







搜索与图论
D F S DFS DFS
D F S DFS DFS又称暴搜,其中最重要的是回溯和剪枝, D F S DFS DFS是不断递归,剪枝是当递归到某一层时,我们判断出一定不是我们所需要的答案,就可以提前结束当前递归避免无效计算;回溯是我们结束当前递归,需要返回上一层时,需要把我们的状态恢复到上一层,以便进行其他情况的搜索。

#include <iostream>
#include <cstring>
using namespace std;
const int N = 20;
int n;
char g[N][N];
bool col[N], dg[N], udg[N];
void dfs(int u)
{
if(u == n)
{
for(int i = 0; i < n; i ++)
{
for(int j = 0; j < n; j ++) cout << g[i][j];
cout << endl;
}
cout << endl;
return;
}
for(int i = 0; i < n; i ++)
{
if(!col[i] && !dg[u + i] && !udg[u - i + n])
{
g[u][i] = 'Q';
col[i] = dg[u + i] = udg[u - i + n] = true;
dfs(u + 1);
col[i] = dg[u + i] = udg[u - i + n] = false;
g[u][i] = '.';
}
}
return;
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n;
for(int i = 0; i < n; i ++)
for(int j = 0; j < n; j ++)
g[i][j] = '.';
dfs(0);
return 0;
}
B F S BFS BFS
B
F
S
BFS
BFS又称宽搜,是逐层搜索,当遍历完某一层所有点之后才会遍历下一层,常用队列实现。当图中的权重都为1或某一定值时,
B
F
S
BFS
BFS搜索具有最短性,即第一次搜索到的点为距离起点最近的点


#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
using namespace std;
typedef pair<int, int> PII;
const int N = 110;
int g[N][N], d[N][N];
int n, m;
queue<PII> q;
int bfs()
{
int dx[4] = {1, -1, 0, 0}, dy[4] = {0, 0, -1, 1};
while(q.size())
{
auto t = q.front();
q.pop();
for(int i = 0; i < 4; i ++)
{
int x = t.first + dx[i], y = t.second + dy[i];
if(x >= 0 && x < n && y >= 0 && y < m && d[x][y] == -1 && g[x][y] == 0)
{
d[x][y] = d[t.first][t.second] + 1;
q.push({x, y});
}
}
}
return d[n - 1][m - 1];
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m;
for(int i = 0; i < n; i ++)
{
for(int j = 0; j < m; j ++)
{
cin >> g[i][j];
}
}
memset(d, -1, sizeof d);
d[0][0] = 0;
q.push({0,0});
cout << bfs() << endl;
return 0;
}
树与图的存储与遍历
树是一种特殊的图,即无环连通图,因此树的存储与遍历与图一样,而无向图可以看成是双向连通的有向图,因此我们只考虑有向图即可。有向图的存储方式主要有两种,分别为邻接矩阵和邻接表,其中邻接矩阵实现方式主要是二维数组,适合存储稠密图;邻接表实现方式主要是单链表,适合存储稀疏图。

树与图的深度优先遍历
我们可以求出删掉每个节点以后,剩余的连通部分节点数的最大值,在求出其中的最小值即可。对于每一个节点,我们都求出以该节点为根节点的子树的节点数,递归求解即可。
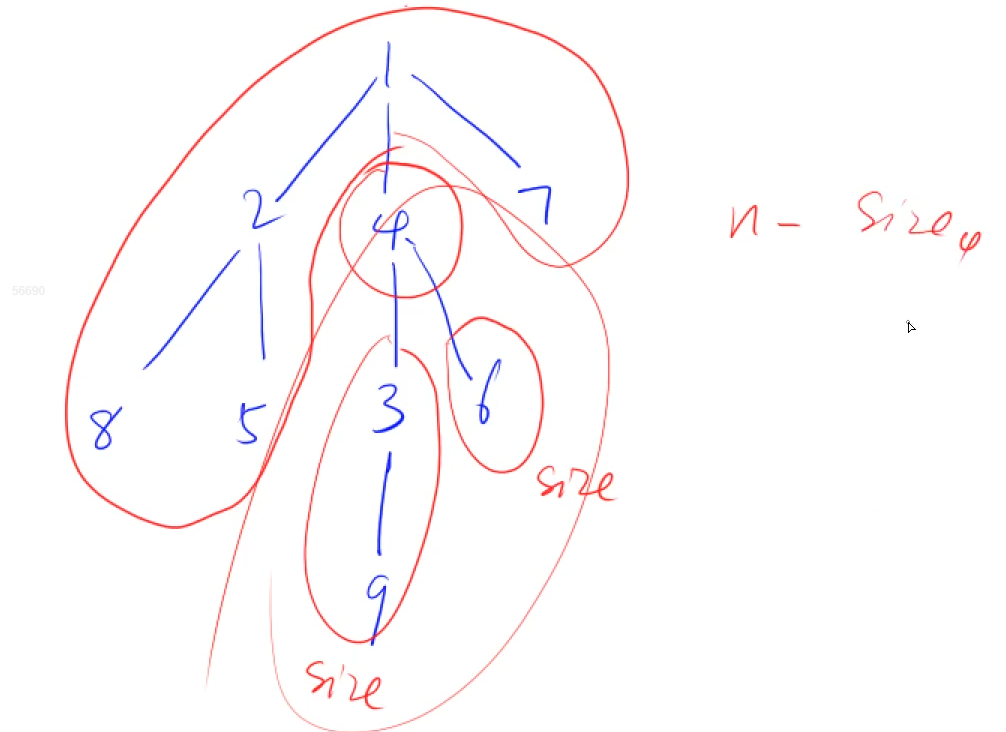
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
using namespace std;
const int N = 100010;
int n;
int ans = N;
bool str[N];
int h[N], e[2 * N], ne[2 * N], idx;
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
int dfs(int u)
{
str[u] = true;
int sum = 1, res = 0;
for(int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if(!str[j])
{
int s = dfs(j);//递归求出每个子树的节点数
res = max(res, s);//记录子树中最大的节点数
sum += s;//计算当前根节点的节点数
}
}
res = max(res, n - sum);//与剩下部分的节点数比较
ans = min(ans, res);//更新答案
return sum;//返回当前根节点的节点数
}
int main()
{
cin >> n;
memset(h, -1, sizeof h);
for(int i = 0; i < n - 1; i ++)
{
int a, b;
cin >> a >> b;
add(a, b);
add(b, a);
}
dfs(1);
cout << ans << endl;
return 0;
}
树与图的广度优先遍历
#include <iostream>
#include <queue>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int h[N], e[N], ne[N], idx;
int d[N];
bool st[N];
int n, m;
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
int bfs()
{
queue<int> q;
q.push(1);
while(q.size())
{
int t = q.front();
q.pop();
st[t] = true;
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if(!st[j])
{
d[j] = d[t] + 1;
st[j] = true;
q.push(j);
}
}
}
return d[n];
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m;
memset(h, -1, sizeof h);
memset(d, -1, sizeof d);
for(int i = 0; i < m; i ++)
{
int a, b;
cin >> a >> b;
add(a, b);
}
d[1] = 0;
cout << bfs() << endl;
return 0;
}
拓扑排序
若一个由图中所有点构成的序列
A
A
A满足:对于图中的每条边
(
x
,
y
)
(x,y)
(x,y),
x
x
x 在
A
A
A中都出现在
y
y
y 之前,则称
A
A
A 是该图的一个拓扑序列。
如果一个图是有向无环图,那么一定存在一个拓扑序,因此有向无环图又称为拓扑图
一个有向无环图一定至少存在一个入度为
0
0
0的点,因此求拓扑序可以从入度为零的点开始,依次遍历所有出边,并删除(保证其指向的点入度为零),再将入度为零的点入队


#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 100010;
int n, m;
int h[N], e[N], ne[N], idx;
int d[N];
int q[N], hh, tt = -1;
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
bool topsort()
{
for(int i = 1; i <= n; i ++)
{
if(!d[i]) q[++ tt] = i;
}
while(hh <= tt)
{
int t = q[hh ++];
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
d[j] --;
if(!d[j]) q[++ tt] = j;
}
}
if(tt == n - 1) return true;
else return false;
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m;
memset(h, -1, sizeof h);
for(int i = 0; i < m; i ++)
{
int a, b;
cin >> a >> b;
add(a, b);
d[b] ++;
}
if(topsort())
{
for(int i = 0; i <= tt; i ++) cout << q[i] << ' ';
}
else cout << "-1" << endl;
return 0;
}
最短路

D i j k s t r a Dijkstra Dijkstra
D
i
j
k
s
t
r
a
Dijkstra
Dijkstra算法是基于贪心实现的,每次选取到起点最近的点,更新起点到其他点的距离,当遍历完所有点时,即得到了起点到其他点的最短路。朴素
D
i
j
k
s
t
r
a
Dijkstra
Dijkstra时间复杂度为
O
(
n
2
)
O(n^2)
O(n2),主要应用于稠密图,一般使用邻接矩阵存储图。


#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
int g[N][N];
int n, m;
int dist[N];
bool st[N];
int dijkstra(int u)
{
dist[u] = 0;
for(int i = 1; i <= n; i ++)
{
int t = -1;
for(int j = 1; j <= n; j ++)
if(!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;//从还未确定最短路径的点中找到最短
st[t] = true;//该点到起点就是最短的
for(int j = 1; j <= n; j ++)
dist[j] = min(dist[j], dist[t] + g[t][j]);//用已找到的点更新其他点到起点的距离
}
return dist[n];
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m;
memset(dist, 0x3f, sizeof dist);
memset(g, 0x3f, sizeof g);
for(int i = 0; i < m; i ++)
{
int a, b, c;
cin >> a >> b >> c;
g[a][b] = min(g[a][b], c);
}
int t = dijkstra(1);
if(t == 0x3f3f3f3f) cout << "-1" << endl;
else cout << t << endl;
return 0;
}
堆优化的 D i j k s t r a Dijkstra Dijkstra时间复杂度为 O ( m l o g ( n ) ) O(mlog(n)) O(mlog(n)),主要应用于稀疏图,一般使用邻接表存储图。

#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
using namespace std;
const int N = 200010;
typedef pair<int, int> PII;
int n, m;
int h[N], e[N], ne[N], w[N], idx;
int dist[N];
bool st[N];
priority_queue<PII, vector<PII>, greater<PII>> heap;//小根堆
void add(int a, int b, int c)
{
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++;
}
int dijkstra(int u)
{
dist[1] = 0;
heap.push({0,1});
while(heap.size())//遍历所有点
{
auto t = heap.top();//取出当前距离起点最近的点
heap.pop();
int ver = t.second, distance = t.first;
if(!st[ver])
{
for(int i = h[ver]; i != -1; i = ne[i])
{
int j = e[i];
if(dist[j] > distance + w[i])
{
dist[j] = distance + w[i];//更新该点的所有出边
heap.push({dist[j], j});//将更新的点放进堆中
}
}
st[ver] = true;
}
}
if(dist[n] == 0x3f3f3f3f) return -1;
else return dist[n];
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m;
memset(dist, 0x3f, sizeof dist);
memset(h, -1, sizeof h);
for(int i = 0; i < m; i ++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
cout << dijkstra(1) << endl;
return 0;
}
B e l l m a n − f o r d Bellman-ford Bellman−ford
B
e
l
l
m
a
n
−
f
o
r
d
Bellman-ford
Bellman−ford算法是每次求经过
k
k
k条边起点到终点的最短距离,
k
k
k最多是
n
n
n,这里需要注意,如果枚举所有边,则可能出现起点到不了终点,但是终点的路径仍然有可能会被更新。使用该算法还需要注意我们在更新其他点时,有可能会出现使用已经更新过的其他点,为了避免这种情况发生,我们每次需要将上一次的结果保存下来,只使用上一次的结果更新其他点。


#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, M = 100010;
using namespace std;
int n, m, k;
int dist[N], backup[N];
struct edge{
int a, b, c;
}Edge[M];
void bellmand()
{
dist[1] = 0;
for(int i = 0; i < k; i ++)
{
memcpy(backup, dist, sizeof dist);
for(int j = 0; j < m; j ++)
{
int a = Edge[j].a, b = Edge[j].b, c = Edge[j].c;
dist[b] = min(dist[b], backup[a] + c);
}
}
}
int main()
{
cin >> n >> m >> k;
memset(dist, 0x3f, sizeof dist);
for(int i = 0; i < m; i ++)
{
int a, b, c;
cin >> a >> b >> c;
Edge[i] = {a, b, c};
}
bellmand();
if(dist[n] > 0x3f3f3f3f / 2) cout << "impossible" << endl;
else cout << dist[n] << endl;
return 0;
}
s p f a spfa spfa
s
p
f
a
spfa
spfa算法是将
B
e
l
l
m
a
n
−
f
o
r
d
Bellman-ford
Bellman−ford优化,在我们更新点的距离时,并不需要遍历所有边,只需要将更新过的点所能到达的点更新即可,即只有自己更新之后,自己所到达的点才可能会被更新。因此我们使用队列来优化,依次将更新过的点入队,然后将队头出队,遍历队头所能到达的点,将被更新的点再入队,这里需要注意,如果更新过的点已经在队列里面了,则只需要更新距离即可,不需要重复入队。


#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 100010;
int n, m;
int h[N], w[N], e[N], ne[N], idx;
int dist[N], backup[N];
bool st[N];
void add(int a, int b, int c)
{
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++;
}
void spfa()
{
queue<int> q;
dist[1] = 0;
st[1] = true;
q.push(1);
while(q.size())
{
int t = q.front();
q.pop();
st[t] = false;
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if(dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
if(!st[j]) //已更新过的点不需要重复入队
{
q.push(j);
st[j] = true;
}
}
}
}
}
int main()
{
cin >> n >> m;
memset(h, -1, sizeof h);
memset(dist, 0x3f, sizeof dist);
for(int i = 0; i < m; i ++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa();
if(dist[n] == 0x3f3f3f3f) cout << "impossible" << endl;
else cout << dist[n] << endl;
return 0;
}
我们可以使用一个数组来存一下当前的边数,当我们更新点的距离时,实际上也更新了一条路径,有一条新的路径使得起点到该点的距离更小,我们记录一下当前路径的边数,如果边数大于
n
n
n,说明存在环,且可以更新最短距离,说明一定存在负权回路。


#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 2010, M = 100010;
int dist[N], cnt[N];
int n, m;
bool st[N];
int h[N], w[M], e[M], ne[M], idx;
void add(int a, int b, int c)
{
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++;
}
bool spfa()
{
queue<int> q;
//将所有点入队
for(int i = 1; i <= n; i ++)
{
q.push(i);
st[i] = true;
}
while(q.size())
{
int t = q.front();
q.pop();
st[t] = false;
for(int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if(dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
cnt[j] = cnt[t] + 1;
//更新了n次,即有n条边,n + 1个点,即存在负环
if(cnt[j] >= n) return true;
if(!st[j])
{
q.push(j);
st[j] = true;
}
}
}
}
return false;
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n >> m;
memset(h, -1, sizeof h);
for(int i = 0; i < m; i ++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
if(spfa()) cout << "Yes" << endl;
else cout << "No" << endl;
return 0;
}
F l o y d Floyd Floyd
f l o y d floyd floyd算法是计算多源汇最短路的常用算法,其原理是基于动态规划,计算出任意两点之间的最短距离,时间复杂度为 O ( n 3 ) O(n^3) O(n3)。 在计算 i , j i, j i,j之间的最短距离时,考虑选取 1 1 1到 k k k的节点作为中间经过的节点时,从 i i i到 j j j的最短路径的长度。

/*
比如,f[1][i][j]就代表了,在考虑了1节点作为中间经过的节点时,从i到j的最短路径的长度。
分析可知,f[1][i][j]的值无非就是两种情况,而现在需要分析的路径也无非两种情况,i=>j,i=>1=>j:
【1】f[0][i][j]:i=>j这种路径的长度,小于,i=>1=>j这种路径的长度
【2】f[0][i][1]+f[0][1][j]:i=>1=>j这种路径的长度,小于,i=>j这种路径的长度
形式化说明如下:
f[k][i][j]可以从两种情况转移而来:
【1】从f[k−1][i][j]转移而来,表示i到j的最短路径不经过k这个节点
【2】从f[k−1][i][k]+f[k−1][k][j]转移而来,表示i到j的最短路径经过k这个节点
总结就是:f[k][i][j]=min(f[k−1][i][j],f[k−1][i][k]+f[k−1][k][j])
从总结上来看,发现f[k]只可能与f[k−1]有关。
*/
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 210;
int n, m, k;
int d[N][N];
void floyd()
{
for(int k = 1; k <= n; k ++)
{
for(int i = 1; i <= n; i ++)
{
for(int j = 1; j <= n; j ++) d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
}
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n >> m >> k;
for(int i = 1; i <= n; i ++)
{
for(int j = 1; j <= n; j ++)
{
if(i == j) d[i][j] = 0;
else d[i][j] = 0x3f3f3f3f;
}
}
for(int i = 0; i < m; i ++)
{
int a, b, c;
cin >> a >> b >> c;
d[a][b] = min(d[a][b], c);
}
floyd();
for(int i = 0; i < k; i ++)
{
int a, b;
cin >> a >> b;
if(d[a][b] > 0x3f3f3f3f / 2) cout << "impossible" << endl;
else cout << d[a][b] << endl;
}
return 0;
}
最小生成树

一般稠密图用朴素版
P
r
i
m
Prim
Prim,稀疏图用
K
r
u
s
k
a
l
Kruskal
Kruskal算法
P r i m Prim Prim
p
r
i
m
prim
prim算法基于贪心策略,每次选取距离当前生成树权值最小的点,将该点加到生成树中,并更新其他点到当前生成树的距离,当把所有的点都加到树中时,所得到的树就是最小生成树。


#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int dist[N], g[N][N];
bool st[N];
int n, m;
int prim()
{
int res = 0;
for(int i = 0; i < n; i ++)
{
int t = -1;
for(int j = 1; j <= n; j ++)
{
if(!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
}
st[t] = true;
if(i && dist[t] == 0x3f3f3f3f) return INF;
if(i) res += dist[t];
for(int j = 1; j <= n; j ++) dist[j] = min(dist[j], g[t][j]);
}
return res;
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n >> m;
memset(dist, 0x3f, sizeof dist);
memset(g, 0x3f, sizeof g);
for(int i = 0; i < m; i ++)
{
int a, b, c;
cin >> a >> b >> c;
g[a][b] = g[b][a] = min(g[a][b], c);
}
int t = prim();
if(t == INF) cout << "impossible" << endl;
else cout << t << endl;
return 0;
}
K r u s k a l Kruskal Kruskal
k
r
u
s
k
a
l
kruskal
kruskal算法思路是从小到大因此枚举所有边,每次尝试将该边加进当前的生成树中,当遍历完所有的边,所得到的生成树就是最小生成树。其中,每次尝试将一条边加进当前的生成树时,需要判断是否会构成环,即判断该边的两个顶点是否在一个连通块中,可以使用并查集判断。


#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 200010;
int n, m;
int p[N];
struct Edge
{
int a, b, c;
bool operator< (const Edge& W)const
{
return c < W.c;
}
}edges[N];
int find(int x)
{
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n >> m;
for(int i = 0; i < m; i ++)
{
int a, b, c;
cin >> a >> b >> c;
edges[i] = {a, b, c};
}
sort(edges, edges + m);
for(int i = 1; i <= n; i ++) p[i] = i;
int res = 0, cnt = 0;
for(int i = 0; i < m; i ++)
{
int a = edges[i].a, b = edges[i].b, c = edges[i].c;
a = find(a), b = find(b);
if(a != b)
{
res += c;
cnt ++;
p[b] = a;
}
}
if(cnt < n - 1) cout << "impossible" << endl;
else cout << res << endl;
return 0;
}
二分图
染色法判定二分图
染色法判定二分图对于每个节点,我们 d f s dfs dfs其所在的连通块,将连通块染色,如果染色失败则不是二分图

#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010, M = 200010;
int h[N],ne[M], e[M], idx;
int color[N];
int n, m;
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
bool dfs(int x, int u)
{
color[x] = u;
for(int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if(!color[j])//若未颜色
{
//判断是否可以将其染色成功
if(!dfs(j, 3 - u)) return false;
}
else if(color[j] == color[x]) return false;
}
return true;
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n >> m;
memset(h, -1, sizeof h);
for(int i = 0; i < m; i ++)
{
int a, b;
cin >> a >> b;
add(a, b), add(b,a);
}
bool flag = true;
for(int i = 1; i <= n; i ++)
{
if(!color[i])
{
if(!dfs(i, 1))
{
flag = false;
}
}
}
if(flag) cout << "Yes" << endl;
else cout << "No" << endl;
return 0;
}
二分图最大匹配
匈牙利算法
匈牙利算法是对于二分图的一个顶点,判断是否可以匹配,若可以匹配则匹配;若不可以匹配,则判断要匹配的点是否可以更换匹配,当遍历完所有点,即得到二分图的最大匹配。


#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, M = 200010;
int h[N], e[M], ne[M], idx;
int match[N];
bool st[N];
int n, m, k;
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
bool find(int u)
{
for(int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if(st[j]) continue;
st[j] = true; //当前的节点一定是有对象的
//如果没有,就匹配给当前的节点,如果已经有对象了,尝试让对方换一个
if(match[j] == 0 || find(match[j]))
{
match[j] = u;
return true;
}
}
return false;
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n >> m >> k;
memset(h, -1, sizeof h);
for(int i = 0; i < k; i ++)
{
int a, b;
cin >> a >> b;
add(a, b);
}
int res = 0;
for(int i = 1; i <= n; i ++)
{
memset(st, false, sizeof st);
if(find(i)) res ++;
}
cout << res << endl;
return 0;
}















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









