









九、高级查询
9.1、高级查询语法概述
一个查询语句的完整形式如下所示:
select子句
[fom子句]
[where子句]
[group by子句]
[having子句]
[order by子句]
[limit子句];
可见,select 语句还是比较复杂的一其实是mysql中最复杂的语句。
总体说明:
① 以上中括号中的任一项都可以省略,但如果不省略,就应该按该顺序出现。
② 通常,fom后的子句都需要有from子句,having 子句需要有group by子句。
③ 这些子句的“执行顺序”,也是按此顺序进行的。


9.2、查询结果数据及select选项
9.2.1、查询“固定数据”
例:
select 1;
select 2, ‘abc’;
select 3, now();
9.2.2、select中可以进行计算
例:
select 1 + 2;
sclect 3+4*5, 6+ round(6,7); #其中round( )为系统函数
9.2.3、查询出的数据字段可以使用别名
例:
select 1 as d1, 2+3 as d2;
select user_ name as un, user_ pass as pwd from user;(也可以不加as)
9.2.4、使用distinct消除查询结果重复行
重复行的含义:
两行(或两行以上)的数据完全一样。
语法形式:
select distinct 字段1 , 字段2, … from表名;
9.3、where子句
语法形式:
select … from表名 where查询条 件;
说明:
① 查询条件,类似php语言中的判断条件,也就是说,where相当于if.
② 查询条件的作用是:针对from子句的表“进行一行一行筛选”,以筛选出符合条件的行。
③ 查询条件中,可以使用很多的运算符,包括:算术运算符,比较运算符,逻辑运算符,等等。
示例:
where id> 10; //比较运算符
where age- 18>=0; //算术运算符,比较运算符
where id<20 and age>= 18: //比较运算符, 逻辑运算符
where year%4=0 and year%100!=0 || year%400=0 ;
//算术运算符,比较运算符,逻辑运算符
9.4、 mysql运算符
9.4.1、算术运算符
+ - * / %
9.4.2、比较运算符:
相等: =
不相等: <> 或 !=
大于: >
大于等于: >=
小于: <
小于等于: <=
9.4.3、逻辑运算符:
逻辑与: && 或 and
逻辑或: || 或 or
逻辑非: ! 或 not
9.4.4、其他特殊运算符
like模糊查找运算符:
用于判断某个字符型字段的值是否包含给定的字符。
语法形式:
xxx字段 like ‘%关键字%’
其中: %表示“任意个数的任意多个字符”。
还可以使用“_”<下杠),表示“任意一个字符”。
示例:
where name like ‘罗%’
//找出ame的第一个字为“罗”的所有
//可以找出:“罗成”、“罗纳尔多”、“罗”
//但找不出“C罗纳尔多”
where name like ’罗_ ‘ (只能找两个字的)
//可以找出:“罗成”,“罗兰”
//但找不出“c罗”,“罗永浩”
极端情况:
where name like “罗”
//其实它只是相当于: name=“罗"
如果不使用“%”或“”,则like 相当于等于(=)。比如:
xxx字段 like ‘关键字’
相当于:
xxx字段 = ’关键字’
between范围限定运算符:
用于判断某个字段的值是否在给定的两个数据范围之间。
语法形式:
xxx字段 between 值1 and 值2
其含义相当于: xxx字段 >= 值1 and xxx字段 <= 值2
in运算符:
用于判断某个字段的值是否在给出的若干个“可选值”范围。
语法形式:
xxx字段 in (值1,值2,… )
其含义是:该字段的值等于所列出的任意一个值,就算满足条件,比如:
籍贯 in( ‘北京’, ‘山东’ , ‘河北’, ‘江西’ );
//则某人籍贯为上述4个之一就ok.
is运算符:
用于判断一个字段中的是“是否存在”(即有没有),只有两个写法,如下所示:
where content is null; //不能写成: content = null;
where content is not null; //不能写成: content != null;

9.5、 group by子句
语法形式:
group by 字段1,字段2,… ;
含义:
表示对所取得的数据,以所给定的字段来进行分组。
最后的结果就是将数操分成了若干组,每组作为一个“整体”成为一行數据。
示例:
对于如下原始数据:
商品信息表(product)
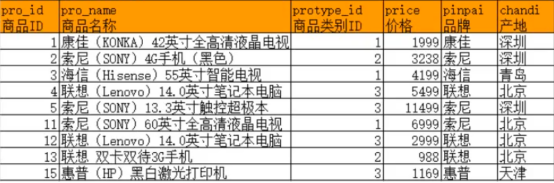
对其“品牌”进行分组:


结果:
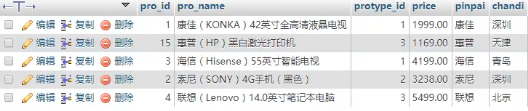
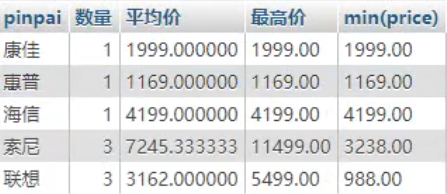
特别注意:
分组查询的结果,要理解为,将“若干行原始数据”,分成了若干组,结果是每组为一行数据。
即:一行数据就代表“一组”这个集合概念,而不再是单个概念。
因此:一行中出现的信息,应该是“组的信息”,而不是“个体信息”。
于是,对于分组查询(group by),select中出现的信息,通常就只有两种情况的信息了:
① 分组本身的字段信息:
② 一组的综合统计信息,主要包括:
● 计数值: count(字段), 表示求出一组中原始数据的行数;
● 最大值: max(字段), 表示求出一组中该字段的最大值;
● 最小值: min(字段), 表示求出一组中该字段的最小值;
● 平均值: avg(字段), 表示求出一组中该字段的平均值;
● 总和值: sum(字段), 表示求出一组中该字段的累加和;
以上五个函数称为“聚合函数”。
9.6、 having子句
语法形式:
having筛选条件
含义:
having的含义跟where的含义一样,只是having是用于对gyroup by分组的结果进行的条件筛选。
即: having 其实是相当于分组之后“有若干行数据”,然后对这些行再筛选。

9.7、 order by子句
语法形式:
order by 字段1 [asc或 desc], 字段2 [asc 或desc], …
含义:
对前面所取得的数据按给定的字段进行排序。
排序方式有:正序 asc , 倒序desc, 如果省略不写,就是asc

9.8、 limit子句
语法形式:
limit 起始行号,行数
说明:
① limit 表示对前面所取得的数据再进行数量上的筛选:取得从某行开始的多少行。
② 行号就是前面所取得数据的“自然顺序号”,从0开始算起 —— 注意不是id,或任何其他实际数据。
③ 起始行号可以省略,此时limit 后只用一个数字,表示从第0行开始取出多少行。
④ limit 子句通常用在“翻页”功能上,用于找出“第n页”的数据,其公式为:
limit(n- 1)" pageSize, pageSize, 其中 pageSize表示每页显示的条数。

应用:
limit子句常常用于网页的“翻页功能”。
基本原理:
limit子句常常用于网页的“翻页功能”。
假设总的数据行数为9,每页显示2行(条),则:
查看第1页: select from product limit 0,2;
查看第2页: select from product limit 2,2;
查看第3页: select from product limit 4,2;
..................
查看第n页: select from product limit (n-1)*2,2;
十、高级插入
10.1、同时插入多行记录
语句形式:
insert into 表名(字段1,字段2, ..) values(值 1,值2, .). (值1,值2, ..), ... ;
10.2、插入查询的结果数据
合义:
就是将一个select语句的查询结果,插入到某个表中!
语句形式:
insert into 表名(字段 1,字段2, … select (xx1, xx2, … ) ;
要求:
① 插入语句的字段个数,跟select语句的字段个数相等;
② 插入语句的字段类型,跟select语句的字段类型相符;

10.3、set语法插入数据
语句形式:
insert into 表名 set字段1=值1, 字段2=值2, …;

10.4、蠕虫复制
所谓蠕虫复制,就是针对一个表的数据,进行快速的复制并插入到所需要的表中,以期在短时间内具备“大量数据”,以用于测试或其他特殊场合,比如:
① 将一个表的大量数据,复制到另一个表中;
insert into tab(id,name,sex,age) select id,name,sex,age from tab1;
② 将一个表的数据复制到本身表中以产生大量数据;
insert into tab(id,name,sex,age) select id,name,sex,age from tab;
10.5、插入时主键冲突的解决办法
所谓主键冲突是指,当插入一条记录的时候,如果插入的记录的主键值,在现有的数据中已经存在,则此时,因为主键不能重复,因此就产生了“主键冲突”。
那如果出现主键冲突,该怎么办呢?
● 办法1: 忽略 —— 终止插入,数据不改变。
其语法为:
insert **ignore** into 表名( 字段... ) values( 值... );

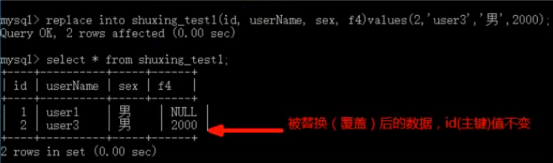
● 办法2:替换 ——删除原纪录,插入新纪录。
其语法为:
replace into into 表名(字段… )values (… );
说明:此replace的用法跟insert一样,也可以插入新记录,只是如果新记录出现主键冲突,就会删除原记录后,再插入该新纪录。
● 办法3:更新 —— 设置为去更新原有数据(而并不插入)。
语法为:
insert into 表名(字段… )values(值…) on duplicate key update XX字段=新的值;
更新类似“替换”(replace) ,区别是:
替换:是将新的数据完整覆盖旧的数据。
更新:可以人为预先设定需要覆盖的旧数据。


十一、高级删除
11.1、按指定顺序删除指定数量的数据
语法形式:
delete from 表名where … [order by 字段名…」[limit 数量 n];
说明:
① order by用于设定删除数据时的删除顺序,跟select语句中的order by子句道理一样。
② limit用于设定删除数据时要删除的行数,即删除的数据可能少于条件筛选出来的数据。
11.2、 truncate 清空
语法形式:
truncate 表名 ;
说明:
表示清空指定表中的所有数据并将表恢复到“初始状态”( 就类似刚刚创建一样 )。
11.3、对比
无条件删除: delete from 表名;
结果:删除了指定表中的所有数据 —— 但表仍然会被记录为“已使用过”。
差别:主要是对于"auto_increment" 的字段,会保留使用过的最大值,而trancate后的表,自增长的序号会完全重新开始(就像新表一样)。


十二、高级更新
语法形式:
update表名set 字段名1=字段值1,… where… [order by 字段名…] [limit 数量n];
说明:
① order by用于设定更新数据时的更新顺序,跟select语句中的order by子句道理一样。
② limit用于设定更新数据时要更新的行数,即更新的数据量可能少于条件筛选出来的数据量。
















 1179
1179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









