







什么是lucene
Lucene是Apache提供的全文检索工具包
相关概念
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。全文检索和数据库检索 的区别:
全文检索的数据是无规律的
全文检索提前建立索引 比数据库的like效率要高
全文检索的效果更准确- Doucment:文档
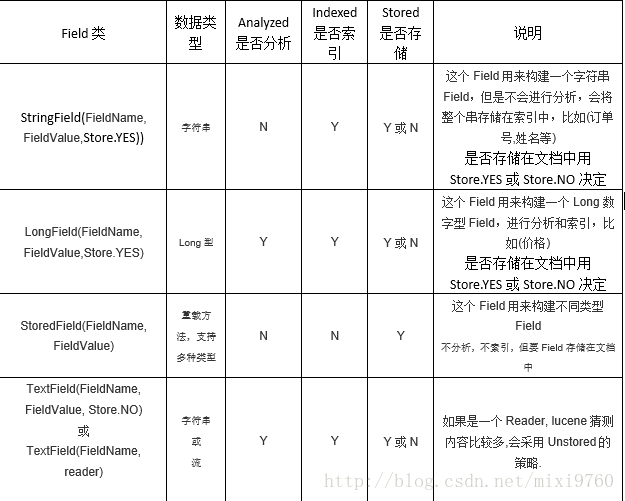
- Field: 类似与java的对象
比如一个文本文件 有 文件大小 文件名称 文件路径 等field
根据这些field 和分词器 会构成很多的term
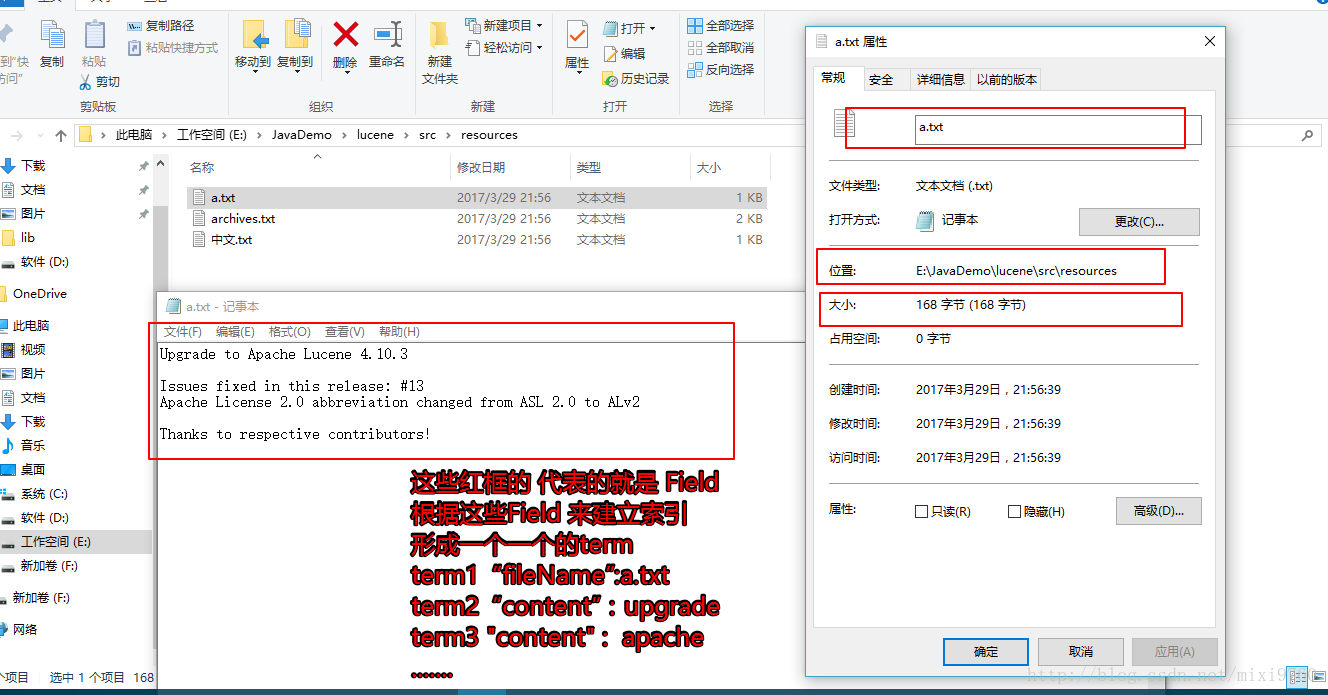
建立索引的时候索引库 一方面保存 文档 一方面保存这些 term 。后期根据这些term进行查询文档
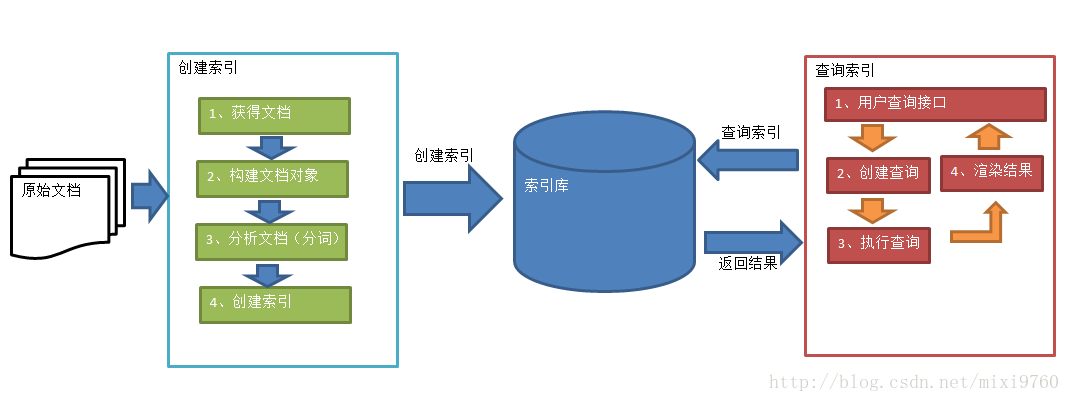
建立索引
//第一步:创建一个java工程,并导入jar包
//第二步:创建一个indexwriter对象
//1)指定索引库的存放位置Directory对象
Directory directory = FSDirectory.open(new File(rootPath + "/temp"));
//2)指定一个分析器,对文档内容进行分析
//Analyzer analyzer = new StandardAnalyzer();//标准分词器 英文
Analyzer analyzer = new IKAnalyzer();//第三方中文分词器
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
//第三步:创建field对象,将field添加到document对象中
File file = new File(rootPath + "/resources");
File[] files = file.listFiles();
//遍历目录中的文件
for (File f : files) {
//第四步:创建document对象
Document document = new Document();
//文件名称
String fileName = f.getName();
Field fileNameField = new TextField("fileName", fileName, Field.Store.YES);
//文件内容
String content = FileUtils.readFileToString(f);
Field contentField = new TextField("content", content, Field.Store.YES);
//文件大小
long size = FileUtils.sizeOf(f);
Field sizeField = new LongField("size", size, Field.Store.YES);
//文件路径
String path = f.getPath();
System.out.println(path);
Field pathField = new StoredField("path", path);
document.add(fileNameField);
document.add(contentField);
document.add(sizeField);
document.add(pathField);
//第五步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。
//并将索引和document对象写入索引
indexWriter.addDocument(document);
}
//第六步;关闭流
indexWriter.close();查询索引
//第一步:创建一个Directory对象,也就是索引库存放的位置
Directory directory = FSDirectory.open(new File(rootPath + "/temp"));
//第二步:创建一个indexReader对象,需要指定Directory对象
IndexReader indexReader = DirectoryReader.open(directory);
//第三步:创建一个indexSearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//第四步:创建一个TermQuery对象,指定查询的域和查询的关键词
Term term = new Term("fileName", "中文");
//方式一:精准查询
Query termQuery = new TermQuery(term);
//方式二:查询所有
//Query query=new MatchAllDocsQuery();
//方式三:数值范围查询 最小值 最大值 区间
//Query query=NumericRangeQuery.newIntRange("size",100,1000,true,true);
//方式四:组合条件查询
//BooleanQuery query=new BooleanQuery();
//query.add(query1, BooleanClause.Occur.MUST);
//query.add(query2, BooleanClause.Occur.MUST);
//方式五:解析查询 参数一:默认域 参数二:分词器
//QueryParser queryParser=new QueryParser("fileName",new IKAnalyzer());
//语法:
// 查询所有 *:*
// 指定查询 域:查询的内容
// 范围域:{ 数字 to 数字}
// 组合查询:域:查询的内容 and/not/or 域:查询的内容
//Query query= queryParser.parse("*:*");
//Query query= queryParser.parse("fileName:中文");
//第五步:执行查询
TopDocs topDocs = indexSearcher.search(termQuery, 2);
//第六步:返回查询的结果,遍历查询结果并输出
ScoreDoc[] scoreDocs = topDocs.scoreDocs;//文档id 数组
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
//文件名称
System.out.println(document.get("fileName"));
//文件内容
System.out.println(document.get("content"));
//文件路径
System.out.println(document.get("path"));
//文件大小
System.out.println(document.get("size"));
System.out.println("---------------end-----------------");
}
//第七步:关闭IndexReader对象
indexReader.close();














 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









