






如何凭借一个汉字的UTF-8编码,得到该汉字的字符串呢?
比如凭借E7BB98这一UTF-8编码得到汉字字符串"织".
首先,对一个汉字字符(串)进行.encode(),可得到一个以UTF-8(默认参数)编码的bytes类型。
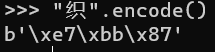
可通过对bytes对象进行.decode()(默认UTF-8)来得到该汉字字符串。
虽然有raw_unicode_escape这样的参数可以在不改变字符串的内容的前提下按原样转换至bytes,从而得到我们想要的bytes

但Python的字符串里,\x应该是不能单独出现的。

对python似乎也不支持对bytes对象进行直接修改。
经过查阅资料,通过用到一个在binascii中叫做unhexlify的函数,可直接将UTF-8编码转换至我们想要的bytes对象。
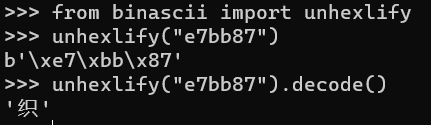
原帖链接:https://www.daniweb.com/programming/software-development/threads/494123/how-can-i-add-add-x
另外一个方法:
utf8code = "e7bb87"
backslash_joined = "\\x".join([""]+[utf8code[idx:idx+2] for idx in range(0,6,2)])
character = backslash_joined.encode().decode('unicode_escape').encode("raw_unicode_escape").decode('utf-8')
















 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









