







宏观上来说,调优分为3个部分:硬件、网络、软件。软件再细分为表设计(范式、字段类型、存储引擎)、SQL语句与索引、配置文件参数、操作系统、文件系统、MySQL版本、体系架构这几大部分
1.1 字符类型
char和varchar是日常使用最多的字符类型。char(N)用于保存固定长度的字符串,长度最大为255,比指定长度大的值将被截短,而比指定长度小的值将会用空格进行填补。
varchar(N)用于保存可变长度的字符串,长度最大为65535,只存储字符串实际需要的长度(它会增加一个额外字节来存储字符串本身的长度), varchar使用额外的1~2字节来存储值的长度,如果列的最大长度小于或等于255,则使用1字节,否则就是用2字节
char和varchar跟字符编码也有密切联系,latin1占用1个字节,gbk占用2个字节,utf8占用3个字节,utf8mb4占用4个字节
1.计算varchar的最大长度
不同的字符集所占用的存储空间会不同,具体如表5-5~表5-7所示
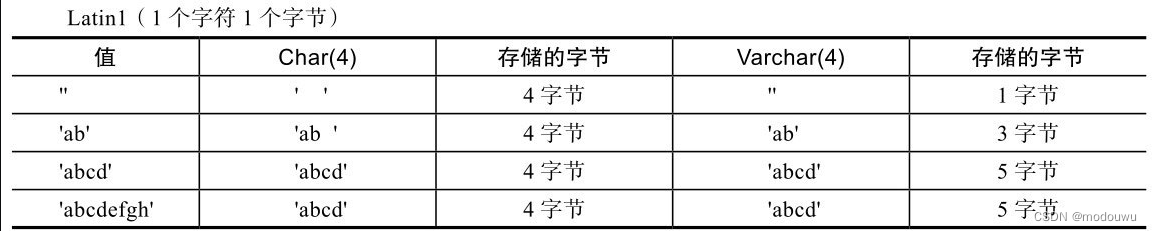
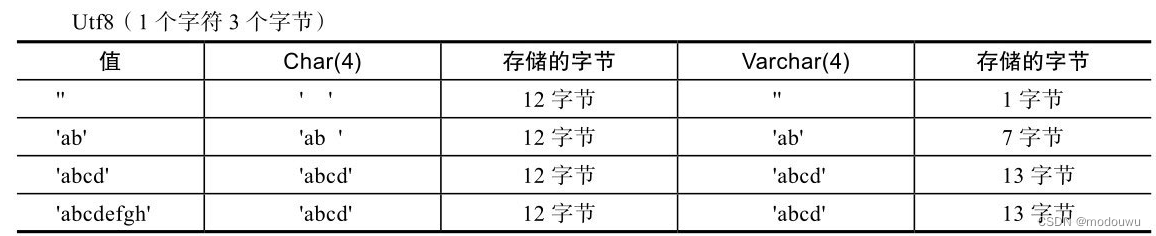
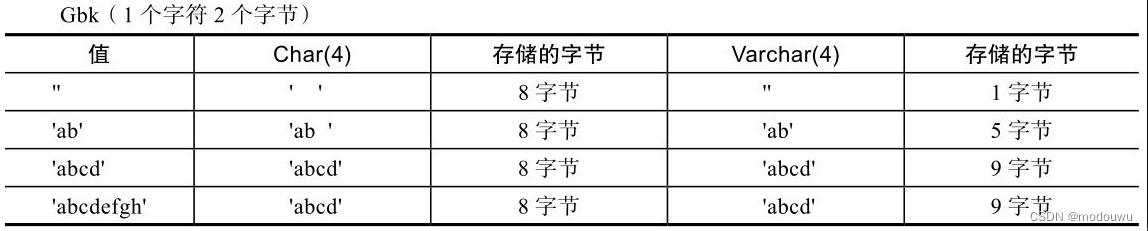
引申出一个问题,既然跟字符编码有关系,那么如何计算出varchar(N)的最大长度?下面就经常使用的gbk和utf8来举例说明。
(1)GBK字符集
首先创建一张表,表里采用gbk字符集,可以看到,字段v设置为32766可以正常创建,但超过了就失败。

因为varchar类型长度大于255,因此这里要用2字节存储值的长度。计算公式:(65535-2)/2=32766.5,也就是说不能大于32767。
(2)UTF8字符集
同样创建一张表,表里采用utf8字符集,可以看到,字段v设置为21844可以正常创建,但超过了就失败。

因为varchar类型长度大于255,因此这里要用3字节存储值的长度。计算公式:(65535-2)/3=21844.3,也就是说不能大于21845。
有人会问,一个表里肯定有好几个字段,那么varchar(N)的最大长度还是按照上面的公式计算吗?事实上,这时就需要变通一下了,假设一个表有如下字段:
(id int, username varchar(20), phone bigint, address varchar(N))
我们来计算下address的最大长度,这里采用GBK字符集,代码如下:
create table info
(id int, username varchar(20), phone bigint, address varchar(32766))charset=gbk;
SQL建表语句的执行结果如图5-22所示。

很奇怪吧?这里输入32766这个长度居然报错了。事实上,MySQL规定一个行的定义长度不能超过65535。若定义的表长度超过这个值,则会报错。而在这个info表中:id字段占用4字节,username字段占用41字节(因为长度小于255,这里要用1字节存储值的长度), phone字段占用8字节,所以计算结果为(65535-4-20×2+1-8-2)/2=32740,也就是不能大于32740,前面输入的32766明显大于此数,自然会报错了。
2.在什么情况下使用char和varchar
经常变化的值,如家庭住址,那么用varchar相对比较合适,因为它只存储字符串实际的长度。而对于固定长度的值,比如uuid函数,那么可以设置为char(32),这样相比于varchar,还节省空间,因为varchar还要用1字节存储值的长度。
既然varchar只存储字符串实际的长度,那么使用varchar(20)或varchar(100)存储’abc’字节都会一样,那我干脆在设计表时就把值定义得大一些,为今后的扩展先预留出来。
对于这个问题,虽然两者存储的空间是一样的,但二者的性能完全不一样,MySQL需要先在内存中分配固定的空间来保存值,这无形中就浪费了内存,而且对表的排序或使用临时表尤其不好,所以只分配真正需要的那部分空间即可。
2.事务的实现
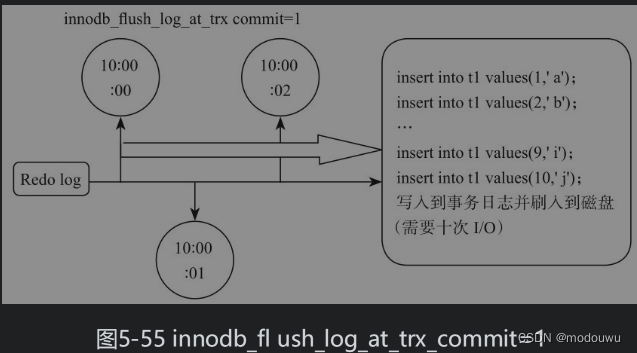
像其他数据库一样,MySQL在进行事务处理的时候使用的是日志先行的方式来保证事务可快速和持久运行的,也就是在写数据前,需要先写日志。当开始一个事务时,会记录该事务的一个LSN日志序列号;当执行事务时,会往InnoDB_Log_Buffer日志缓冲区里插入事务日志(redo log);当事务提交时,会将日志缓冲区里的事务日志刷入磁盘。这个动作是由innodb_flush_log_at_trx_commit这个参数控制的。
innodb_flush_log_at_trx_commit=0,表示每个事务提交时,每隔一秒把log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。也就是说一秒之前的日志都保存在日志缓冲区,也就是内存上,如果机器宕掉,可能丢失1秒的事务数据。
innodb_flush_log_at_trx_commit=1,表示每个事务提交时,表示在每次事务提交的时候,都把log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。这样的话,数据库对IO的要求就非常高了,如果底层的硬件提供的IOPS比较差,那么MySQL数据库的并发很快就会由于硬件IO的问题而无法提升。
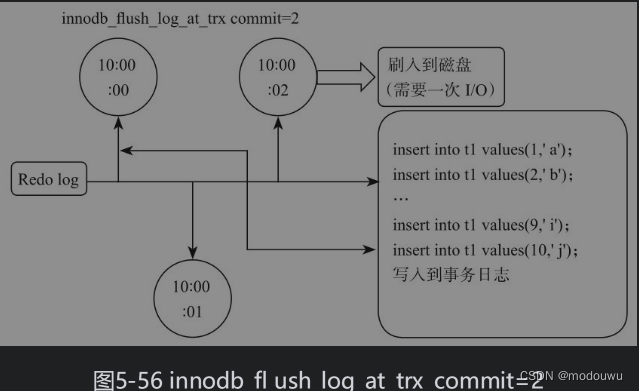
innodb_flush_log_at_trx_commit=2,表示每个事务提交时,表示在每次事务提交的时候会把log buffer刷到文件系统中去,但并不会立即刷写到磁盘。如果只是MySQL数据库挂掉了,由于文件系统没有问题,那么对应的事务数据并没有丢失。只有在数据库所在的主机操作系统损坏或者突然掉电的情况下,数据库的事务数据可能丢失1秒之类的事务数据。这样的好处,减少了事务数据丢失的概率,而对底层硬件的IO要求也没有那么高(log buffer写到文件系统中,一般只是从log buffer的内存转移的文件系统的内存缓存中,对底层IO没有压力)。
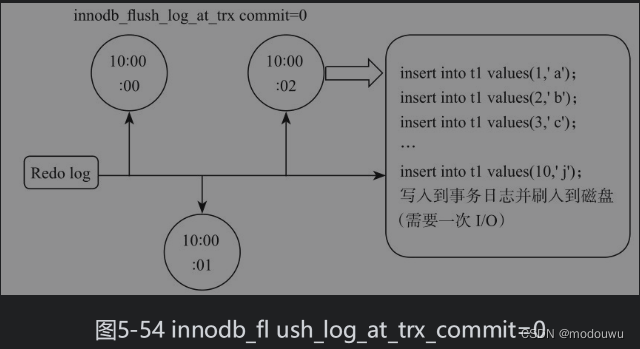
除了记录事务日志以外,数据库还会记录一定量的撤销日志(undo log), undo与redo正好相反,在对数据进行修改时,由于某种原因失败了,或者人为执行了rollback回滚语句,就可以利用这些撤销日志将数据回滚到修改之前的样子。
事务提交以后,首先刷新到binlog,然后再刷新到redo log里。如果在刷新到binlog的时候发生宕机,那么MySQL数据库在下次启动时,由于redo log里没有该事务记录就会回滚,但是二进制日志已经记录了该事务信息,不能被回滚。所以另一端的slave会复制master上的binlog,这样主从数据就会出现不一致,XA事务可以保证InnoDB redo log与MySQL binlog的一致性。可以将innodb_support_xa设置为1,但会对性能产生影响。
索引优化
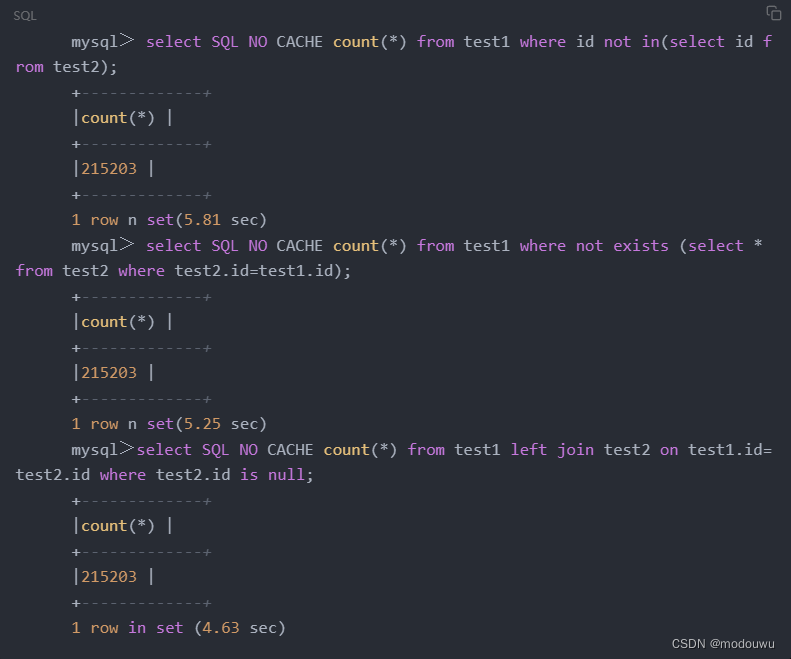
not in子查询优化
执行子查询时,MYSQL需要创建临时表,查询完毕后再删除这些临时表,所以,子查询的速度会受到一定的影响,这里多了一个创建和销毁临时表的过程。应尽量避免使用子查询,可用left join表连接取代之。
limit分页优化
看下面的limit查询:
mysql> select SQL NO CACHE * from test1 order by id limit 99999,10;
±----------±----------±-----+
| d|t d|name|
±----------±----------±-----+
| 100000 | 100000 | abc |
| 100001 | 100001 | abc |
| 100002 | 100002 | abc |
| 100003 | 100003 | abc |
| 100004 | 100004 | abc |
| 100005 | 100005 | abc |
| 100006 | 100006 | abc |
| 100007 | 100007 | abc |
| 100008 | 100008 | abc |
| 100009 | 100009 | abc |
±----------±----------±-----+
10 rows in set (0.07 sec)
在上面的SQL语句中,虽然用上了id索引,但要从第一行开始起定位至99999行,然后再扫描出后10行,相当于进行一个全表扫描,显然效率不高。我们来看看优化方法,如下:
mysql> select SQL NO CACHE * from test1 where id >=100000 order by id limit 10;
±----------±----------±-----+
| d|t d|name|
±----------±----------±-----+
| 100000 | 100000 | abc |
| 100001 | 100001 | abc |
| 100002 | 100002 | abc |
| 100003 | 100003 | abc |
| 100004 | 100004 | abc |
| 100005 | 100005 | abc |
| 100006 | 100006 | abc |
| 100007 | 100007 | abc |
| 100008 | 100008 | abc |
| 100009 | 100009 | abc |
±----------±----------±-----+
10 rows in set (0.00 sec)
第二种写法比第一种快了7倍,利用id索引直接定位100000行,然后再扫描出后10行,相当于一个range范围扫描。
or条件如何优化
在SQL语句里有or条件,则会用不到索引,下面看这个例子:下面的SQL语句中,user和age字段都建立索引。
mysql> SELECT * FROM USER WHERE name=‘d’ or age=41;
±—±-------±-----+
| id | name | age |
±—±-------±-----+
|4 |d |23 |
|6 |f |41 |
±—±-------±-----+
2 rows in set (0.00 sec)
上面这条语句会用到索引吗?答案是:不会。
改为union all结果集合并。
致命的无引号导致全表扫描,无法用到索引
这是开发人员在日常写SQL语句时容易忽视的一个问题。mysql是强类型,用数字当字符类型,数字一定要加引号。
当取出的数据量超过表中数据的20%,优化器就不会使用索引,而是全表扫描
我们看下面的一个例子,这里要取出大于2012年3月15日的数据,如图5-79所示。

优化器执行的结果是全表扫描。虽然有索引,但没有用上,扫描的行数太多了(8位数),优化器认为全表扫描比索引来得快。下面缩短了时间范围,如图5-80所示。

现在,已经使用到了索引。
order by、group by优化

从优化器上来看,里面使用了排序Using filesort。
我们可以考虑为pid字段和change_date建立一个联合索引。
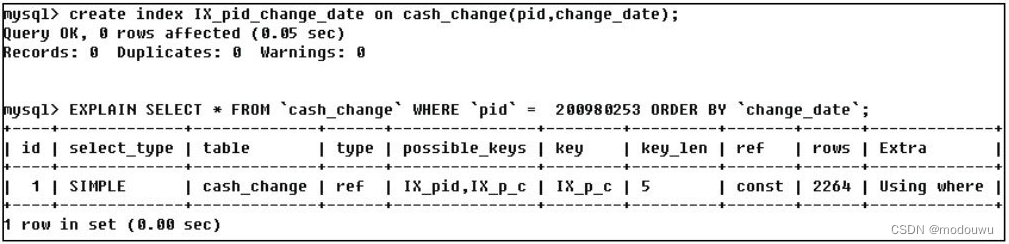
可以看到,Using filesort排序已经没有了。Group by的优化方法也是一样的。
如果order by后面有多个字段排序,它们的顺序要一致,如果一个是降序,一个是升序,也会出现Using filesort排序。
MySQL5.6优化了Index Merge合并索引
也就是说,一条SQL可以用上两个索引了。
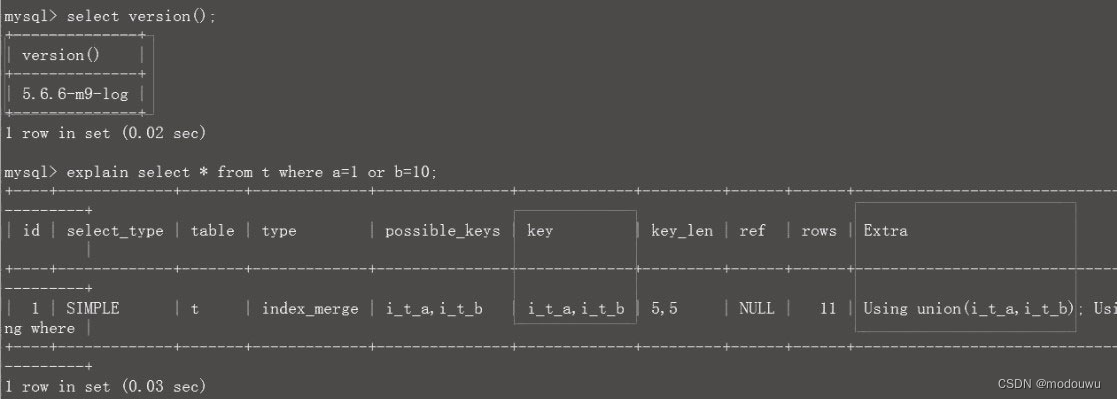
可以看到,两个索引一起用到了,这是因为采用了索引合并的方式。但是,如果是三个字段索引,则用不上索引合并
MySQL5.6支持Index Condition Pushdown索引优化
Index Condition Pushdown(简称ICP),Using index condition, ICP减少了存储引擎访问表的次数,从而提高数据库的整体性能。














 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









