









Learning to Super Resolve Intensity Images from Events
从事件中学习超分辨强度图像
项目代码点击此处或者 https://github.com/gistvision/e2sri
这篇文章和E2SRI:Learning to Super Resolve Intensity Images from Events感觉是同一个意思,不过一个投的IEEE一个投的CVPR,E2SRI这篇要详细一点~~
老规矩,先看看摘要:
事件相机检测每个像素的强度差异,并产生具有低延迟、高动态范围和低功耗的异步事件流。作为权衡,事件相机具有低空间分辨率。我们提出了一个端到端网络来直接从事件流中重建高分辨率、高动态范围 (HDR) 图像。我们在模拟和真实世界序列上评估我们的算法,并验证它捕捉场景的精细细节,并优于将最先进的事件与图像算法与最先进的超分辨率方案相结合许多量化措施大幅度提高。我们通过使用主动传感器像素 (APS) 帧或迭代重建图像来进一步扩展我们的方法。
1.Introduction
事件相机,也称为神经形态相机,其低成本、高动态感应范围、低延迟和低功耗。它通过检查具有预定义阈值的强度变化量,将像素位置 (x, y) 的强度变化表示为异步的正号或负号 (σ)。这种类似于流的表示,取决于场景和相机的移动,可以通过准确的时间戳 (t) 实现 μs 级的延迟,并以 (x, y, t, σ) 的形式表示每个触发事件。
通过将 APS 帧视为输入或迭代地学习网络以向初始图像添加细节来重建更多细节。
2.Related Work
事件到强度图像。
之前的方法在生成的强度图像中将错误作为阴影状伪影传播。
图像超分辨率 (SR)。
3.Approach
论文提出了一个全卷积网络,它以感兴趣的时间戳附近的一系列事件堆栈作为输入,将它们与由 FNet 获得的光流成对关联,并通过 EFR 校正成对堆栈和流的组合,然后将它们馈送到基于循环神经网络的超分辨率网络(SRNet),该网络输出每个堆栈的隐藏状态和中间强度输出。最后,论文通过混合来自多个时间戳的中间输出来构建一个超分辨强度图像。
3.1 Event Stacking Method(事件堆叠方法)
事件的流式表示在空间域中是稀疏的,需要准备捕获场景细节以由卷积神经网络重建。尽管最近在堆叠方法方面取得了进展,但我们的网络使用简单的堆叠方法(例如基于事件数 (SBN) 的堆叠)表现良好。通过对我们网络的输入块进行少量修改,可以直接使用高级堆叠方法。
使用 SBN,从事件流中的任何时间戳开始,我们计算事件的数量,直到达到预定义的数量 (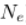 ),然后累积事件以在堆栈中形成一个通道。我们对一个堆栈重复此过程 c 次。因此,每个堆栈包含总共
),然后累积事件以在堆栈中形成一个通道。我们对一个堆栈重复此过程 c 次。因此,每个堆栈包含总共 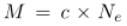 事件,具有 h × w × c 的维度,其中 h 和 w 分别是 APS 图像的宽度和高度。这个 c 通道堆栈作为输入被馈送到网络中。对应的 APS 帧在堆栈中最后一个事件的时间戳处被采样,以获取基本事实 (GT)。在每个通道,所有像素值初始设置为 128。如果一个事件在位置 (x, y) 被触发,我们将同一通道中 (x, y) 处的像素值替换为 256(正事件)或 0(正事件)事件)。由于新出现的事件可以覆盖旧事件,因此需要仔细选择 M 以更好地保留时空视觉信息。帧速率可以由 Ne 和每个堆栈之间的重叠事件数随时间确定。
事件,具有 h × w × c 的维度,其中 h 和 w 分别是 APS 图像的宽度和高度。这个 c 通道堆栈作为输入被馈送到网络中。对应的 APS 帧在堆栈中最后一个事件的时间戳处被采样,以获取基本事实 (GT)。在每个通道,所有像素值初始设置为 128。如果一个事件在位置 (x, y) 被触发,我们将同一通道中 (x, y) 处的像素值替换为 256(正事件)或 0(正事件)事件)。由于新出现的事件可以覆盖旧事件,因此需要仔细选择 M 以更好地保留时空视觉信息。帧速率可以由 Ne 和每个堆栈之间的重叠事件数随时间确定。
我们凭经验选择每个堆栈使用 3,000 个事件,其中每个堆栈有 3 个通道。可以针对具有较大分辨率事件输入的实验修改此数字,以确保堆栈中的平均事件数显示具有精细细节的视觉上合理的输出。然而,由于网络是在包含不同数量的本地事件的不同场景上训练的,所以网络在推理时对每个堆栈选择的事件数量不是很敏感。
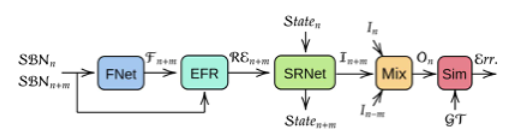
我们的端到端事件到超分辨率强度图像框架的概述。输入堆栈 SBNn+m 和中央堆栈 SBNn 被提供给 FNet 以创建光流 (Fn+m)。流和堆栈连接起来并提供给 EFR 以纠正事件特征。其输出 REn+m 与前一个状态 (Staten) 一起提供给 SRNet,以创建中间强度输出 In+m 和下一个状态 (Staten+m)。所有中间强度输出被连接并提供给混合器 (Mix) 网络,该网络创建最终输出 (On)。最后,使用相似性损失(Sim)将输出与训练groundtruth(GT)进行比较,包括Learned Perceptual Image Patch Similarity(LPIPS)项和l1项来计算误差(Err)。
3.2 网络架构
我们按照三个原则设计网络架构。首先,我们考虑输入和目标的特征(第 3.2.1 节)。其次,我们为超分辨率网络(SRNet)提供了足够大的假设空间,以解决场景中各种复杂程度的运动(第 3.2.4 节)。最后,我们提出了一种新颖的目标函数,它可以添加结构细节,同时远离模糊和伪影(第 3.2.6 节)。我们描述了我们提出的网络的每个组件的细节。
3.2.1 综述
我们考虑为我们的网络输入堆叠的事件流。特别是,对于三个堆栈(3S)的输入序列,堆栈是包含第n个APS时间戳(SBNn)的堆栈,它之前的堆栈SBNn-m和它之后的堆栈(SBNn+m)。
每个堆栈有 M 个(例如,3, 000)个事件,其结束位置 m 将根据触发 M 个事件所需的时间量在事件的时间线上变化。 SBNn 是三个序列中的中央堆栈。它在 SBNn-m 之后被馈送到网络,预测的强度输出对应于这个堆栈。如果堆栈之间没有重叠(L = 0)(图 3 中的“非重叠”输入),则 SBNn+m 和 SBNn-m 堆栈分别距中央堆栈的开头或结尾有 M 个事件。我们还可以使用重叠堆栈来创建更高的帧率;下一个堆栈的结尾将是中心减去重叠量 (M -L) 之后的 M 个事件(图 3 中的“重叠”输入)。补充中提供了有关重叠堆叠的更多详细信息。
SBNn+m 和 SBNn-m 与中央堆栈分别馈送到光流估计网络 (F Ne t) 以预测堆栈之间的光流 (Fn+m 或 Fn-m)。这些事件堆栈与 F Net 获得的光流连接,然后由事件特征校正网络 (EF R) 进行校正。然后将校正后的事件堆栈(REn+m)提供给超分辨率网络(SRNet)。 SRNet 使用修正后的事件堆栈 (REn+m) 获取前一个状态 (Staten),并创建顺序模型的下一个状态 (Staten+m) 和超分辨强度,如输出 (In+m)。
由于堆栈将连续事件流量化为单独的输入,因此每个堆栈可能不包含重建图像所需的所有细节。因此,来自所有堆栈的中间强度输出然后由混合器网络 (Mi x) 混合,以重建具有丰富细节的强度图像 On。对于初始堆栈,仅将第一个堆栈馈送到 EF R 子网络以创建初始 Staten。 Mi x 的输出被提供给相似性网络 (Sim),以根据误差 (Err) 优化参数。
3.2.2 Flow Network (FNet)(流网络)
堆叠事件流的一个不希望的缺点是失去了堆栈之间的时间关系。堆栈之间丢失的时间关系可以通过使用堆栈序列和每对堆栈之间的光流来部分恢复,因为光流报告场景中的触发事件如何移动以及变化发生在哪个位置。 SBN 堆叠包含足够的边缘信息,可以用作众所周知的基于学习的光流估计算法的图像输入。因此,我们不对其进行微调,而是使用预训练的FNet 用于计算效率1。我们使用 [9] 作为我们的流量估计网络,并将其称为 FNet。

建议方法中的详细数据流。此示例基于第三个堆栈 (SBNn+m),因此先前的输入、光流和中间强度输出都被淡化了。将 APS 帧调整为输出大小 (On) 以进行比较
3.2.3 Event Feature Rectification Network (EFR)(事件特征校正网络)
堆叠事件的另一个缺点是在快速触发位置覆盖先前的事件信息。被覆盖的事件会导致事件堆栈模糊,并最终导致重建质量降低。为了防止覆盖事件,我们将两个事件堆栈与光流连接起来,并将其提供给两个称为事件特征校正 (EFR) 网络的卷积层。通过 EFR,我们逐步融合事件流上的堆栈以保留每个事件的详细信息。
当两个堆栈在仅一个堆栈可见的位置具有光流无法关联的事件时,EFR 有助于重建图像,因为我们使用 EF 、R 的所有三个输入,所以这些事件更有可能被保留用于强度重建。注意中央堆栈在没有估计流量的情况下提供给该网络,因为它没有流量。
3.2.4 Super Resolution Network (SRNet)(超分辨率网络)
纠正后的事件现在由我们称为SRNet的主网络超级解决。我们对SRNet使用递归神经网络,因为我们堆叠的事件流的每个部分捕获输出图像的细节,并且它们最初是连续的,但是通过堆叠方法被量化。为了缓解这种不连续性,我们利用递归神经网络的内部存储状态,在每个输入堆栈内部更新状态时,以连续的方式重建具有丰富细节的不同区域。具体来说,单个事件堆栈可能会部分遗漏先前触发的事件的重要细节,这些事件不在其堆栈范围内,但已被先前的堆栈捕获。
已经表明,叠加事件能够通过深度神经网络如 U-net 合成强度图像。在架构上,我们进一步扩展了ResNet的想法,深度为15个块,具有更多过滤器和更大的内核大小。特别是,按照 MISR 中设计良好的网络,我们利用剩余学习的力量来实现超分辨强度。我们使用受 SISR 网络启发的大视野,将校正后的事件特征传输到随机共振强度发生器(RN et-C)。其主要任务是通过转置卷积运算的组合来创建初始SR强度图像状态。
SRNet被设计成在增加强度信息的同时放大输入RE。SRNet的整体结构如图4所示。我们使用三个残差网络(RNet { A,B,D})的组合,这三个残差网络由包含两个卷积层的五个ResNet块组成。这些网络比 RNet-C 更浅,因为它们编码来自先前状态的类似特征的表示,而不是直接来自校正的事件。从RN et-C的输出中减去作为上采样编码器的RN et-A的输出,以产生内部误差(en ),该误差测量当前整流事件堆栈REn+m与先前状态Staten相比贡献了多少
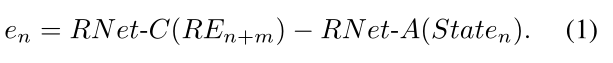
该误差作为RN et-B的输入,RN et-B用作通用编码器。我们通过RN et-B的输出与RN et-C相加来定义下一个状态(Staten+m ),因此当前输入(REn+m)被强调为
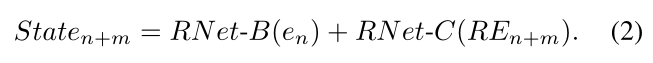
状态n+m被提供给最终解码器(RN et-D ),以使中间强度输出(In+m)为

一般而言,RN et-C通过添加前一堆栈遗漏的场景的细节,将来自当前堆栈的新信息添加到前一状态。即使在当前堆栈捕获的一些区域中没有事件,但是有场景细节在由先前堆栈捕获的区域中,先前状态(Staten)通过RN et-A保存该信息作为其隐藏状态,以重建相当缺失的区域中的场景细节。我们在附录中详述了其他设计参数,如层类型、过滤器数量。
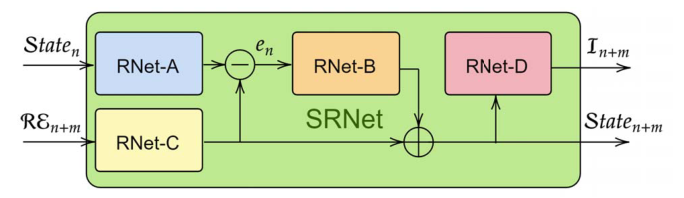
图4。所提出的超解析网络(SRNet)的详细架构(图2中的绿块)。四个主要残差网络被设计成作为大型编码器-解码器方案来执行。RNet-A用于更新隐藏状态,而RNet-B和RNet-D分别充当编码器和解码器,以将隐藏状态映射为超分辨率强度输出(In+m)。
3.2.5 Mixer Network (Mix)(混频器网络)
混频器网络旨在增强不同时间位置(I = { n m,n,n+m})的SRNet输出(Ii ),以在中央堆栈的时间戳(n)处重建细节丰富的强度图像(On)。该网络采用卷积层来重建具有精细细节的强度图像。
3.2.6 Similarity Loss (Sim)(相似性损失)
给定重建图像(O)和它的GT (G ),我们用两项定义损失函数。首先,我们使用非结构化损失,如l1范数来重建整体更清晰的图像。1(O,G) =||O G||1而不是 l2 这导致输出图像中具有低频纹理的平滑边缘。作为。1可能丢失场景的结构信息,我们进一步利用能够通过学习的感知图像块相似性(LPIPS)或感知相似性[26]作为我们的目标函数的第二项来补偿结构缺乏的标准。具体地,给定由预训练网络(例如,AlexNet [11])编码的一对图像(O,G),提取第1层的近端特征(Glhw),同时通过通道维度(Hl,Wl)对其激活进行归一化。然后,每个通道通过向量wl [26]进行缩放。2计算距离。最后,通过所有层(l)在图像轴(h,w)上计算LPIPS损失的空间平均值,如下
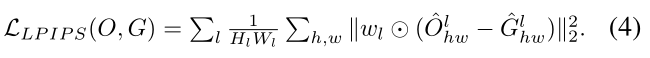
最终的目标函数Lsim是这两项的组合,平衡参数 λ 为
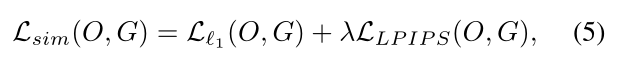
我们最小化它来学习参数。
4.Experiments and Analyses(实验和分析)
为了进行实证验证,我们使用事件摄像机模拟器(ESIM) 生成的序列和四个具有挑战性和多样性的真实世界公共数据集。[1, 15, 22, 27].我们在附录中描述了数据集的细节。对于定量分析,我们使用dB(对数标度)中的PSNR、作为零(不太相似)到一(完全相似)之间的分数的结构相似性[25] (SSIM)、均方误差(MSE)和感知相似性(LPIPS)作为度量来评估两幅图像中的高级特征的相似性(值越低,相似性越大)。对于每个实验,我们在8个Titan-Xp GPU的集群上训练我们的网络。批量大小为8,初始学习率为0.01,在给定最大历元数(例如,在我们的实验中为50)的剩余历元的每一半,初始学习率衰减10倍。我们在所有实验中使用λ = 0.01,另有说明。
/原来看了这么久,它是用的事件摄像机的模拟器得到的……不是直接用事件摄像机拍摄得到的……
4.1 Comparison with State of the Arts(与最先进水平的比较)
我们首先提出了从事件直接重建SR强度图像的任务,因此没有可直接比较的方法。因此,我们首先对输出进行下采样,并与相同大小的强度重建方法进行比较,以评估我们的重建质量。然后,我们将我们的方法与结合了最先进的超分辨率(SR)方法的最先进的强度重建方法进行比较。
Image reconstruction without super-resolution.无超分辨率重建
我们在来自事件摄像机数据集的七个具有挑战性的真实世界序列上,将我们的方法的下采样输出与最先进的事件强度图像方法进行比较[。为了符号简洁,我们将**高通滤波方法简写为 HF ,将流形正则化简写为 MR ,将事件到视频生成简写为 EV ,将条件GANs的事件到强度简写为 EG **。遵循许多真实世界事件数据集中的评估协议,我们认为APS帧为GT。我们遵循[17]的序列分割,并使用报道的HF、MR和EV的性能测量。例如,我们使用作者的重建图像来评估性能。
如表1所示,我们提出的方法优于LPIPS中的所有其他方法。这意味着重建的强度图像在感觉上比以前的方法更好。我们的方法在多个序列上也表现出较高的SSIM分数和与EG相当的MSE误差。与EV类似,我们仅用合成序列训练模型,并应用于真实世界的序列。在这种不需要微调的具有挑战性的零发射数据传输设置中,我们的方法在真实世界事件上优于其他方法。注意,LPIPS中的两个亚军方法(EV和EG)也使用基于学习的框架。
表1。与真实世界序列上最先进的强度合成方法进行比较[15]。我们的方法在LPIPS的所有序列中,以及在SSIM的平均序列中,都优于以前的方法。亚军方法带有下划线。我们使用了文献[17]中报道的HF [22]、MR [18]和EV [17]的数字,同时评估了作者重建的EG [24]的图像。

表二。与SISR [4]和MISR[7]方法相结合,从事件直接(我们的)到事件到强度图像合成(EV)的超分辨强度图像的定量比较。

超分辨率图像重建。我们现在将最先进的事件到强度重建算法与最先进的SR方法相结合,并将我们的方法与它们进行比较。对于最先进的事件强度算法,我们使用EV2,因为它是亚军方法,在大多数序列和平均上优于SSIM中的EG和LPIPS(表1)。对于超分辨率算法,我们使用两个最近的超分辨率算法;一个是SISR [4],另一个是MISR [7]。如表2所示,我们的方法在所有指标上都远远优于结合了最先进的SR算法的最先进的强度重建算法。我们使用来自ESIM生成的数据集的30个序列。
对于定性分析,我们在 图5 和 图1 中的真实世界和模拟序列上展示了通过EV、EV+MISR的组合和我们的方法的强度重建。请注意,我们的方法从事件中重建精细的细节。在图1中,EG并不总是从事件中重建场景细节,有时会产生幻觉抖动伪像。虽然EV从事件中重建场景细节比EG相对更好,但它会产生类似阴影的伪像,并使场景的某些区域变暗。此外,在数据中存在热像素的情况下,EV不过滤它们;白点或黑点出现在EV的结果中,而我们的方法主要是在没有显式操作的情况下过滤掉它们。我们在补充材料中提供了更多的结果。
我们进一步对来自另一个流行数据集[1]的序列进行实验,并在图6中定性地将我们的方法与EG和EV进行比较。我们的方法可以揭示细节这在构建相同大小的图像(如指尖或纹理)时是不可见的。

图5。直接合成SR强度图像(ours)和作为强度图像估计下游应用的超分辨(EV+MISR)之间的定性比较。突出显示的框被放大,以便更好地进行比较。
4.2 Analysis on Loss Terms (Lsim)(损失条款分析)
我们烧蚀损失函数来定量地研究图像重建中各项的影响, 表3 和 图7 定性地显示了这一点。所有分析和消融研究均采用模拟数据进行,以便利用高质量燃气轮机进行可靠的定量分析。只用Ll1第一项,我们在PSNR观察到更好的性能,但导致视觉上不太清晰的图像,从而在所有其他指标中表现不佳。仅使用LLPIPS的术语,我们观察到图像看起来在视觉上是可接受的,但是下PSNR的缺点是在事件较少的区域和边缘上有点状伪像。最终提出的损失函数Lsim在SSIM和MSE中表现最好,在PSNR和LPIPS中略有下降,但在视觉上创建了最可信的图像。

图6。在[1]的序列上,我们的缩减输出与EV和EG的定性比较(没有APS)。我们的方法能够从小到128×128像素的输入中重建结构细节。补充材料中提供了更多结果。
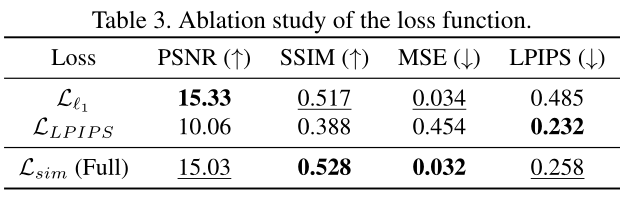
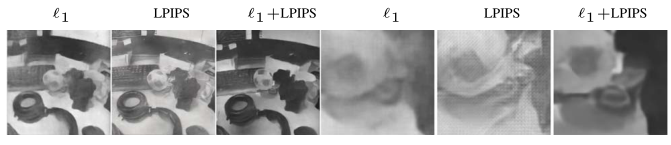
图7。损失函数对重建质量的影响。l1 规范平滑边缘,感知相似性(LPIPS)增加了结构细节,但也产生了伪像的结合l1+LPIPS (Lsim)在增加结构细节的同时显示较少的伪像。

4.3 Analysis on Super Resolution Parameters(超分辨率参数分析)
我们评估了两个随机共振参数的影响;输出质量上的放大因子(2×,4×)和堆栈序列(3S,7S)的大小。我们将结果总结在表8中。比较3S和7S,我们发现7S在所有指标上都有更好的表现。这意味着序列上较长的递归可以产生更可靠的隐藏状态并导致更高质量的输出。此外,当使用更长的序列时,更有可能捕获只发生很短时间的事件,因为在更大的递归上展开有助于保留短事件的信息。将事件超分辨为更大的图像更具挑战性,因为对于一种算法来说,处理不存在事件的大空间位置并不容易。虽然与2倍相比,MSE有所下降,但这是因为分母中的数字由于图像的大小而变大,并且与输出质量没有太大关系。

图9。极端HDR情况下的图像重建比较[15,22]。与EV和APS相比,我们的方法合成了更多的细节,同时产生了更少的伪影。请放大并比较建议的红框。
4.4 Qualitative Analysis on HDR Sequences(HDR序列的定性分析)
使用事件摄像机的一个具有挑战性的场景是捕捉极端动态范围下的事件。我们对这种极端条件下的输出进行定性分析,并与图9中的EV进行比较。包括APS框架的普通相机具有低得多的动态范围,并且或者产生黑色区域(当相机未能感测到其感测范围下的强度细节时,如顶行所示)或者产生白色区域(当光线涌入相机并且相机不能感测高于其感测范围时,如底行所示)。我们观察到,我们的方法可以解决更高的范围,并揭示更多的结构细节,EV和APS框架无法捕捉。
4.5 Analysis on the Failure Modes(失效模式分析)
失败案例大多与在长轨迹上丢失背景细节有关动作迅速。在这样的序列中,我们的方法仅恢复与我们的中心堆栈的时间距离有限的场景部分。我们在补充材料中展示并进一步分析了一些故障模式。

表4。时间稳定性误差评估(方程式。6).加号表示盲后处理[13]。我们的方法(3S,7S)不直接考虑时间一致性,但是更长的堆栈序列(7S)更一致。EV[17]使用多达L=40个输入堆栈,最初更加一致。然而,在后处理之后,我们甚至在最小的序列上得到更低的误差。
5.Extensions(扩展)
视频重建。我们的目标是重建单个图像,而不是视频。因此,帧之间的时间一致性不是我们感兴趣的,因此并不总是成立的。为了将我们的方法扩展到视频重建,我们利用盲后处理方法[12]来编码强度图像之间的时间一致性,并在补充视频中展示定性结果。为了定量评估时间一致性,我们遵循来自[13]的时间稳定性度量,其基于两个连续合成帧(Ft,Ft+1)之间的流扭曲误差:
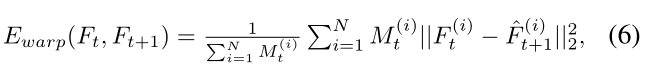
其中,Ft+1是Ft+1的扭曲帧,Mt ∈ {0,1}是基于[20]的非遮挡遮罩,以确保计算仅应用于非遮挡区域。我们计算用于扭曲帧的光流和基于APS帧的非遮挡图,用于评估所有比较的方法和APS的扭曲误差,因为它们是GT。我们在表4中总结了与EV相比不同大小的序列(3S和7S)的结果。虽然我们的方法(3S和7S)由于缺乏时间一致性而比EV差,但简单的后处理(3S+和7S+)显著提高了性能,远远超过EV [17]及其后处理版本(EV +)。
互补和双通。为了在具有挑战性的设置中评估我们的方法,我们不使用APS帧来超分辨图像。使用APS框架,我们可以进一步提高输出质量。我们通过使用APS帧作为补充[22]或Comp来命名扩展。我们用低分辨率(LR) APS帧来训练网络的初始状态中心堆栈(秒。3.2.1)并提供事件作为其附近的堆栈。我们观察到网络学习从LR输入添加更高分辨率的细节。
然而,互补方法对中心叠加的质量很敏感,特别是如果中心叠加模糊或有噪声,其伪影会传播到最终重建。为了避免这种缺点,我们提出了另一种扩展,它不使用APS帧,而是仅使用两次迭代或从事件传递,称为Duo-Pass。在第一步中,我们使用主方案仅从事件创建强度图像。在第二遍中,我们使用来自第一遍的合成强度图像作为中心堆栈,类似于我们在互补方法中使用APS帧。通过二次传递,我们能够进一步恢复第一次传递遗漏的HR细节,而无需APS帧的帮助。我们定性地比较了我们的方法(main)、Duo-Pass和Comp的结果。在图10中。我们在补充材料中提供了更多的结果。

图10。扩展。Duo-Pass迭代SR两次,互补(Comp。)使用带有APS帧的事件。
6. Conclusion(结论)
我们建议通过端到端的神经网络从事件中直接重建更高分辨率的强度图像。我们证明,我们的方法重建高质量的图像,与现有技术相比,在相同大小的图像重建和超分辨率。我们进一步将我们的方法扩展到DuoPass,该duo pass执行额外的传递以添加缺失的细节,并且除了事件之外还利用APS帧进行补充。我们还通过简单的后处理来重建视频,以确保时间一致性。
———————————————————————————————————————————
总的来说,就是:
事件摄像机通过检测每像素强度差异,产生具有低延迟、高动态范围和低功耗的异步事件流,它将像素位置(x,y)的强度变化异步表示为加号或减号(σ),通过精确的时间戳(t)实现微秒级的延迟,并以(x,y,t,σ)的形式表示每个触发的事件。方法是用预定义的阈值检查强度变化量。
我们提出了一个全卷积网络,它将感兴趣的时间戳附近的事件堆栈序列作为输入,将它们与通过F-Ne-t获得的它们的光流成对地关联,并通过EF-R校正成对堆栈和流的组合,然后将它们馈送到基于递归神经网络的超分辨率网络(SRNet ),该网络输出每个堆栈的隐藏状态和中间强度输出。最后,我们通过mix混合来自多个时间戳的中间输出,以构建超分辨率强度图像。
运行项目
设置部分
配置好ROS以及事件相机模拟器后,开始下述步骤:
Make your own environment
python -m venv ./e2sri
source e2sri/bin/activate
Install the requirements
cd e2sri
#我解压的github项目包名字为e2sri-master,所以为cd e2sri-master
pip install -r requirements.txt
Unizp pyflow
cd src
unzip pyflow.zip
cd pyflow
python3 setup.py build_ext -i
预准备部分
下载数据集,链接在github里面有给~~
下完数据集之后,数据集的压缩包名字是datasets,因为后续代码中是dataset,建议更改
推理部分
python test.py --data_dir ../dataset/slider_depth --checkpoint_path ../save_dir/2x_7s.pth --save_dir ../save_dir
我在这里遇到的问题是:
1、错误提示说有文件找不到,我把解压后的数据集文件夹名字都改成了dataset,因为解压zip后,有一个dataset文件夹,还有一个__MACOSX文件夹,该文件夹中的子文件夹名字应该也为dataset
2、RuntimeError: no valid convolution algorithms available in CuDNN
解决了,是pytorch版本不对,pytorch、cuda、cudnn、驱动这些版本必须对应

训练部分:
python3 train.py --config_path ./configs/2x_3.yaml --data_dir ../dataset/Gray_5K_7s_tiny --save_dir ../save_dir
报错:

参考:此处
find . -name "*.DS_Store" -type f -delete
删除所有的.DS_Store文件
正常运行~


搞定,后面就是用自己的数据集搞了~~















 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









