






一安装浏览器插件elasticseaeh-head
-
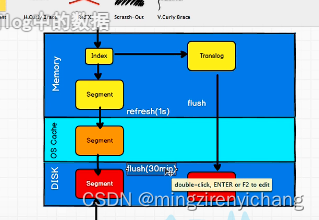
es先写入内存,再写入translog。写入硬盘时有flush和translog
-
tranlog记录es索引写入日志,防止异常原因断电等造成数据丢失。
-
数据写入操作系统的文件缓存系统
-
es删除数据:并不真正删除,而是标记为.del文件保存,类似于逻辑删除。但是会导致硬盘上的es文件越来越多,会有一个合并文件的操作,这个时候会将文件彻底删除。
-
es默认分词器
get http://localhost:9200/_analyze
{
“analyzer”:“standard”,
“text”:[“这是一个分词器”]
} -
ik分词器(中文分词器)版本需要与es对应
ik插件解压缩后放置在es目录plugins下,重启es,可以使用ik
ik参数
{
“text”:“”
“analyzer”:“ik_max_smart” //最粗粒度的划分单词
“analyzer”:“ik_smart”//最细粒度的划分单词
}
例如:
get _analyze
{
“analyzer”:ik_smart",
“text”:[“最细粒度的划分”]
}
6.1. 固定词语不拆分存储。
(1)ik目录下config创建.dic文件,将不分词的词语输入保存即可
(2)ik目录config目录下修改Analyzer.cfg.xml文件

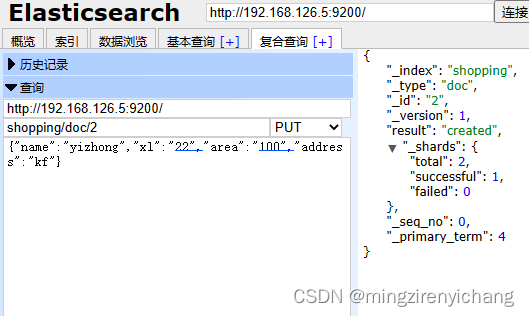
es-head写入(shopping为索引名)2为唯一性标识,必填
post shopping/doc
put shoppint/doc/2
- es数据删除
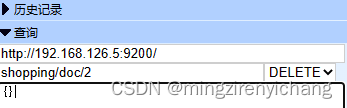
9.不区分索引,根据查询条件查询所有索引

10.不区分索引多条件查询

11.查看所有索引

12.设置别名(通过该名称也可以查询到索引)
aliases
13.es不允许修改索引信息
14.恢复删除后的文档数据.del或查询删除后的文档数据.del
15.查询整个集群的文档数量

16.查询索引所有数据
get 索引名/_search
17.删除单个索引
delete /索引名/_doc/唯一性id
整个索引文档删除post /索引名/_doc
18.批量写入索引
put /索引名/_bulk
{index:“”,id:“”…}
{“age”:“”,“”:“”}
{“index”:{“_index”:“test”,“_id”:“5”}}
{“id”:“5”,“name”:“lisi”,“age”:“21”,“address”:“sq”}
{“index”:{“_index”:“test”,“_id”:“6”}}
{“id”:“6”,“name”:“zhangtang”,“age”:“19”,“address”:“ly”}
19.分词保存,分词查询
zhang san :会保存为两个关键词
zhangsan:为一个关键词
分词查询:可以同时查询多个关键字
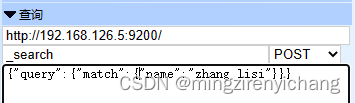
20.全词搜索
term
{“query”:{“term”:{“name”:“lisi”}}}
21.对返回结果进行限制
{
“_resource”:[“age”],
“query”:{“must”:
{“match”:{“name”:“lisi”}}
}
}
22.组合查询(与是must,或是should)查询多个条件
should:{
“match”:{“age”}
“match”:{“name”}
}
例(查询标题中含有hadoop 和hbase的):
{
“query”:{
“should”:{
“match”:{
“title”:{“query”:“hadoop”,“boost”,1}
},
“match”:{
“title”:{“query”:“hbase”,“boost”,1}
}
}
}
}
23.排序(根据年龄排序)
{
“query”{“must”:{“age”}},
“sort”:{“age”:{“order desc”}}
}
24.分页查询
{“query”:{},
“from”:2, --从第几条数据开始查询
“size”:2 --每页显示的数据
}
25.分组查询
{
“aggs”: {
“ageGroup”: {
“terms”: {
“field”: “age”
}
}
},
“size”: 0
}
26.分组后聚合
{
“aggs”: {
“ageGroup”: {
“terms”: {
“field”: “age”
}
},
“aggs”:{
“aggsum”:{
“sum”:{
“field”:“age”
}
}
}
},
“size”: 0
}
27.求年龄平均值
{
“aggs”: {
“ageAvg”: {
“avg”: {
“field”: “age”
}
},
“size”: 0
}
28.排序
{
“aggs”:{
“ageOrder”:{
“top_hits”:{
“sort”:[{
“age”:{
“order”:" desc"
}
}],
“size”:0
}
}
},
“size”:0
}
29.调整创建索引的默认信息
单条:
put index_name
{
“settings”:{
“number_of_shards”:2
}
}
30.删除整个索引
31.创建索引模板并使用,关键字_template
索引模板可反复修改
创建模板:
put _template/templatename
{
“index_pattens”: [ —创建的索引规则,索引名称带my开头的自动引用该模板
“my*”
],
“settings”: {
“index”: {
“number_of_shards”: 1
}
},
“mappings”: {
“properties”: {
“now”: {
“type”: “date”,
“format”: “yyyy/mm/dd”
}
}
}
}
—es-head不支持now,type,date等
{
“index_patterns”: [
“my*”
],
“settings”: {
“index”: {
“number_of_shards”: 1
}
}
}
32.查询es创建的索引模板
get _template/templatename
33.使用模板,索引名称为my开头的即可
get my_template_test

34.删除创建的索引模板
delete _template/my_template_test
35.文档评分机制
查询结果根据评分不同,优先展示
get indexname/_search?explain=true
{
“query”:{
“match”:{
“name”:“zhang”
}
}
}
评分标准:boots * idf * tf
idf :逆文档频率 计算规则:log(1+(N-n+0.5)/(n+0.5)
tf:词频 计算规则:freq/(freq+k1*(1-b+b*dl/avgdl))
boots:权重系数。有固定的值==2.2
- 提升所查询数据的分值,优先展示
查询条件加权重值—boost
例如:
{
“query”:{
“should”:{
“match”:{
“title”:{“query”:“hadoop”,“boost”,1}
},
“match”:{
“title”:{“query”:“hbase”,“boost”,2}
}
}
}
}
权重系数有固定值2.2 可以通过参数调整增加或减小,以上boost将优先展示title包含hbase的数据。
title包含hbase的权重系数为2.2*2=4.4
title包含hadoop的权重系数为2.2
37.eql数据查询语言
建立各个数据之间的查询关系














 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









