







一. 系统要求
ClickHouse可以在任何具有x86_64,AArch64或PowerPC64LE CPU架构的Linux,FreeBSD或Mac OS X上运行。 官方预构建的二进制文件通常针对x86_64进行编译,并利用SSE 4.2指令集,因此,除非另有说明,支持它的CPU使用将成为额外的系统需求。下面是检查当前CPU是否支持SSE 4.2的命令:
$ grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"要在不支持SSE 4.2或AArch64,PowerPC64LE架构的处理器上运行ClickHouse,您应该通过适当的配置调整从源代码构建ClickHouse。
二. 快速安装(单机)
本次安装操作系统为CentOS 7
1. 登陆官网 https://clickhouse.tech/#quick-start
2. 在Quick start上选择Centos or RedHat,安装步骤进行安装
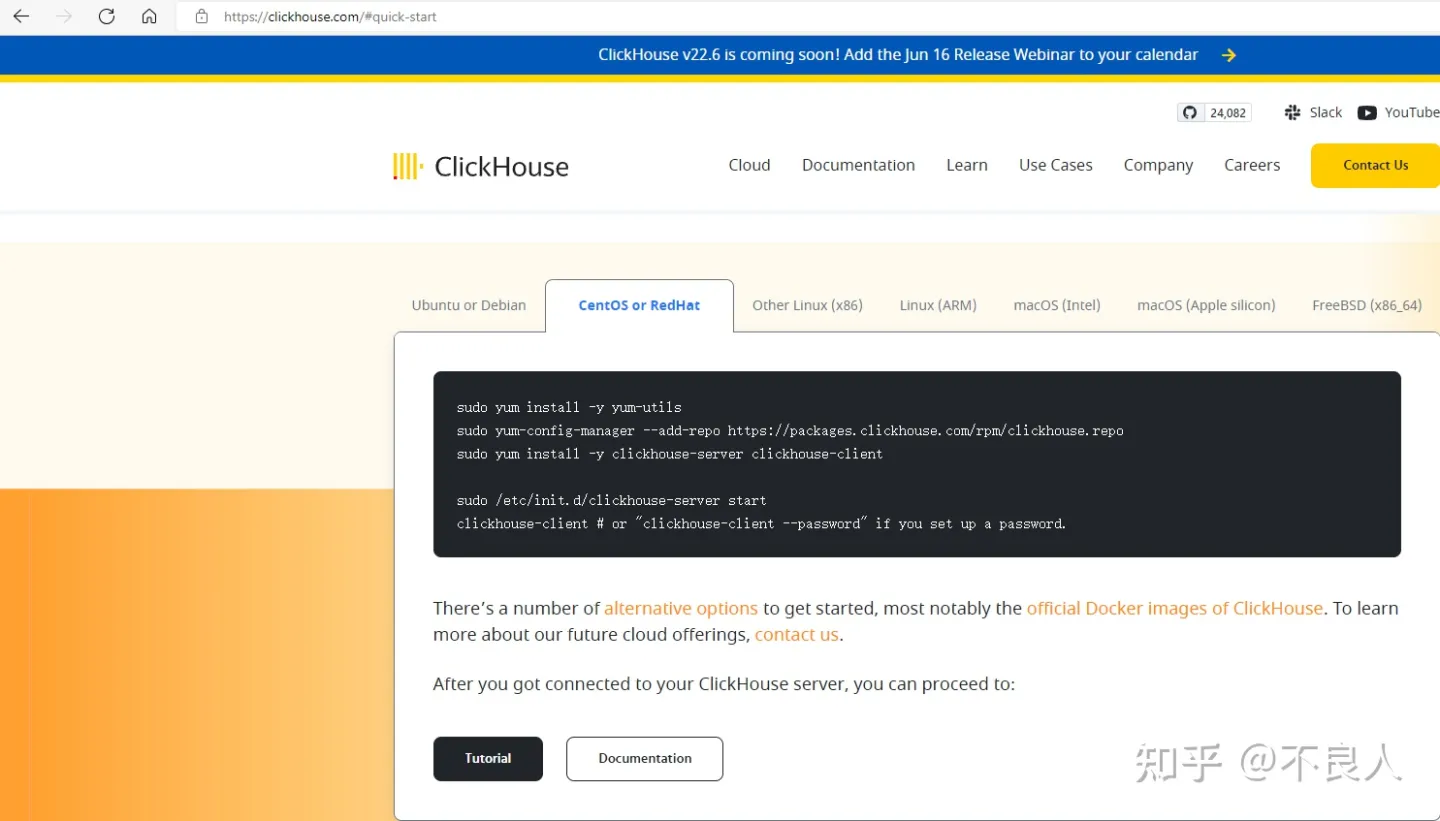
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
sudo yum install -y clickhouse-server clickhouse-client
sudo /etc/init.d/clickhouse-server start # 启动服务端
clickhouse-client # or "clickhouse-client --password" if you set up a password. # 连接客户端
clickhouse-client #启动客户端默认在localhost:9000
clickhouse-client --host=localhost --port=9000 --user=xxx --password=xxx -m
# 具体在/etc/clickhouse-server/ 里的 config.xml文件 修改listen_host和相关port
# -m:多行模式, 是指在数据表里写sql时可以将一条sql语句分行输入,否则只能将一条sql语句完整输入
3. 服务管理常用命令:
CentOS 7系统下,我们推荐使用如下命令管理clickhouse-server的启停及状态查看
systemctl start clickhouse-server
systemctl stop clickhouse-server
systemctl status clickhouse-server
4. ClickHouse的目录信息
/var/log/clickhouse-server/ # clickhouse-server的日志文件
/etc/clickhouse-server/ #config.xml包含的是clickhouse全局的配置,users.xml包含用户相关的配置
/var/lib/clickhouse/ #里面有许多文件,主要关注 data 和 metadata, data里面包含clickhouse的数据库 , metadata存放对应库表的元数据信息
5. 示例

三. 集群搭建
1. 集群节点信息
- 192.168.200.91 cdh01
- 192.168.200.98 cdh02
- 192.168.200.99 cdh03
2. 搭建一个zookeeper集群(如果有则跳过)
- 下载 zookeeper-3.4.8.tar.gz 安装包,放置到上面三台服务器相同目录下(/usr/local)
- 进入到/usr/local目录下,解压tar包,tar -zxvf zookeeper-3.4.8.tar.gz
- 进入zookeeper的conf目录,拷贝zoo_sample.cfg为zoo.cfg,cp zoo_sample.cfg zoo.cfg 修改zoo.cfg文件:
tickTime=2000
dataDir=/opt/zookeeper
clientPort=2181
initLimit=10
syncLimit=2
server.1=cdh01:2888:3888
server.2=cdh02:2888:3888
server.3=cdh03:2888:3888- 三台服务器分别创建目录 : mkdir /opt/zookeeper
- 在/opt/zookeeper目录中创建一个名为myid的文件,三台服务器文件内容分别为1,2,3
- 进入zookeeper的bin目录,启动zookeeper服务,每个节点都需要启动 ./zkServer.sh start
- 启动之后查看每个节点的状态 ./zkServer status , 其中有一个节点是leader,有两个节点是follower,证明zookeeper集群是部署成功的
- 测试zookeeper连接 ./zkCli.sh -server cdh01:2181
3. 集群部署
3.1 首先在三台服务器分别安装上clickhouse, 安装参照如上单机方式。
3.2 修改配置文件: vim /etc/clickhouse-server/config.xml
<!-- 修改端口:(默认9000端口跟hdfs冲突) -->
<tcp_port>9002</tcp_port>
<!-- 修改时区 -->
<timezone>Asia/Shanghai</timezone>
<!-- 配置监听网络 -->
<!--ip地址,配置成::可以被任意ipv4和ipv6的客户端连接, 需要注意的是,如果机器本身不支持ipv6,
这样配置是无法连接clickhouse的,这时候要改成0.0.0.0 -->
<listen_host>0.0.0.0</listen_host>
<!-- 添加集群相关配置 -->
<remote_servers>
<!-- 3个分片1个副本 -->
<test_cluster_three_shards_internal_replication>
<shard>
<!-- 是否只将数据写入其中一个副本,默认为false,表示写入所有副本,
在复制表的情况下可能会导致重复和不一致,所以这里要改为true,
clickhouse分布式表只管写入一个副本,其余同步表的事情交给复制表和zookeeper来进行 -->
<internal_replication>true</internal_replication>
<replica>
<host>cdh01</host>
<port>9002</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>cdh02</host>
<port>9002</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>cdh03</host>
<port>9002</port>
</replica>
</shard>
</test_cluster_three_shards_internal_replication>
</remote_servers>
<!-- zookeeper配置 -->
<zookeeper>
<node>
<host>cdh01</host>
<port>2181</port>
</node>
<node>
<host>cdh02</host>
<port>2181</port>
</node>
<node>
<host>cdh03</host>
<port>2181</port>
</node>
</zookeeper>
<!-- 复制标识的配置,也称为宏配置,这里唯一标识一个副本名称,每个实例配置都是唯一的 -->
<macros>
<!-- 当前节点在在集群中的分片编号,需要在集群中唯一,3个节点分别为01,02,03 -->
<shard>01</shard>
<!-- 副本的唯一标识,需要在单个分片的多个副本中唯一,3个节点分别为cdh01,cdh02,cdh03 -->
<replica>cdh01</replica>
</macros>除了直接修改/etc/clickhouse-server/config.xml文件外,我们也可以在/etc/clickhouse-server/config.d目录下创建一个名为metrika.xml的配置文件来配置remote_servers,zookeeper, macros。例如:
<?xml version="1.0"?>
<yandex>
<!—ZooKeeper配置,名称自定义,和config.xml 对应,一般就用这个名字就好 -->
<zookeeper-servers>
<node index="1">
<!—节点配置,可以配置多个地址-->
<host>127.0.0.1</host>
<port>2181</port>
</node>
</zookeeper-servers>
<clickhouse_remote_servers> <!--远程服务名称 config.xml使用-->
......
</clickhouse_remote_servers>
<macros>
......
</macros>
</yandex>接着,在全局配置config.xml中使用<include_from>标签导入刚才定义的配置。
<zookeeper incl="zookeeper-servers" optional="true" />
<remote_servers incl="clickhouse_remote_servers" optional="true" />
<macros incl="macros" optional="true"/>
<include_from>/etc/clickhouse server/config.d/metrika.xml</include_from>这里就再不继续扩展。
4. 简单测试
1) . 首先各节点启动 : systemctl start clickhouse-server 查看运行状态 : systemctl status clickhouse-server

2) . 任意节点连接clickhouse : clickhouse-client --host=cdh02 --port=9002 -m
查询集群 :
select cluster,shard_num,replica_num,host_name,port,user,is_local from system.clusters;
SELECT version();
5. 建库
官方文档: CREATE DATABASE | ClickHouse Docs
语法:
CREATE DATABASE [IF NOT EXISTS] db_name
[ON CLUSTER cluster]
[ENGINE = db_engine(...)]
[COMMENT 'Comment']功能说明:
1. 创建名称为db_name的数据库。
2. 如果指定了 ON CLUSTER cluster 子句,那么在指定集群 cluster 的所有服务器上创建 db_name 数据库。
3. ENGINE = db_engine(...), 数据库引擎。ClickHouse 默认使用 Atomic 数据库引擎,即有默认值 ENGINE = Atomic。Atomic 引擎提供了可配置的 table engines 和 SQL dialect,它支持非阻塞的DROP TABLE和RENAME TABLE查询和原子的表交换查询命令 EXCHANGE TABLES t1 AND t2。Atomic 中的所有表都有持久的 UUID,数据存储在/clickhouse_path/store/xxx/xxxyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy/ 路径下。其中,xxxyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy是表 UUID,支持在不更改 UUID 和移动表数据的情况下执行重命名。可以使用DatabaseCatalog,通过 UUID访问 Atomic 数据库中的表。执行DROP TABLE 命令,不会删除任何数据,Atomic 数据库只是通过将元数据移动到 /clickhouse_path/metadata_dropped/,并将表标记为已删除,并通知 DatabaseCatalog。
在 20.5 版本中(可以使用 SELECT version() 查看 ClickHouse 版本),ClickHouse 首次引入了数据库引擎 Atomic。从 20.10 版开始,它是默认数据库引擎(之前默认使用 engine=Ordinary )。
下面我们在任意节点执行sql创建一个数据库:
CREATE DATABASE IF NOT EXISTS test01 ON CLUSTER test_cluster_three_shards_internal_replication;
查看数据库 :
show databases;
show create database test01;
看当前ClickHouse Server 进程实例下更加详细的数据库列表信息:
select * FROM system.databases;
这样我们就在所有节点都创建了名为test01的数据库。
6. 建表
官方文档: CREATE TABLE | ClickHouse Docs
1). 创建本地表 :
CREATE TABLE [IF NOT EXISTS] [db.]table_name ON CLUSTER cluster
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = engine_name()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...];选项描述:
- db:指定数据库名称,如果当前语句没有包含‘db’,则默认使用当前选择的数据库为‘db’。
- cluster:指定集群名称,目前固定为default。ON CLUSTER 将在每一个节点上都创建一个本地表。
- type:该列数据类型,例如 UInt32。
- DEFAULT:该列缺省值。如果INSERT中不包含指定的列,那么将通过表达式计算它的默认值并填充它。
- MATERIALIZED:物化列表达式,表示该列不能被INSERT,是被计算出来的; 在INSERT语句中,不需要写入该列;在SELECT *查询语句结果集不包含该列。
- ALIAS :别名列。这样的列不会存储在表中。 它的值不能够通过INSERT写入,同时使用SELECT查询星号时,这些列也不会被用来替换星号。 但是它们可以用于SELECT中,在这种情况下,在查询分析中别名将被替换。
- 物化列与别名列的区别: 物化列是会保存数据,查询的时候不需要计算,而别名列不会保存数据,查询的时候需要计算,查询时候返回表达式的计算结果
以下选项与表引擎相关,只有MergeTree系列表引擎支持:
- PARTITION BY:指定分区键。通常按照日期分区,也可以用其他字段或字段表达式。
- ORDER BY:指定 排序键。可以是一组列的元组或任意的表达式。
- PRIMARY KEY: 指定主键,默认情况下主键跟排序键相同。因此,大部分情况下不需要再专门指定一个 PRIMARY KEY 子句。
- SAMPLE BY :抽样表达式,如果要用抽样表达式,主键中必须包含这个表达式。
- SETTINGS:影响 性能的额外参数。
- GRANULARITY :索引粒度参数。
示例,创建一个本地表:
CREATE TABLE test01.table_001_local ON CLUSTER 'test_cluster_three_shards_internal_replication' (
ts DateTime,
tvid Int32,
area Int32,
count Int32
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/test01/table_001_local/{shard}', '{replica}')
PARTITION BY toYYYYMMDD(ts)
ORDER BY (ts,tvid,area); 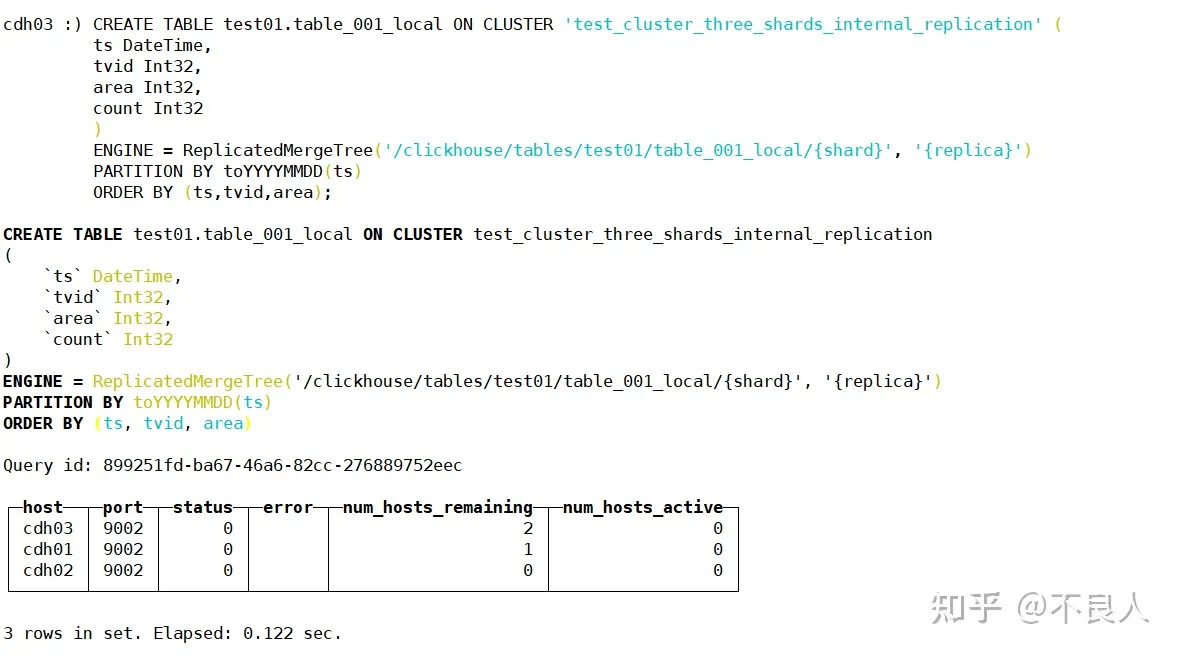
说明 :
高可用集群(双副本以上),要用ReplicatedMergeTree等Replicated系列引擎,否则副本之间不进行数据复制,导致数据查询结果不一致。{shard},{replica} 参数不需要赋值。
2). 创建分布式表:
基于本地表创建一个分布式表。
CREATE TABLE [db.]table_name ON CLUSTER default
AS db.local_table_name
ENGINE = Distributed(<cluster>, <database>, <shard table> [, sharding_key])参数说明:
- db:数据库名。
- local_table_name:对应的已经创建的本地表表名。
- shard table:同上,对应的已经创建的本地表表名。
- sharding_key:分片表达式。可以是一个字段,例如user_id(integer类型),通过对余数值进行取余分片;也可以是一个表达式,例如rand(),通过rand()函数返回值/shards总权重分片;为了分片更均匀,可以加上hash函数,如intHash64(user_id)。
示例:创建一个分布式表:
CREATE TABLE test01.table_001 ON CLUSTER 'test_cluster_three_shards_internal_replication'
AS test01.table_001_local
ENGINE = Distributed(test_cluster_three_shards_internal_replication,test01,table_001_local,tvid);
7. 简单测试插入查询
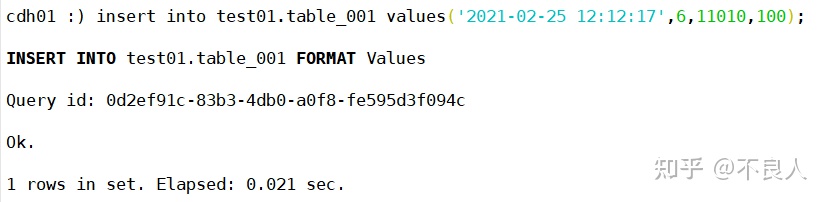
我们在cdh01节点执行两条插入语句:
insert into test01.table_001 values('2021-02-25 12:12:17',6,11010,100);
insert into test01.table_001 values('2021-02-25 12:12:17',7,11010,100); 两条插入语句只改了sharding_key,即tvid字段的值。

查询分布式表(各节点):
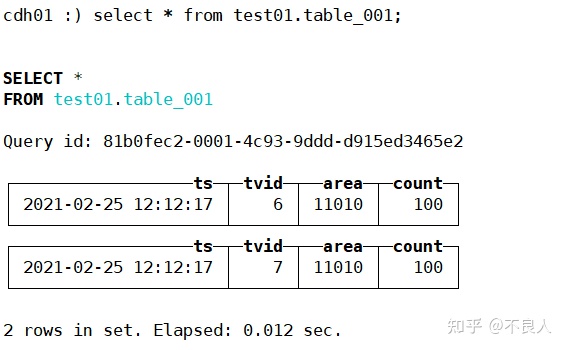
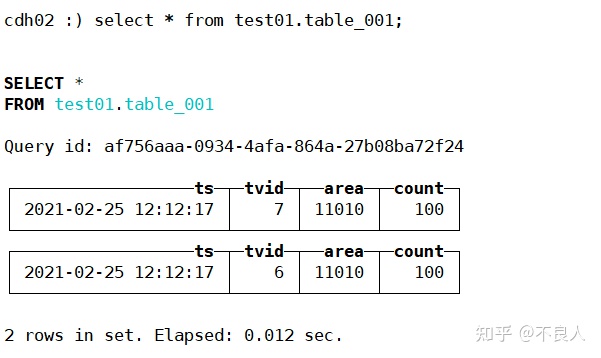

可以看到各节点分布式表查询数据是一样的。
查询本地表(各节点):
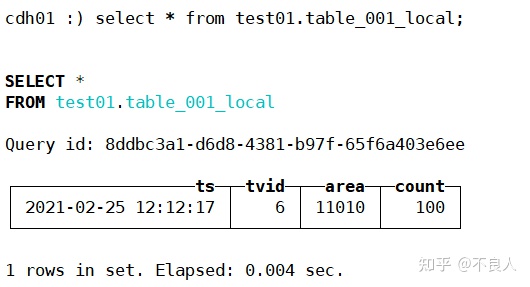
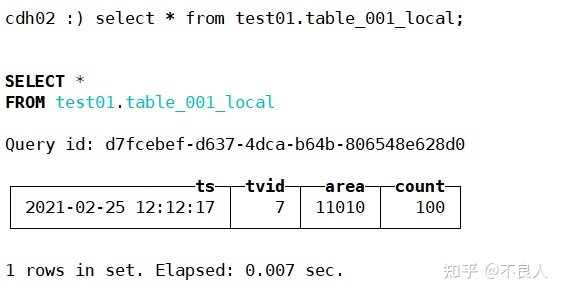
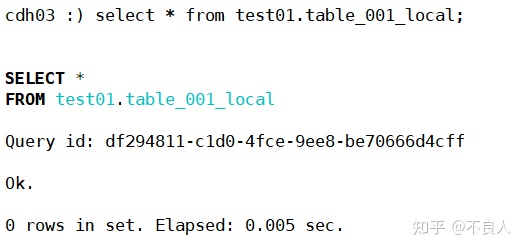
可以看到cdh01,cdh02各查到一条数据,cdh03没数据,说明sharding_key起了作用。
8. 测试单分片多副本
停止集群: systemctl stop clickhouse-server
修改配置文件: vim /etc/clickhouse-server/config.xml
<!-- 添加集群相关配置 -->
<remote_servers>
<!-- 1个分片3个副本 -->
<test_cluster_three_shards_internal_replication>
<shard>
<!-- 是否只将数据写入其中一个副本,默认为false,表示写入所有副本,
在复制表的情况下可能会导致重复和不一致,
所以这里要改为true,clickhouse分布式表只管写入一个副本,
其余同步表的事情交给复制表和zookeeper来进行 -->
<internal_replication>true</internal_replication>
<replica>
<host>cdh01</host>
<port>9002</port>
</replica>
<replica>
<host>cdh02</host>
<port>9002</port>
</replica>
<replica>
<host>cdh03</host>
<port>9002</port>
</replica>
</shard>
</test_cluster_three_shards_internal_replication>
</remote_servers>
<!-- 复制标识的配置,也称为宏配置,这里唯一标识一个副本名称,每个实例配置都是唯一的 -->
<macros>
<!-- 当前节点在在集群中的分片编号,需要在集群中唯一,3个节点都为01-->
<shard>01</shard>
<!-- 副本的唯一标识,需要在单个分片的多个副本中唯一,3个节点分别为cdh01,cdh02,cdh03 -->
<replica>cdh01</replica>
</macros>启动集群:systemctl start clickhouse-server
连接集群: clickhouse-client --port=9002 -m
查询集群:select cluster,shard_num,replica_num,host_name,port,user,is_local from system.clusters;

在其中一个节点建库:
CREATE DATABASE IF NOT EXISTS test02 ON CLUSTER test_cluster_three_shards_internal_replication;
创建本地表:
CREATE TABLE test02.table_001_local ON CLUSTER 'test_cluster_three_shards_internal_replication' (
ts DateTime,
tvid Int32,
area Int32,
count Int32
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/test02/table_001_local/{shard}', '{replica}')
PARTITION BY toYYYYMMDD(ts)
ORDER BY (ts,tvid,area); 
创建分布式表:
CREATE TABLE test02.table_001 ON CLUSTER 'test_cluster_three_shards_internal_replication'
AS test02.table_001_local
ENGINE = Distributed(test_cluster_three_shards_internal_replication,test02,table_001_local,tvid);
插入一条数据:
insert into test02.table_001 values('2021-02-25 12:12:17',6,11010,100);查询分布式表和本地表(各节点)
select * from test02.table_001;
select * from test02.table_001_local;结论:
各节点查询分布式表和本地表数据是一样的,说明副本生效。














 4934
4934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









