







上篇文章中记录了二叉树的基本功能的实现,现在继续总结二叉树的学习。为啥要用二叉查找树呢,我们知道在顺序表上使用二分查找是非常快的,但是顺序表的插入和删除就显得有点麻烦;而链表的插入和删除仅需要调整一些指责就OK了。二叉查找树就是要达到快速查找(就像顺序表上的二分查找),而且要做到快速的插入和删除(就想操作链表一样)。
下面是基本定义:二叉查找树是一颗二叉树,它或者为空,或者它的每个节点有一个键(在数据元素内),而且满足下列条件
1.根(如果存在)的键比根的左子树中任意结点的键大
2.根(如果存在)的键比根的右子树中任意结点的键小
3.根的左右子树还是二叉查找树
接着就要贴代码了,这里的类Search_tree继承自Binary_tree,为了简单实验没有定义键和数据的结构体,测试时直接用int型代替,关于类Binary_tree可以参考http://blog.csdn.net/mjlsuccess/article/details/14223715
Search_tree类定义
#include "Binary_tree.h"
enum Error_code {success, not_present, duplicate_error};
template<class Record>
class Search_tree:public Binary_tree<Record>
{
public:
Error_code insert(const Record& new_data);
Error_code remove(const Record& old_data);
Error_code tree_search(Record &target) const;
private://一些辅助函数
Error_code remove_root(Binary_node<Record>* & sub_root);
Binary_node<Record>* search_node(Binary_node<Record>* sub_root, Record& target) const;
Error_code search_and_insert(Binary_node<Record>* & sub_root, const Record& new_data);
Error_code search_and_destroy(Binary_node<Record>* & sub_root, const Record & target);
};有两个函数提供了非递归版本,但是还没有做测试
#include "Search_tree.h"
//插入操作,不能重复插入否则返回 duplicate_error
template<class Record>
Error_code Search_tree<Record>::insert(const Record& new_data)
{
return search_and_insert(root, new_data);
}
template<class Record>
Error_code Search_tree<Record>::search_and_insert(Binary_node<Record>* & sub_root,
const Record& new_data)
{
#if 1
if(sub_root==NULL)
{
sub_root = new Binary_node<Record>(new_data);
return success;
}
else if(new_data < sub_root->data)
return search_and_insert(sub_root->left, new_data);
else if(new_data > sub_root->data)
return search_and_insert(sub_root->right, new_data);
else return duplicate_error;
#else //非递归版
while (sub_root != NULL)
{
if(new_data < sub_root->data)
sub_root = sub_root->left;
else if(new_data > sub_root->data)
sub_root = sub_root->right;
else
return duplicate_error;
}
sub_root = new Binary_node<Record>(new_data);
return success;
#endif
}
//查找操作
template<class Record>
Binary_node<Record>* Search_tree<Record>::search_node(
Binary_node<Record>* sub_root, Record& target) const
{
#if 1
if(sub_root->data == target || sub_root == NULL)
return sub_root;
else if(sub_root->data > target)
return search_node(sub_root->left, target);
else
return search_node(sub_root->right, target);
#else //非递归版本
while(sub_root->data != target || sub_root != NULL)
{
if(sub_root->data < target) sub_root = sub_root->right;
else sub_root = sub_root->left;
}
return sub_root;
#endif
}
template<class Record>
Error_code Search_tree<Record>::tree_search(Record &target) const
{
Binary_node<Record>* node = search_node(root, target);
if(node == NULL)
return not_present;
else
{
target = node->data;
return success;
}
}
//删除操作,删除操作首先找到待删除的结点但并不释放内存,而是接着获取该节点的
//左子树,然后一直查询到左子树的最右边的结点,把该节点的data赋给带删除的节点
template<class Record>
Error_code Search_tree<Record>::remove_root(Binary_node<Record>* & sub_root)
{
if(sub_root == NULL) return not_present;
Binary_node<Record>*to_delete = sub_root;
if(sub_root->right==NULL) sub_root = sub_root->left;
else if(sub_root->left == NULL) sub_root = sub_root->right;
else
{
to_delete = sub_root->left;
Binary_node<Record>*parent = sub_root;
while(to_delete->right !=NULL)
{
parent = to_delete;
to_delete = to_delete->right;
}
sub_root->data = to_delete->data;
if(parent==sub_root) sub_root->left = to_delete->left;
else parent->right = to_delete->left;
}
delete to_delete;
return success;
}
template<class Record>
Error_code Search_tree<Record>::remove(const Record& old_data)
{
return search_and_destroy(root, old_data);
}
template<class Record>
Error_code Search_tree<Record>::search_and_destroy(
Binary_node<Record>* & sub_root, const Record & target)
{
if(sub_root==NULL || sub_root->data==target)
return remove_root(sub_root);
else if(target < sub_root->data)
return search_and_destroy(sub_root->left, target);
else
return search_and_destroy(sub_root->right, target);
}(1)这里要注意的是插入操作和删除操作,这两个操作都是需要不断地去比较,如果能优化比较次数,那么算法就得到优化
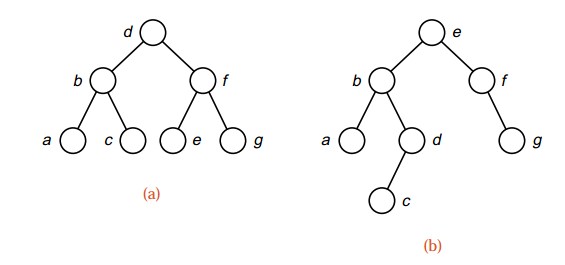

上传了2张图片,(a)树对查找来书是最佳的,它最为茂密,树越茂密通常要比较的次数就越少。显然(a)(b)树要优于下面的树,那么在插入元素时不要将insert方法用于已排过序的键,否则你可能就得到如图(e)中的二叉树,其实(e)图中的树已经退化为链表了
(2)关于删除操作,首先是遍历得到要删除结点的位置记为a,移到它的左结点记为b,然后对b移到它尽可能远的右结点记为c,接下来把c的值赋给a,删除c,完成操作。当然还有一些特殊情况要考虑
-----------------简单的测试代码------------------------
#include <iostream>
#include "Search_tree.h"
using namespace std;
void print( int& x);
int main()
{
Search_tree<int> dd;
dd.insert(8);
dd.insert(4);
dd.insert(2);
dd.insert(6);
dd.insert(1);
dd.insert(2);
dd.insert(3);
dd.insert(12);
dd.insert(10);
dd.insert(14);
cout<<"preorder: ";
dd.preorder(print);
cout<<endl;
cout<<"inorder: ";
dd.inorder(print);
cout<<endl;
int a = 14;
if(dd.tree_search(a) == success)
cout<<"find "<<a<<" success"<<endl;
//删除
dd.remove(4);
cout<<"preorder: ";
dd.preorder(print);
cout<<endl;
system("pause");
return 0;
}
void print( int& x)
{
cout<<x<<" ";
}














 1748
1748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









