







 本文介绍了如何利用Scrapy爬取依赖AJAX技术渲染的动态网页。动态网页通常通过AJAX实现异步更新,部分内容需要发送特定HTTP头信息来获取。文章通过实例展示了如何构造URL和设置请求头,以提取网页中的数据。
本文介绍了如何利用Scrapy爬取依赖AJAX技术渲染的动态网页。动态网页通常通过AJAX实现异步更新,部分内容需要发送特定HTTP头信息来获取。文章通过实例展示了如何构造URL和设置请求头,以提取网页中的数据。
[http://scrapy2016.12.1/dongtaiwangye]
本节内容
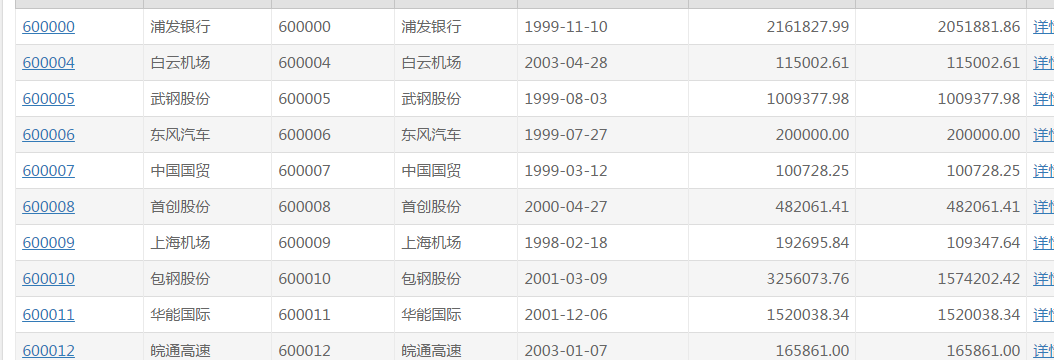
动态网页一般是通过AJAX进行技术渲染,AJAX是指一种创建交互式网页应用的网页开发技术,即通过后台与服务器进行少量数据交换,AJAX可以使网页实现异步更新,这就意味着可以在不重新加载整个页面的情况下,对网页的某部分进行更新。在某些时候,网站的某些内容的访问需要回复才能看到全部内容,所以我们需要通过发送给服务器http头信息来获取到内容。本节就来介绍通过发送给服务器http头信息方法,来获取所需要的内容。我们想要提取的网页内容,如下图,链接为[http://www.sse.com.cn/assortment/stock/list/share/]。
- 从JavaScript中读取内容
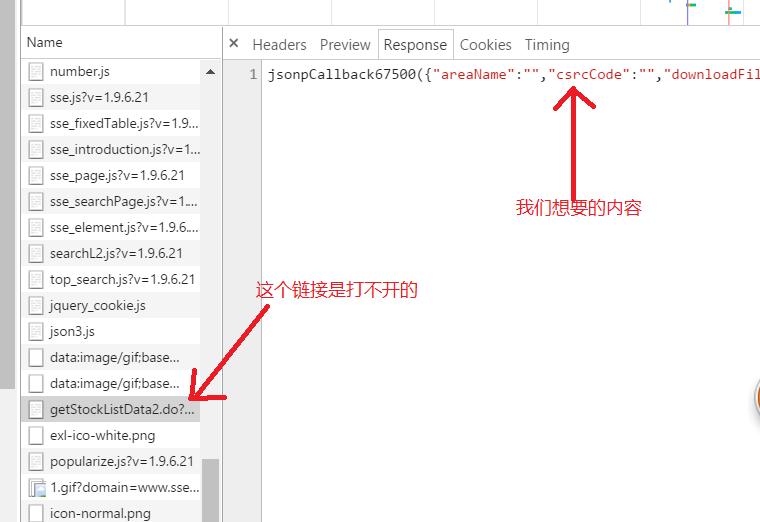
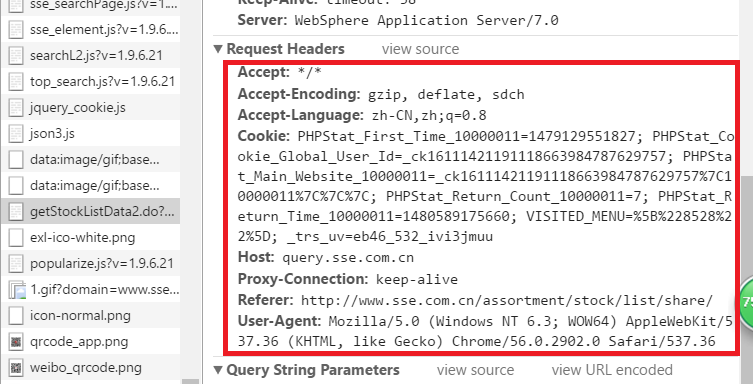
链接打不开的原因打不开的原因就在于,在浏览器上访问的request头信息与程序提交的头信息不同,因此我们需要头信息,如下图Cookie="PHPStat_First_Time_10000011=1479129551827; PHPStat_Cookie_Global_User_Id=_ck16111421191118663984787629757; PHPStat_Main_Website_10000011=_ck16111421191118663984787629757%7C10000011%7C%7C%7C; PHPStat_Return_Count_10000011=6; PHPStat_Return_Time_10000011=1480472254948; _trs_uv=eb46_532_ivi3jmuu; VISITED_MENU=%5B%228528%22%5D"
headers ={
'User-agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2902.0 Safari/537.36',
'Cookie': Cookie,
'Connection': 'keep-alive',
'Accept': '*/*',
'Accept-Encoding':'gzip, deflate, sdch'
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4786
4786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









