









很多时候我们学习AI的时候会用到很多第三方库,那么是不是可以不用库就能来联系AI算法呢?当然。
以下是几个可以用 Python 实现的简单 AI 算法,它们不依赖于外部库,适合初学者来理解这些算法:
1. 线性回归(Linear Regression)
线性回归是最简单的回归算法,目标是通过一条直线拟合数据。通过最小二乘法来找出最优的线性关系。
应用场景:
-
预测任务: 线性回归是最简单的回归模型之一,常用于预测数值型目标变量。例如:
- 房价预测: 根据面积、位置、房龄等特征预测房屋价格。
- 销售预测: 根据广告预算、季节性、促销活动等因素预测产品销售额。
- 气温预测: 根据历史气象数据预测未来的气温。
-
趋势分析: 用于寻找数据中的线性趋势,揭示变量之间的线性关系。例如:
- 股票市场分析: 根据历史股价数据分析和预测未来股价走势。
-
风险评估: 在金融、保险等领域使用线性回归模型评估风险。例如:
- 信用评分: 根据个人信用历史预测信用分数。
- 保险定价: 根据个人健康状况、年龄、历史理赔等因素评估投保人风险。
优点:
- 简单直观,易于理解和实现。
- 对于线性关系的数据效果较好。
局限:
- 对于数据中存在非线性关系的任务,线性回归表现较差。
import random
# 创建一些简单的数据
data = [(x, 2*x + 1 + random.uniform(-1, 1)) for x in range(10)]
# 计算平均值
mean_x = sum(x for x, y in data) / len(data)
mean_y = sum(y for x, y in data) / len(data)
# 计算斜率(slope)和截距(intercept)
numerator = sum((x - mean_x) * (y - mean_y) for x, y in data)
denominator = sum((x - mean_x) ** 2 for x, y in data)
slope = numerator / denominator
intercept = mean_y - slope * mean_x
print(f"斜率: {slope}, 截距: {intercept}")
# 使用计算得到的斜率和截距来预测
def predict(x):
return slope * x + intercept
# 测试预测
for x, y in data:
print(f"真实值: {y}, 预测值: {predict(x)}")
解释:
- 生成简单的线性数据,添加了噪声。
- 使用最小二乘法计算斜率(slope)和截距(intercept),然后进行预测。
为了让结果可视化,我们加入一个图片展示:
下面是将线性回归的结果可视化的代码,包括绘制数据点和拟合的直线。为了绘制图形,我们使用 matplotlib 库来生成图表,但不需要其他复杂的库,只需要 matplotlib 来显示图形。
如果你没有安装 matplotlib,可以通过以下命令安装:
pip install matplotlib
线性回归与可视化
import random
import matplotlib.pyplot as plt
# 创建一些简单的数据
data = [(x, 2*x + 1 + random.uniform(-1, 1)) for x in range(10)]
# 计算平均值
mean_x = sum(x for x, y in data) / len(data)
mean_y = sum(y for x, y in data) / len(data)
# 计算斜率(slope)和截距(intercept)
numerator = sum((x - mean_x) * (y - mean_y) for x, y in data)
denominator = sum((x - mean_x) ** 2 for x, y in data)
slope = numerator / denominator
intercept = mean_y - slope * mean_x
# 使用计算得到的斜率和截距来预测
def predict(x):
return slope * x + intercept
# 可视化数据点
x_data = [x for x, y in data]
y_data = [y for x, y in data]
# 绘制数据点
plt.scatter(x_data, y_data, color='blue', label='Data points')
# 绘制拟合的线性回归线
x_range = range(min(x_data), max(x_data)+1)
y_range = [predict(x) for x in x_range]
plt.plot(x_range, y_range, color='red', label=f'Linear fit: y = {slope:.2f}x + {intercept:.2f}')
# 添加标题和标签
plt.title('Linear Regression')
plt.xlabel('X')
plt.ylabel('Y')
# 显示图例
plt.legend()
# 显示图形
plt.show()
代码解释:
- 数据生成: 我们生成了一些
(x, y)数据点,其中y是根据线性关系y = 2x + 1生成的,但加入了一些随机噪声。 - 线性回归计算: 使用最小二乘法来计算直线的斜率(slope)和截距(intercept)。
- 绘制图形:
- 使用
matplotlib.pyplot.scatter绘制原始数据点。 - 使用
matplotlib.pyplot.plot绘制拟合的线性回归直线。
- 使用
- 图形展示: 添加了标题、轴标签和图例,并显示最终的图形。
图片解读
- 蓝色点表示数据点。
- 红色线表示拟合的线性回归直线。
- 你可以修改菜蔬来使得预测和蓝点偏离,这样可以更直观的理解拟合
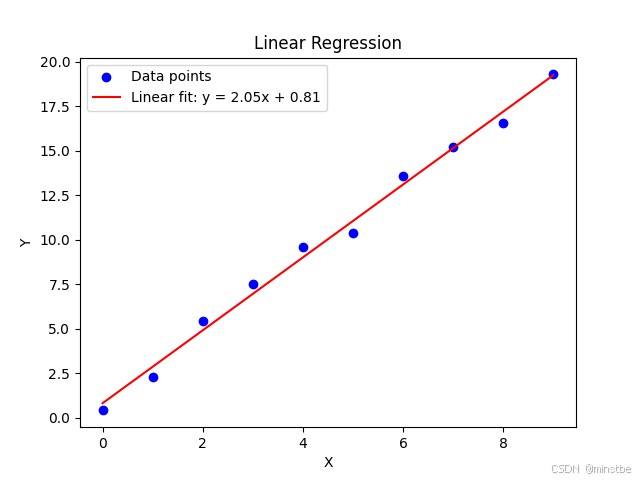
上面这段代码不仅计算并展示了线性回归的结果,还通过图形化的方式展示了模型的拟合效果。
2. K-近邻算法(K-NN)
K-近邻是一个简单的分类算法,它通过计算样本点之间的距离来分类。
应用场景:
-
分类任务: K-NN 是一种基于实例的学习算法,适用于小数据集的分类任务。例如:
- 手写数字识别: 识别手写数字(如MNIST数据集中的数字)。
- 垃圾邮件过滤: 基于邮件内容分类邮件为垃圾邮件或正常邮件。
- 语音识别: 根据语音特征将语音信号分类为不同的命令或字母。
-
推荐系统: 基于用户历史行为或偏好进行物品推荐。例如:
- 电影推荐: 根据用户过往观看的电影推荐相似电影。
- 电商推荐: 基于购物历史推荐潜在感兴趣的商品。
优点:
- 算法简单,易于理解。
- 无需训练过程(懒学习)。
局限:
- 计算复杂度较高,尤其是在大规模数据集上。
- 对噪声数据敏感,容易受到异常值的影响。
import math
# 计算欧几里得距离
def euclidean_distance(point1, point2):
return math.sqrt(sum((x - y) ** 2 for x, y in zip(point1, point2)))
# K-近邻算法
def knn(train_data, test_point, k):
distances = []
for point, label in train_data:
dist = euclidean_distance(point, test_point)
distances.append((dist, label))
distances.sort(key=lambda x: x[0])
# 获取k个最近邻的标签
neighbors = [label for _, label in distances[:k]]
# 返回最常见的标签
return max(set(neighbors), key=neighbors.count)
# 示例训练数据 [(特征, 标签)]
train_data = [
((1, 2), 'A'),
((2, 3), 'A'),
((3, 4), 'B'),
((5, 5), 'B'),
]
# 测试点
test_point = (3, 3)
# 使用K-近邻进行预测
k = 3
predicted_label = knn(train_data, test_point, k)
print(f"预测标签: {predicted_label}")
解释:
- 计算测试点与训练数据集中每个点的欧几里得距离。
- 根据距离选择最接近的
k个点,预测测试点的标签。
同样,我们也加入可视化:
下面是一个使用 K-近邻(K-NN)算法进行分类并进行可视化的代码示例。我们将使用 matplotlib 来绘制训练数据点和测试点,以及显示最近邻点的选择。
K-近邻算法与可视化
import math
import random
import matplotlib.pyplot as plt
# 计算欧几里得距离
def euclidean_distance(point1, point2):
return math.sqrt(sum((x - y) ** 2 for x, y in zip(point1, point2)))
# K-近邻算法
def knn(train_data, test_point, k):
distances = []
for point, label in train_data:
dist = euclidean_distance(point, test_point)
distances.append((dist, label))
distances.sort(key=lambda x: x[0])
# 获取k个最近邻的标签
neighbors = [label for _, label in distances[:k]]
# 返回最常见的标签
return max(set(neighbors), key=neighbors.count)
# 示例训练数据 [(特征, 标签)]
train_data = [
((1, 2), 'A'),
((2, 3), 'A'),
((3, 4), 'B'),
((5, 5), 'B'),
((6, 7), 'B'),
((8, 8), 'A'),
]
# 测试点
test_point = (4, 4)
# 使用K-近邻进行预测
k = 3
predicted_label = knn(train_data, test_point, k)
# 可视化数据点和测试点
train_points_a = [point for point, label in train_data if label == 'A']
train_points_b = [point for point, label in train_data if label == 'B']
test_x, test_y = test_point
# 创建图形
plt.figure(figsize=(6, 6))
# 绘制训练数据点
train_points_a_x, train_points_a_y = zip(*train_points_a)
train_points_b_x, train_points_b_y = zip(*train_points_b)
plt.scatter(train_points_a_x, train_points_a_y, color='blue', label='Class A', marker='o')
plt.scatter(train_points_b_x, train_points_b_y, color='red', label='Class B', marker='x')
# 绘制测试点
plt.scatter(test_x, test_y, color='green', label='Test Point', s=100, edgecolor='black')
# 计算并绘制最近的k个邻居
distances = [(euclidean_distance(test_point, point), label) for point, label in train_data]
distances.sort(key=lambda x: x[0])
nearest_neighbors = distances[:k]
# 绘制最近邻点
for dist, label in nearest_neighbors:
point = train_data[distances.index((dist, label))][0]
plt.plot([test_x, point[0]], [test_y, point[1]], color='black', linestyle='--')
# 标题和标签
plt.title(f'K-Nearest Neighbors (k={k})')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 显示图例
plt.legend()
# 显示图形
plt.show()
# 输出预测的标签
print(f"预测标签: {predicted_label}")
代码解释:
- 欧几里得距离计算: 使用
euclidean_distance函数计算测试点和每个训练点之间的距离。 - K-近邻算法: 在
knn函数中,计算测试点到训练集的每个点的距离,并根据距离选出k个最近的邻居,通过投票得出最终分类。 - 数据可视化:
- 使用
matplotlib绘制训练数据点。不同类别的点使用不同的颜色和标记。 - 绘制测试点为绿色,并标出最近邻点(使用虚线连接测试点与邻居点)。
- 在图形中显示类别 A 和 B 的训练数据,测试点,以及最近邻点。
- 使用
可视化效果
- 蓝色圆点 表示类别 A 的训练数据。
- 红色叉号 表示类别 B 的训练数据。
- 绿色大圆点 是测试点。
- 黑色虚线 连接测试点与它的
k个最近邻点。
图片解读
- 通过 K-近邻算法对测试点进行预测,并显示图形,帮助你直观理解 K-近邻分类的原理。
- 该示例中的
k=3,所以测试点的预测标签是根据最近的 3 个邻居来进行决定的。
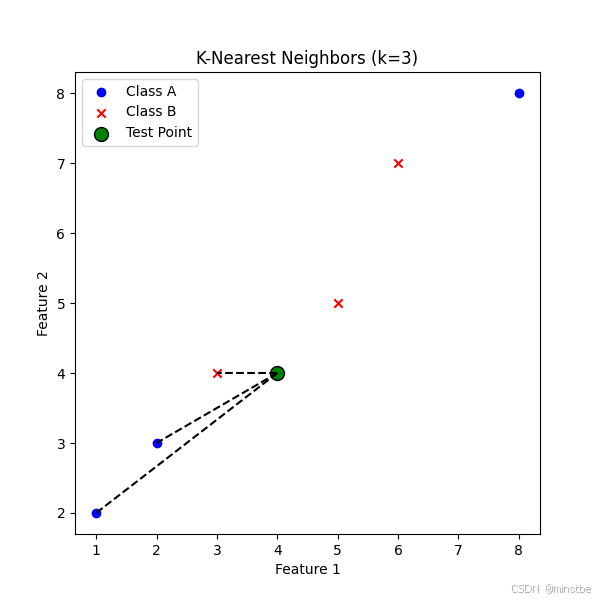
这段代码和图片,能够帮助初学者更好地理解 K-近邻算法的工作原理,同时通过可视化来展示算法如何对新数据点进行分类。
3. 朴素贝叶斯分类(Naive Bayes)
朴素贝叶斯是基于贝叶斯定理的一种简单的分类算法,假设特征之间是条件独立的。
应用场景:
-
文本分类: 朴素贝叶斯算法因其对文本数据(尤其是高维数据)的高效性,常用于自然语言处理(NLP)任务。例如:
- 情感分析: 对社交媒体帖子或评论进行情感分类(如积极、消极或中立)。
- 垃圾邮件分类: 基于邮件的单词频率分类邮件为垃圾邮件或正常邮件。
- 主题建模: 根据文章的词汇分布自动识别文章的主题。
-
医学诊断: 用于分类病人是否患有某种疾病。例如:
- 癌症诊断: 根据病人的历史数据和检验结果判断是否患有癌症。
-
推荐系统: 通过朴素贝叶斯模型预测用户对物品的兴趣。例如:
- 产品推荐: 根据用户过去购买的数据预测用户可能感兴趣的产品。
优点:
- 对高维数据(如文本分类)非常有效。
- 模型训练速度快,适用于大规模数据集。
- 适合处理多类别分类任务。
局限:
- 假设特征之间条件独立,这对于实际应用中可能并不成立,影响模型性能。
- 处理连续数据时,通常需要进行平滑处理或离散化。
# 计算先验概率和条件概率
def naive_bayes(train_data, test_point):
# 计算各类的先验概率
total = len(train_data)
classes = set(label for _, label in train_data)
prior_probabilities = {label: sum(1 for _, l in train_data if l == label) / total for label in classes}
# 计算条件概率
likelihoods = {}
for label in classes:
class_data = [point for point, l in train_data if l == label]
likelihoods[label] = {i: sum(1 for p in class_data if p[i] == test_point[i]) / len(class_data)
for i in range(len(test_point))}
# 计算后验概率并分类
posterior_probabilities = {}
for label in classes:
posterior_probabilities[label] = prior_probabilities[label]
for i in range(len(test_point)):
posterior_probabilities[label] *= likelihoods[label][i]
return max(posterior_probabilities, key=posterior_probabilities.get)
# 示例训练数据 [(特征, 标签)]
train_data = [
((1, 2), 'A'),
((2, 3), 'A'),
((3, 4), 'B'),
((5, 5), 'B'),
]
# 测试点
test_point = (3, 3)
# 使用朴素贝叶斯进行预测
predicted_label = naive_bayes(train_data, test_point)
print(f"预测标签: {predicted_label}")
解释:
- 计算每个类别的先验概率(标签的分布)。
- 计算每个类别下每个特征的条件概率。
- 根据贝叶斯定理计算后验概率,最终返回具有最大后验概率的类别。
加入可视化:
下面是一个朴素贝叶斯分类(Naive Bayes)算法的示例,并结合 matplotlib 进行可视化。我们将通过图形展示不同类别的数据点,以及如何通过朴素贝叶斯算法对一个新的测试点进行分类。
朴素贝叶斯分类与可视化
import matplotlib.pyplot as plt
import numpy as np
import random
# 朴素贝叶斯分类算法
def naive_bayes(train_data, test_point):
# 计算各类的先验概率
total = len(train_data)
classes = set(label for _, label in train_data)
prior_probabilities = {label: sum(1 for _, l in train_data if l == label) / total for label in classes}
# 计算每个特征的条件概率
likelihoods = {}
for label in classes:
class_data = [point for point, l in train_data if l == label]
likelihoods[label] = {i: sum(1 for p in class_data if p[i] == test_point[i]) / len(class_data)
for i in range(len(test_point))}
# 计算后验概率并分类
posterior_probabilities = {}
for label in classes:
posterior_probabilities[label] = prior_probabilities[label]
for i in range(len(test_point)):
posterior_probabilities[label] *= likelihoods[label][i]
# 返回最有可能的标签
return max(posterior_probabilities, key=posterior_probabilities.get)
# 示例训练数据 [(特征, 标签)]
train_data = [
((1, 2), 'A'),
((2, 3), 'A'),
((3, 4), 'B'),
((5, 5), 'B'),
((6, 7), 'B'),
((8, 8), 'A'),
]
# 测试点
test_point = (4, 4)
# 使用朴素贝叶斯进行预测
predicted_label = naive_bayes(train_data, test_point)
# 可视化数据点和测试点
train_points_a = [point for point, label in train_data if label == 'A']
train_points_b = [point for point, label in train_data if label == 'B']
test_x, test_y = test_point
# 创建图形
plt.figure(figsize=(6, 6))
# 绘制训练数据点
train_points_a_x, train_points_a_y = zip(*train_points_a)
train_points_b_x, train_points_b_y = zip(*train_points_b)
plt.scatter(train_points_a_x, train_points_a_y, color='blue', label='Class A', marker='o')
plt.scatter(train_points_b_x, train_points_b_y, color='red', label='Class B', marker='x')
# 绘制测试点
plt.scatter(test_x, test_y, color='green', label='Test Point', s=100, edgecolor='black')
# 计算并绘制决策边界
x_min, x_max = plt.xlim()
y_min, y_max = plt.ylim()
# 使用 meshgrid 创建网格点
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100))
# 为每个网格点预测标签
grid_points = np.c_[xx.ravel(), yy.ravel()]
predictions = [naive_bayes(train_data, point) for point in grid_points]
# 将预测结果转换为数字('A' -> 1, 'B' -> 0)
predictions_numeric = [1 if pred == 'A' else 0 for pred in predictions]
# 将预测结果重塑为与网格相同的形状
predictions_numeric = np.array(predictions_numeric).reshape(xx.shape)
# 绘制决策边界
plt.contourf(xx, yy, predictions_numeric, alpha=0.3)
# 标题和标签
plt.title('Naive Bayes Classifier with Decision Boundary')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 显示图例
plt.legend()
# 显示图形
plt.show()
# 输出预测的标签
print(f"预测标签: {predicted_label}")
代码解释:
-
朴素贝叶斯分类:
- 先计算各个类别的先验概率,即每个类别在训练数据中出现的频率。
- 然后计算每个特征在给定类别下的条件概率。
- 通过贝叶斯定理,结合先验概率和条件概率,计算每个类别的后验概率,最后选择后验概率最大的类别作为预测标签。
-
数据可视化:
- 训练数据点:使用不同的颜色和标记表示不同类别的训练数据点。
- 测试点:绘制一个绿色的点作为测试点。
- 决策边界:为了展示朴素贝叶斯分类的效果,我们通过绘制一个简单的决策边界来显示分类区域。我们通过在整个平面上构造一个网格,并预测每个网格点的标签,从而绘制出不同类别的区域。
- 决策边界可视化:通过
plt.contourf()函数绘制不同类别的区域,使得类别 A 和类别 B 的区域有不同的颜色。
可视化效果
- 蓝色圆点:类别 A 的训练数据点。
- 红色叉号:类别 B 的训练数据点。
- 绿色大圆点:测试点。
- 阴影区域:展示了朴素贝叶斯分类器的决策边界,不同的阴影区域代表不同的分类区域。
结果
- 通过朴素贝叶斯算法对测试点进行预测,并显示图形,帮助你直观理解朴素贝叶斯算法如何对不同的类别进行区分。
- 图形展示了训练数据、测试点及其决策边界,明确地展示了分类区域的划分。
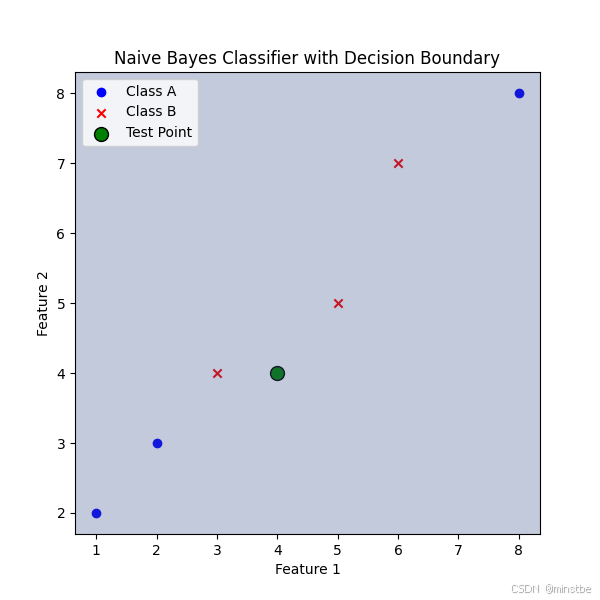
这段代码将帮助你更好地理解朴素贝叶斯分类的原理,并通过可视化的方式直观地展示算法的分类效果。
4. 感知器算法(Perceptron)
感知器是一种简单的线性分类器,可以通过迭代调整权重来进行训练。
应用场景:
-
二分类问题: 感知器是最基本的线性分类模型,适用于具有线性可分性的二分类问题。例如:
- 垃圾邮件分类: 将邮件分类为垃圾邮件和正常邮件。
- 图片识别: 基于特征将图片分类为不同类型(如猫和狗)。
-
神经网络的基础: 感知器是深度学习中神经网络的基础构建块。它为后续的多层感知器(MLP)和深度神经网络(DNN)提供了基本框架。用于更复杂的应用,如:
- 图像识别: 在卷积神经网络(CNN)中使用感知器作为最基本的神经元单元进行图像分类。
- 语音识别: 基于深度神经网络对语音信号进行识别。
优点:
- 算法简单,理解和实现容易。
- 对线性可分问题效果好。
局限:
- 仅能处理线性可分问题,对于非线性问题性能较差。
- 收敛性较差,可能无法在所有情况下找到全局最优解。
# 感知器算法
def perceptron(train_data, learning_rate=0.1, epochs=10):
# 初始化权重和偏置
weights = [0] * (len(train_data[0][0]) + 1) # 特征数 + 1 for bias
for epoch in range(epochs):
for features, label in train_data:
# 添加偏置项
features = [1] + features
prediction = sum(w * f for w, f in zip(weights, features))
prediction = 1 if prediction >= 0 else 0
# 更新权重
error = label - prediction
weights = [w + learning_rate * error * f for w, f in zip(weights, features)]
return weights
# 示例训练数据 [(特征, 标签)]
train_data = [
([1, 2], 1),
([2, 3], 1),
([3, 4], 0),
([5, 5], 0),
]
# 使用感知器算法训练
weights = perceptron(train_data)
# 测试新的数据点
def predict(features, weights):
features = [1] + features # 添加偏置项
prediction = sum(w * f for w, f in zip(weights, features))
return 1 if prediction >= 0 else 0
# 测试点
test_point = [3, 3]
predicted_label = predict(test_point, weights)
print(f"预测标签: {predicted_label}")
解释:
- 感知器通过权重调整来最小化预测误差,通过迭代训练来学习权重。
- 在每次迭代时,计算误差并根据误差调整权重。
加入可视化:
感知器(Perceptron)是一种简单的线性分类算法,用于二分类任务。它通过迭代调整权重向量来使得模型能够正确分类数据点。在可视化上,感知器能够通过一个决策边界来将不同类别的数据分开。以下是实现感知器算法并加入可视化的代码。
感知器算法步骤:
- 初始化权重和偏置。
- 对每个训练样本进行预测,并根据错误的分类调整权重和偏置。
- 重复上述步骤直到收敛(即没有错误的分类)。
代码实现和可视化:
import matplotlib.pyplot as plt
import numpy as np
# 感知器算法
def perceptron_algorithm(train_data, learning_rate=0.1, epochs=100):
# 初始化权重和偏置
weights = np.zeros(len(train_data[0][0])) # 特征的维度
bias = 0
for epoch in range(epochs):
for features, label in train_data:
# 预测值:计算加权和加偏置的结果
prediction = np.dot(features, weights) + bias
# 如果预测错误,更新权重和偏置
if label * prediction <= 0:
weights += learning_rate * label * np.array(features)
bias += learning_rate * label
return weights, bias
# 示例训练数据 [(特征, 标签)]
train_data = [
((1, 2), 1),
((2, 3), 1),
((3, 3), 1),
((4, 5), -1),
((5, 5), -1),
((6, 7), -1),
]
# 可视化数据点和决策边界
train_points_positive = [point for point, label in train_data if label == 1]
train_points_negative = [point for point, label in train_data if label == -1]
# 训练感知器模型
weights, bias = perceptron_algorithm(train_data)
# 可视化训练数据点
train_points_positive_x, train_points_positive_y = zip(*train_points_positive)
train_points_negative_x, train_points_negative_y = zip(*train_points_negative)
plt.figure(figsize=(6, 6))
# 绘制正类数据点
plt.scatter(train_points_positive_x, train_points_positive_y, color='blue', label='Class 1', marker='o')
# 绘制负类数据点
plt.scatter(train_points_negative_x, train_points_negative_y, color='red', label='Class -1', marker='x')
# 绘制决策边界
x_min, x_max = plt.xlim()
y_min, y_max = plt.ylim()
# 计算决策边界的两个点
x1 = x_min
x2 = x_max
y1 = -(weights[0] * x1 + bias) / weights[1]
y2 = -(weights[0] * x2 + bias) / weights[1]
# 绘制直线作为决策边界
plt.plot([x1, x2], [y1, y2], color='green', label='Decision Boundary')
# 标题和标签
plt.title('Perceptron Algorithm with Decision Boundary')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 显示图例
plt.legend()
# 显示图形
plt.show()
代码解析:
perceptron_algorithm(): 这是感知器算法的实现,输入是训练数据(特征和标签),学习率和迭代次数(epochs)。每次迭代会通过判断预测值和实际标签的符号来更新权重和偏置,直到模型收敛。- 训练数据:
train_data是一个包含特征和标签的训练集,1和-1分别表示正类和负类。 - 决策边界: 使用感知器训练得到的
weights和bias,可以计算出决策边界。在二维空间中,决策边界的方程为w1 * x1 + w2 * x2 + b = 0,并且可以通过y = -(w1 * x + b) / w2计算得到边界线上的点。 - 可视化:
- 正类点用蓝色圆点表示。
- 负类点用红色叉号表示。
- 绿色直线是感知器算法学习到的决策边界。
结果:
- 训练数据:蓝色和红色点分别表示正类和负类数据。
- 决策边界:绿色直线表示感知器算法学习到的决策边界,将正类和负类数据分开。
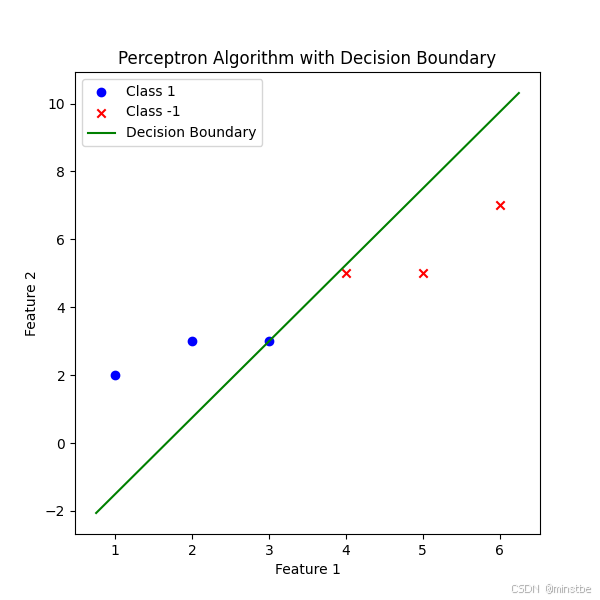
这个可视化展示了感知器算法如何通过调整权重和偏置来找到一个线性决策边界,成功地将不同类别的数据分开。
总结
这些算法各自有不同的应用领域和适用场景:
- 线性回归 适合于预测数值型结果,尤其是当数据具有线性关系时。
- K-NN 是一个简单的分类方法,适用于小型数据集,并且能够处理非线性决策边界,适合用于推荐和模式识别任务。
- 朴素贝叶斯 是一个高效的分类算法,特别适用于文本分类、垃圾邮件过滤等高维数据问题。
- 感知器 是一种基础的线性分类器,可以用于简单的二分类问题,且是神经网络的基础。
以上这些算法是人工智能领域中最基础且容易理解的算法,不依赖任何库,适合用于教学。这些算法的核心思想也能帮助学生更好地理解 AI 和机器学习的基本原理。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









