






Python在读取中文数据的时候经常会出错
例如,有以下代码,想要打印一下是否读取到了stopkey:
stopkey = [w.strip() for w in codecs.open('data/stopWord.txt', encoding='UTF-8').readlines()]
print(stopkey)
错误信息如下:
UnicodeEncodeError: 'gbk' codec can't encode character '\xa9' in position 32: illegal multibyte sequence
很明显这是一个字符编码的问题,工程默认的编码方式是gbk,所以无法打印出utf-8编码的字符。
- 点击File–>settings:
- 找到Editor–>File Encodings
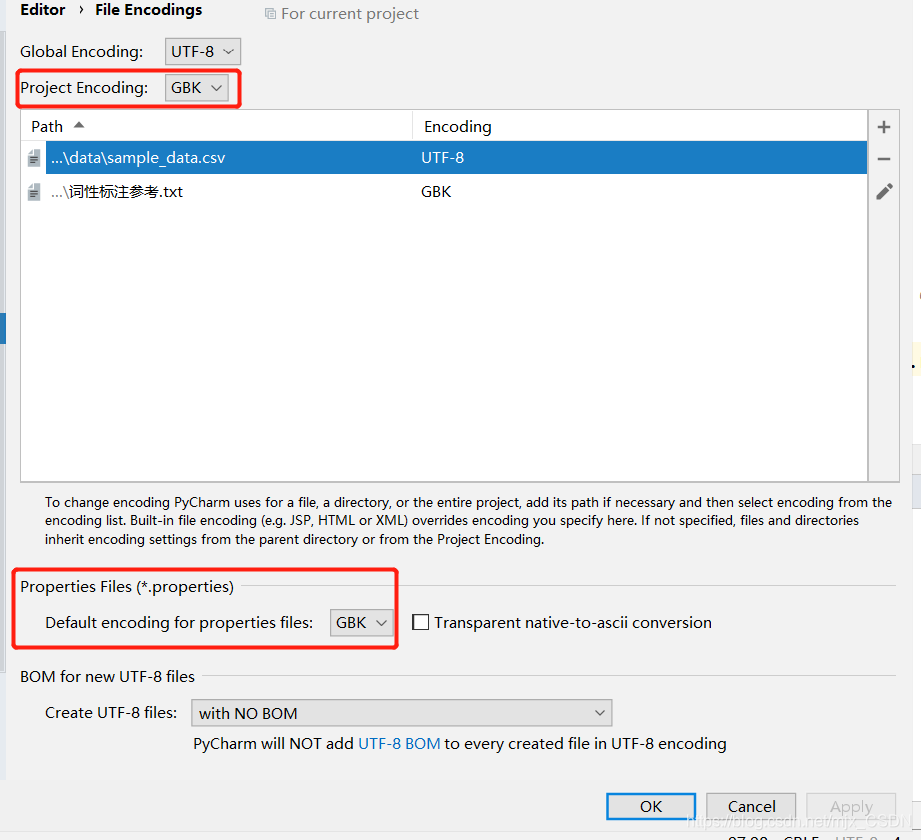
- 将红色框住的部分修改为UTF-8
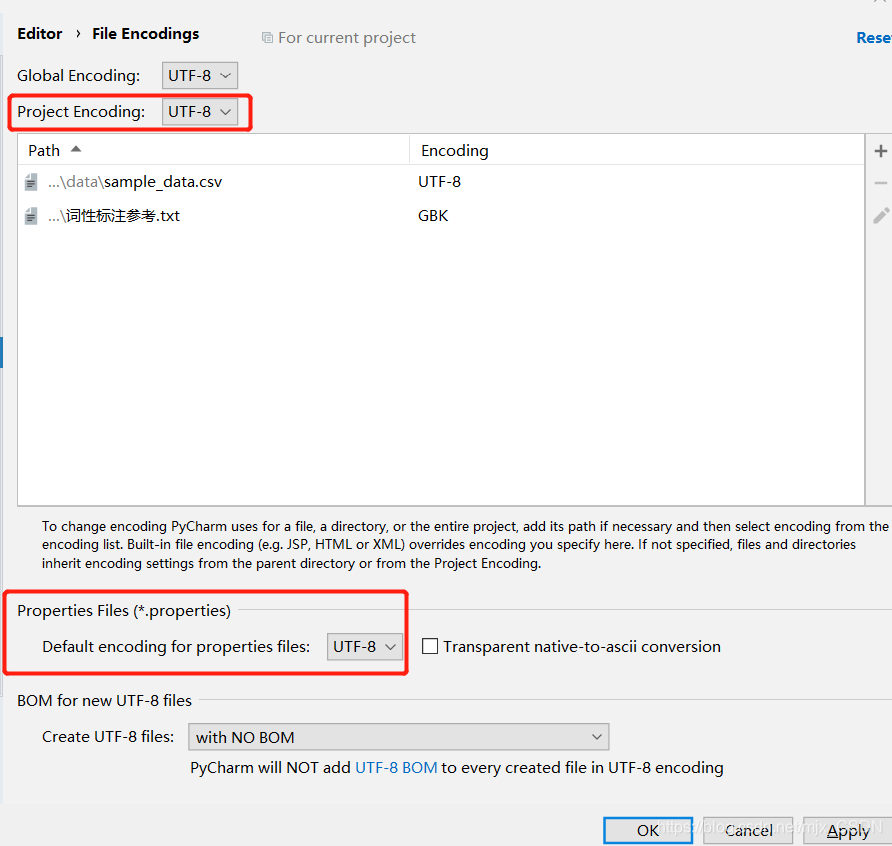
- 点击OK就可以了:
最终结果,成功打印出来了:
















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









