






进阶数据结构
树
树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
树的特点
- 每个结点有零个或多个子节点
- 每一个非根结点有且只有一个父节点
- 只有根节点没有父节点
- 除了根结点外,每个子节点可以分为多个不相交的子树叶子节点
树的相关定义
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3d723Nxy-1612864710794)(1.png)]](https://img-blog.csdnimg.cn/20210209181508731.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
如上图所示
节点的度: 一个节点含有的子树的个数称为该节点的度; 如上图:A的为6
叶节点或终端节点: 度为0的节点称为叶节点; 如上图:B、C、H、I…等节点为叶节点
非终端节点或分支节点: 度不为0的节点; 如上图:D、E、F、G…等节点为分支节点
双亲节点或父节点: 若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
孩子节点或子节点: 一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
兄弟节点: 具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
树的度: 一棵树中,最大的节点的度称为树的度; 如上图:树的度为6
节点的层次: 从根开始定义起,根为第1层,根的子节点为第2层,以此类推
树的高度或深度: 树中节点的最大层次; 如上图:树的高度为4
堂兄弟节点: 双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
节点的祖先: 从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙: 以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林: 由m(m>0)棵互不相交的树的集合称为森林
树的表示
-
表示一棵树:主要是找节点、节点之间的关系。
-
表示方式:双亲表示法、孩子表示法、孩子兄弟表示法等
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kOrvxrT9-1612864710795)(2.png)]](https://img-blog.csdnimg.cn/2021020918152054.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OHvpxc2s-1612864710797)(3.png)]](https://img-blog.csdnimg.cn/20210209181526952.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fZMhq7TT-1612864710800)(4.png)]](https://img-blog.csdnimg.cn/20210209181533515.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
-
双亲表示法
struct Node{
int data;//当前节点的值域
struct Node* parent;//当前节点的双亲位置
}
1234
- 孩子表示法:孩子给几个主要取决于树的度是多少。
假设这棵树的度为2。
struct Node{
int data;
struct Node* child1;
struct Node* child2;
}
12345
- 孩子兄弟表示法
struct Node{
struct Node* child;
struct Node* brother;
int data;
}
二叉树基本概念
二叉树的定义
一棵二叉树是节点的一个有限集合,该集合或者为空,或者由一个根节点加上两棵左子树和右子树组成
二叉树的特点:
1、每个节点最多有两棵子树,即二叉树不存在度大于2的节点
2、二叉树的子树有左右之分,其子树的次序不能颠倒
二叉树的形式:

满二叉树:
在一棵二叉树中,所有分支节点都存在左子树和右子树,并且所有的叶节点都在同一层上

完全二叉树:
完全二叉树是由满二叉树而引出来的,若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数(即1~h-1层为一个满二叉树),第 h 层所有的结点都连续集中在最左边,这就是完全二叉树

扩充二叉树
扩充二叉树是对已有二叉树的扩充,扩充后的二叉树的节点都变为度数为2的分支节点。也就是说,如果原节点的度数为2,则不变,度数为1,则增加一个分支,度数为0的叶子节点则增加两个分支。

平衡二叉树
是一棵空树或它的任意节点的左右两个子树的高度差的绝对值不超过1
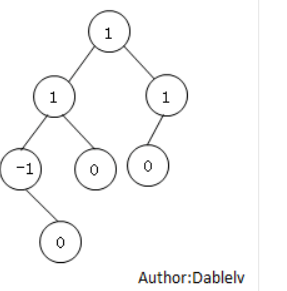
线索二叉树
如果某个结点的左孩子为空,则将空的左孩子指针域改为指向其前驱;如果某结点的右孩子为空,则将空的右孩子指针域改为指向其后继.另外应再多创建一个不存储数据的结点,供没有后继的结点指.
二叉树的性质:
1、若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2i-1个节点
2、若规定只有根节点的二叉树的深度为1,则深度为k的二叉树的最大节点数是2^k-1
3、对任何一棵二叉树,如果其叶子节点个数为n0,度为2的非叶子节点个数为n2,则n0=n2+1
4、具有n个节点的完全二叉树的深度k为log2(n+1)向上取整
5、对于具有n个节点的完全二叉树,如果按照从上至下从左至右的顺序对所有结点从0开始编号,则对于序号为i的节点有:
(1)如果i>=0,则序号为i节点的双亲结点的序号为(i-1)/2;如果i=0,则序号i节点无双亲结点
(2)如果2i+1<n,则序号i结点的左孩子的序号为2i+1,右孩子的序号为2i+2;如果2i+1>=n,则序号i节点无孩子节点
存储结构
顺序存储

优点:存储完全二叉树,简单省空间
缺点:对一般二叉树尤其单支树,存储空间利用不理想
链式存储

仿真指针存储

二叉树的应用场景
- 普通的二叉树,很难构成现实的应用场景,但因其简单,常用于学习研究,平衡二叉树则是实际应用比较多的。常见于快速匹配、搜索等方面。
- 常用的树有:AVL树、红黑树、B+树、Trie(字典)树。
1、AVL树: 最早的平衡二叉树之一。应用相对其他数据结构比较少。windows对进程地址空间的管理用到了AVL树。
2、红黑树: 平衡二叉树,广泛用在C++的STL中。如map和set都是用红黑树实现的。还有Linux文件管理。
3、B/B+树: 用在磁盘文件组织 数据索引和数据库索引。
4、Trie树(字典树): 用在统计和排序大量字符串,如自动机、M数据库索引。
二叉树的操作
二叉树的遍历
二叉树的遍历主要有三种:
1.前序遍历(根->左->右)
2.中序遍历(左->根->右)
3.后序遍历(左->右->根)
举例分析这三种情况 如下图:
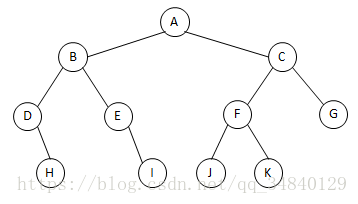
前序遍历:
每遍历一个结点,都要当作一个根对待,对这个根进行前序遍历,比如这个二叉树,从A结点开始(此时A结点是一个根,根->左->右),然后左,也就是B,再把B当作一个根(根->左->右),所以下面是D,再把B当作一个根(根->左->右),没有左,所以再右,也就是H,H没有子树了,然后再遍历B的右,也就是E,再把E当作一个根,没有左,所以右,也就是I,I没有子树了,再遍历A的右,也就是C,此时完成的遍历顺序是(A->B->D->H->E->I->C),遍历完A结点的左子树了,再遍历右,也就是C,把C当作一个根(根->左->右),左也就是F,再把F当成一个根(根->左->右),左就是J,右就是K,然后J和K都没有子树,就回去遍历C的右,也就是G,G也没有子树,此时A的右子树就遍历完了,所以这个二叉树就遍历完了,遍历完成的顺序是(A->B->D->H->E->I->C->F->J->K->G)
中序遍历
因为中序遍历是左->根->右,所以从A结点开始的时候,先遍历B,然后把B当作一个根,再遍历B的左,就是D,然后把D当作一个根,遍历D的左,D没有左子树,所以遍历D,然后右,也就是H,然后回去遍历B,再遍历他的右,也就是E,再把E当作一个根,遍历E的左,没有左,遍历E,再遍历右,也就是I,然后A的左子树都遍历完成,回去遍历A,此时遍历的顺序是(D->H->B->E->I->A),A的左子树遍历完成后,再遍历A的右子树,首先是C,然后把C当作一个根,遍历他的左,也就是F,然后把F当作一个根,遍历他的左,也就是J,然后J没有子树,回去遍历根F后,再遍历右,也就是K,K也没有子树,所以C的左子树遍历完了,再遍历C后,遍历右,也就是G,此时G没有子树,所以A的右子树遍历完了,所以这个二叉树就遍历完了,遍历完成的顺序是(D->H->B->E->I->A->J->F->K->C->G)
后序遍历
因为后序遍历是左->右->根,所以从A结点开始时,先遍历左,也就是B,然后把B当作一个根,再遍历他的左,也就是D,然后把D当作一个根,他没有左子树,所以再遍历他的右,也就是H,然后回去遍历根,也就是D,然后再回去遍历B的右,也就是E,把E当作一个根,E没有左子树,所以遍历他的右,也就是I,然后回去遍历根E,然后再回去遍历根B,此时A的左子树遍历完成,遍历顺序是(H->D->I->E->B),然后遍历A的右,也就是C,把C当作一个根,再遍历C的左,也就是F,把F当作一个根,再遍历他的左也就是J,然后遍历右也就是K,回去遍历根F,然后遍历根C的右,也就是G,然后回去遍历根C,最后回去遍历根A,此时A的右子树遍历完成,所以二叉树遍历完成,遍历顺序是(H->D->I->E->B->J->K->F->G->C->A)
例题
通过二叉树的中序和另一种序列,可以得到一颗唯一的二叉树,并推出另一序列。
1.前序中序画树并推出后序序列

解析:由前序序列可以得知,A是二叉树的根,所以再看中序序列,就可以知道,HBDF是二叉树的左子树,EKCG是二叉树的右子树,然后由前序序列还可以得知B是左子树的根结点,然后由中序序列还可以得知H是B的左子树结点,DF是右子树结点,D是F的左子树结点,此时A的左子树就推断完了,然后推右子树,由前序序列得知E是A的右子树根节点,由中序序列得知,E没有左子树,否则遍历完左子树不能立刻遍历E,然后由中序/前序序列可知C是E的右子树结点,K是C的左子树,G是C的右子树,然后画出整个二叉树即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NkElEOMN-1612864710800)(15.png)]](https://img-blog.csdnimg.cn/20210209180216664.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
再根据二叉树可推知后序序列是 HDFBKGCEA ,因此选择B。
2.中序后序画树并推出前序序列
中序遍历: ADEFGHMZ
后序遍历: AEFDHZMG
解析:由后序序列可知G是二叉树的根节点,由中序序列可知ADEF是左子树,HMZ是右子树,由后序序列可知D是左子树根节点,M是右子树根节点,由后序/中序序列可知,A是D的左子树结点,EF是D的右子树结点,E是F的左子树结点,由中序/后序序列可知H是M的左子树结点,Z是M的右子树结点,然后画出二叉树.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h3cMB5Fg-1612864710801)(16.png)]](https://img-blog.csdnimg.cn/20210209180245259.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
所以前序序列为 GDAFEMHZ
二叉树的创建
//前序创建
void CreatrBiTree(Bitreenode* t)
{
int data;
cin >> data;
if (data == 0)
*t = NULL;
else
{
*t = new BiTree;
if (!(*t))
return;
(*t)->data = data;
CreatrBiTree(&(*t)->lchild);
CreatrBiTree(&(*t)->rchild);
}
}
二叉树的遍历(代码实现)
前序遍历
//前序遍历 根 左 右
void showBiTree(Bitreenode t,int level)
{
if (t == NULL)
return;
else
{
cout << t->data << "在第" << level << "层" << endl;
showBiTree(t->lchild,level+1);
showBiTree(t->rchild,level+1);
}
}
中序遍历
//中序遍历 左 根 右
void SHowBiTree(Bitreenode t,int level)
{
if (t == NULL)
return;
else
{
SHowBiTree(t->lchild, level + 1);
cout << t->data << "在第" << level << "层" << endl;
SHowBiTree(t->rchild, level + 1);
}
}
后序遍历
//中序遍历 左 根 右
void SHowBiTree(Bitreenode t,int level)
{
if (t == NULL)
return;
else
{
SHowBiTree(t->lchild, level + 1);
cout << t->data << "在第" << level << "层" << endl;
SHowBiTree(t->rchild, level + 1);
}
}
二叉树结点数
//结点个数
int jiedianmember(Bitreenode t)
{
if (t == NULL)
return 0;
else
{
return jiedianmember(t->lchild) + jiedianmember(t->rchild) + 1;
}
}
二叉树子结点数
//子结点个数
int zijiedianmember(Bitreenode t)
{
if (t == NULL)
return 0;
if (t->lchild == NULL && t->rchild == NULL)
return 1;
return zijiedianmember(t->lchild) + zijiedianmember(t->rchild);
}
某一层结点数
//第k层结点个数 就是求上一层子结点个数 方便写递归
int dikzijiemember(Bitreenode t,int k)
{
if (t == NULL)
return 0;
if (k == 0)
return 1;
return dikzijiemember(t->lchild,k-1) + dikzijiemember(t->rchild,k-1);
}
输出某一层
//输出第i层
void showiceng(Bitreenode t,int i)
{
if (t == NULL)
return;
if (i == 0)
{
cout << t->data<<endl;
return;
}
showiceng(t->lchild, i-1);
showiceng(t->rchild, i-1);
}
层序遍历
//层序遍历
void cengshowBiTree(Bitreenode t)
{
if (t == NULL)
return;
else
{
for (int i = 0; i <= 3; i++)
{
showiceng(t,i);//输出每层的函数
}
}
}
查找某个数
//查找某个数
Bitreenode searchx(Bitreenode t,int x)
{
Bitreenode boot;
if (t == NULL)
return NULL;
if (t->data == x)
return t;
boot = searchx(t->lchild, x);
if (boot)
return boot;
return searchx(t->rchild, x);
}
销毁二叉树
//销毁二叉树
void DestroyBiTree(Bitreenode* t)
{
if (*t)
{
DestroyBiTree(&(*t)->lchild);
DestroyBiTree(&(*t)->rchild);
delete (*t);
*t = NULL;
}
}
完整代码
#include<iostream>
using namespace std;
typedef struct BiTree
{
int data;
struct BiTree* lchild,*rchild;
}BiTree,*Bitreenode;
//前序创建
void CreatrBiTree(Bitreenode* t)
{
int data;
cin >> data;
if (data == 0)
*t = NULL;
else
{
*t = new BiTree;
if (!(*t))
return;
(*t)->data = data;
CreatrBiTree(&(*t)->lchild);
CreatrBiTree(&(*t)->rchild);
}
}
//前序遍历 根 左 右
void showBiTree(Bitreenode t,int level)
{
if (t == NULL)
return;
else
{
cout << t->data << "在第" << level << "层" << endl;
showBiTree(t->lchild,level+1);
showBiTree(t->rchild,level+1);
}
}
//中序遍历 左 根 右
void SHowBiTree(Bitreenode t,int level)
{
if (t == NULL)
return;
else
{
SHowBiTree(t->lchild, level + 1);
cout << t->data << "在第" << level << "层" << endl;
SHowBiTree(t->rchild, level + 1);
}
}
//后序遍历 左 右 根
void SHOWBiTree(Bitreenode t, int level)
{
if (t == NULL)
return;
else
{
SHOWBiTree(t->lchild,level+1);
SHOWBiTree(t->rchild,level+1);
cout << t->data << "在第" << level << "层" << endl;
}
}
//销毁二叉树
void DestroyBiTree(Bitreenode* t)
{
if (*t)
{
DestroyBiTree(&(*t)->lchild);
DestroyBiTree(&(*t)->rchild);
delete (*t);
*t = NULL;
}
}
//结点个数
int jiedianmember(Bitreenode t)
{
if (t == NULL)
return 0;
else
{
return jiedianmember(t->lchild) + jiedianmember(t->rchild) + 1;
}
}
//子结点个数
int zijiedianmember(Bitreenode t)
{
if (t == NULL)
return 0;
if (t->lchild == NULL && t->rchild == NULL)
return 1;
return zijiedianmember(t->lchild) + zijiedianmember(t->rchild);
}
//第k层结点个数 就是求上一层子结点个数 方便写递归
int dikzijiemember(Bitreenode t,int k)
{
if (t == NULL)
return 0;
if (k == 0)
return 1;
return dikzijiemember(t->lchild,k-1) + dikzijiemember(t->rchild,k-1);
}
//输出第i层
void showiceng(Bitreenode t,int i)
{
if (t == NULL)
return;
if (i == 0)
{
cout << t->data<<endl;
return;
}
showiceng(t->lchild, i-1);
showiceng(t->rchild, i-1);
}
//层序遍历
void cengshowBiTree(Bitreenode t)
{
if (t == NULL)
return;
else
{
for (int i = 0; i <= 3; i++)
{
showiceng(t,i);//输出每层的函数
}
}
}
//查找某个数
Bitreenode searchx(Bitreenode t,int x)
{
Bitreenode boot;
if (t == NULL)
return NULL;
if (t->data == x)
return t;
boot = searchx(t->lchild, x);
if (boot)
return boot;
return searchx(t->rchild, x);
}
int main()
{
Bitreenode tree;
CreatrBiTree(&tree);
showBiTree(tree, 0);
SHowBiTree(tree, 0);
SHOWBiTree(tree, 0);
int ret=jiedianmember(tree);
cout <<"结点个数为:"<< ret << endl;
int Ret = zijiedianmember(tree);
cout<<"子结点个数为:"<<Ret<<endl;
int REt = dikzijiemember(tree, 1);
cout << "第一层结点个数为:" << REt << endl;
showiceng(tree, 2);
cengshowBiTree(tree);
tree=searchx(tree, 5);
cout << tree;
DestroyBiTree(&tree);
return 0;
}
树和二叉树的转换
树转二叉树
1.加线:在兄弟之间加一连线
2.抹线:对每个结点,除了左孩子外,去除与其余孩子之间的关系
3.旋转:一树的根结点为轴心,将整数顺时针旋转45°
例子:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y6Kepqv1-1612864710802)(../AppData/Roaming/Typora/typora-user-images/1612518201847.png)]](https://img-blog.csdnimg.cn/2021020918030618.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
二叉树转树
1.加线:若某一结点是双亲结点的左孩子,则将该结点的右孩子,右孩子的右孩子…沿分支找到的所有右孩子,都与该结点的双亲用线连起来.
2.抹线:抹掉原二叉树中双亲与右孩子之间的连线
3.调整:将结点按层次排列,形成树结构
例子:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s7jBhcYq-1612864710802)(../AppData/Roaming/Typora/typora-user-images/1612518533827.png)]](https://img-blog.csdnimg.cn/20210209180321138.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
森林
概念:
多颗互不相交的树的集合;
性质:
树中的结点数等于所有结点的度数加1(含有n个结点的树边数为n-1)
树中有n-1条边,所有结点的度数为n-1 ->此树中含有n个结点
m叉树中中第i层最多有m^(i-1)个结点;
第一层1个,第二程m个,第三层m2个,数学归纳法得出第i层最多有m(i-1)个
树高为h的m叉树最多有(m^h-1)/(m-1)个结点;
1+m+m2+…+m(h-1) 等比数列求和
含有n个结点的m叉树的最小高度为 logm[n(m-1)+1]上取整;
让每一层都达到最大结点数,所形成的树高度最小;
(mh-1)/(m-1)>=n且(m(h-1)-1)/(m-1)<n;
求解两方程得出
logm[n(m-1)+1]<=h<logm[n(m-1)+1]+1
森林和二叉树的转换
森林转二叉树
1.转换:将各棵树分别转换成二叉树
2.连线:将每棵树的根节点用线相连
3.旋转:以第一棵树根节点为二叉树的根,再以根节点为轴心,顺时针旋转,构成二叉树型结构
例子:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vsSInuOJ-1612864710802)(../AppData/Roaming/Typora/typora-user-images/1612519002510.png)]](https://img-blog.csdnimg.cn/20210209180335482.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
二叉树转森林
1.抹线:将二叉树根节点与其右孩子连线,及沿右分支搜索到的所有右孩子间连线全部抹掉,使之变成孤立的二叉树
2.还原:将孤立的二叉树还原成树
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s9wUymIc-1612864710803)(../AppData/Roaming/Typora/typora-user-images/1612519637125.png)]](https://img-blog.csdnimg.cn/2021020918034986.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
树和森林的遍历
树的遍历
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LEwRvuGM-1612864710803)(../AppData/Roaming/Typora/typora-user-images/1612519932724.png)]](https://img-blog.csdnimg.cn/20210209180359163.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
森林的遍历
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c4TvRym1-1612864710804)(../AppData/Roaming/Typora/typora-user-images/1612521281836.png)]](https://img-blog.csdnimg.cn/20210209180407103.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
先序遍历
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5PakhkqP-1612864710804)(../AppData/Roaming/Typora/typora-user-images/1612521406607.png)]](https://img-blog.csdnimg.cn/20210209180417690.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
中序遍历
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tyecMBBA-1612864710804)(../AppData/Roaming/Typora/typora-user-images/1612521482742.png)]](https://img-blog.csdnimg.cn/20210209180426174.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
例子:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T1DpNmqD-1612864710805)(../AppData/Roaming/Typora/typora-user-images/1612521538713.png)]](https://img-blog.csdnimg.cn/20210209180436678.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
哈夫曼树(最优二叉树)
哈夫曼树的基本概念
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oebjRdp7-1612864710805)(../AppData/Roaming/Typora/typora-user-images/1612533040621.png)]](https://img-blog.csdnimg.cn/20210209180446155.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IhCHDKfC-1612864710805)(../AppData/Roaming/Typora/typora-user-images/1612533729985.png)]](https://img-blog.csdnimg.cn/20210209180454181.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bSsZlZWA-1612864710806)(../AppData/Roaming/Typora/typora-user-images/1612533641837.png)]](https://img-blog.csdnimg.cn/20210209180501627.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KPTesH2i-1612864710806)(../AppData/Roaming/Typora/typora-user-images/1612534122094.png)]](https://img-blog.csdnimg.cn/20210209180510647.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1xMKCZZ7-1612864710807)(../AppData/Roaming/Typora/typora-user-images/1612534591766.png)]](https://img-blog.csdnimg.cn/20210209180519280.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
哈夫曼树的构建
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mySJyTna-1612864710807)(../AppData/Roaming/Typora/typora-user-images/1612535893678.png)]](https://img-blog.csdnimg.cn/2021020918052847.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
构建代码实现
typedef struct huff
{
int weight;
int parent, lchild, rchild;
}huff,*hufftree;
首先初始化令 parent=0, lchild=0, rchild=0,然后初始化n个叶子节点,输入0-n结点的权值。
void createbufftree(hufftree hf)
{
int n,m;
cin >> n;
if (n <= 1)
return;
m = 2 * n - 1;//数组有2n-1个元素
hf = new huff[m];//申请n个也就是2n-1个空间,0-n
for (int i = 0; i < m; i++)//将 2n-1个结点都初始化
{
hf->lchild = 0;
hf->rchild = 0;
hf->parent = 0;
}
for (int i = 0; i < n; i++)//输入前n个结点的权值
{
cin >> hf[i].weight;
}
}
初始化完成后,进行下面n-1次合并,依次产生n-1个结点hf[i],i=n-2n,在[0…i]中选两个未被选过的,且parent==0的结点中选权值最小的两个结点:hf[s1],hf[s2]
然后修改这两个结点的parent值,hf[s1].parent=i,hf[s2].parent=i
然后修改新产生的hf[i],hf[i].weifht=hf[s1].weight+hf[s2].weight,hf[i].lchild=s1,hf[i].rchild=s2.
哈夫曼编码
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wBU8URvc-1612864710807)(../AppData/Roaming/Typora/typora-user-images/1612621588678.png)]](https://img-blog.csdnimg.cn/20210209180539472.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D6oREIH9-1612864710808)(../AppData/Roaming/Typora/typora-user-images/1612621694893.png)]](https://img-blog.csdnimg.cn/20210209180601855.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W0LtV5k3-1612864710808)(../AppData/Roaming/Typora/typora-user-images/1612621738965.png)]](https://img-blog.csdnimg.cn/20210209180646435.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OrOm4RRQ-1612864710809)(../AppData/Roaming/Typora/typora-user-images/1612621802126.png)]](https://img-blog.csdnimg.cn/20210209180704767.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-88HjOHkL-1612864710809)(../AppData/Roaming/Typora/typora-user-images/1612621835151.png)]](https://img-blog.csdnimg.cn/20210209180712527.png#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cnKXYfnt-1612864710810)(../AppData/Roaming/Typora/typora-user-images/1612621863937.png)]](https://img-blog.csdnimg.cn/20210209180720602.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gxJiBSK2-1612864710810)(../AppData/Roaming/Typora/typora-user-images/1612624303720.png)]](https://img-blog.csdnimg.cn/20210209180729608.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
完整代码
#include<iostream>
using namespace std;
#pragma warning (disable:4996)
#define maxSize 100
/*
赫夫曼树的存储结构,它也是一种二叉树结构,
这种存储结构既适合表示树,也适合表示森林。
*/
typedef struct Node
{
int weight; //权值
int parent; //父节点的序号,为-1的是根节点
int lchild, rchild; //左右孩子节点的序号,为-1的是叶子节点
}HTNode, *HuffmanTree; //用来存储赫夫曼树中的所有节点
typedef char **HuffmanCode; //用来存储每个叶子节点的赫夫曼编码
HuffmanTree create_HuffmanTree(int *wet, int n);
void select_minium(HuffmanTree HT, int k, int &min1, int &min2);
int min(HuffmanTree HT, int k);
void HuffmanCoding1(HuffmanTree HT, HuffmanCode &HC, int n);
void HuffmanCoding2(HuffmanTree HT, HuffmanCode &HC, int n);
int countWPL1(HuffmanTree HT, int n);
int countWPL2(HuffmanTree HT, int n);
int main()
{
int w[] = { 5,4,3,2,1 };//用数组w存储各个权值
int n=5;//表示数组w中的个数
HuffmanCode HC = NULL;
HuffmanTree hTree = create_HuffmanTree(w, n);
int wpl1 = countWPL1(hTree, n);
printf("从叶子结点开始遍历二叉树求最小带权路径长度WPL=%d\n", wpl1);
int wpl2 = countWPL2(hTree, n);
printf("从根结点开始遍历二叉树求最小带权路径长度WPL=%d\n", wpl2);
printf("\n从叶子到根结点编码结果为:\n");
HuffmanCoding1(hTree, HC, n);
printf("\n从根结点到叶子结点编码结果为:\n");
HuffmanCoding2(hTree, HC, n);
system("pause");
return 0;
}
/*根据给定的n个权值构造一棵赫夫曼树,wet中存放n个权值*/
HuffmanTree create_HuffmanTree(int *wet, int n)
{
//一棵有n个叶子节点的赫夫曼树共有2n-1个节点
int total = 2 * n - 1;
HuffmanTree HT = (HuffmanTree)malloc(total * sizeof(HTNode));
if (!HT)
{
printf("HuffmanTree malloc faild!");
exit(-1);
}
int i;
//以下初始化序号全部用-1表示,
//这样在编码函数中进行循环判断parent或lchild或rchild的序号时,
//不会与HT数组中的任何一个下标混淆
//HT[0],HT[1]...HT[n-1]中存放需要编码的n个叶子节点
for (i = 0; i < n; i++)
{
HT[i].parent = -1;
HT[i].lchild = -1;
HT[i].rchild = -1;
HT[i].weight = *wet;
wet++;
}
//HT[n],HT[n+1]...HT[2n-2]中存放的是中间构造出的每棵二叉树的根节点
for (; i < total; i++)
{
HT[i].parent = -1;
HT[i].lchild = -1;
HT[i].rchild = -1;
HT[i].weight = 0;
}
int min1, min2; //用来保存每一轮选出的两个weight最小且parent为0的节点
//每一轮比较后选择出min1和min2构成一课二叉树,最后构成一棵赫夫曼树
for (i = n; i < total; i++)
{
select_minium(HT, i, min1, min2);
HT[min1].parent = i;
HT[min2].parent = i;
//这里左孩子和右孩子可以反过来,构成的也是一棵赫夫曼树,只是所得的编码不同
HT[i].lchild = min1;
HT[i].rchild = min2;
HT[i].weight = HT[min1].weight + HT[min2].weight;
}
return HT;
}
/*
从HT数组的前k个元素中选出weight最小且parent为-1的两个,分别将其序号保存在min1和min2中
*/
void select_minium(HuffmanTree HT, int k, int &min1, int &min2)
{
min1 = min(HT, k);
min2 = min(HT, k);
}
/*
从HT数组的前k个元素中选出weight最小且parent为-1的元素,并将该元素的序号返回
*/
int min(HuffmanTree HT, int k)
{
int i = 0;
int min; //用来存放weight最小且parent为-1的元素的序号
int min_weight; //用来存放weight最小且parent为-1的元素的weight值
//先将第一个parent为-1的元素的weight值赋给min_weight,留作以后比较用。
//注意,这里不能按照一般的做法,先直接将HT[0].weight赋给min_weight,
//因为如果HT[0].weight的值比较小,那么在第一次构造二叉树时就会被选走,
//而后续的每一轮选择最小权值构造二叉树的比较还是先用HT[0].weight的值来进行判断,
//这样又会再次将其选走,从而产生逻辑上的错误。
while (HT[i].parent != -1)
i++;
min_weight = HT[i].weight;
min = i;
//选出weight最小且parent为-1的元素,并将其序号赋给min
for (; i < k; i++)
{
if (HT[i].weight < min_weight && HT[i].parent == -1)
{
min_weight = HT[i].weight;
min = i;
}
}
//选出weight最小的元素后,将其parent置1,使得下一次比较时将其排除在外。
HT[min].parent = 1;
return min;
}
/*
从叶子节点到根节点逆向求赫夫曼树HT中n个叶子节点的赫夫曼编码,并保存在HC中
*/
void HuffmanCoding1(HuffmanTree HT, HuffmanCode &HC, int n)
{
//用来保存指向每个赫夫曼编码串的指针
HC = (HuffmanCode)malloc(n * sizeof(char *));
if (!HC)
{
printf("HuffmanCode malloc faild!");
exit(-1);
}
//临时空间,用来保存每次求得的赫夫曼编码串
//对于有n个叶子节点的赫夫曼树,各叶子节点的编码长度最长不超过n-1
//外加一个'\0'结束符,因此分配的数组长度最长为n即可
char *code = (char *)malloc(n * sizeof(char));
if (!code)
{
printf("code malloc faild!");
exit(-1);
}
code[n - 1] = '\0'; //编码结束符,亦是字符数组的结束标志
//求每个字符的赫夫曼编码
int i;
for (i = 0; i < n; i++)
{
int current = i; //定义当前访问的节点
int father = HT[i].parent; //当前节点的父节点
int start = n - 1; //每次编码的位置,初始为编码结束符的位置
//从叶子节点遍历赫夫曼树直到根节点
while (father != -1)
{
if (HT[father].lchild == current) //如果是左孩子,则编码为0
code[--start] = '0';
else //如果是右孩子,则编码为1
code[--start] = '1';
current = father;
father = HT[father].parent;
}
//为第i个字符的编码串分配存储空间
HC[i] = (char *)malloc((n - start) * sizeof(char));
if (!HC[i])
{
printf("HC[i] malloc faild!");
exit(-1);
}
//将编码串从code复制到HC
strcpy(HC[i], code + start);
}
for (int i = 0; i < n; ++i) {
printf("%s\n", HC[i]);
}
free(code); //释放保存编码串的临时空间
}
/*
从根节点到叶子节点无栈非递归遍历赫夫曼树HT,求其中n个叶子节点的赫夫曼编码,并保存在HC中
*/
void HuffmanCoding2(HuffmanTree HT, HuffmanCode &HC, int n)
{
//用来保存指向每个赫夫曼编码串的指针
HC = (HuffmanCode)malloc(n * sizeof(char *));
if (!HC)
{
printf("HuffmanCode malloc faild!");
exit(-1);
}
//临时空间,用来保存每次求得的赫夫曼编码串
//对于有n个叶子节点的赫夫曼树,各叶子节点的编码长度最长不超过n-1
//外加一个'\0'结束符,因此分配的数组长度最长为n即可
char *code = (char *)malloc(n * sizeof(char));
if (!code)
{
printf("code malloc faild!");
exit(-1);
}
int cur = 2 * n - 2; //当前遍历到的节点的序号,初始时为根节点序号
int code_len = 0; //定义编码的长度
//构建好赫夫曼树后,把weight用来当做遍历树时每个节点的状态标志
//weight=0表明当前节点的左右孩子都还没有被遍历
//weight=1表示当前节点的左孩子已经被遍历过,右孩子尚未被遍历
//weight=2表示当前节点的左右孩子均被遍历过
int i;
for (i = 0; i < cur + 1; i++)
{
HT[i].weight = 0;
}
//从根节点开始遍历,最后回到根节点结束
//当cur为根节点的parent时,退出循环
while (cur != -1)
{
//左右孩子均未被遍历,先向左遍历
if (HT[cur].weight == 0)
{
HT[cur].weight = 1; //表明其左孩子已经被遍历过了
if (HT[cur].lchild != -1)
{ //如果当前节点不是叶子节点,则记下编码,并继续向左遍历
code[code_len++] = '0';
cur = HT[cur].lchild;
}
else
{ //如果当前节点是叶子节点,则终止编码,并将其保存起来
code[code_len] = '\0';
HC[cur] = (char *)malloc((code_len + 1) * sizeof(char));
if (!HC[cur])
{
printf("HC[cur] malloc faild!");
exit(-1);
}
strcpy(HC[cur], code); //复制编码串
}
}
//左孩子已被遍历,开始向右遍历右孩子
else if (HT[cur].weight == 1)
{
HT[cur].weight = 2; //表明其左右孩子均被遍历过了
if (HT[cur].rchild != -1)
{ //如果当前节点不是叶子节点,则记下编码,并继续向右遍历
code[code_len++] = '1';
cur = HT[cur].rchild;
}
}
//左右孩子均已被遍历,退回到父节点,同时编码长度减1
else
{
HT[cur].weight = 0;
cur = HT[cur].parent;
--code_len;
}
}
for (int i = 0; i < n; ++i) {
printf("%s\n", HC[i]);
}
free(code);
}
/*
从叶子结点开始遍历二叉树直到根结点,根结点为HT[2n-1],且HT[2n-1].parent=-1;
各叶子结点为HT[0]、HT[1]...HT[n-1]。
关键步骤是求出各个叶子结点的路径长度,用此路径长度*此结点的权值就是
此结点带权路径长度,最后将各个叶子结点的带权路径长度加起来即可。
*/
int countWPL1(HuffmanTree HT, int n)
{
int i,countRoads,WPL=0;
/*
由creat_huffmanTree()函数可知,HT[0]、HT[1]...HT[n-1]存放的就是各个叶子结点,
所以挨个求叶子结点的带权路径长度即可
*/
for (i = 0; i < n; i++)
{
int father = HT[i].parent; //当前节点的父节点
countRoads = 0;//置当前路径长度为0
//从叶子节点遍历赫夫曼树直到根节点
while (father != -1)
{
countRoads++;
father = HT[father].parent;
}
WPL += countRoads * HT[i].weight;
}
return WPL;
}
/*
以下是从根结点开始遍历二叉树,求最小带权路径长度。关键步骤是求出各个叶子
结点的路径长度,用此路径长度*此结点的权值就是此结点带权路径长度,最后将
各个叶子结点的带权路径长度加起来即可。
*/
int countWPL2(HuffmanTree HT, int n)
{
int cur = 2 * n - 2; //当前遍历到的节点的序号,初始时为根节点序号
int countRoads=0, WPL=0;//countRoads保存叶子结点的路径长度
//构建好赫夫曼树后,把visit[]用来当做遍历树时每个节点的状态标志
//visit[cur]=0表明当前节点的左右孩子都还没有被遍历
//visit[cur]=1表示当前节点的左孩子已经被遍历过,右孩子尚未被遍历
//visit[cur]=2表示当前节点的左右孩子均被遍历过
int visit[maxSize] = { 0 };//visit[]是标注数组,初始化为0
//从根节点开始遍历,最后回到根节点结束
//当cur为根节点的parent时,退出循环
while (cur != -1)
{
//左右孩子均未被遍历,先向左遍历
if (visit[cur]==0)
{
visit[cur] = 1; //表明其左孩子已经被遍历过了
if (HT[cur].lchild != -1)
{ //如果当前节点不是叶子节点,则路径长度+1,并继续向左遍历
countRoads++;
cur = HT[cur].lchild;
}
else
{ //如果当前节点是叶子节点,则计算此结点的带权路径长度,并将其保存起来
WPL += countRoads * HT[cur].weight;
}
}
//左孩子已被遍历,开始向右遍历右孩子
else if (visit[cur]==1)
{
visit[cur] = 2;
if (HT[cur].rchild != -1)
{ //如果当前节点不是叶子节点,则记下编码,并继续向右遍历
countRoads++;
cur = HT[cur].rchild;
}
}
//左右孩子均已被遍历,退回到父节点,同时路径长度-1
else
{
visit[cur] = 0;
cur = HT[cur].parent;
--countRoads;
}
}
return WPL;
}
图
图的基本概念
G=(V,E)
V:顶点(数据元素)的有穷非空集合
E:边的有穷集合
图按照边的有无方向分为无向图和有向图。无向图由顶点和边组成,有向图由顶点和弧构成。弧有弧尾和弧头之分,带箭头一端为弧头。
无向图:
每条边都是无方向的
有向图:
每条边都是有方向的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hqkqF8rl-1612864710811)(../AppData/Roaming/Typora/typora-user-images/1612796780465.png)]](https://img-blog.csdnimg.cn/20210209180745584.png#pic_center)
完全图:
任意两个点都有一条边相连
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KnHau4R1-1612864710811)(../AppData/Roaming/Typora/typora-user-images/1612796840030.png)]](https://img-blog.csdnimg.cn/20210209180754418.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
稀疏图:
有很少边或弧的图(e<nlogn)
稠密图:
有很多边或弧的图
网:
边/弧带权的图
邻接:
有边/弧相连的两个顶点之间的关系
存在(vi,vj)(无向图,两点直接有线),则称vi,vj互为邻接点
存在 <vi,vj>(有向图,从vi到vj有线),则称vi邻接到vj,vj邻接于vi
关联(依附):
边/弧与顶点之间的关系
存在(vi,vj)/<vi,vj>,则称该边/弧关联与vi和vj
顶点的度:
与该顶点相关联的边的数目,记为TD(v)
在有向图中,顶点的度等于该顶点的入度和出度之和
顶点v的入度是以v为终点的有向边的条数,记作ID(v)
顶点v的出度是以v为始点的有向边的条数,记作OD(v)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f35vQtbS-1612864710811)(../AppData/Roaming/Typora/typora-user-images/1612797419902.png)]](https://img-blog.csdnimg.cn/2021020918080567.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
当有向图中仅一个顶点的入度为0,其余顶点的入度均为1,此时是有向树
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8AAH3TQq-1612864710811)(../AppData/Roaming/Typora/typora-user-images/1612797509140.png)]](https://img-blog.csdnimg.cn/20210209180813604.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
路径:
接续的边(若干条)构成的顶点序列
路径长度:
路径上边或弧的数目/权值之和
回路(环):
第一个顶点和最后一个顶点相同的路径
简单路径:
除路径起点和终点相同外,其余顶点均不相同的路径
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XOUHqCml-1612864710812)(../AppData/Roaming/Typora/typora-user-images/1612798024350.png)]](https://img-blog.csdnimg.cn/20210209180824159.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
连通图(强连通图):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1hKveQRs-1612864710813)(../AppData/Roaming/Typora/typora-user-images/1612798147307.png)]](https://img-blog.csdnimg.cn/20210209180833971.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
权与网:
图中边或弧所具有的相关数称为权,表明从一个顶点到另一个顶点的距离或损耗。
带权的图称为网
子图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ggcnhzDQ-1612864710813)(../AppData/Roaming/Typora/typora-user-images/1612798303851.png)]](https://img-blog.csdnimg.cn/20210209180842925.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
连通分量(强连通分量):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ySXZVPAT-1612864710814)(../AppData/Roaming/Typora/typora-user-images/1612798428016.png)]](https://img-blog.csdnimg.cn/20210209180852436.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OVq4dzH3-1612864710814)(../AppData/Roaming/Typora/typora-user-images/1612798573778.png)]](https://img-blog.csdnimg.cn/20210209180901648.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
极小连通子图:
该子图是G的连通子图,在该子图中删除任何一条边,该子图不再连通
生成树与森林
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UuE3nm8F-1612864710815)(../AppData/Roaming/Typora/typora-user-images/1612798723552.png)]](https://img-blog.csdnimg.cn/20210209180911241.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21pbmdyZW5fMTMxNA==,size_16,color_FFFFFF,t_70#pic_center)
图的存储结构
图的存储结构—-邻接矩阵
图的邻接矩阵的表示方式需要两个数组来表示图的信息,一个一维数组表示每个数据元素的信息,一个二维数组(邻接矩阵)表示图中的边或者弧的信息。
如果图有n个顶点,那么邻接矩阵就是一个n*n的方阵,方阵中每个元素的值的计算公式如下:

邻接矩阵表示图的具体示例如下图所示:
首先给个无向图的实例:

下面是一个有向图的实例:

OK,到这里为止,我们给出一个无向图的邻接矩阵和一个有向图的邻接矩阵,我们可以从这两个邻接矩阵得出一些结论:
- 无向图的邻接矩阵都是沿对角线对称的
- 要知道无向图中某个顶点的度,其实就是这个顶点vi在邻接矩阵中第i行或(第i列)的元素之和;
- 对于有向图,要知道某个顶点的出度,其实就是这个顶点vi在邻接矩阵中第i行的元素之和,如果要知道某个顶点的入度,那就是第i列的元素之和。
但是,如果我们需要表示的图是一个网的时候,例如假设有个图有n个顶点,同样该网的邻接矩阵也是一个n*n的方阵,只是方阵元素的值的计算方式不同,如下图所示:

这里的wij表示两个顶点vi和vj边上的权值。无穷大表示一个计算机允许的、大于所有边上权值的值,也就是一个不可能的极限值。下面是具体示例,表示的一个有向网的图和邻接矩阵:


图的存储结构—-邻接矩阵的代码实现
#include<iostream>
using namespace std;
enum Graphkind{ DG, DN, UDG, UDN }; //{有向图,无向图,有向网,无向网}
typedef struct Node
{
int * vex; //顶点数组
int vexnum; //顶点个数
int edge; //图的边数
int ** adjMatrix; //图的邻接矩阵
enum Graphkind kind;
}MGraph;
void createGraph(MGraph & G,enum Graphkind kind)
{
cout << "输入顶点的个数" << endl;
cin >> G.vexnum;
cout << "输入边的个数" << endl;
cin >> G.edge;
//输入种类
//cout << "输入图的种类:DG:有向图 DN:无向图,UDG:有向网,UDN:无向网" << endl;
G.kind = kind;
//为两个数组开辟空间
G.vex = new int[G.vexnum];
G.adjMatrix = new int*[G.vexnum];
cout << G.vexnum << endl;
int i;
for (i = 0; i < G.vexnum; i++)
{
G.adjMatrix[i] = new int[G.vexnum];
}
for (i = 0; i < G.vexnum; i++)
{
for (int k = 0; k < G.vexnum; k++)
{
if (G.kind == DG || G.kind == DN)
{
G.adjMatrix[i][k] = 0;
}
else {
G.adjMatrix[i][k] = INT_MAX;
}
}
}
/*//输入每个元素的信息,这个信息,现在还不需要使用
for (i = 0; i < G.vexnum; i++)
{
cin >> G.vex[i];
}*/
cout << "请输入两个有关系的顶点的序号:例如:1 2 代表1号顶点指向2号顶点" << endl;
for (i = 0; i < G.edge; i++)
{
int a, b;
cin >> a;
cin >> b;
if (G.kind == DN) {
G.adjMatrix[b - 1][a - 1] = 1;
G.adjMatrix[a - 1][b - 1] = 1;
}
else if (G.kind == DG)
{
G.adjMatrix[a - 1][b - 1] = 1;
}
else if (G.kind == UDG)
{
int weight;
cout << "输入该边的权重:" << endl;
cin >> weight;
G.adjMatrix[a - 1][b - 1] = weight;
}
else {
int weight;
cout << "输入该边的权重:" << endl;
cin >> weight;
G.adjMatrix[b - 1][a - 1] = weight;
G.adjMatrix[a - 1][b - 1] = weight;
}
}
}
void print(MGraph g)
{
int i, j;
for (i = 0; i < g.vexnum; i++)
{
for (j = 0; j < g.vexnum; j++)
{
if (g.adjMatrix[i][j] == INT_MAX)
cout << "∞" << " ";
else
cout << g.adjMatrix[i][j] << " ";
}
cout << endl;
}
}
void clear(MGraph G)
{
delete G.vex;
G.vex = NULL;
for (int i = 0; i < G.vexnum; i++)
{
delete G.adjMatrix[i];
G.adjMatrix[i] = NULL;
}
delete G.adjMatrix;
}
int main()
{
MGraph G;
cout << "有向图例子:" << endl;
createGraph(G, DG);
print(G);
clear(G);
cout << endl;
cout << "无向图例子:" << endl;
createGraph(G, DN);
print(G);
clear(G);
cout << endl;
cout << "有向图网例子:" << endl;
createGraph(G, UDG);
print(G);
clear(G);
cout << endl;
cout << "无向图网例子:" << endl;
createGraph(G, UDN);
print(G);
clear(G);
cout << endl;
return 0;
}
输出结果:


4、图的存储结构—-邻接矩阵的优缺点
- 优点:
直观、容易理解,可以很容易的判断出任意两个顶点是否有边,最大的优点就是很容易计算出各个顶点的度。 - 缺点:
当我么表示完全图的时候,邻接矩阵是最好的表示方法,但是对于稀疏矩阵,由于它边少,但是顶点多,这样就会造成空间的浪费。
图的存储结构—邻接表
邻接表是图的一种链式存储结构。主要是应对于邻接矩阵在顶点多边少的时候,浪费空间的问题。它的方法就是声明两个结构。如下图所示:

OK,我们虽然知道了邻接表是这两个结构来表示图的,那么它的怎么表示的了,不急,我们先把它转为c++代码先,然后,再给个示例,你就明白了。
typedef char Vertextype;
//表结点结构
struct ArcNode {
int adjvex; //某条边指向的那个顶点的位置(一般是数组的下标)。
ArcNode * nextarc; //指向下一个表结点
int weight; //这个只有网图才需要使用。普通的图可以直接忽略
};
//头结点
struct Vnode
{
Vertextype data; //这个是记录每个顶点的信息(现在一般都不需要怎么使用)
ArcNode * firstarc; //指向第一条依附在该顶点边的信息(表结点)
};
无向图的示例:

从图中我们可以知道,顶点是通过一个头结点类型的一维数组来保存的,其中我们每个头结点的firstarc都是指向第一条依附在该顶点边的信息,表结点的adjvex表示的该边的另外一个顶点在顶点数组中的下标,weight域对于普通图是无意义的,可以忽略,nextarc指向的是下一条依附在该顶点的边的信息。
下面再给出一个有向图的例子:

通过上述的两个例子,我们应该明白邻接表是如何进行表示图的信息的了。
图的存储结构—-邻接表的代码实现
#include<iostream>
#include<string>
using namespace std;
typedef string Vertextype;
//表结点结构
struct ArcNode {
int adjvex; //某条边指向的那个顶点的位置(一般是数组的下标)。
ArcNode * nextarc; //指向下一个表结点
int weight; //这个只有网图才需要使用。
};
//头结点
struct Vnode
{
Vertextype data; //这个是记录每个顶点的信息(现在一般都不需要怎么使用)
ArcNode * firstarc; //指向第一条依附在该顶点边的信息(表结点)
};
//
struct Graph
{
int kind; //图的种类(有向图:0,无向图:1,有向网:2,无向网:3)
int vexnum; //图的顶点数
int edge; //图的边数
Vnode * node; //图的(顶点)头结点数组
};
void createGraph(Graph & g,int kind)
{
cout << "请输入顶点的个数:" << endl;
cin >> g.vexnum;
cout << "请输入边的个数(无向图/网要乘2):" << endl;
cin >> g.edge;
g.kind = kind; //决定图的种类
g.node = new Vnode[g.vexnum];
int i;
cout << "输入每个顶点的信息:" << endl;//记录每个顶点的信息
for (i = 0; i < g.vexnum; i++)
{
cin >> g.node[i].data;
g.node[i].firstarc=NULL;
}
cout << "请输入每条边的起点和终点的编号:" << endl;
for (i = 0; i < g.edge; i++)
{
int a;
int b;
cin >> a; //起点
cin >> b; //终点
ArcNode * next=new ArcNode;
next->adjvex = b - 1;
if(kind==0 || kind==1)
next->weight = -1;
else {//如果是网图,还需要权重
cout << "输入该边的权重:" << endl;
cin >> next->weight;
}
next->nextarc = NULL;
//将边串联起来
if (g.node[a - 1].firstarc == NULL) {
g.node[a - 1].firstarc=next;
}
else
{
ArcNode * p;
p = g.node[a - 1].firstarc;
while (p->nextarc)//找到该链表的最后一个表结点
{
p = p->nextarc;
}
p->nextarc = next;
}
}
}
void print(Graph g)
{
int i;
cout << "图的邻接表为:" << endl;
for (i = 0; i < g.vexnum; i++)
{
cout << g.node[i].data<<" ";
ArcNode * now;
now = g.node[i].firstarc;
while (now)
{
cout << now->adjvex << " ";
now = now->nextarc;
}
cout << endl;
}
}
int main()
{
Graph g;
cout << "有向图的例子" << endl;
createGraph(g,0);
print(g);
cout << endl;
cout << "无向图的例子" << endl;
createGraph(g, 1);
print(g);
cout << endl;
return 0;
}
输出结果:


图的存储结构—-邻接表的优缺点
- 优点:
对于,稀疏图,邻接表比邻接矩阵更节约空间。 - 缺点:
不容易判断两个顶点是有关系(边),顶点的出度容易,但是求入度需要遍历整个邻接表。
有向图的存储结构—-十字链表
十字链表是有向图的一个专有的链表结构,我们之前也说了,邻接表对于我们计算顶点的入度是一个很麻烦的事情,而十字链表正好可以解决这个问题。十字链表和邻接表一样,他会有两个结构来表示图:其中一个结构用于保存顶点信息,另外一个结构是用于保存每条边的信息,如下图所示:

同样,我们知道头结点就是用于保存每个顶点信息的结构,其中data主要是保存顶点的信息(如顶点的名称),firstin是保存第一个入度的边的信息,firstout保存第一个出度的边的信息。其中,表结点就是记录每条边的信息,其中tailvex是记录这条边弧头的顶点的在顶点表中的下标(不是箭头那个),headvex则是记录弧尾对应的那个顶点在顶点表中的下标(箭头的那个),hlink是指向具有下一个具有相同的headvex的表结点,tlink指向具有相同的tailvex的表结点,weight是表示边的权重(网图才需要使用)。具体的代码表示如下:
typedef string Vertextype;
//表结点结构
struct ArcNode {
int tailvex; //弧尾的下标,一般都是和对应的头结点下标相同
int headvex; //弧头的下标
ArcNode * hlink; //指向下一个弧头同为headvex的表结点 ,边是箭头的那边
ArcNode * tlink; //指向下一个弧尾为tailvex的表结点,边不是箭头的那边
int weight; //只有网才会用这个变量
};
//头结点
struct Vnode
{
Vertextype data; //这个是记录每个顶点的信息(现在一般都不需要怎么使用)
ArcNode *firstin; //指向第一条(入度)在该顶点的表结点
ArcNode *firstout; //指向第一条(出度)在该顶点的表结点
};
下面,我们给出一个有向图的十字链表的例子:

其实,这个自己也可以去尝试手画一个十字链表出来,其实都是很简单的
有向图的存储结构—-十字链表代码实现
#include<iostream>
#include<string>
using namespace std;
typedef string Vertextype;
//表结点结构
struct ArcNode {
int tailvex; //弧尾的下标,一般都是和对应的头结点下标相同
int headvex; //弧头的下标
ArcNode * hlink; //指向下一个弧头同为headvex的表结点 ,边是箭头的那边
ArcNode * tlink; //指向下一个弧尾为tailvex的表结点,边不是箭头的那边
int weight; //只有网才会用这个变量
};
//头结点
struct Vnode
{
Vertextype data; //这个是记录每个顶点的信息(现在一般都不需要怎么使用)
ArcNode *firstin; //指向第一条(入度)在该顶点的表结点
ArcNode *firstout; //指向第一条(出度)在该顶点的表结点
};
struct Graph
{
int kind; //图的种类(有向图:0,有向网:1)
int vexnum; //图的顶点数
int edge; //图的边数
Vnode * node; //图的(顶点)头结点数组
};
void createGraph(Graph & g,int kind)
{
cout << "请输入顶点的个数:" << endl;
cin >> g.vexnum;
cout << "请输入边的个数(无向图/网要乘2):" << endl;
cin >> g.edge;
g.kind = kind; //决定图的种类
g.node = new Vnode[g.vexnum];
int i;
cout << "输入每个顶点的信息:" << endl;//记录每个顶点的信息
for (i = 0; i < g.vexnum; i++)
{
cin >> g.node[i].data;
g.node[i].firstin = NULL;
g.node[i].firstout = NULL;
}
cout << "请输入每条边的起点和终点的编号:" << endl;
for (i = 0; i < g.edge; i++)
{
int a, b;
cin >> a;
cin >> b;
ArcNode * next = new ArcNode;
next->tailvex = a - 1; //首先是弧头的下标
next-> headvex = b - 1; //弧尾的下标
//只有网图需要权重信息
if(kind==0)
next->weight = -1;
else
{
cout << "输入该边的权重:" << endl;
cin >> next->weight;
}
next->tlink = NULL;
next->hlink = NULL;
//该位置的顶点的出度还为空时,直接让你fisrstout指针指向新的表结点
//记录的出度信息
if (g.node[a - 1].firstout == NULL)
{
g.node[a - 1].firstout = next;
}
else
{
ArcNode * now;
now = g.node[a - 1].firstout;
while (now->tlink)
{
now = now->tlink;
}
now->tlink = next;
}
//记录某个顶点的入度信息
if (g.node[b - 1].firstin == NULL)
{
g.node[b - 1].firstin = next;
}
else {
ArcNode * now;
now = g.node[b - 1].firstin;
while (now->hlink)//找到最后一个表结点
{
now = now->hlink;
}
now->hlink = next;//更新最后一个表结点
}
}
}
void print(Graph g)
{
int i;
cout << "各个顶点的出度信息" << endl;
for (i = 0; i < g.vexnum; i++)
{
cout << g.node[i].data << " ";
ArcNode * now;
now = g.node[i].firstout;
while (now)
{
cout << now->headvex << " ";
now = now->tlink;
}
cout << "^" << endl;
}
cout << "各个顶点的入度信息" << endl;
for (i = 0; i < g.vexnum; i++)
{
cout << g.node[i].data << " ";
ArcNode * now;
now = g.node[i].firstin;
while (now)
{
cout << now->tailvex << " ";
now = now->hlink;
}
cout << "^" << endl;
}
}
int main()
{
Graph g;
cout << "有向图的例子" << endl;
createGraph(g, 0);
print(g);
cout << endl;
return 0;
}

无向图的存储结构—-邻接多重表
邻接多重表是无向图的另一种链式存储结构。我们之前也说了使用邻接矩阵来存储图比价浪费空间,但是如果我们使用邻接表来存储图时,对于无向图又有一些不便的地方,例如我们需要对一条已经访问过的边进行删除或者标记等操作时,我们除了需要找到表示同一条边的两个结点。这会给我们的程序执行效率大打折扣,所以这个时候,邻接多重表就派上用场啦。
首先,邻接多重表同样是对邻接表的一个改进得到来的结构,它同样需要一个头结点保存每个顶点的信息和一个表结点,保存每条边的信息,他们的结构如下:

其中,头结点的结构和邻接表一样,而表结点中就改变比较大了,其中mark为标志域,例如标志是否已经访问过,ivex和jvex代表边的两个顶点在顶点表中的下标,ilink指向下一个依附在顶点ivex的边,jlink指向下一个依附在顶点jvex的边,weight在网图的时候使用,代表该边的权重。
下面是一个无向图的邻接多重表的实例(自己也可以尝试去画画,具体的原理都是很简单的):

无向图的存储结构—-邻接多重表代码实现
#include<iostream>
#include<string>
using namespace std;
//表结点
struct ArcNode
{
int mark; //标志位
int ivex; //输入边信息的那个起点
ArcNode * ilink; //依附在顶点ivex的下一条边的信息
int jvex; //输入边信息的那个终点
ArcNode * jlink; //依附在顶点jvex的下一条边的信息
int weight;
};
//头结点
struct VexNode {
string data; //顶点的信息,如顶点名称
ArcNode * firstedge; //第一条依附顶点的边
};
struct Graph {
int vexnum; //顶点的个数
int edge; //边的个数
VexNode *node; //保存顶点信息
};
void createGraph(Graph & g)
{
cout << "请输入顶点的个数:" << endl;
cin >> g.vexnum;
cout << "请输入边的个数(无向图/网要乘2):" << endl;
cin >> g.edge;
g.node = new VexNode[g.vexnum];
int i;
cout << "输入每个顶点的信息:" << endl;//记录每个顶点的信息
for (i = 0; i < g.vexnum; i++)
{
cin >> g.node[i].data;
g.node[i].firstedge = NULL;
}
cout << "请输入每条边的起点和终点的编号:" << endl;
for (i = 0; i < g.edge; i++)
{
int a, b;
cin >> a;
cin >> b;
ArcNode * next = new ArcNode;
next->mark = 0;
next->ivex = a - 1; //首先是弧头的下标
next->jvex = b - 1; //弧尾的下标
next->weight = -1;
next->ilink = NULL;
next->jlink = NULL;
//更新顶点表a-1的信息
if (g.node[a - 1].firstedge == NULL)
{
g.node[a - 1].firstedge = next;
}
else {
ArcNode * now;
now = g.node[a - 1].firstedge;
while (1) {
if (now->ivex == (a - 1) && now->ilink == NULL)
{
now->ilink = next;
break;
}
else if (now->ivex == (a - 1) && now->ilink != NULL) {
now = now->ilink;
}
else if (now->jvex == (a - 1) && now->jlink == NULL)
{
now->jlink = next;
break;
}
else if (now->jvex == (a - 1) && now->jlink != NULL) {
now = now->jlink;
}
}
}
//更新顶点表b-1
if (g.node[b - 1].firstedge == NULL)
{
g.node[b - 1].firstedge = next;
}
else {
ArcNode * now;
now = g.node[b - 1].firstedge;
while (1) {
if (now->ivex == (b - 1) && now->ilink == NULL)
{
now->ilink = next;
break;
}
else if (now->ivex == (b - 1) && now->ilink != NULL) {
now = now->ilink;
}
else if (now->jvex == (b - 1) && now->jlink == NULL)
{
now->jlink = next;
break;
}
else if (now->jvex == (b - 1) && now->jlink != NULL) {
now = now->jlink;
}
}
}
}
}
void print(Graph g)
{
int i;
for (i = 0; i < g.vexnum; i++)
{
cout << g.node[i].data << " ";
ArcNode * now;
now = g.node[i].firstedge;
while (now)
{
cout << "ivex=" << now->ivex << " jvex=" << now->jvex << " ";
if (now->ivex == i)
{
now = now->ilink;
}
else if (now->jvex == i)
{
now = now->jlink;
}
}
cout << endl;
}
}
int main()
{
Graph g;
createGraph(g);
print(g);
system("pause");
return 0;
}
输出结果:

来源(https://blog.csdn.net/qq_35644234/article/details/57083107)### 图的存储结构
图的存储结构—-邻接矩阵
图的邻接矩阵的表示方式需要两个数组来表示图的信息,一个一维数组表示每个数据元素的信息,一个二维数组(邻接矩阵)表示图中的边或者弧的信息。
如果图有n个顶点,那么邻接矩阵就是一个n*n的方阵,方阵中每个元素的值的计算公式如下:
邻接矩阵表示图的具体示例如下图所示:
首先给个无向图的实例:
下面是一个有向图的实例:
OK,到这里为止,我们给出一个无向图的邻接矩阵和一个有向图的邻接矩阵,我们可以从这两个邻接矩阵得出一些结论:
- 无向图的邻接矩阵都是沿对角线对称的
- 要知道无向图中某个顶点的度,其实就是这个顶点vi在邻接矩阵中第i行或(第i列)的元素之和;
- 对于有向图,要知道某个顶点的出度,其实就是这个顶点vi在邻接矩阵中第i行的元素之和,如果要知道某个顶点的入度,那就是第i列的元素之和。
但是,如果我们需要表示的图是一个网的时候,例如假设有个图有n个顶点,同样该网的邻接矩阵也是一个n*n的方阵,只是方阵元素的值的计算方式不同,如下图所示:
这里的wij表示两个顶点vi和vj边上的权值。无穷大表示一个计算机允许的、大于所有边上权值的值,也就是一个不可能的极限值。下面是具体示例,表示的一个有向网的图和邻接矩阵:
图的存储结构—-邻接矩阵的代码实现
#include<iostream>
using namespace std;
enum Graphkind{ DG, DN, UDG, UDN }; //{有向图,无向图,有向网,无向网}
typedef struct Node
{
int * vex; //顶点数组
int vexnum; //顶点个数
int edge; //图的边数
int ** adjMatrix; //图的邻接矩阵
enum Graphkind kind;
}MGraph;
void createGraph(MGraph & G,enum Graphkind kind)
{
cout << "输入顶点的个数" << endl;
cin >> G.vexnum;
cout << "输入边的个数" << endl;
cin >> G.edge;
//输入种类
//cout << "输入图的种类:DG:有向图 DN:无向图,UDG:有向网,UDN:无向网" << endl;
G.kind = kind;
//为两个数组开辟空间
G.vex = new int[G.vexnum];
G.adjMatrix = new int*[G.vexnum];
cout << G.vexnum << endl;
int i;
for (i = 0; i < G.vexnum; i++)
{
G.adjMatrix[i] = new int[G.vexnum];
}
for (i = 0; i < G.vexnum; i++)
{
for (int k = 0; k < G.vexnum; k++)
{
if (G.kind == DG || G.kind == DN)
{
G.adjMatrix[i][k] = 0;
}
else {
G.adjMatrix[i][k] = INT_MAX;
}
}
}
/*//输入每个元素的信息,这个信息,现在还不需要使用
for (i = 0; i < G.vexnum; i++)
{
cin >> G.vex[i];
}*/
cout << "请输入两个有关系的顶点的序号:例如:1 2 代表1号顶点指向2号顶点" << endl;
for (i = 0; i < G.edge; i++)
{
int a, b;
cin >> a;
cin >> b;
if (G.kind == DN) {
G.adjMatrix[b - 1][a - 1] = 1;
G.adjMatrix[a - 1][b - 1] = 1;
}
else if (G.kind == DG)
{
G.adjMatrix[a - 1][b - 1] = 1;
}
else if (G.kind == UDG)
{
int weight;
cout << "输入该边的权重:" << endl;
cin >> weight;
G.adjMatrix[a - 1][b - 1] = weight;
}
else {
int weight;
cout << "输入该边的权重:" << endl;
cin >> weight;
G.adjMatrix[b - 1][a - 1] = weight;
G.adjMatrix[a - 1][b - 1] = weight;
}
}
}
void print(MGraph g)
{
int i, j;
for (i = 0; i < g.vexnum; i++)
{
for (j = 0; j < g.vexnum; j++)
{
if (g.adjMatrix[i][j] == INT_MAX)
cout << "∞" << " ";
else
cout << g.adjMatrix[i][j] << " ";
}
cout << endl;
}
}
void clear(MGraph G)
{
delete G.vex;
G.vex = NULL;
for (int i = 0; i < G.vexnum; i++)
{
delete G.adjMatrix[i];
G.adjMatrix[i] = NULL;
}
delete G.adjMatrix;
}
int main()
{
MGraph G;
cout << "有向图例子:" << endl;
createGraph(G, DG);
print(G);
clear(G);
cout << endl;
cout << "无向图例子:" << endl;
createGraph(G, DN);
print(G);
clear(G);
cout << endl;
cout << "有向图网例子:" << endl;
createGraph(G, UDG);
print(G);
clear(G);
cout << endl;
cout << "无向图网例子:" << endl;
createGraph(G, UDN);
print(G);
clear(G);
cout << endl;
return 0;
}
输出结果:
4、图的存储结构—-邻接矩阵的优缺点
- 优点:
直观、容易理解,可以很容易的判断出任意两个顶点是否有边,最大的优点就是很容易计算出各个顶点的度。 - 缺点:
当我么表示完全图的时候,邻接矩阵是最好的表示方法,但是对于稀疏矩阵,由于它边少,但是顶点多,这样就会造成空间的浪费。
图的存储结构—邻接表
邻接表是图的一种链式存储结构。主要是应对于邻接矩阵在顶点多边少的时候,浪费空间的问题。它的方法就是声明两个结构。如下图所示:
OK,我们虽然知道了邻接表是这两个结构来表示图的,那么它的怎么表示的了,不急,我们先把它转为c++代码先,然后,再给个示例,你就明白了。
typedef char Vertextype;
//表结点结构
struct ArcNode {
int adjvex; //某条边指向的那个顶点的位置(一般是数组的下标)。
ArcNode * nextarc; //指向下一个表结点
int weight; //这个只有网图才需要使用。普通的图可以直接忽略
};
//头结点
struct Vnode
{
Vertextype data; //这个是记录每个顶点的信息(现在一般都不需要怎么使用)
ArcNode * firstarc; //指向第一条依附在该顶点边的信息(表结点)
};
无向图的示例:
从图中我们可以知道,顶点是通过一个头结点类型的一维数组来保存的,其中我们每个头结点的firstarc都是指向第一条依附在该顶点边的信息,表结点的adjvex表示的该边的另外一个顶点在顶点数组中的下标,weight域对于普通图是无意义的,可以忽略,nextarc指向的是下一条依附在该顶点的边的信息。
下面再给出一个有向图的例子:
通过上述的两个例子,我们应该明白邻接表是如何进行表示图的信息的了。
图的存储结构—-邻接表的代码实现
#include<iostream>
#include<string>
using namespace std;
typedef string Vertextype;
//表结点结构
struct ArcNode {
int adjvex; //某条边指向的那个顶点的位置(一般是数组的下标)。
ArcNode * nextarc; //指向下一个表结点
int weight; //这个只有网图才需要使用。
};
//头结点
struct Vnode
{
Vertextype data; //这个是记录每个顶点的信息(现在一般都不需要怎么使用)
ArcNode * firstarc; //指向第一条依附在该顶点边的信息(表结点)
};
//
struct Graph
{
int kind; //图的种类(有向图:0,无向图:1,有向网:2,无向网:3)
int vexnum; //图的顶点数
int edge; //图的边数
Vnode * node; //图的(顶点)头结点数组
};
void createGraph(Graph & g,int kind)
{
cout << "请输入顶点的个数:" << endl;
cin >> g.vexnum;
cout << "请输入边的个数(无向图/网要乘2):" << endl;
cin >> g.edge;
g.kind = kind; //决定图的种类
g.node = new Vnode[g.vexnum];
int i;
cout << "输入每个顶点的信息:" << endl;//记录每个顶点的信息
for (i = 0; i < g.vexnum; i++)
{
cin >> g.node[i].data;
g.node[i].firstarc=NULL;
}
cout << "请输入每条边的起点和终点的编号:" << endl;
for (i = 0; i < g.edge; i++)
{
int a;
int b;
cin >> a; //起点
cin >> b; //终点
ArcNode * next=new ArcNode;
next->adjvex = b - 1;
if(kind==0 || kind==1)
next->weight = -1;
else {//如果是网图,还需要权重
cout << "输入该边的权重:" << endl;
cin >> next->weight;
}
next->nextarc = NULL;
//将边串联起来
if (g.node[a - 1].firstarc == NULL) {
g.node[a - 1].firstarc=next;
}
else
{
ArcNode * p;
p = g.node[a - 1].firstarc;
while (p->nextarc)//找到该链表的最后一个表结点
{
p = p->nextarc;
}
p->nextarc = next;
}
}
}
void print(Graph g)
{
int i;
cout << "图的邻接表为:" << endl;
for (i = 0; i < g.vexnum; i++)
{
cout << g.node[i].data<<" ";
ArcNode * now;
now = g.node[i].firstarc;
while (now)
{
cout << now->adjvex << " ";
now = now->nextarc;
}
cout << endl;
}
}
int main()
{
Graph g;
cout << "有向图的例子" << endl;
createGraph(g,0);
print(g);
cout << endl;
cout << "无向图的例子" << endl;
createGraph(g, 1);
print(g);
cout << endl;
return 0;
}
输出结果:
图的存储结构—-邻接表的优缺点
- 优点:
对于,稀疏图,邻接表比邻接矩阵更节约空间。 - 缺点:
不容易判断两个顶点是有关系(边),顶点的出度容易,但是求入度需要遍历整个邻接表。
有向图的存储结构—-十字链表
十字链表是有向图的一个专有的链表结构,我们之前也说了,邻接表对于我们计算顶点的入度是一个很麻烦的事情,而十字链表正好可以解决这个问题。十字链表和邻接表一样,他会有两个结构来表示图:其中一个结构用于保存顶点信息,另外一个结构是用于保存每条边的信息,如下图所示:
同样,我们知道头结点就是用于保存每个顶点信息的结构,其中data主要是保存顶点的信息(如顶点的名称),firstin是保存第一个入度的边的信息,firstout保存第一个出度的边的信息。其中,表结点就是记录每条边的信息,其中tailvex是记录这条边弧头的顶点的在顶点表中的下标(不是箭头那个),headvex则是记录弧尾对应的那个顶点在顶点表中的下标(箭头的那个),hlink是指向具有下一个具有相同的headvex的表结点,tlink指向具有相同的tailvex的表结点,weight是表示边的权重(网图才需要使用)。具体的代码表示如下:
typedef string Vertextype;
//表结点结构
struct ArcNode {
int tailvex; //弧尾的下标,一般都是和对应的头结点下标相同
int headvex; //弧头的下标
ArcNode * hlink; //指向下一个弧头同为headvex的表结点 ,边是箭头的那边
ArcNode * tlink; //指向下一个弧尾为tailvex的表结点,边不是箭头的那边
int weight; //只有网才会用这个变量
};
//头结点
struct Vnode
{
Vertextype data; //这个是记录每个顶点的信息(现在一般都不需要怎么使用)
ArcNode *firstin; //指向第一条(入度)在该顶点的表结点
ArcNode *firstout; //指向第一条(出度)在该顶点的表结点
};
下面,我们给出一个有向图的十字链表的例子:
其实,这个自己也可以去尝试手画一个十字链表出来,其实都是很简单的
有向图的存储结构—-十字链表代码实现
#include<iostream>
#include<string>
using namespace std;
typedef string Vertextype;
//表结点结构
struct ArcNode {
int tailvex; //弧尾的下标,一般都是和对应的头结点下标相同
int headvex; //弧头的下标
ArcNode * hlink; //指向下一个弧头同为headvex的表结点 ,边是箭头的那边
ArcNode * tlink; //指向下一个弧尾为tailvex的表结点,边不是箭头的那边
int weight; //只有网才会用这个变量
};
//头结点
struct Vnode
{
Vertextype data; //这个是记录每个顶点的信息(现在一般都不需要怎么使用)
ArcNode *firstin; //指向第一条(入度)在该顶点的表结点
ArcNode *firstout; //指向第一条(出度)在该顶点的表结点
};
struct Graph
{
int kind; //图的种类(有向图:0,有向网:1)
int vexnum; //图的顶点数
int edge; //图的边数
Vnode * node; //图的(顶点)头结点数组
};
void createGraph(Graph & g,int kind)
{
cout << "请输入顶点的个数:" << endl;
cin >> g.vexnum;
cout << "请输入边的个数(无向图/网要乘2):" << endl;
cin >> g.edge;
g.kind = kind; //决定图的种类
g.node = new Vnode[g.vexnum];
int i;
cout << "输入每个顶点的信息:" << endl;//记录每个顶点的信息
for (i = 0; i < g.vexnum; i++)
{
cin >> g.node[i].data;
g.node[i].firstin = NULL;
g.node[i].firstout = NULL;
}
cout << "请输入每条边的起点和终点的编号:" << endl;
for (i = 0; i < g.edge; i++)
{
int a, b;
cin >> a;
cin >> b;
ArcNode * next = new ArcNode;
next->tailvex = a - 1; //首先是弧头的下标
next-> headvex = b - 1; //弧尾的下标
//只有网图需要权重信息
if(kind==0)
next->weight = -1;
else
{
cout << "输入该边的权重:" << endl;
cin >> next->weight;
}
next->tlink = NULL;
next->hlink = NULL;
//该位置的顶点的出度还为空时,直接让你fisrstout指针指向新的表结点
//记录的出度信息
if (g.node[a - 1].firstout == NULL)
{
g.node[a - 1].firstout = next;
}
else
{
ArcNode * now;
now = g.node[a - 1].firstout;
while (now->tlink)
{
now = now->tlink;
}
now->tlink = next;
}
//记录某个顶点的入度信息
if (g.node[b - 1].firstin == NULL)
{
g.node[b - 1].firstin = next;
}
else {
ArcNode * now;
now = g.node[b - 1].firstin;
while (now->hlink)//找到最后一个表结点
{
now = now->hlink;
}
now->hlink = next;//更新最后一个表结点
}
}
}
void print(Graph g)
{
int i;
cout << "各个顶点的出度信息" << endl;
for (i = 0; i < g.vexnum; i++)
{
cout << g.node[i].data << " ";
ArcNode * now;
now = g.node[i].firstout;
while (now)
{
cout << now->headvex << " ";
now = now->tlink;
}
cout << "^" << endl;
}
cout << "各个顶点的入度信息" << endl;
for (i = 0; i < g.vexnum; i++)
{
cout << g.node[i].data << " ";
ArcNode * now;
now = g.node[i].firstin;
while (now)
{
cout << now->tailvex << " ";
now = now->hlink;
}
cout << "^" << endl;
}
}
int main()
{
Graph g;
cout << "有向图的例子" << endl;
createGraph(g, 0);
print(g);
cout << endl;
return 0;
}
无向图的存储结构—-邻接多重表
邻接多重表是无向图的另一种链式存储结构。我们之前也说了使用邻接矩阵来存储图比价浪费空间,但是如果我们使用邻接表来存储图时,对于无向图又有一些不便的地方,例如我们需要对一条已经访问过的边进行删除或者标记等操作时,我们除了需要找到表示同一条边的两个结点。这会给我们的程序执行效率大打折扣,所以这个时候,邻接多重表就派上用场啦。
首先,邻接多重表同样是对邻接表的一个改进得到来的结构,它同样需要一个头结点保存每个顶点的信息和一个表结点,保存每条边的信息,他们的结构如下:
其中,头结点的结构和邻接表一样,而表结点中就改变比较大了,其中mark为标志域,例如标志是否已经访问过,ivex和jvex代表边的两个顶点在顶点表中的下标,ilink指向下一个依附在顶点ivex的边,jlink指向下一个依附在顶点jvex的边,weight在网图的时候使用,代表该边的权重。
下面是一个无向图的邻接多重表的实例(自己也可以尝试去画画,具体的原理都是很简单的):
无向图的存储结构—-邻接多重表代码实现
#include<iostream>
#include<string>
using namespace std;
//表结点
struct ArcNode
{
int mark; //标志位
int ivex; //输入边信息的那个起点
ArcNode * ilink; //依附在顶点ivex的下一条边的信息
int jvex; //输入边信息的那个终点
ArcNode * jlink; //依附在顶点jvex的下一条边的信息
int weight;
};
//头结点
struct VexNode {
string data; //顶点的信息,如顶点名称
ArcNode * firstedge; //第一条依附顶点的边
};
struct Graph {
int vexnum; //顶点的个数
int edge; //边的个数
VexNode *node; //保存顶点信息
};
void createGraph(Graph & g)
{
cout << "请输入顶点的个数:" << endl;
cin >> g.vexnum;
cout << "请输入边的个数(无向图/网要乘2):" << endl;
cin >> g.edge;
g.node = new VexNode[g.vexnum];
int i;
cout << "输入每个顶点的信息:" << endl;//记录每个顶点的信息
for (i = 0; i < g.vexnum; i++)
{
cin >> g.node[i].data;
g.node[i].firstedge = NULL;
}
cout << "请输入每条边的起点和终点的编号:" << endl;
for (i = 0; i < g.edge; i++)
{
int a, b;
cin >> a;
cin >> b;
ArcNode * next = new ArcNode;
next->mark = 0;
next->ivex = a - 1; //首先是弧头的下标
next->jvex = b - 1; //弧尾的下标
next->weight = -1;
next->ilink = NULL;
next->jlink = NULL;
//更新顶点表a-1的信息
if (g.node[a - 1].firstedge == NULL)
{
g.node[a - 1].firstedge = next;
}
else {
ArcNode * now;
now = g.node[a - 1].firstedge;
while (1) {
if (now->ivex == (a - 1) && now->ilink == NULL)
{
now->ilink = next;
break;
}
else if (now->ivex == (a - 1) && now->ilink != NULL) {
now = now->ilink;
}
else if (now->jvex == (a - 1) && now->jlink == NULL)
{
now->jlink = next;
break;
}
else if (now->jvex == (a - 1) && now->jlink != NULL) {
now = now->jlink;
}
}
}
//更新顶点表b-1
if (g.node[b - 1].firstedge == NULL)
{
g.node[b - 1].firstedge = next;
}
else {
ArcNode * now;
now = g.node[b - 1].firstedge;
while (1) {
if (now->ivex == (b - 1) && now->ilink == NULL)
{
now->ilink = next;
break;
}
else if (now->ivex == (b - 1) && now->ilink != NULL) {
now = now->ilink;
}
else if (now->jvex == (b - 1) && now->jlink == NULL)
{
now->jlink = next;
break;
}
else if (now->jvex == (b - 1) && now->jlink != NULL) {
now = now->jlink;
}
}
}
}
}
void print(Graph g)
{
int i;
for (i = 0; i < g.vexnum; i++)
{
cout << g.node[i].data << " ";
ArcNode * now;
now = g.node[i].firstedge;
while (now)
{
cout << "ivex=" << now->ivex << " jvex=" << now->jvex << " ";
if (now->ivex == i)
{
now = now->ilink;
}
else if (now->jvex == i)
{
now = now->jlink;
}
}
cout << endl;
}
}
int main()
{
Graph g;
createGraph(g);
print(g);
system("pause");
return 0;
}
输出结果:
来源(https://blog.csdn.net/qq_35644234/article/details/57083107)















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









