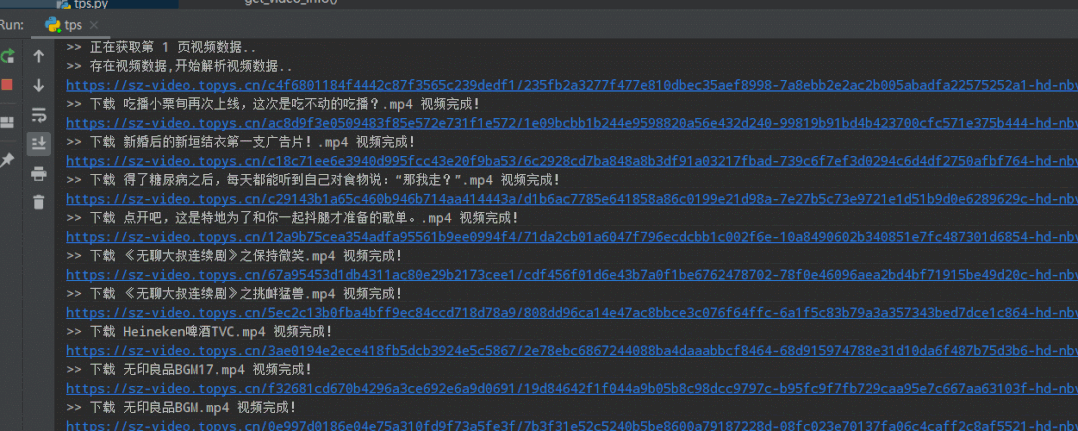
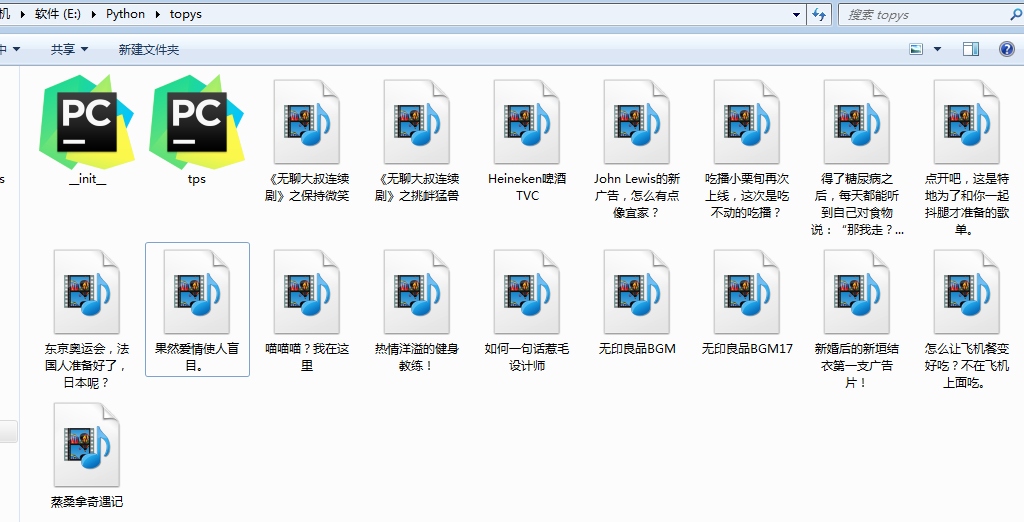
爬取下载视频效果
想要获取完整源码文件代码的老哥可以关注本渣渣微信公众号,后台回复“视频爬取”!
完整源码获取
关注本渣渣微信公众号

后台回复: 视频爬取
即可获取视频爬取下载完整源码
查看更多爬虫文章
视频:端午充实的假期
提前祝大家端午节快乐!
·················END·················
你好,我是二大爷,
革命老区外出进城务工人员,
互联网非早期非专业站长,
喜好python,写作,阅读,英语
不入流程序,自媒体,seo . . .
公众号不挣钱,交个网友。
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注二大爷呗~给你分享python,写作,阅读的内容噢~
扫一扫下方二维码即可关注我噢~
有趣的灵魂在等你

长按扫码关注















 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









