







在这里要事先说明一下我也是新手,很多东西我了解不是很深入,写算法完全是锻炼自己逻辑能力同时顺带帮助读研的朋友么解决一些实际问题。所以很多时候考虑的东西不是很全面能请各位看到博文的大牛们指正。对于排序算法说实在的我觉得已经写烂了,但是为什么还是要过一遍呢?还是为了能够打牢基础。说一下自己的看法,对于已经的玩烂的算法因该怎么学。首先最重要的还是了解算法的基本模型和算法思想,我觉得这是非常重要的。其次的话首先先尝试自己实现算法每个步骤的功能,当遇到瓶颈的时候回去看算法思想。当你写出来的时候就应该去网上找找有没有更好的实现方法。编程最大的魅力在于每个人都有每个人的套路。然后去思考自己还有哪些地方写的不够好。写算法实际上目标只有两个,对基础语法的巩固和对算法思想的理解。
堆排序
堆
在这里首先要先解释一下什么是堆,堆栈是计算机的两种最基本的数据结构。堆的特点就是FIFO(first in first out)先进先出,这里的话我觉得可以理解成树的结构。堆在接收数据的时候先接收的数据会被先弹出。
栈的特性正好与堆相反,是属于FILO(first in/last out)先进后出的类型。栈处于一级缓存而堆处于二级缓存中。这个不是本文重点所以不做过多展开。
堆排序节点访问和操作定义
堆节点的访问
在这里我们借用wiki的定义来说明:
通常堆是通过一维数组来实现的。在阵列起始位置为0的情况中
(1)父节点i的左子节点在位置(2*i+1);
(2)父节点i的右子节点在位置(2*i+2);
(3)子节点i的父节点在位置floor((i-1)/2);
堆操作
堆可以分为大根堆和小根堆,这里用最大堆的情况来定义操作:
(1)最大堆调整(MAX_Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点。这是核心步骤,在建堆和堆排序都会用到。比较i的根节点和与其所对应i的孩子节点的值。当i根节点的值比左孩子节点的值要小的时候,就把i根节点和左孩子节点所对应的值交换,当i根节点的值比右孩子的节点所对应的值要小的时候,就把i根节点和右孩子节点所对应的值交换。然后再调用堆调整这个过程,可见这是一个递归的过程。
(2)建立最大堆(Build_Max_Heap):将堆所有数据重新排序。建堆的过程其实就是不断做最大堆调整的过程,从len/2出开始调整,一直比到第一个节点。
(3)堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算。堆排序是利用建堆和堆调整来进行的。首先先建堆,然后将堆的根节点选出与最后一个节点进行交换,然后将前面len-1个节点继续做堆调整的过程。直到将所有的节点取出,对于n个数我们只需要做n-1次操作。
这里用网上的一张直观图来感受一下
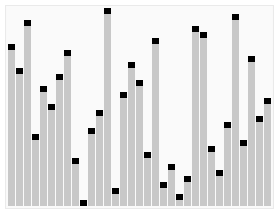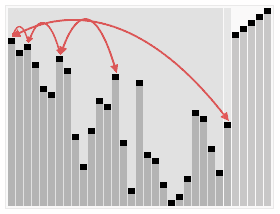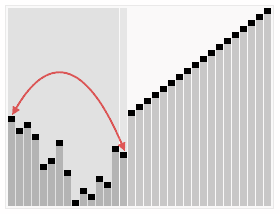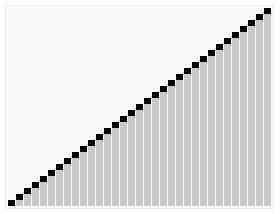
代码片
import random
def MAX_Heapify(heap,HeapSize,root):#在堆中做结构调整使得父节点的值大于子节点
left = 2*root + 1
right = left + 1
larger = root
if left < HeapSize and heap[larger] < heap[left]:
larger = left
if right < HeapSize and heap[larger] < heap[right]:
larger = right
if larger != root:#如果做了堆调整则larger的值等于左节点或者右节点的,这个时候做对调值操作
heap[larger],heap[root] = heap[root],heap[larger]
MAX_Heapify(heap, HeapSize, larger)
def Build_MAX_Heap(heap):#构造一个堆,将堆中所有数据重新排序
HeapSize = len(heap)#将堆的长度当独拿出来方便
for i in xrange((HeapSize -2)//2,-1,-1):#从后往前出数
MAX_Heapify(heap,HeapSize,i)
def HeapSort(heap):#将根节点取出与最后一位做对调,对前面len-1个节点继续进行对调整过程。
Build_MAX_Heap(heap)
for i in range(len(heap)-1,-1,-1):
heap[0],heap[i] = heap[i],heap[0]
MAX_Heapify(heap, i, 0)
return heap
if __name__ == '__main__':
a = [30,50,57,77,62,78,94,80,84]
print a
HeapSort(a)
print a
b = [random.randint(1,1000) for i in range(1000)]
print b
HeapSort(b)
print b这里的函数名我就直接用了wiki上对堆操作的定义,方便理解,其实也是方便我以后来看。
时间复杂度
堆排序的时间复杂度分为两个部分一个是建堆的时候所耗费的时间,一个是进行堆调整的时候所耗费的时间。而堆排序则是调用了建堆和堆调整。
刚刚在上面也提及到了,建堆是一个线性过程,从len/2-0一直调用堆调整的过程,相当于o(h1)+o(h2)+…+o(hlen/2)这里的h表示节点深度,len/2表示节点深度,对于求和过程,结果为线性的O(n)
堆调整为一个递归的过程,调整堆的过程时间复杂度与堆的深度有关系,相当于lgn的操作。
因为建堆的时间复杂度是O(n),调整堆的时间复杂度是lgn,所以堆排序的时间复杂度是O(nlgn)。
参考wiki地址: https://zh.wikipedia.org/zh/堆排序#Python.E8.AF.AD.E8.A8.80















 2214
2214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









