







python 人脸识别并截取人脸保存
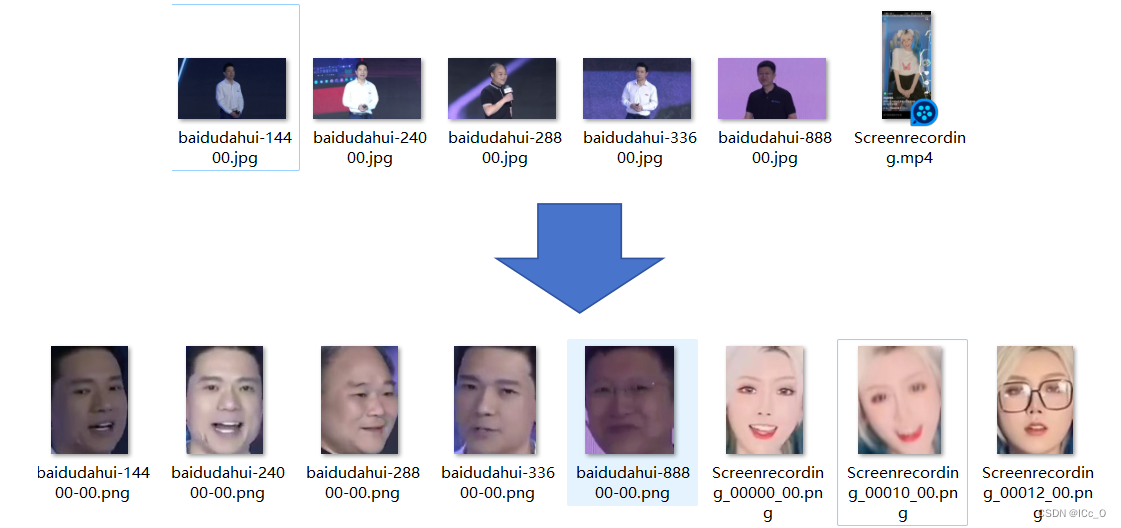
实现的功能
1.界面化,拖入包含图片/视频的文件夹后,一键统一处理
2.实现人脸识别并截取保存功能
3.可以处理图片和视频
import os, time, sys, cv2, random
import tkinter as tk
import windnd
import numpy as np
baseDirPath = sys.path[0] #在导入paddlehub之前执行, 否则地址会被改变
print(baseDirPath)
import paddlehub as hub #百度方案
#加载模型
module = hub.Module(name = 'pyramidbox_lite_server')
VideoType = ['mp4', 'flv', 'webm', 'wmv', 'ts']
PicType = ['jpg', 'png', 'bmp', 'jpeg']
video_path = baseDirPath + '\\01\\movie'
face_pic_dir = baseDirPath + '\\01\\pic'
if not os.path.exists(face_pic_dir):
os.makedirs(face_pic_dir)
###########################################################
#读含中文/韩文/日文等特殊字符路径的图片
def cv_imread(in_path):
im = cv2.imdecode(np.fromfile(in_path, dtype=np.uint8),-1)
return im
#路径中有中文名 cv2写
def cv_imwrite(out_path, imp_np):
imp_type = '.' + out_path.split('.')[-1]
cv2.imencode(imp_type, imp_np)[1].tofile(out_path)
############################################################
###############################################
#1.pic--face 图片人脸识别
def getFaceFromPic(vin_path, vout_dir):
src = cv_imread(vin_path)
pic_name = vin_path.split('\\')[-1].split('.')[0]
result = module.face_detection(data = {'data':[src]})
for i in range(len(result[0]['data'])):
if result[0]['data'][i]['confidence'] > 0.9:
left = result[0]['data'][i]['left']
top = result[0]['data'][i]['top']
right = result[0]['data'][i]['right']
bottom = result[0]['data'][i]['bottom']
img = src[top:bottom, left:right]
pic_o = vout_dir + f'\\{pic_name}-{i:02d}.png'
cv_imwrite(pic_o, img)
#2.video -- face 视频帧提取后人脸识别
def getFaceFromVideo(vin_path, vout_dir):
print('processing---',vin_path)
cap = cv2.VideoCapture(vin_path)
video_fullname = os.path.basename(vin_path)
video_name = video_fullname.split('.')[0]
total_frame = cap.get(7)
video_fps = cap.get(5)
cap_frames = []
d_t = 10 #每10s取1帧pic
d_i = 1 #计数
if (video_fps < 15) or (total_frame < (30 * video_fps)): #帧率小于15或时长小于30s跳过
return
while True:
if d_i * d_t * video_fps > total_frame: #超过总时长则退出
break
cap_frames = cap_frames + [int(d_i * d_t * video_fps)]
d_i += 1
if len(cap_frames) > 0:
pic_num = 0
for cap_frame in cap_frames:
pic_dir = vout_dir + '\\pic_cache\\' + video_name
if not os.path.exists(pic_dir):
os.makedirs(pic_dir)
#pic_path = pic_dir + '\\' + video_name + f'-{pic_num:05d}.png'
cap.set(cv2.CAP_PROP_POS_FRAMES, cap_frame)
r_val, v_frame = cap.read()
if r_val:
#cv_imwrite(pic_path, v_frame)
result = module.face_detection(data = {'data':[v_frame]})
for i in range(len(result[0]['data'])):
if result[0]['data'][i]['confidence'] > 0.9:
left = result[0]['data'][i]['left']
top = result[0]['data'][i]['top']
right = result[0]['data'][i]['right']
bottom = result[0]['data'][i]['bottom']
img_crop = v_frame[top:bottom, left:right]
dst_path = vout_dir + '\\' + f'{video_name}_{pic_num:05d}_{i:02d}.png'
cv_imwrite(dst_path, img_crop)
pic_num += 1
if __name__ == '__main__':
root = tk.Tk()
root.geometry('1080x540')
#文件夹
src_path = tk.StringVar()
src_path.set(r'D:\Python')
def dragged_src(files):
msg = '\n'.join((item.decode('gbk') for item in files))
src_path.set(msg)
def bt_get_face():
src_paths = src_path.get()
file_list = []
if os.path.isfile(src_paths):
file_list = [src_paths]
elif os.path.isdir(src_paths):
for root, dirs, files in os.walk(src_paths):
for file in files:
file_list += [os.path.join(root, file)]
print(file_list)
for file_path in file_list:
file_type = file_path.split('.')[-1]
if file_type.lower() in VideoType:
getFaceFromVideo(file_path, face_pic_dir)
if file_type.lower() in PicType:
getFaceFromPic(file_path, face_pic_dir)
print('-------------finish------------')
#############界 面 绘 制##########################
face_fm = tk.LabelFrame(root, text='文件名处理', padx= 2, pady = 2)
face_fm.pack(fill = 'x')
label_src_dir = tk.Label(face_fm, text = '图片文件夹', padx= 2, pady = 2)
label_src_dir.pack(side='left')
et_src_path = tk.Entry(face_fm, width = 40, textvariable = src_path)
et_src_path.pack(side='left', padx = 2,pady = 2)
windnd.hook_dropfiles(et_src_path , func = dragged_src)
bt_sfd1 = tk.Button(face_fm, text='处理', width = 6, command = bt_get_face)
bt_sfd1.pack(side ='left',padx = 2)
root.mainloop()
源码:https://download.csdn.net/download/mjc1321/89070532















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









